ABSTRACT
DESHPANDE, AMEY S. Online Erasure Coding in Distributed Storage Systems. (Under the direction of Xiaosong Ma.)
Multi-node data-intensive computing systems such as MapReduce heavily rely on data repli-cation in order to achieve fault tolerance and to ensure data availability. However, replirepli-cation is expensive. Each redundant replica results in 100% storage overhead. Moreover, the replication process is intensive on network bandwidth consumption. These factors contribute to higher energy consumption in any typical data-center like scenario.
Online Erasure Coding in Distributed Storage Systems
by
Amey S. Deshpande
A thesis submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Master of Science
Computer Science
Raleigh, North Carolina
2010
APPROVED BY:
Frank Mueller Xuxian Jiang
Xiaosong Ma
DEDICATION
BIOGRAPHY
ACKNOWLEDGEMENTS
I would like to thank my advisor Dr. Xiaosong Ma for her support, guidance and encouragement throughout my graduate studies. I would also like to thank my committee members Dr. Frank Mueller and Dr. Xuxian Jiang for their guidance. I especially thank Dr. Zhe Zhang with whom I have worked closely for this work. I am grateful to the members of Systems Research group – Divya Dinakar, Karthik Vijayakumar, Jagan Srinivasan, Manav Vasavada, Feng Ji, Fei Meng, Abhishek Sreenivasa, and others for their cooperation and valuable inputs along with all the fun we had while working together. I am obliged to my friends at NCSU – Anup Mokashi, Sourabh Alurkar, Sameer Majithia, Sharad Bade and Nikhilesh Dwivedi who made my graduate life an enjoyable experience. I also thank Dr. Sailesh Krishnamurthy for offering me a Summer internship at Truviso, Inc., which has helped in shaping my research and career interests.
TABLE OF CONTENTS
List of Figures . . . vii
Chapter 1 Introduction . . . 1
1.1 Motivation . . . 1
1.2 Research Overview . . . 2
1.2.1 Problem Definition . . . 2
1.2.2 Summary of Contributions . . . 2
1.3 Thesis Outline . . . 3
Chapter 2 Background. . . 4
2.1 Hadoop Distributed File System (HDFS) . . . 4
2.1.1 Architecture . . . 4
2.1.2 Fault-tolerance . . . 4
2.1.3 Interface . . . 5
2.2 Erasure Coding . . . 6
2.2.1 Mapping Erasure Coding to HDFS . . . 6
2.3 Related Work . . . 7
2.3.1 Erasure Coding vs. Replication . . . 7
2.3.2 Miscellaneous Work . . . 8
Chapter 3 Online Erasure Coding for HDFS. . . 9
3.1 Online Erasure Encoder . . . 9
3.1.1 Unit of Encoding . . . 10
3.1.2 Location of Fragments . . . 10
3.1.3 Per-file Configurability . . . 10
3.1.4 “Push” vs. “Pull” Model . . . 11
3.1.5 Handling Parity-unprotected Blocks . . . 13
3.1.6 Efficiency . . . 14
3.2 Erasure Decoder . . . 14
3.2.1 On-the-fly Decoding . . . 15
3.2.2 Persistent Recovery . . . 15
3.3 Complete Erasure Codec . . . 16
Chapter 4 Implementation of HDFS Extensions . . . 18
4.1 Objectives . . . 18
4.1.1 Online Encoder . . . 18
4.1.2 Decoder . . . 19
4.2 Online Erasure Encoder . . . 19
4.2.1 Encoder Extensions . . . 20
4.3 Erasure Decoder . . . 22
4.4 Codec Library . . . 24
Chapter 5 Evaluation . . . 25
5.1 Staging-in . . . 26
5.2 Analytical Workloads . . . 27
5.2.1 Wordcount . . . 28
5.2.2 Sort . . . 29
5.2.3 CloudBurst . . . 30
5.3 Failure Analysis . . . 31
5.3.1 Staging-out . . . 32
5.3.2 Analytical Workloads . . . 32
5.4 Complexity Analysis . . . 36
5.4.1 State Dependencies . . . 36
5.4.2 Code Complexity . . . 37
Chapter 6 Conclusions. . . 38
LIST OF FIGURES
Figure 2.1 A typical HDFS cluster setup [11] . . . 5
Figure 3.1 Offline block-level 3-of-5 erasure encoding scheme . . . 12
Figure 3.2 Online block-level 3-of-5 erasure encoding scheme . . . 13
Figure 3.3 Complete erasure codec design showing 3-of-5 coding scheme . . . 16
Figure 4.1 Layout of a packet in HDFS. . . 20
Figure 5.1 Staging an 8GB file into HDFS using 10 datanodes . . . 26
Figure 5.2 Performance ofwordcount workload with 8GB input on 10 worker nodes 28 Figure 5.3 Performance ofsort workload with 8GB input on 10 worker nodes . . . . 29
Figure 5.4 Performance ofCloudBurst with 4GB input file on 10 worker nodes . . . 30
Figure 5.5 Performance of reading 8GB file sequentially from 10 datanodes during failure . . . 31
Figure 5.6 Performance ofwordcount with 8GB input dataset on 10 datanodes dur-ing failure. . . 32
Figure 5.7 Performance of sort with 8GB input dataset on 10 datanodes during failure. . . 33
Figure 5.8 Performance of CloudBurst with 4GB input dataset on 10 datanodes during failure. . . 34
Figure 5.9 Penalties due to failure within respective redundancy schemes . . . 34
Chapter 1
Introduction
1.1
Motivation
Modern data centers have to store and analyze petabytes of data, if not more. The sources that generate such massive amounts of data are varied, ranging from financial market transaction updates, web-based service providers and content-provider companies like Amazon, Facebook, Microsoft, and Google. Their data rates often range from tens to hundreds of gigabytes per hour [5]. In addition to such “user-facing” data, scientific experiments and simulations in fields such as astronomy, bioinformatics, paritcle physics produce data sizes ranging from hundreds of terabytes to petabytes per year [20].
