MICROTUBULE-BASED NEURO-FUZZY NESTED FRAMEWORK FOR SECURITY OF
CYBER-PHYSICAL SYSTEM
ANKUSH RAI, JAGADEESH KANNAN R
School of Computing Science and Engineering, VIT University, Chennai, Tamil Nadu, India. Email: [email protected] Received: 28 December 2016, Revised and Accepted: 10 May 2017
ABSTRACT
Objective: Network and system security of cyber-physical system are of vital significance in the present information correspondence environment. Hackers and network intruders can make numerous fruitful endeavors to bring crashing of the networks and web services by unapproved interruption. Computing systems connected to the internet are stood up to with a plenty of security threats, running from exemplary computer worms to impart drive-by downloads and bot networks. In the most recent years, these threats have achieved another nature of automation and sophistication, rendering most defenses inadequate. Ordinary security measures that depend on the manual investigation of security incidents and attack advancement intrinsically neglect to give an assurance from these threats.
Methods: As an outcome, computer systems regularly stay unprotected over longer time frames. This study presents a network intrusion detection based on machine learning as a perfect match for this issue as learning strategies give the capacity to naturally dissect data and backing early detection of threats.
Results and Discussion: The results from the study have created practical results so far, and there is eminent wariness in the community about learning based defenses. Machine learning-based intrusion detection and network security systems are one of these solutions. It dissects and predicts the practices of clients, and after that, these practices will be viewed as an attack or a typical conduct.
Keywords: Intrusion detection, Artificial intelligence, Machine learning.
INTRODUCTION
Computer security on a very basic level contrasts from other application areas of machine learning. The sound utilization of a learning strategy requires precisely tending to different imperatives that are pivotal for operating a security system in practice. While the performance of machine learning in different ranges is regularly dictated by a solitary quality, for example, the arrangement accuracy, security includes a few components that require consideration. We expect to extend this work to the nonspecific utilization of machine learning and recognize four key variables for the innovation aftermaths that that will affect the end result of machine learning-based network security system’s viability.
a. Effectivity: First, any learning technique connected in the setting of security should be viable—either in recognizing, investigating, or counteracting threats. As opposed to different territories, this effectivity is very issue particular and might include a few quality measurements. For instance, an interruption detection system should accurately distinguish attacks and in addition accomplish a sensible low false alert rate as else it is inapplicable in practice.
b. Efficiency: A second critical element is productivity. The primary
inspiration for utilizing learning strategies as a part of security is their capacity to naturally give results. Consequently, learning should be quick to accomplish an advantage over traditional security methods. We will probably think of the system which systematically enhances the runtime performance of a grouping strategy for malicious software.
A greater part of the past exploration has concentrated on these two variables when considering learning in security applications. Operational system in practice, nonetheless, additionally requires tending to requests of specialists continuously. A primary explanation behind the absence of machine learning in practical security is that
effectivity and productivity alone are not adequate for planning fruitful security systems.
c. Transparency: One focal angle is straightforwardness. No professional is willing to operate a discovery system, which neglects to give logical choices. Luckily, machine learning is not essentially obscure and there exist a few methodologies for clarifying the choices of learning techniques.
d. Robustness: Finally, any augmentation to a security system will turn into an objective of attacks itself. Subsequently, machine learning should likewise manage the issue of being attacked, for instance, if a foe messes around with the learning process or tries to avoid detection and investigation. On the off chance that considered amid the outline, nonetheless, learning techniques can be developed in a vigorous way and withstand distinctive attack sorts, for instance, by randomization and expansion of the learning process. Regularization expands the essential learning improvement punishes learning rate in complex theories. Thus, we will be addressing such shortcomings by developing AI that will react and assess the move sets bilaterally to balance such advanced network threats.
