Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2841
Crawling Hidden Objects in web Search Interface with KNN
Queries
JAMMI SATYA KEERTHI, DR.Y.S.KOTESWARA RAO, DR.G.GURU KESAVA DAS P G Student, Dept. Of CSE, Eluru College Of Engineering & Technology, Duggirala Assistant Professor, Dept. Of CSE, Eluru College Of Engineering & Technology, Duggirala Professor & Head of the Department, Dept. Of CSE, Eluru College Of Engineering & Technology,
Duggirala
Abstract: This places of business the issue of crawling all things profitably from a LBS webpage, through individuals all in all kNN web look interface it gives. Specifically, we make crawling algorithm for 2D and
higher-dimensional spaces, independently, and
appear through speculative examination that the overhead of our algorithms can be restricted by a segment of the amount of estimations and the amount of crawled articles, paying little personality to the essential allocations of the things. We moreover stretch out the algorithms to utilize
circumstances where certain partner
information about the essential data scattering, e.g., the people thickness of a zone which is frequently emphatically connected with the thickness of LBS things, is available.
Keywords: Information and Communications
Technology, Location based Searching
technique, LBS server, kNN queries, crawling objects.
1. INTRODUCTION
With rapidly creating commonness, Location Based Services (LBS), e.g., Google Maps, Yahoo Local, We Chat, Four Square, et cetera,
started offering electronic interest incorporates that take after a kNN request interface. Specifically, for a customer decided request region q, these locales remove from the things in its backend database the best k nearest neighbors to q and give back these k articles to the customer through the web interface. Here k is frequently a little regard like 50 or 100. For example, Mc-Donald's benefits the fundamental 25 nearest restaurants for a customer demonstrated region through its territories look site page. While such a kNN examine interface is routinely sufficient for an individual customer looking for the nearest shops or restaurants, data specialists and masters excited about a LBS advantage much of the time look for a more expansive point of view of its key data. For example, an agent of
the drive-thru food industry may be
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2842 brief span later a data inspector can simply see
the crawled data as a detached database and play out whatever examination activities liked.
Here "crawling" is widely portrayed, i.e., it can imply the extraction of all things from the database, or simply those articles that satisfy certain assurance conditions, in light of the fact that such conditions can be "experienced" to the kNN interface. For example, if the target here is to crawl Google Maps, at that point the objective may be to crawl each Vietnamese diner in Washington, DC. One can see that this condition can be viably experienced to Google Maps by binding request territories to be from Washington, DC, and deciding "Vietnamese restaurants" as the chase keyword1. Note that the key particular test for crawling through a kNN interface is to restrain the amount of inquiries issued to the LBS advantage. The essential is realized by confinements constrained by most LBS organizations on the amount of inquiries allowed from an IP address or a customer account (if there ought to be an event of an API organization, for instance, Google Maps) for a given day and age (e.g., multi day). For example, Twitter obliges the request rate at 180 inquiries for each 15 minute. Clearly, no count can accomplish the endeavor without issuing in any occasion n=k questions, where n is yield gauge (i.e., the amount of crawled things), in light of the fact that every request returns at most k of the n objects. Everything considered, we will without a doubt have a yield delicate estimation, which regardless should have an inquiry cost as close n=k as could be permitted.
2. PROBLEM DEFINITION
We have shown our frameworks for crawling kNN based databases. With the proposed approach, we can totally slither all motivations behind a database with kNN interface in 2-D space with cost under O(n2), self-sufficient of the point spread in the space. Another issue shared by both existing systems is that they simply take a shot at 2D spaces, anyway not higher-dimensional spaces that reveal a kNN interface. Moved by the insufficiencies of the present methods, we make 2D and higher-dimensional crawling algorithms for kNN interfaces in this paper, with the guideline responsibilities delineated as takes after: We start with watching out for the kNN sneaking issue in 1-D spaces, and propose a 1-D crawling algorithm with upper bound of the inquiry cost being O(n=k), where n is the amount of yield articles, and k is the best k imprisonment. We by then use the 1D algorithm as a building block for kNN crawling more than 2-D spaces, and present speculative examination which exhibits that the inquiry cost of the figuring depends just on the amount of yield articles n anyway not the data scattering in the spatial space.