There is a demand for analytical jobs that dig into such humongous datasets to gain insights about the data contents. For example, Google is widely known to serve content-aware adver-tisements in users’ inboxes. Other examples include background scanning on mail servers for spam-detection and de-duplication. In the past few years, novel paradigms for distributed com-puting such as MapReduce [8] and Dryad [22] have gained popularity in industry for analytical workloads. Leveraging such elastic analytics models, incrementally scalable “shipping code to data” frameworks are built for data center-like scenarios. Such systems handle combinations of foreground and analytical jobs, and can be termed as Data Intensive Scalable Computing systems (DISC [4]). Within these frameworks, data, computation, and network interconnect co-exist on the hosts, where moving computation is assumed to be cheaper than moving data [18].
replication is expensive, in terms of storage space occupied and network bandwidth consumed. These factors may also contribute to higher energy costs [25]. As an alternative to replication, erasure coding has been considered potentially more efficient and has attracted a great amount of research [1, 16, 19, 26, 29, 32, 33, 35, 37, 38]. By definition, anm-of-nerasure coding scheme encodesmunits of data intonunits such that anymof them can reconstruct the original data. While 3-way replication and 3-of-5 erasure coding both tolerate 2 faults, the former requires 3× storage consumption, while the latter only requires 1.6×. That is, less amount of data is written over network onto storage while ensuring the same degree of fault-tolerance.
1.2
Research Overview
1.2.1 Problem Definition
While the potential of erasure coding for storage and network savings over replication is clear, why is erasure coding not used commonly in practice in MapReduce systems? We understand that there are more complex trade-offs involved when it comes to DISC-like scenarios. A key point is that DISC workloads are diverse in their read-write requirements. Although erasure coding is the clear winner for write-intensive workloads, the benefits of erasure coding are not obvious when the workloads are either read-intensive or combinations of both. Moreover, industry developers tend to perceive erasure coding as “complex” since the mechanism is not as simple as replication. In our work, we provide a comprehensive discussion on application scenarios and evaluation metrics, and conduct a quantitative comparison between erasure coding and replication with several representative applications on a realistic platform.
In order for erasure coding to be realistically evaluated, it is essential to develop an erasure codec library for a state-of-the-art DISC file system. We use HDFS, Hadoop Distributed File System [18], as a case study. HDFS is functionally equivalent to the Google File System [11] and is used in Hadoop [15], Apache’s open-source implementation of Google’s MapReduce model [8]. Most importantly, Hadoop forms an interesting case as it is widely used in the production systems of companies like Facebook, Yahoo!, Amazon, and many others to crunch large amounts of data [14]. In this thesis, we develop an erasure codec library for HDFS and examine its effectiveness using several typical MapReduce workloads. A more detailed introduction of Hadoop and HDFS is given in section 2.1.
1.2.2 Summary of Contributions
1. The author proposed an online erasure encoder design for HDFS.
2. The author implemented a complete erasure codec extension to HDFS, including on-the-fly decoder and persistent recovery mechanisms.
3. The author carried out extensive tests using several synthetic and real-world workloads under various failure situations, and performed detailed comparisons of erasure coding scheme with the default replication policy in HDFS.
We have performed this work in collaboration with Dr. Zhe Zhang from Oak Ridge Na-tional Laboratory, and Dr. Eno Thereska and Dr. Dushyanth Narayanan from Microsoft Research Cambridge. Listed above are the individual contributions of the author, with guide-lines from collaborators about original problem statement, choice of workloads, and selection of application-independent metrics.
1.3
Thesis Outline
Chapter 2
Background
2.1
Hadoop Distributed File System (HDFS)
2.1.1 Architecture
HDFS [18] is a functional equivalent of the Google File System [11]. It has been designed to suit huge file sizes (order of gigabytes and more) and follows a master-slave paradigm. The file data is stored on slave nodes, also known as datanodes. We use these terms interchangeably in our discussion. The files are divided into smaller chunks, also known as blocks. Each block is a regular file on datanode, managed on disk by the operating system. That is, HDFS is an application-level file system. HDFS views files as collections of such blocks. The master, also known as the namenode, stores metadata of the entire filesystem, such as list of files, file-to-blocks mapping, locations of file-to-blocks for each file on datanodes and so on. HDFS provides a filesystem interface to applications in the form of aclient. For file accesses, client interacts with the namenode for metadata, and communicates with the datanodes for file data. Since HDFS deals with files typically multi-GB in size, the size of a block is large, in the order of MBs, typically 64MB. Figure 2.1 shows the architecture of HDFS with various interactions between a client, the namenode and datanodes.
2.1.2 Fault-tolerance
Figure 2.1: A typical HDFS cluster setup [11]
failures through periodicheartbeat messages. If the master notices that a certain datanode has failed, it initiates a re-replication process on per-block basis, in which the number of “live” replicas of blocks on the failed datanodes are restored using the reachable copies. To counter against different levels of failures, such as disk, node, power and network switch failures, the blocks are replicated across datanodes and across racks. The block placement policy dictates that when 3×replication is used, a replica of a block is placed on a datanode in the same rack, while another replica is placed on a datanode in some other rack. The namenode can potentailly rebalance the cluster to ensure load distribution. However, the implementation work is ongoing [18].