We have to note here that none of these variables is new in the field of computer security and in practice security system ought to address these key elements—whether it applies machine learning or not. It therefore shocks no one that even numerous traditional security instruments neglect to fulfill all components similarly well. For instance, numerous instruments for attack detection experience the ill effects of false alarms, and examination systems for malicious software are frequently vulnerable to evasion. In any case, it is a compassion that a generous assemblage of past work on learning for security has disregarded these elements and there is an unmistakable interest for examination that brings the promising capacities of machine learning to practical security solutions.
Problem statement
There is a surprising imbalance between the extensive researches on machine learning-based anomaly detection pursued in the academic intrusion detection community, versus the lack of operational deployments of such systems. We argue that this discrepancy stems in large part from specifics of the problem domain that makes it significantly harder to apply machine learning effectively than in many other areas of computer science where such schemes are used with greater success. The domain-specific challenges include (i) the need for outlier detection, while machine learning instead performs better at finding similarities, (ii) very high costs of classification errors, which render error rates as encountered in other domains unrealistic, (iii) a semantic gap between detection results and their operational interpretation, (iv) the enormous variability of benign traffic, making it difficult to find stable notions of normality, (v) significant challenges with performing sound evaluation, and (vi) the need to operate in an adversarial setting. While none of these renders machine learning an inappropriate tool for intrusion detection, we deem their unfortunate combination in this domain as a primary reason for its lack of success.
To overcome these challenges, our research will undergo a specific set of guidelines for applying machine learning to network intrusion detection. In particular, we will be working for the importance of obtaining insight into the operation of an anomaly detection system in terms of its capabilities and limitations from an operational point of view. It is crucial to acknowledge that the nature of the domain is such that one can always find schemes that yield marginally better receiver operating characteristic curves than anything else has for a specific given setting. Such results however do not contribute to the progress of the field without any semantic understanding of the gain. Our research will contribute to strengthening solutions corresponding to machine-based network security and its applications on anomaly detection by pinpointing the fundamental challenges it faces.
Normal insusceptible system is another proposed technique to manage the interruption detection issue in a disseminated way. Disseminated positive and negative indicators are utilized to separate self and non-self-practices [5]. As indicated by the work portrayed in [14], a multi-specialists design recognizes the interruption of different free elements by independent operators working on the whole. Another multi-operators design comprising self-sufficient specialists that are based on hereditary programming strategy is likewise proposed in [6]. Specialists abusing the learning force of hereditary writing computer programs are assessed with their performance, and operators having most astounding performance are distinguished intrusions. Clustering procedures are connected on unlabeled data keeping in mind the end goal to find irregularities in the data [7].
Developing fuzzy classifiers has been concentrated on for conceivable application to the interruption detection issue [8,9]. System review preparing data is utilized to concentrate rules for every typical and strange conduct by the hereditary calculation. Guidelines are spoken to as complete expression tree with recognized administrators, for example, conjunction, disjunction, and not.
METHODS
A machine learning system endeavors to discover a hypothesis function that maps events into various classes. For instance, an interruption detection system would discover a hypothesis function that maps an incident point or an occurrence of network conduct into one of two results: Ordinary or interruption. One sort of learning system called directed learning works by taking a preparation data set together with names recognizing the class for each point in the preparation data set. For instance, a managed learning calculation for interruption detection system would have a preparation set comprising focuses relating to ordinary conduct and guides comparing toward interruption conduct. The learning calculation chooses the hypothesis function that best predicts the grouping of a point. More muddled learning calculations can manage incident focuses that are both named and unlabeled and besides can manage nonstop surges of unlabeled focuses with the goal that preparation is a progressing process.
