Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3501
Answering Approximate Queries over XML Data
P.V. Aparanjini Priyadarsini & Mrs. Chaganti B N Lakshmi
Lecturer Department Of Computer Science Sreeramachandra Arts & Science College Tilak Nagar, Hyderabad, India.
Associate Professor Department Of It Mahaveer Institute Of Science And Technology Bandlaguda Hyderabad, India.
Abstract: Data trade is the issue of finding an occurrence of an objective composition, given an occasion of a source outline and a detail of the connection between the source and the objective. Hypothetical establishments of data trade have as of late been explored for social data. In this paper, we begin investigating the fundamental properties of XML data trade that is, rebuilding of XML archives that fit in with a source DTD under an objective DTD and answering inquiries composed over the objective mapping. We characterize XML data trade settings in which source-to target conditions allude to the various leveled structure of the data. Consolidating DTDs and conditions makes some XML data trade settings conflicting. We examine the consistency issue and decide its correct multifaceted nature. We at that point move to query answering and demonstrate a division hypothesis that groups data trade settings into those over which query answering is tractable, and those over which it is coNP-finished, contingent upon classes of general articulations utilized as a part of DTDs.
Moreover, for every single tractable case, we give polynomial-time calculations that register target XML records over which inquiries can be replied.
Keywords: XML, approximate
query-answering, data mining, intentional information, succinct answers
1. INTRODUCTION
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3502 since query dialects for semi-organized data
depend upon the one record structure to pass on its semantics, all together for query detailing to be viable clients need to know this structure ahead of time, which is frequently not the situation. Truth be told, it isn't required for an XML record to have a characterized diagram: half of the archives on the web don't have one. At the point when clients determine inquiries without knowing the report structure, they may neglect to recover information which was there, however under an alternate structure. This confinement is a vital issue which did not develop with regards to social database administration frameworks. Visit, emotional results of this circumstance are either the information over-burden issue, where an excess of data are incorporated into the appropriate response in light of the fact that the arrangement of watchwords indicated for the pursuit catches excessively numerous implications, or the information hardship issue, where either the utilization of improper catchphrases, or the wrong plan of the query, keep the client from accepting the right answer. As an outcome, while getting to out of the blue an expansive dataset, increasing some broad information about its fundamental basic and semantic attributes helps examination on more particular subtle elements. This paper tends to the need of getting the essence of the report before querying
it, both as far as substance and structure. Finding repetitive examples inside XML records gives astounding learning about the archive content: visit designs are in actuality intentional information about the data contained in the report itself, that is, they indicate the record regarding an arrangement of properties as opposed to by methods for data. Instead of the itemized and exact information passed on by the data, this information is halfway and regularly approximate, however, engineered, and concerns both the record structure and its substance. Specifically, mining affiliation guidelines to give outlined portrayals of XML records has been explored in numerous recommendations either by utilizing dialects and systems created in the XML setting or by actualizing chart or tree-based calculations. In this paper, we present a proposition for mining and putting away TARs (Tree-based Association Rules) as a way to speak to intentional information in local XML. Naturally, a TAR speaks to intentional learning
in the shape SB ⇒ SH, where SB is the body
tree and SH the head tree of the governor and
SB is a subtree of SH. The run SB ⇒ SH states
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3503 of the reports, valuable in many regards:
(i)when a client faces a dataset out of the blue, s/he doesn't know its highlights and successive examples give an approach to see rapidly what is contained in the dataset;
(ii)Besides inherently unstructured archives, there are a critical bit of XML records which have some structure, yet just verifiably, that is, their structure has not been proclaimed by means of a DTD or an XML-Schema. Since most work on XML query dialects has concentrated on reports having a known structure, querying the
previously mentioned records is very
troublesome in light of the fact that clients need to figure the structure to determine the query conditions accurately. TARs speak to a data manage that encourages clients to be more viable in query detailing;(iii) it bolsters query advancement outline, most importantly in light of the fact that intermittent structures can be utilized for physical query streamlining, to help the development of lists and the plan of proficient access techniques for visit questions, and furthermore on the grounds that continuous
examples permit to find shrouded
trustworthiness requirements, that can be utilized for semantic improvement;(iv)For protection reasons, a report answer may uncover a controlled arrangement of TARs rather than the first archive, as an outlined view that covers delicate points of interest.