2.1.3 Interface
2.2
Erasure Coding
As discussed in chapter 1, erasure coding is another way to improve data reliability and avail-ability in a distributed file system. With erasure encoding, m fragments of data are encoded to producenfragments, wheren > m. The encoding function is such that the original mdata fragments can be reconstructed using any available m among the n fragments, by a process called erasure decoding. The rate of encoding is the ratio r = mn < 1. Such coding scheme
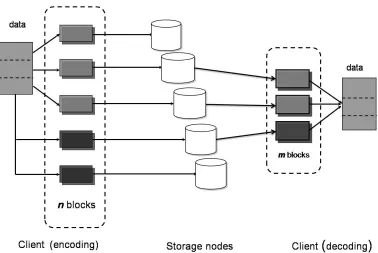
requires 1r× higher storage space. Since the original m fragments can be reconstructed using any m fragments, an m-of-n erasure coding scheme can sustain upto (n−m) lost fragments (i.e. (n−m) erasures). This is the degree of fault tolerance. For example, a 3-of-5 erasure coding scheme can tolerate upto two missing fragments. It is interesting to note that N-way replication can be viewed as a special case of erasure coding, where m = 1 and n = N. By virtue of the coding function and values ofmand n, erasure coding can achieve significant sav-ings on storage space as compared to replication. The actual process of erasure coding involves knowledge of an array of mathematical concepts and operations. A comprehensive overview of erasure coding theory and techniques is given in select publications [27, 29, 37].
2.2.1 Mapping Erasure Coding to HDFS
In our work, we apply the existing erasure coding theory and techniques to the case of HDFS. While doing so, we have to carefully map the concepts from erasure coding to the architecture of HDFS.
Fragment Size and Locations
Coding Function
The choice of erasure coding function is another important factor. Simple functions like XOR cannot ensure protection against multiple failures at a time. We resort to more complicated functions of Reed-Solomon codes [30] and its extensions [17, 28, 21]. We use software RAID-6 as our base case, which can sustain upto two failures at a time. We extend our system to be able to tolerate larger number of faults. We choose a Cauchy-Reed-Solomon coding technique based on the performance analysis presented by Plank et al. [27, 29]
2.3
Related Work
In the previous sections we gave an overview two key components of our work – HDFS and erasure coding and introduced existing related work on them. In this section, we discuss some of the existing work on replication versus erasure coding under various storage requirements.
The closest existing work to our work is DiskReduce [10] that has led to HDFS-RAID [9]. It modifies HDFS to compress 3× replicated data using erasure coding. The key idea here is to perform delayed, asynchronous encoding on the data and recover storage space by RAID-5 or RAID-6 style encoding schemes. The encoding is performed by employing a “pull” model in which one datanode fetches m data blocks from and writes (n−m) blocks out to HDFS. The main motivation behind this work is to save storage savings on “archived” data. However, a major disadvantage of this approach is the network bandwidth utilized during background encoding, essentially because of the “pull” nature. Also, initially the data is replicated, 3×
by default, adding to the network and disk usage, although the disk space is later reclaimed partially. We follow a “push” model to perform erasure encoding aggressively, online, in the critical access path of HDFS for optimal network bandwidth and storage space utilization. We present a detailed discussion of “push” vs. “pull” model in section 3.1.
2.3.1 Erasure Coding vs. Replication
Replication and erasure coding are compared in a peer-to-peer distributed storage scenario based on the trade-offs in availability and read latency, and the complexity associated with erasure coding [32]. Choice of values ofm andnin anm-of-ncoding scheme, and their impact on CPU and network demand, have been studied in literature [35]. Weatherspoon et al. have performed quantitative analysis of disk and bandwidth requirements for replication and erasure coding in case of peer-to-peer storage systems [37]. We compare erasure coding with replication in a significantly different case of data-intensive computing in data-center environments, and present workload-dependent and workload-independent trade-offs.
space savings from such codes – the motivation behind our work – are valued in AutoRAID [38]. Ursa Minor [1] demonstrates the performance improvement resulting from workload-dependent encoding schemes and fault-models as compared to a single, more general configuration in a cluster-based storage system. FAB [33] proposes a fully distributed cluster storage architecture based on commodity hardware. It uses replication and erasure coding to ensure fault-tolerance and data availability, which is a key principle of HDFS design. Glacier [16] uses erasure coding to save on storage cost while providing massive redundancy in presence of highly correlated failures. Various failure recovery schemes in software RAID systems and associated trade-offs on data availability have been studied [3]. Pond, the OceanStore prototype [31] uses erasure coding as an alternative to replication to save storage space and studies its effects on write throughput and read latency in an incrementally-scalable, Internet-scale distributed storage system. Hendricks et al. [19] show that erasure coding can achieve higher throughput for large writes as compared to replication, and present a Byzantine fault-tolerant protocol for distributed storage system based on erasure coding. Our work focuses on the cluster-based environment where computation coexists with data storage, and the trade-offs of erasure coding versus replication on “non-archival” workload performance tend to be more complex.
2.3.2 Miscellaneous Work
Chapter 3
Online Erasure Coding for HDFS
We presented an overview of HDFS in section 2.1. In this chapter we present the design of the core components of our erasure codec system. Section 3.1 presents a brief description of how an application writes a file to HDFS and extends it to perform online erasure encoding. Section 3.2 provides an overview of read operation of HDFS. We enhance it to perform two types of decoding –on-the-fly recovery and persistent recovery.
3.1
Online Erasure Encoder
An application uses a client to interact with HDFS. While writing to a file sequentially, the client establishes connection with datanodes on per-block basis and interacts in granularity of packets (typically 64KB each). Multiple such packets make up a block. For each new block corresponding to the file, the client contacts the namenode to receive relevant metadata – block identifier and destination datanodes. For the rest of write operation, it only deals with the datanodes. A more detailed discussion of packet-level interaction is provided in section 4.2.