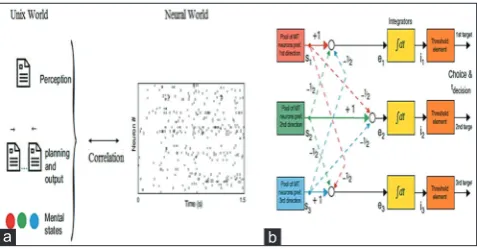
A learner can have an unequivocal preparing stage or can be constantly prepared as an online learner. Online learning permits the learner to adjust to evolving conditions; the supposition of stationarity is debilitated to suit long haul changes in the appropriation of data seen by the learner (Fig. 2). Online learning is more adaptable; however, conceivably rearranges causative attacks. By definition, an online Fig. 1: (a-b) Architecture of the network learner, where MT
represents neurons modeled based on microtubules
a b
Related work
There are a few methodologies for taking care of network interruption and detection issues. Lee and Salvatore [1] assembled an interruption detection model by utilized affiliation govern and visit scene strategies on system review data. Pivot attribute(s) as a type of thing imperatives are utilized just to register significant examples, and an iterative level-wise estimated mining method is utilized to reveal the low recurrence designs in semi-robotized way. NIDES system performs inconsistency detection by utilizing factual methodologies [2]. It generates profiles by utilizing factual estimations that tip into action of subjects and profile era. All in all, there are four sorts of factual estimations: Intensity of activities, review record distribution, downright categorical, and ordinal. Neural networks are trained to recognize interruption systems. An n-layer network is built and conceptual charges are characterized as far as arrangement of information units, the data forwarded for training to the neural net. Every command operation is considered with pre-characterized with orders together to anticipate the following incoming command operation anticipated from the client. Subsequent to training, the system has the profile of the client. At the testing step, the irregularity is said to happen as the client goes astray from the normal conduct [3]. Short arrangements of system get complete the forecast process. In this system, Hamming separation examination with an edge is utilized to segregate the ordinary succession from the strange grouping [4].
In this study we build a machine learning-based network security system for detecting malicious adversary who aims to intrude the network and try evading detection (Fig. 1). We aim to quantify the lower bounds of the detection algorithm on the performance of different classes of algorithms, and in terms of the kind of power, the adversary has. To make the algorithm more robust as a malicious adversary who controls part of the data and aims to delay learning, the adversary could ensure that, without updates, the algorithm never learns a good signature. By allowing updates, algorithm might find a good signature over a longer period. To make the network security algorithm to withstand the adversary tricky tactics to evade detection or to fool the machine learning algorithm as it wants the algorithm to make as many errors as possible, the adversary aims to release information about the true signature as slowly as possible. To eliminate the adversary’s ability to manipulate the training and testing pool, and the kinds of
The imperative added to the learning issue by the punishment term might help our defenses in two ways:
a. First, it has the impact of smoothing the arrangement, evacuating many-sided quality that an enemy may abuse in attacks [8,10]. b. Second, earlier dispersions can be a helpful approach to encode
master information around an area or use space structure gained from a preprocessing step [11,12].
In the least difficult case, we may have a sensible estimate for the parameters (for example, the mean) that we wish to refine; in a more perplexing circumstance, we could perform an investigation of a related data set giving relationship data which illuminate a multivariate Gaussian earlier on the parameters. At the point when the learner has more former data (or imperatives) on which to base the learning, there is less reliance on careful data fitting, so there is less open door for the attacker to impart and impact the learning process.
The learner can profit by the capacity to distinguish attacks regardless of the fact that they are not counteracted [10]. Distinguishing attacks can be troublesome notwithstanding when the enemy is not endeavoring to hide them. Be that as it may, we might have the capacity to recognize causative attacks by utilizing an extraordinary test set. This test set could incorporate a few known intrusions and interruption variations, and also some irregular indicates that are comparable the intrusions. After the learner has been prepared, misclassifying a lopsidedly high number of intrusions could demonstrate bargains. To identify gullible exploratory attacks, a separate bunching calculation could be keep running against data ordered by the learner [11,12]. The sudden appearance of a huge cluster close to the choice limit could show systematic testing. This kind of protection is likened to port output detection, which has turned into a contest between port scanners and intrusion detection systems.