3. LITERATURE SURVEY
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2843 Web. We have produced DeepBot, a model
hid web crawler prepared to get to such substance. DeepBot gets as data a course of action of room definitions, each one depicting a specific data gathering undertaking and normally perceives and makes sense of how to execute inquiries on the structures apropos to them. In this paper we depict the strategies used for building DeepBot and report the test happens got when testing it with a couple of bona fide data gathering endeavors.
We show a system called DEQUE (Deep
WEbQUerySystEm) for showing and
scrutinizing the significant Web. We propose a data show for addressing and securing HTML outlines, and a web shape request lingo called DEQUEL for recuperating data from the significant Web and securing them in the design favorable for additional taking care of. Our system can address shapes (single and consecutive) with data regards from relations and from result pages (delayed consequences of addressing web outlines). We show a novel approach in exhibiting of persistent structures and present the possibility of the super shape. A model system has been executed on a SUN workstation working under Solaris 2.7 using Perl variation 5.005_2 and using MySQL (adaptation 3.23.49) DBMS as the data stockpiling.
Significant web creep is stressed with the issue of surfacing covered substance behind interest interfaces on the Web. While some significant destinations keep up report arranged artistic substance (e.g., Wikipedia, PubMed, Twitter, et cetera.), which has for the most part been the convergence of the
significant web composing, we watch that a gigantic piece of significant locales, including all online shopping districts, priest sorted out components instead of substance records. Disregarding the way that crawling such
substance organized substance is
unquestionably significant for a combination of purposes, existing crawling strategies streamlined for document arranged substance are not most suitable for component arranged areas. In this work, we portray a model structure we have produced that has some mastery in crawling component orchestrated
significant destinations. We propose
methodology exclusively fitted to deal with indispensable subproblems including question period, release page filtering and URL deduplication in the specific setting of substance arranged significant destinations. These methods are likely surveyed and had all the earmarks of being practical.
4. PROPOSED SYSTEM
We make crawling algorithm for 2D and higher-dimensional spaces, exclusively, and display through speculative examination that the overhead of our algorithms can be restricted by a component of the amount of estimations and the amount of crawled articles, paying little regard to the fundamental disseminations of the items. At that point we
develop our OPTIMAL-1D-CRAWL
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2844 motivations behind the database if the point
thickness in the area changes not too much. We similarly attempted the proposed crawling algorithms on the veritable enlightening accumulations Yahoo Local in 2-D space and Eye-glasses in 4-D space. We depict the unobtrusive components of these datasets independently as takes after, this algorithm was proposed in work. To our best data, this algorithm is the best in class of crawling algorithm for kNN based databases in 2-D space. In their work, the makers completed a methodology, called constrained delaunay triangulation, to reliably distribute uncovered areas into triangles, by then issued the new request on the point of convergence of the best triangle.
OPTIMAL-1D-CRAWL ALGORITHM
The detail of this OPTIMAL-1DCRAWL algorithm is exhibited in Algorithm 1. This algorithm focuses on the midpoints of revealed areas while the already portrayed covering algorithm focuses on the limits of revealed districts - simply this unpretentious distinction prompts on a very basic level diverse query intricacy comes about.
Algorithm 1: OPTIMAL-1D-CRAWL
Algorithm
DBSCAN for grids clustering:
This paper presented another algorithm
GRPDBSCAN (Grid-based DBSCAN
Algorithm with Referential Parameters). GRPDBSCAN, which accumulate the matrix segment system and various thicknesses in light of the grouping algorithm, enhanced its effectiveness. Then again, the Eps and Minpts parameters of the DBSCAN algorithm were they auto-produced, more target.
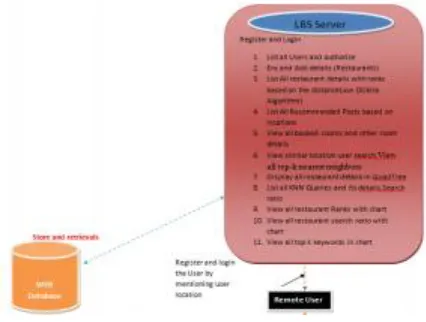
Figure 1: Architecture Diagram
Objective of the project:
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2845 (Crawling Nearest Neighbor) web search
strategy, with the goal that subsequently information searchers can just regard the searched information as a disconnected database and play out whatever symptomatic activities it wanted. Here "creeping" (searching) is for the most part characterized, i.e., it can allude to the extraction of all articles from the database, or just those items that fulfill certain choice conditions, inasmuch as such conditions can be "went through" to the kNN interface.