For a scalable distributed file system,append can be a complicated operation. A key factor here is the large block size of HDFS. The append algorithm will have to consider whether the last block of the existing file is completely filled. If it is completely filled, the append operation can proceed with a new (empty) block. If it is not, the append operation may have to continue with the last block until it is complete. In both cases, consistency of the file needs to be maintained [11]. HDFS follows the model ofwrite-once-read-many for files. As a result, it does not support random write operation. It is consistent with the design philosophy of the Google File System, which regards random writes as “practically non-existent” [11]. Therefore, a potential argument that erasure coding could be expensive for read-modify-write access sequence associated with random writes does not hold for the case of HDFS.
discuss potential design alternatives and justify our choice for each factor. While choice of unit of encoding depends upon the locations of coded fragments, other factors are independent of each other. However, each of them plays a key role in the effectiveness of overall encoder design.
3.1.1 Unit of Encoding
We discussed in section 2.2 that the encoding is performed on fragments. Before discussing other design parameters, we determine the appropriate fragment in HDFS on which encoding can be performed. There are two entities involved in write operation – packets and blocks. We consider them as choices for encoding fragment. By choosing a packet as the unit of encoding, we mean that m packets from a block can be encoded to yield (n−m) additional packets. On the other hand, by choosing a block as the unit, we mean thatmdistinct blocks can be encoded to yield (n−m) additional blocks. In HDFS, the choice of coding fragment is constrained by its locations.
3.1.2 Location of Fragments
To ensure fault-tolerance against node-failures (due to disk, node, network and power failures), the n fragments resulting from encoding m fragments have to be written to distinct storage units. HDFS considers a datanode as monolithic unit of storage. It does not distinguish between multiple storage devices, which may be attached to each single datanode. Thus the choice of unit of encoding should be such that then fragments can reside on ndistinct datanodes.
The HDFS design dictates that all packets belonging to a block have to be written consec-utively on the same datanode. Hence, packets from the same block cannot be used to perform encoding without changing the HDFS design constraints on packet placement. On the other hand, there are no such constraints on locations of distinct blocks. Also, the namenode views a block as the fundamental storage unit of files and does not recognize packets within a block. As a result, we use a block as the unit of encoding. We encodem data blocks to produce (n−m) “parity” blocks. We ensure that such nblocks reside on ndistinct datanodes. While choosing n datanodes, we rely on the namenode’s block placement policy to maintain load balance in the cluster.
3.1.3 Per-file Configurability
makingnmuch larger than m. Hot-spots can be avoided by combining replication and erasure coding. In order to accommodate such requirements, users should be able to choose encoding schemes for special files independent of other files and irrespective of default values.
Such per-file configurable coding scheme puts certain constraints on which blocks can be encoded together to yield parity blocks. Potentially, an encoder scheme can collectany mdata blocks based on locality and produce (n−m) parity blocks. Per-file scheme demands that the blocks belonging to the same file can only be encoded together. As a result, the encoder must locate and fetch blocks corresponding to the same file, and cannot simply rely on locality of blocks.
3.1.4 “Push” vs. “Pull” Model
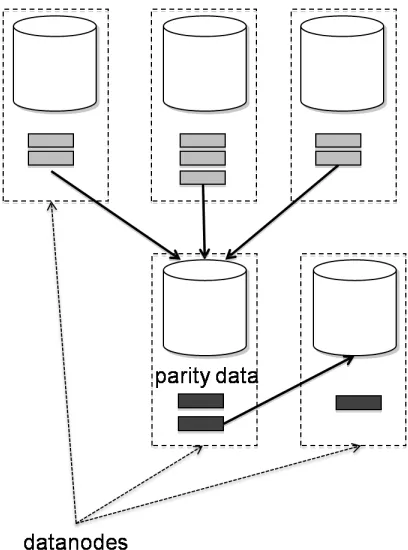
For a distributed file system, there are two possible models to perform erasure encoding. Online encoding is a “push” model where the data and parity blocks are sent to datanodes by the data source. The data source performs the encoding computations in such case. In a “pull” model, the source only writes data blocks to the file system. It need not be aware of erasure encoding scheme. The data blocks in file system are later read asynchronously to perform erasure encoding in the background. The “pull” model forms the basis for offline erasure encoding. Let us consider the trade-offs ofonline andofflineencoding schemes with an example wherem= 3 and n= 5 for m-of-ncoding scheme, as follows.
“Pull” Model
Figure 3.1: Offline block-level 3-of-5 erasure encoding scheme
“Push” Model
An online encoder, on the other hand, aggressively writes two parity blocks per three data blocks generated at source, as soon as they are generated. The data source can be a workload running on either a host external to the cluster, or a datanode, by virtue of “ship code to data” paradigm. Per-file configurable coding scheme favors such encoding since generally a single application writes to a file sequentially. Effectively, the data source ends up writing 53× data to file system. It means that the network interface of the writer node can potentially become a bottleneck. Also, the encoding computations performed on the source host may compete for system resources (E.g. CPU time) with applications running, if any. Figure 3.2 depicts a case of online erasure encoder. Here it is assumed that a hostexternal to the HDFS cluster is the data source and performs the encoding. Hence all data and parity blocks are written over network to datanodes.
!"#$%!&'
()!"*%#!'
original
data
parity
data
storage
nodes
g
ro
u
p
Figure 3.2: Online block-level 3-of-5 erasure encoding scheme
3.1.5 Handling Parity-unprotected Blocks
The per-file coding scheme works well when the size of a file is multiple of (blocksize∗m) bytes. This may not be the case always. The lastf ilesize- modulo - (blocksize∗m) bytes will not have any parity blocks associated with them. As a result, they require special handling. One option is to generate dummy data to to fill the incompletem-block group, and use the complete group for erasure encoding. This may require corresponding changes in the read interface of the client to ensure that the application does not accidentally receive the dummy data. Alternatively, we can fall back to replication for such blocks that could not be parity-protected. In such case, we require (n−m) additional copies of parity-unprotected blocks to ensure the degree of fault-tolerance. None of the two schemes is a clear winner as the storage trade-offs depend on values ofm,nand the file size.