The steps involved in working of neuro-fuzzy inference system are as follows:
Step 1: Selection of input and output linguistic variable. Identify relevant input and output variable. Assign linguistic label to each variable. These variables are expressed using fuzzy set. The linguistic variables characterize the key features such as minimum bandwidth, hop
count, route selection, and probability and fuzzy sets labels these linguistic as low, high, small medium, etc. Then, select proper membership function for input and output variables.
Step 2: Applying fuzzification processes in this step, the crisp input is fuzzified with the help of membership function defined in the first step.
Step 3: Design of the fuzzy IF-THEN rule base. The set of IF-THEN rules is constructed to obtain the desired behavior of the system on the basis of knowledge of human expert. IF x is A, THEN y is B, where A and B are linguistic values of the linguistic variables x and y, respectively. To achieve the full functionality of the system, the rules can be kept on changing.
Step 4: Aggregation of rule output from inference engine is received by
aggregating the measurement of fuzzified input with the microtubule
neurons as described below: Compute:
SDij = Uj*Si*Dj
j j j=∑ e
Where Uj is the scan rate of the input, Si is the block of feed of input, and
Dj is the decomposition rate and j is the iterative index of each of the
episode of the decomposition of the pattern.
Update:
D
j j 1
i j e
S (e , T+ t)
=
∏
∆Where T is the new time for the decomposed pattern and ∆t is the
advancement in time.
Iterate backward Si−1, such that the scanned paragraph of text is
decomposed for the next step of SD association: Arg max (Si−1)=Si ⊕ tanh (jUj)
Step 5: Repeat steps 1-3 until SD converges to its minimal value.
Mobility and recursive patterns are considered as input and node traversal time or packet delivery rate is considered as the output linguistic variable for the proposed fuzzy controller. The fuzzy membership functions of all input and output parameters are divided into three subsets namely {low, medium, high}. In this work to define low, medium, high subsets, Gaussian membership function has been used because it has the advantage of being smooth and non-zero at all points. The use of microtubule neurons allows the nesting of the neuronal values for fuzzy-based spatial exploration local feedback inhibition of false negative data sets.
Distinguishing an attack gives the learner data about the attacker’s abilities. These data might be utilized to reformulate barrier strategies. As the enemy’s control over the data expands, the best strategy for the learner is to disregard conceivably corrupted data. Something else, the attacker can misuse lost trust. These thoughts have been formalized inside of the connection of duplicity recreations, which ordinarily accept all players know the degree to which different players might control data. In any case, if the gatherings gauge each other’s capacities, more complex strategies rise. In a few circumstances, the learner might have the capacity to change the data seen by the attacker. This strategy of disinformation has the objective of befuddling the attacker’s assessment of the learner’s state. In the least difficult case, the enemy would then be confronted with a circumstance much the same as a learner under an aimless causative accessibility attack. The objective of the learner is to keep the enemy from learning the choice limit. It would be ideal if you take note of how the parts of attacker and learner have been switched.
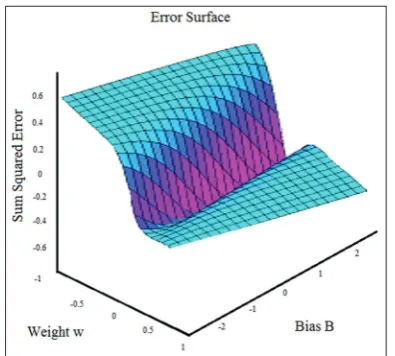
A more complex learner could trap the enemy into trusting that a specific interruption was excluded in the preparation set. This clearly Fig. 2: Performance plot of the proposed system where error
surface shows minute sum squared error for the bidirectional operation
learner changes its forecast function after some time, so an attacker has the chance to shape this change. Continuous causative attacks might be hard to recognize. To expand heartiness against causative attacks, we oblige the class of functions (theories) that the learner considers. The limitation we consider is the measurable strategy of regularization. Regularization expands the essential learning
allowed “interruption” would go about as a honeypot, bringing on the enemy to uncover itself. An expansion in the occurrence of that specific attack would be recognized, uncovering the presence of an attacker. For this situation, once more, parts would switch, and the enemy would confront a circumstance similar to a learner subjected to a focused on causative trustworthiness attack. Focused on attacks relies on the characterization of one point or a little arrangement of focuses. They are more delicate to varieties in the choice limit than unpredictable attacks since limit movement will probably change the grouping of the applicable focuses. This proposes randomization as a potential device against focused causative attacks. In such an attack, the attacker needs to do a specific measure of work to move the choice limit past the focused on the point. On the off chance that there is some randomization in the position of the limit and the attacker has defective input from the learner, more research work is required in this connection.