TARs can be questioned to acquire quick, albeit approximate, answers. This is especially valuable when brisk answers are required as well as when the first records are inaccessible. Actually, once separated, TARs can be put away in a (littler) report and be gotten to autonomously of the dataset they were removed from. Compressing, TARs are separated for two principal purposes: 1) to get a brief thought – the essence – of both the structure and the substance of an XML record, and 2) to utilize them for intentional query answering, that is, enabling the client to query the removed TARs as opposed to the first archive. In this paper, we focus basically on the second assignment.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3504 data, significantly diminishing time and cost.
This paper gives a strategy to getting intentional learning from XML records as TARs, and after that putting away these TARs as an option, manufactured dataset to be questioned for giving brisk and compressed answers. Our strategy is described by the accompanying key viewpoints: an) it works straightforwardly on the XML reports, without changing the data into a middle of the road arrange, b) it searches for general affiliation rules, without the need to force what ought to be contained in the precursor and resulting of the lead, c) it stores affiliation controls in XML organization, and d) it deciphers the inquiries on the first dataset into questions on the TARs set. The point of our proposition is to give an approach to utilize intentional Knowledge as a substitute of the first archive amid querying and not to enhance the execution time of the questions over the first XML dataset, as in.
The rest of this paper is sorted out as in the accompanying segments. Segment 2will depicts the related work child data trade over XML questions. Segment 3 will exhibit the proposed data trade over XML inquiries technique. In Section 4, we will dissect the aftereffects of the proposed strategy and contrast it and standard data trade techniques. At long last, a concise conclusion will be given in Section 5.
2. RELATED WORK
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3505 research and business. In these applications, data
originating from different sources must be changed to data complying with a solitary target outline to empower assist data investigation. As of late, the dangerous development of information online has offered ascend to considerably more application classes that require semantic joining. One application class assembles data-mix frameworks. Such a framework furnishes clients with a uniform query interface (called interceded mapping) to a huge number of data. By and large, way records are proposed to rapidly answer questions that take after some successive way layout, and are worked by ordering just those ways having exceedingly visit inquiries. We begin from an alternate point of view: we need to give a snappy, and regularly approximate, answer likewise to easygoing inquiries. Inokuchi et al. displayed a basic issue in building a data-coordination framework, along these lines, is to supply the semantic matches. Since by and by data sources frequently contain copy things another imperative issue is to distinguish and dispose of copy data tuples from the answers returned by the sources previously exhibiting the last answers to the client query. Another essential application class is peer data administration, which is a characteristic augmentation of data joining. Goldman et al. exhibited a companion data administration
framework Does away with the idea of interceded blueprint and permits peers (that is, taking an interest data sources) to query and recover data specifically from each other. Such querying and data recovery require the making of semantic correspondences among the associates. As of late there has likewise been
extensive consideration on demonstrate
administration, which makes apparatuses for effortlessly controlling models of data (for instance, data portrayals, site structures, and substance relationship [ER] outlines). Here semantic combination assumes a focal part; as coordinating and consolidating models frame center operations in display administration algebras.Washio et al. introduced a data-sharing application emerge in various current certifiable spaces. They likewise assume an imperative part in developing spaces, for example, web based
business, bioinformatics, and pervasive
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3506 that semantic reconciliation plays in their
arrangement.
3. PROPOSED WORK
The proposed work plans to give non specific help to querying provenance information to empower an extensive variety of clients and applications. Regular sorts of provenance questions we need to help incorporate standard heredity inquiries for determining the data and summons used to infer other data; inquiries that enable clients to guarantee that particular data and conjuring conditions were fulfilled inside a run; questions for determining the sources of info and yields of summons (e.g., in view of the
on-screen characters utilized and their
parameters); and inquiries. The proposed framework comprises of the accompanying four modules.