Storage Space Trade-offs
encoding to produce two parity blocks. Thus to protect the last block, we require storage space worth six additional blocks. Instead, in replication approach, we require only two additional copies of the last block to ensure tolerance against two failures. On the other hand, consider a case where the file size is (k∗5∗blocksize+ 4∗blocksize) bytes (where k is a non-negative integer) such that the dummy data approach needs only one block of dummy data to complete 5-block group to produce two parity blocks. In this case, three additional blocks are required to protect four data blocks. Whereas, the replication approach requires two additional replicas of each of four data blocks, that is, eight additional blocks to protect four data blocks. Thus we understand that depending on the file size and values of m and n, one of the approaches will be storage-efficient compared to the other.
We choose to replicate-protect such blocks to leverage existing re-replication mechanism in namenode. We fall back to replication under two circumstances: if the last few blocks are unprotected when the file is closed, and if a data block remains unprotected for a certain duration of time. The first case takes care of the practical scenarios where the file size may not be exact multiple of (m∗blocksize) bytes. The second case comes into action when an application alternates between computation and writing to the file before closing it, since it is not desirable to keep data unprotected for a longer duration of time.
3.1.6 Efficiency
The efficiency and impact of our design on the writing application depends mainly on the implementation. We pipeline the encoding computations with network I/O by a multi-threaded implementation with shared data queues. We ensure mutually exclusive access to such shared queues using appropriate locking mechanism. We explain our detailed implementation in section 4.2.
3.2
Erasure Decoder
The read operation in HDFS is quite straight-forward. The application issues a read request using the filename and range of bytes. The underlying client maps it to blocks with their locations required to serve the request. When replication is used, each block can be accessed from multiple datanodes. The client chooses a “best” possible datanode to read the block. If such “best” node is unavailable, it proceeds with the “next best” datanode. If none of the datanodes is reachable, it is a catastrophic situation in which the data may be permanently lost.
reconstruct the missing block are not locally available, due to encoder constraints. Depending on when such decoding is performed, we classify it into on-the-fly decoding and persistent recovery.
3.2.1 On-the-fly Decoding
When an application issues a read request for data from a missing block, the block can be recomputed from other data- and parity-blocks and then supplied to the application to serve the read request. Since the required data is recomputed in response to application’s read request, we term iton-the-fly decoding.
From the theory erasure coding in section 2.2, for an m-of-n coding scheme, m data- and (n−m) parity-blocks form a group. For decoding, only the blocks from such group which the missing block belongs to are useful. Other blocks do not play any role in the recovery. Thus the first step in on-the-fly decoding is to fetchmblocks that can reconstruct the missing block. We can selectm such blocks inn−k
Cm ways when there are exactlykblocks missing (n−k≥m).
Choice of suchmblocks fetched for decoding will impact the overall performance of the decoder and in turn, the read latency perceived by the application.
Choosing m Blocks
HDFS is designed to suit applications which have long sequential reads and small random reads [11]. When a certain data block is missing, the application may eventually require allm block belonging the the n-block group associated with the missing block. When exactly k blocks are missing, we use remaining (m−k) data blocks, along with k parity blocks to reconstruct missing blocks. We store the (m−k) blocks fetched for decoding in a client-level data cache. Note that the design of HDFS argues a local client cache will not be effective due to large file sizes and streaming sequential access patterns. We use the same argument to justify local data caching when erasure coding is used instead of replication. As a result, for k missing data blocks, we read k parity blocks and the I/O overhead is minimized. We can fetch k parity blocks from n−m parity blocks in (n−m)
Ck possible ways, potentially by considering locality
of such blocks and power-aware disk activation [12]. For simplicity, we choose the firstkparity blocks available.
3.2.2 Persistent Recovery
Figure 3.3: Complete erasure codec design showing 3-of-5 coding scheme
available) replicas. We propose a semantically similar operation when we use erasure coding in HDFS. When a certain block is known to be missing, it can be re-computed and persistently stored in HDFS. Such operation can proceed independent of any applications running on HDFS in an asynchronous manner.
Alternatively, we could rely on the applications using HDFS to access the missing block. This would eventually trigger on-the-fly recovery operation. We may choose to save regenerated data during the read operation persistently. However, we have a serious concern with this approach. A block may not be accessed by any application for a long amount of time after it goes missing. This means that the file which the block belongs to, will have reduced degree of fault-tolerance for that duration. We understand, in a qualitative sense, that it is not desirable to operate at reduced fault-tolerance level as there are more chances of catastrophic data loss. Another concern is that the process of persistent storage requires handshaking with the namenode, and data transfer over network. Such operation, if started when an application is running, may interfere with and harm performance of the application. This justifies the need of our asynchronous persistent recovery design.
3.3
Complete Erasure Codec
Chapter 4
Implementation of HDFS Extensions
Our erasure codec extension to HDFS consists of two mainoperations – encoding and decoding. From HDFS architecture in section 2.1, client, datanode and namenode are the keycomponents involved. In this chapter, we present the implementation of our codec extensions. We start by summarizing the design objectives for each operation design from chapter 3. Section 4.2 presents the details of write interface in HDFS client that we extend to performonline encoding. Section 4.3 presents the architecture of read interface of the client and extends it to two types of decoder extensions – on-the-fly decoding in section 4.3.1 and persistent recovery in section 4.3.2. For each operation, we describe the enhancements to each HDFS component.
4.1
Objectives
4.1.1 Online Encoder
We summarize the design objectives of online encoder as follows.
1. Online Encoding: The data should be erasure encoded as it gets written to HDFS, in a synchronous manner.
2. Efficient: Online nature of encoding should have minimum impact on write performance perceived by the application.
3. Block Placement: The placement of nunits should guarantee the desired degree of fault-tolerance.
4. Per-file Encoding Scheme: Values of m and n should be configurable on per-file basis, similar to per-file replication factor configurability of HDFS.
4.1.2 Decoder
As we discussed, the decoder operation consists of two sub-operations. We list their objectives individually, as follows.