The more we think about the circulation of preparing data, the less room there is for an attacker to control the learner. The impediment, in any case, is that the true blue data have less impact in the learning process. A strain exists in the middle of expressivity and requirement: As the learner incorporates more former data, it loses adaptability to adjust to the data; however, as it incorporates more data from the data, it turns out to be more vulnerable to attack. This makes this tradeoff in the antagonistic situation and it turns out to be more important on the grounds that the attacker might have impact on the data. Randomization builds the enemy’s work, yet it additionally will expand the learner’s base error rate. Deciding the appropriate measure of randomization is an open issue.
Some machine learning systems are prepared by the end client, while others are prepared utilizing data from numerous clients or associations. The decision between these two models is now and then gives a role as a tradeoff between the measure of preparing data and the mystery of the subsequent classifier. This issue likewise applies to any interruption detection system; if this system is prepared every time and being sent, then it will have nearly little data in regard to ordinary network traffic. It will likewise have no opportunity to find out about novel intrusions before seeing them in nature. On the other hand, the system that uses a worldwide arrangement of guidelines would have the capacity to adjust to novel interruption endeavors all the more rapidly. Sadly, any enemy with access to an open IDS order function can test to guarantee that its interruption focuses will be acknowledged by deployments of the same characterization function.
These issues are incidents of a more broad issue. At times, it appears to be sensible to expect that the enemy has little access to data accessible to the learner. Notwithstanding, unless the enemy has no earlier learning about the learning issue nearby, we cannot expect the greater part of the data gave in the preparation set is mystery. In this manner, it is vague what amount is picked up by endeavoring to keep the preparation set, and in this way the condition of the classifier, mystery. Numerous systems as of now endeavor to accomplish a harmony in the middle of worldwide and neighborhood retraining. Systems that take this methodology can possibly beat systems that perform preparing at a solitary level. Be that as it may, the connections between multilevel preparing, the enemy’s area information, and secrecy is not yet surely known in the literature and this will be addressed on in our work.
RESULTS AND DISCUSSION
Interruption or peculiarity detection systems confront a key test of moving their results into significant reports for the network administrator. In numerous studies, we have observed an absence of this important last step, which we term the semantic gap. Tragically, in the interruption detection community, we locate a propensity to restrict the assessment of abnormality detection systems to an appraisal of a system’s capacity to dependably recognize deviations from the typical profile. At the same time, without a doubt contains a vital element for a sound study, the following step then needs to decipher the results from an administrator’s perspective—“What does
it mean?” Answering this inquiry goes to the heart of the distinction between discoveries “anomalous movement” and “attacks.” Those acquainted with inconsistency detection are typically the first to recognize that such systems are not focusing to distinguish malicious conduct but rather simply report what has not been seen sometime recently, whether benign or not. We contend however that one cannot stop by then. All things considered, the target of sending an interruption detection system is to discover attacks, and subsequently an identifier that does not take into consideration spanning this gap is unrealistic to meet operational desires. The regular involvement with abnormality detection systems delivering an excess of false positives underpins this perspective: By definition, a machine learning calculation does not commit any errors inside of its model of normality, yet for the administrator, it is the results’ elucidation that matters.