1. The System Construction Module
2. Query Relaxations
3. Approximate Queries Processing
4. top-k Retrieval Approach
A probabilistic XML report characterizes a likelihood circulation over a space of deterministic XML archives. Each deterministic report having a place with this space is known as a conceivable word. A record spoke to as a marked tree has conventional and distributional hubs. Standard hubs are normal XML hubs and
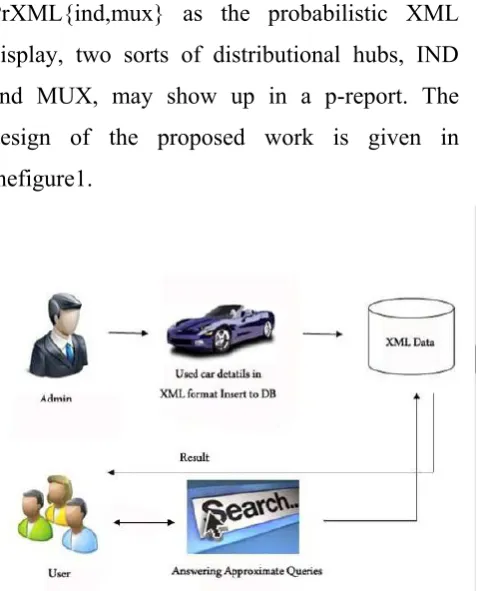
they may show up in deterministic archives, while distributional hubs are utilized for characterizing the probabilistic procedure of creating deterministic reports and they don't happen in those records. As we embrace PrXML{ind,mux} as the probabilistic XML display, two sorts of distributional hubs, IND and MUX, may show up in a p-report. The design of the proposed work is given in thefigure1.
Figure 1. Proposed System Architecture
A. System Construction Module
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3507 connections among them. A straightforward
XML data example which contains a heterogeneous gathering of utilized cars.We build up the framework for the utilization of client auto deals framework. The substances accessible in our framework are administrator and clients. A sorts out autos in light of the model of an auto, B composes autos as indicated by the offering area, and C incorporates autos that are composed by model and year. The approximate inquiries can be accomplished by presenting substitutes having the approximate query aims with the first query, which we call comparative substitutes.
B. Query Relaxations:
System of query relaxations for supporting approximates the inquiries over XML data. The answers basic this system are not constrained to entirely fulfill the given query definition; rather, they can be established on properties inferable from the first query. A query unwinding
technique consolidating structures and
substance, as well as the components that clients are more worried about (we deduce these
elements by first breaking down the first query and afterward recognizing unwinding requesting of structures and hubs), to answer approximate XML questions. Our technique gathers the elements that clients are more worried about in view of the examination of client's unique query for supporting query relaxations. Likewise, our approach separates the unwinding requesting as opposed to giving an equivalent significance to every hub to be casual. Specifically, the main loose structure to be considered is the one that has the most astounding likeness coefficient with unique query, and the principal hub to be casual is the slightest imperative hub. Query unwinding empowers frameworks to debilitate the query requirements to a less confined shape to suit clients' needs. Generally, inquiries presented by clients are changed in different perspectives and approaches to adapt to various circumstances. The significance of such procedures that empower programmed query alteration comes from the way that this conduct is an extremely basic action in human talk.
C. Approximate Query Processing:
In this module Approximate query preparing (AQP) is an option way that profits approximate answer utilizing information which is like the one from which the query would be answered.We first propose a complex structure of query relaxations for supporting approximate
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3508 with the first query, which we call comparative
substitutes.Approximate query is a recovery system, which observes matches that are probably going to be significant to a hunt contention notwithstanding when the contention does not precisely relate to the coveted information. An approximate query is finished by methods for an approximate coordinating technique, which restores a rundown of results in view of likely pertinence despite the fact that pursuit contention may not precisely coordinate.