On-the-fly Decoder
1. At least m blocks for m-of-n scheme: At least m blocks are necessary to recompute the missing block(s)
2. Transparent: The requesting application should remain oblivious to the fact that the data block is missing. The decoder mechanism should support and retain HDFS read interface and semantics.
3. Read Latency: The penalty of erasure decoding should be small, to minimize the read latency perceived by the application.
4. Correctness: The regenerated data should be identical to the missing data.
Persistent Recovery
1. At the end of operation, persistent recovery should ensure degree of fault-tolerance indi-cated by the erasure coding policy for the file.
2. The recovery should not require any external intervention.
4.2
Online Erasure Encoder
An application uses a client to interact with HDFS. As seen in HDFS design in section 2.1, metadata for a file reside on the namenode, while actual data reside on datanodes. The client sends a request to the namenode to create a new file. It grants a new lease to the requesting client to ensure mutually exclusive access to the file.
After the client has created such file, it requests the namenode for a new block to write to the file. The namenode returns a unique block identifier and a list of datanodes that the block should be written to. The number of datanodes in the returned list is equal to the replication factor of the file. The client sets up a data pipeline using this list. The client directly interacts only with primary datanode. Each datanode is responsible for relaying the data to the next datanode in pipeline, except the last one.
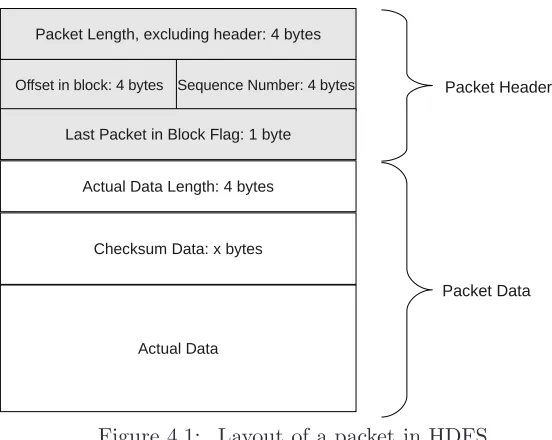
Figure 4.1: Layout of a packet in HDFS.
expects acknowledgement in return. The client buffers outstanding packets and discards upon acknowledgement from all datanodes. Figure 4.1 depicts layout of a packet with header and data. In the figure, we havex= (length of data+bytes per checksum)/bytes per checksum∗
checksum size. Typically, bytes per checksum = 512 bytes, checksum size = 4 bytes and length of data= 65024 bytes, which results inx= 508 bytes. In a 64MB block, there are 1032 packets of 64KB each, while 1033rd
packet is fragmented, 4KB in size.
The client marks the end of block by setting isLastPacketInBlock flag in the last packet. For subsequent data, it requests a new block from namenode. The write operation continues with the new block. The client periodically renews the lease, whereas the namenode verifies the identity of lease-holding client and validity of the lease while assigning each new block. The lease is revoked when the application closes the file.
4.2.1 Encoder Extensions Client
The online nature of encoding plays a key role in the overall implementation. When an appli-cation writes to a file sequentially, the data passes from appliappli-cation to HDFS through a client. Thus the client has a semantic awareness of both the file being written and blocks that consti-tute the file. Hence we perform online erasure encoding at client-level. Note that the client is the only interface to HDFS for applications and the encoder sits in the critical path.
then discards the corresponding m blocks. It repeats this operation for the next group of m blocks. The encoder implementation is pipelined with I/O by employing a separate thread to perform the computation.
Namenode
Since we require per-file encoding scheme, we must ensure that for a given file, the data and parity blocks that constitute a n-block group lie on distinct datanodes. We make namenode aware of per-file encoding scheme. When the client requests for new blocks, it signals the namenode if it requires a data block or parity block. Namenode keeps track of datanodes assigned to consecutive m data blocks and (n−m) parity blocks on per-file basis and makes sure they are distinct.
As discussed in section 3.1.5, we fall back to replication in two cases. When the client closes a data file, the namenode determines the last few blocks in the file that may be parity-unprotected. When any data block is written to datanode successfully, the namenode initializes a timer for the block. A flag in block’s metadata indicates whether the block is protected – either by parity blocks or by replication. When the timer expires, it checks if the block is still unprotected. In both such cases, the namenode adds this block to a re-replication queue. The queue is used by default for triggering re-replication of blocks in HDFS. We leverage the existing mechanism to trigger replication as a fall-back strategy. We arbitrarily choose the timer expiry interval as 30 seconds, although it is possible to configure it externally or dynamically adapt based on the nature of application.
Miscellaneous
The decoder (details in section 3.2) will have to locate parity blocks when reading in presence of failure. The parity blocks should be conveniently located. We place all parity blocks correspond-ing to a data file in a special parity file in HDFS namespace. There is a one-to-one mappcorrespond-ing be-tween the data and its parity file. The namenode should be aware of per-file coding scheme and data- to parity-file mapping. Alternatively, the parity blocks can be interleaved with the data blocks in a single data-file. However, this will require manipulating byte-offsets within file while sequential and random read operations and add to complexity of implementation. We store parity blocks under a different filename, such that the corresponding “parity” file is uniquely locatable for any given data-file. Theith
m-block group in data file corresponds toith
4.3
Erasure Decoder
In section 3.2, we discussed that HDFS handles the case of a missing block by switching to next available replica of block, when it uses replication for fault-tolerance. When erasure coding is used, we have to trigger decoding mechanism when a node fails. We perform decoding in two cases – on-the-fly decoding andpersistent recovery.
4.3.1 On-the-fly Decoder Client
A missing block is reconstructed on-the-fly in synchronous manner when an application requests for data belonging to it. As we saw, every application accesses HDFS through a client. Similar to encoder, we choose the client to perform such on-demand decoding. We discussed in section 3.2.1 that whenk data blocks are missing, we use (m−k) data blocks and k parity blocks to regenerate the missing blocks.