While tending to the semantic gap, one thought is the joining of nearby security strategies. While frequently dismissed in academic research, a crucial perception about operational networks is the extent to which they vary: Numerous security limitations are a site-particular property. Action that is fine in an academic setting can be banned in an endeavor network, and even inside a solitary association, division approaches can contrast generally. In this manner, it is urgent to suit such contrasts. For an abnormality detection system, the characteristic strategy to address site-specifics has the system “learn” them amid preparing with typical traffic. In any case, one cannot just affirm this as the answer for the subject of adjusting to various locales; one needs to expressly demonstrate it since the center issue worries that such varieties can demonstrate assorted and barely noticeable. Lamentably, as a rule, security strategies are not characterized freshly on a specialized level. For instance, a domain may tolerate shared traffic that the length of it is not utilized for conveying improper substance and that it stays, “underneath the radar” regarding volume. To report an infringement of such a strategy, the intrusion detection system would need a thought of what is considered “suitable” or “horrifyingly extensive” in that specific environment; a choice out of span for any of today’s systems. Reporting only the utilization of P2P applications is likely not especially valuable unless the earth level out bans such use. As far as we can tell, such dubious rules are really regular in numerous situations, and in some cases, begin in the uncertain lawful dialect found in the “terms of administration” to which clients must concur. The fundamental test with respect to the semantic gap sees how the components the oddity detection system operates on identify with the semantics of the network environment. Specifically, for any given decision of elements, there will be a basic point of confinement to the sort of determinations can create from them. Coming back to the P2P sample, while looking at just network stream records, it is difficult to envision how one may spot wrong substance. As another illustration, consider exfiltration of personally identifying information (PII). In numerous risk models, loss of PII positions entirely high as it has the potential for bringing about significant harm (either straightforwardly, in money-related terms, or because of exposure or political aftermath). On a specialized level, a few types of PII are not that difficult to depict, for example, government-managed savings numbers too ledger numbers take after particular plans that one can check naturally. Be that as it may, an oddity detection system created without such portrayals has little any desire for discovering PII, and even given cases of PII and non-PII will probably experience issues refining rules for accurately recognizing one from the other.
CONCLUSION
REFERENCES
1. Lee W, Salvatore J. Mining audit data to build intrusion detection models. In: Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; 1998. p. 66-72.
2. Lunt T. Detecting intruders in computer systems. In: Proceedings of Auditing and Computer Technology Conference; 1999. p. 23-30. 3. Ryan J, Lin M, Miikkulainen R. Intrusion detection with neural
networks. In: Advances in Neural Information Processing Systems. Vol. 10. Cambridge: MIT Press; 1998.
4. Bridges S, Vaughn R. Fuzzy data mining and genetic algorithms applied to intrusion detection. In: Proceedings of the National Information Systems Security Conference; 2000. p. 8-15.
5. Hofmeyr S, Forrest S, Somayaji A. Intrusion detection using sequences of system calls. J Comput Secur 1998;6:151-80.
6. Balasubramaniyan J, Fernandezm J, Isacoff D, Spafford E. An architecture for intrusion detection using autonomous agents. In:
Proceedings of the Annual Computer Security Applications Conference; 1998. p. 13-24.
7. Crosbie M. Applying genetic programming to intrusion detection. In: Proceedings of AAAI Fall Symposium Series; 1995. p. 45-52. 8. Sequeira K, Zaki M. ADMIT: Anomaly-base data mining for intrusions.
In: Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; 2002. p. 45-56.
9. Gomez J, Dasgupta D, Nasraoui O. Complete expression trees for evolving fuzzy classifiers systems with genetic algorithms and application to network intrusion detection. In: Proceedings of the NAFIPS-FLINT Joint Conference; 2002. p. 469-74.
10. Rai A. Secure two party computation. J Adv Shell Program 2014;1(2):5-6.
11. Rai A, Sakkaravarthi R. Distributed learning in networked controlled cyber physical system. Int J Pharm Technol 2016;8(3):18537-46. 12. Rai A. Unsupervised probabilistic debugging. Recent Trends Program