D. Top-k Retrieval Approach:
In this module a novel best k recovery approach that can intelligently produce the most encouraging answers in a request connected with the positioning measure.The proposed likeness appraisal and the degrees of significance we supplement the query relaxations with a programmed recovery approach that can effectively create the most encouraging best k answers.The answer score of an answer (a match) measures the pertinence of that response to the client's query. For a given parameter k,the top-k issue is looking through the best k answers (matches) requested from best (most astounding answer score) to the most exceedingly awful. 4. EXPERIMENTAL ANALYSIS
We have built up a model framework supporting MFA's and calculations revise and HyPE (and its variations OptHyPE and OptHyPE-C). In our examinations, we concentrated on the most
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3509 and that of the Java API for XML Processing
Reference Implementation, which depends on XERCES and XALAN. We additionally contrasted and JAXP-COMPILE, a variant of JAXP that precompiled the info query and changes over it into an arrangement of Java classes. The two JAXP variants had comparable execution and in this manner we just report one of them. We ran different sorts of XPath inquiries with basic channels on data esteems, unions of questions, and Boolean blends of filters.We demonstrate the assessment time both for questions with result sizes of a couple of many hubs and questions that arrival a couple of thousands of hubs For each query sort, we report the assessment time for JAXP, HyPE, OptHyPE and OptHyPE-C. The figures demonstrate unmistakably that our calculation reliably beat JAXP by a factor of three for HyPE, and four for OptHyPE and OptHyPE-C. We likewise watch that much of the time, both upgraded renditions of HyPE run twice as quick as HyPE. Note also that the execution of OptHyPE-C is practically indistinguishable to that of OptHyPE (while OptHyPE-C utilizes a packed file). The figure 2, 3, 4 demonstrates the execution of the proposed framework in examination with standard strategies.
Fig-2. A filter returning a large set of nodes
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3510 Figure 4.Query with filter disjunctions
The second arrangement of examinations explored the execution of assessing standard XPath questions with the diverse renditions of HyPE. Existing choices depend on an interpretation of normal XPath into an all the more effective query dialect like XQuery. We led a progression of tests following this approach. In particular, we deciphered a few customary XPath questions into XQuery and assessed them in GALAX.
These tests reliably demonstrated that the questions in XQuery required impressively additional time than their standard XPath partners. Thus we discard GALAX from our exchange in light of the fact that notwithstanding for a straightforward standard XPath query on the littlest utilized report tree, GALAX required additional time than HyPE for a similar query on the biggest tree. Henceforth, we just concentrate on the relative execution of our calculation. We ran distinctive sorts of customary XPath inquiries that include Kleene star outside a channel, inside a channel, channels inside Kleene stars and blends thereof The general conclusion is reliable with our perceptions in regards to XPath questions. In fact, OptHyPE and OptHyPE-C indicate impressive change over HyPE. A fascinating perception is that HyPE prunes a considerable number of component hubs. In particular, HyPE (resp.
OptHyPE) prunes, overall, 78.2% (resp. 88%) of the component hubs for our illustration inquiries.
5. CONCLUSION
In this paper, we display a novel data gathering plan for WSNs with a solitary versatile sink called, virtual paired tree framework based data gathering plan, which develops a virtual twofold tree foundation for sensor hubs to request the sink area. The sink moves along the fringe leaf-ranges in a clockwise way and stops in each leaf-region to gather data. The visit time in various zones depends on the aggregate sum of data gathered after the sink enters every region. The principle commitment of our virtual twofold tree foundation based data gathering plan is to gather the entire system data with less communicate overhead effectively. We likewise explore the effect of various structures on the normal vitality utilization, the upkeep cost, the bundle misfortune rate and the quantity of parcels gathered, individually. What's more, contrast the proposed plan and standard data gathering plans in the recreation. Results demonstrate that the specialist based data gathering plan is vitality productive and draws out the system lifetime essentially with fair
bundle misfortune rate, particularly in
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3511 REFERENCES
1. T.K Srinath and Joby George, Data Mining
for Xml Query Answering Support,In International Journal of Scientific and Research Publications, Volume 5, Issue 11, November 2015
2. Mirjana Mazuran, Elisa Quintarelli, and
Letizia Tanca, Data mining for XML query-answering support, IEEE TRANSACTIONS
ON KNOWLEDGE AND DATA
ENGINEERING, 2011
3. K. Wong, J. X. Yu, and N. Tang. Answering
xml queries using pathbased indexes: A survey. World Wide Web, 9(3):277–299, 2006
4. E. Hovy. Combining and standardizing
largescale, practical ontologies for machine translation and other uses. In The First International Conference on Language Resources and Evaluation (LREC), pages 535–542, Granada, Spain, 1998.