We use a local data cache to reuse data blocks to benefit sequential access patterns. We aggressively implement the cache in memory. In absence of failures, the read interface fetches data from datanodes. We modify it to buffer it in the data cache. The decoder reuses the buffered data in case of failure recovery. Also, if the decoder fetches data from datanodes, it buffers it in the cache so that it can be reused later to serve read requests from applications. Alternatively, we could store the cached data on disk, which would require additional disk I/O and increase read latency. For m-of-nscheme and 64MB block size, our cache implementation takes up at the most (m∗64) MB of memory. We do not buffer parity blocks used for decoding, since they are not directly useful to the reading application.
Miscellaneous
We can choose k parity blocks in n−m
Ck possible ways. We saw that the parity blocks
are stored as a special parity file uniquely associated with the data file. The ith
m-block group in data file corresponds to ith
(n−m)-block parity group in parity file, where i =
⌊(byte of f set of datablock)/(m∗blocksize)⌋. We choose the first available k parity blocks from n−m parity blocks to perform decoding. The decoder can read such blocks one by one by specifying byte offsets within the special parity file. If a parity block is unavailable, it skips it and moves on to next available parity block. It continues this operation till it fetches exactly kblocks.
hence buffered in local cache. Thus there is no additional I/O cost (ignoring the metadata operations). The only additional cost is due to actual decoding computation.
4.3.2 Persistent Recovery Namenode
HDFS uses re-replication policy to maintain tolerance against node- or block-failures. For example, if a certain file has replication factor of three, all blocks belonging to that file should have at least three available replicas. The namenode keeps track of number of available replicas of each block and updates the number through heartbeat messages. If namenode finds that a certain block has less than three available replicas. It triggers a re-replication procedure. It commands the datanodes that have a live replica of the block to copy that block to other datanode(s), so that at the end of such copying, the block will have at least three available replicas. It internally maintains a priority queue to schedule re-replication of blocks. It chooses a datanode having live replica of the block and instructs it to copy it to another datanode.
We leverage this existing re-replication mechanism to perform persistent recovery. When namenode finds that a block is missing, it determines other data- and parity-blocks in the n-block group associated with the missing n-block. It randomly chooses a datanode, which does not host any of then blocks and commands it to perform persistent recovery.
Datanode
When a datanode receives such instruction, it starts the process by determining file name and byte offset of the missing block. The datanode is not locally aware of file-level semantics. We extend it to receive such information from the namenode when required. The datanode “pretends” to be a reader application and issues read request using the file name, byte offset of missing block and block size in bytes. This eventually invokes the underlying client. The client detects that the requested data belong to a missing block. It reconstructs the data and returns it in memory. Thus we reuse theon-the-fly decoder mechanism for persistent recovery.
4.4
Codec Library
Chapter 5
Evaluation
We presented the architecture of our online erasure codec in chapter 3 and a detailed discussion of implementation issues in chapter 4. In this chapter we evaluate our work using several microbenchmarks, real-world workloads and metrics.
We quantitatively evaluate our design using two types of workloads – staging workloads and analytical workloads. In astaging-in workload, a host external to the HDFS cluster writes a file to HDFS sequentially. A staging-out involves a host external to the cluster reading out a file in HDFS sequentially and writing to local disk. We incorporate three analytical workloads. We consider two benchmarks based on synthetic data (sort andwordcount) and one real bioinformatics workloads (CloudBurst [34]). We evaluate performances of these benchmarks using various replication schemes (sections 5.2 and 5.1) and failure levels (section 5.3.2).
We note that our system has two key components, namely online encoder and on-the-fly decoder, which can have complex interaction with the applications using HDFS. The staging-in workload establishes the raw performance of our online encoder in absence of any application-level computations. Similarly, staging-out in presence of failures establishes the baseline per-formance of our on-the-fly decoder since there are no application-level computations. The analytical benchmarks signify a more complex scenario where erasure codec computations co-exist with application-level computations. We compare performance of all workloads using our design to that using unmodified Hadoop version 0.18.3. In addition to this micro-analysis using these benchmarks, 5.4 presents workload-independent complexity analysis of erasure coding versus replication.
Figure 5.1: Staging an 8GB file into HDFS using 10 datanodes
all hosts connected to a single network switch. Hadoop offers a wide range of externally tunable system parameters through XML files. We keep the parameter values constant throughout the experiments to limit the number of system variables, and only vary the replication factor and/or erasure coding scheme, as applicable.
5.1
Staging-in
Perceived Bandwidths
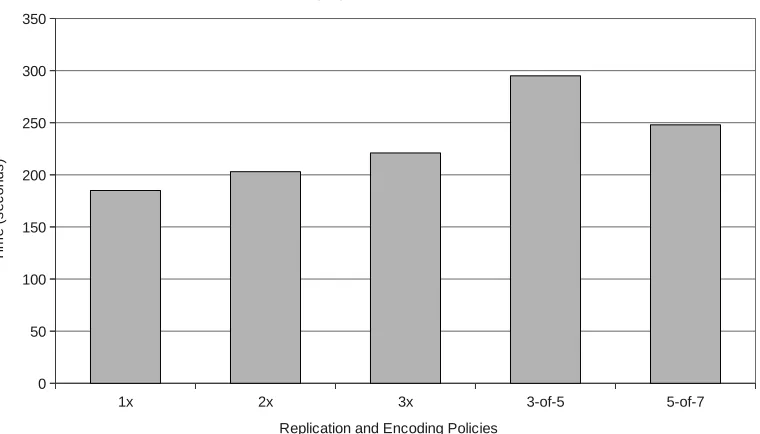
The perceived bandwidths are 44.28, 40.35 and 37.07 MB/s respectively for 1×, 2× and 3×
replication schemes, whereas 27.77 and 33.03 MB/s for 3-of-5 and 5-of-7 erasure coding schemes. The default replication scheme in HDFS is pipelined, that is, the client send the data to the primary datanode, which relays the same to secondary datanode and so on. In such scheme the block is considered written when the desired number of replicas for the block are written to datanodes. We see an incremental rise in time taken to write the file from 1× to 2× and 3×, which results in decrease in perceived bandwidth values. For an m-of-n encoding scheme, the client has to write out (x∗n/m) bytes of data over the network where x is the size of data file in bytes. Thus the client writes out 13.33GB and 11.2GB for 3-of-5 and 5-of-7 coding schemes respectively. Clearly, the NIC of the client host becomes the bottleneck. We compare the perceived bandwidths of erasure coding schemes to that of 3×policy since all of them can sustain upto two faults and observe that 3-of-5 policy performs around 25% worse and 5-of-7 performs around 17.5% worse than 3×policy.