5. CONCLUSION
In this paper, we center the issue of crawling the LBS through the bound kNN look interface. However shrouded fixations by and large exist in 2-D space, there are several usages with focuses in higher dimensional spaces. We develop the 2-D crawling figuring to the general m-D space, and give the m-D crawling calculation with hypothetical upper bound examination. For 2-D space, we inspect outside making sense of how to update the crawling execution. The exploratory outcomes demonstrate the abundancy of our proposed estimations. In this review, the proposed figurings creep information request by given a square shape (solid shape) in the spatial space. In the general circumstance when the obliged territory of the things is sporadic, it can be pre-appropriated a game-plan of square shapes (3D squares) before utilizing the structures proposed in this paper.
REFERENCES
[1] L. Barbosa and J. Freire, “Siphoning hidden web data through keyword-based interfaces,” in SBBD, 2004, pp. 309– 321.
[2] A. Ntoulas, P. Pzerfos, and J. Cho, “Downloading textual hidden web content through keyword queries,” in Digital Libraries, 2005. JCDL’05. Proceedings of the 5th ACM/IEEE-CS Joint Conference on. IEEE, 2005, pp. 100– 109.
[3] K. Vieira, L. Barbosa, J. Freire, and A. Silva, “Siphon++: a hidden-web crawler for keyword-based interfaces,” in Proceedings of the 17th ACM conference on Information and knowledge management. ACM, 2008, pp. 1361–1362.
[4] L. Jiang, Z. Wu, Q. Feng, J. Liu, and Q. Zheng, “Efficient deep web crawling using reinforcement learning,” in Advances in Knowledge Discovery and Data Mining. Springer, 2010, pp. 428–439.
[5] S. Raghavan and H. Garcia-Molina, “Crawling the hidden web,” in VLDB 2001, Proceedings of 27th International Conference on Very Large Data Bases, September 11-14, 2001,Roma, Italy, 2001, pp. 129–138.
[Online]. Available:
http://www.vldb.org/conf/2001/P129.pdf
[6] S. W. Liddle, D. W. Embley, D. T. Scott, and S. H.Yau, “Extracting data behind web forms,” in Conceptual Modeling - ER 2002, 21st International Conference on Conceptual Modeling, Tampere, Finland, October 7-11,
2002, Proceedings,2002, pp. 402–413.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2846 [7] P. Wu, J. Wen, H. Liu, and W. Ma, “Query
selection techniques for efficient crawling of structured web sources,” in Proceedings of the 22nd International Conference on Data Engineering, ICDE2006, 3-8 April 2006, Atlanta, GA, USA, 2006,p.47. [Online].
Available: http://dx.doi.org/10.1109/ICDE.
2006.124
[8]Mcdonalds, “Mcdonalds page,
http://www.mcdonalds.com/,” [Accessed:
Aug.6, 2014]. [Online]. Available: nurlfhttp:
//www. mcdonalds.com/us/en/ restaurant
locator. htmlg
[9] S. Byers, J. Freire, and C. T. Silva, “Efficient acquisition of webdata through restricted query interfaces,” in Poster Proceedings of the Tenth International World Wide Web Conference, WWW 10, Hong
Kong, China, May 1-5, 2001,
2001.[Online].Available:
http://www10.org/cdrom/posters/105 1.pdf
[10] W. D. Bae, S. Alkobaisi, S. H. Kim, S. Narayanappa, and C. Shahabi, “Web data retrieval: solving spatial range queries using
k-nearest neighbor searches,” Geo
informatica, vol. 13,no. 4, pp. 483–514, 2009.
[11]G. E. Glasses,
“Greateyeglassespage,http://www.greateyegla sses.com/shop/search.php,” [Accessed: Jan.
20, 2014]. [Online]. Available:
nurlfhttp://www.greateyeglasses.com /shop/search.phpg
[12]Yahoo,“Yahoolocalpage,
https://local.yahoo.com/,” [Accessed: Dec.
2012]. [Online]. Available: nurlfhttps://local. yahoo.com/g