5. Navethe T, KruzanskiAdome, Advances in
frequent itemset mining implementations: report on FIMI’03. SIGKDD Explorations, 6(1):109– 117, 2004.
6. A. Jimenez, F. Berzal, and J. C. Cubero.
Mining induced and embedded ´ subtrees in ordered, unordered, and partially-ordered trees. In Proc. of the 17th Int. Symposium on Methodologies for Intelligent Systems, pages
111–120, 2008.
7. J. Widom. Dataguides: Enabling query
formulation and optimization in
semistructured databases. In Proc. of the 23rd Int. Conf. on Very Large Data Bases, pages 436–445, 1997.
8. R. Goldman and J. Widom. Approximate
DataGuides. In Proc. of the Workshop on Query Processing for Semistructured Data and NonStandard Data Formats, pages 436– 445, 1999.
9. T. Washio, and H. Motoda. Complete
mining of frequent patterns from graphs: Mining graph data. Machine Learning, 50(3):321– 354, 2003.
10.D. Katsaros, A. Nanopoulos, and Y.
Manolopoulos. Fast mining of frequent tree structures by hashing and indexing. Information & Software Technology, 47(2):129–140, 2005.
11.M. Kuramochi and G. Karypis. An efficient
algorithm for discovering frequent
subgraphs. IEEE Transactions on
Knowledge and Data Engineering,
16(9):1038–1051, 2004.
12.H. C. Liu and J. Zeleznikow. Relational
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 3512
13.Gary Marchionini. Exploratory search: from
finding to understanding. Communications of the ACM, 49(4):41–46, 2006.
14.Gary Marchionini. Exploratory search: from
finding to understanding.Communications of the ACM, 49(4):41–4 6, 2006.
15.T. Asai, K. Abe, S. Kawasoe, H. Arimura, H.
Sakamoto, and S. Arikawa. Efficient substructure discovery from large semi-structured data. In Proc. of the SIAM Int. Conf. on Data Mining, 2002.
16.T. Asai, H. Arimura, T. Uno, and S. Nakano.
Discovering frequent substructures in large unordered trees. In Technical Report DOI-TR 216, Department of Informatics, Kyushu University.
http://www.i.kyushuu.ac.jp/doitr/trcs216.pdf, 2003.
17.R. Agrawal and R. Srikant. Fast algorithms
for mining association rules in large databases. In Proc. of the 20th Int. Conf. on Very Large Data Bases, pages 487–499. Morgan Kaufmann Publishe rs Inc., 1994.
18.World Wide Web Consortium. XQuery 1.0:
An XML query language, 2007.
http://www.w3C.org/TR/xquery.
19.A. Termier, M. Rousset, M. Sebag, K.
Ohara, T. Washio, and H. Motoda. Dryadeparent, an efficient and robust closed
attribute tree mining algorithm. IEEE Transactions on Knowledge and Data Engineering, 20(3):300–320, 2008.
20.A. Evfimievski, R. Srikant, R. Agrawal, and
J. Gehrke. Privacy preserving mining of association rules. In Proc. of the 8th ACM Int. Conf. on Knowledge Discovery and Data Mining, pages 217–228, 2002.
AUTHOR’s PROFILE
P.V.Aparanjini priyadarsini is pursed M.Sc computer Science in Koti Women College ,Hyderabad and M.Tech in the stream of
Compuer Science and
Engineering from Mahaveer Institute of Science and Technology Bandlaguda Hyderabad.