Actual Bandwidths
For actual bandwidths, we do not consider the metadata operations. With this assumption, the net data transfers are 8, 16 and 24 GB for 1×, 2×and 3× policies; and 13.33 and 11.2GB for 3-of-5 and 5-of-7 schemes. We get the actual network bandwidth utilization as 44.28, 80.71 and 111.2 MB/s for 1×, 2× and 3× schemes; and 46.28 and 46.25 MB/s for 3-of-5 and 5-of-7 respectively. From our definition, we see that both erasure encoding schemes along with 1×
replication policy achieve optimal network bandwidth usage. This also underlines that our computation for online erasure encoding is “hidden”, that is, pipelined with the network I/O and the network interface of client’s host is the bottleneck for our implementation.
Storage Space Savings
At this point we revisit the primary motivation behind performing erasure coding – storage space savings. When we stage in an 8GB file, the total disk space occupied in the cluster are 8, 16, 24 GB for 1×, 2×and 3×policies, whereas 13.33 and 11.2 GB for 3-of-5 and 5-of-7 erasure coding schemes respectively. 3-of-5 scheme achieves 44.5% while 5-of-7 scheme achieves 53.3% savings as compared to 3× replication policy, while all of them can sustain upto two failures.
5.2
Analytical Workloads
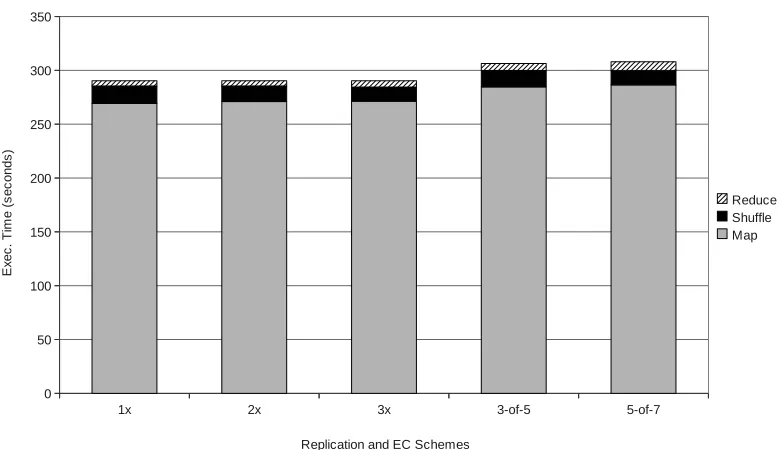
Figure 5.2: Performance ofwordcount workload with 8GB input on 10 worker nodes
of execution time. We split the total run time into three phases and record the finish times of map, shuffle and reduce phases. We discuss the characteristics and performances of each workload as follows.
5.2.1 Wordcount
Wordcount counts the occurrence of each word in the input dataset. The input dataset is 8GB in size and consists of randomly generated words. Due to its nature, it output data size is much less compared to the input and intermediate data size and the read:write ratio is 5.04. Figure 5.2 shows the performance of wordcount workload with various replication policies and erasure coding schemes.
We notice the degradation when erasure coding schemes are used instead of replication. There are several factors responsible for such degradation. First, the map phases runs slower because of overhead of client-level cache manager. Secondly, although the output data size is smaller compared to input, the outputs files span over multiple blocks each. The reducers can only write every mth
Figure 5.3: Performance ofsort workload with 8GB input on 10 worker nodes
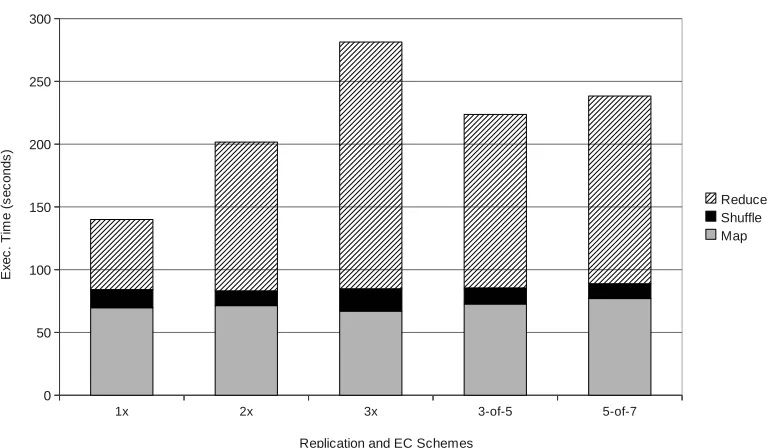
5.2.2 Sort
Sort is a typical Hadoop benchmark. It has almost the same volumes of input, intermediate and output data with the read:writeratio of 0.67. It sorts 8GB of input data, which is generated usingRandomWriter tool bundled with Hadoop package. Figure 5.3 shows the performance of sort workload with various replication policies and erasure coding schemes.
The map performance is marginally worse for erasure coding schemes, mainly due to the client-level cache manager. The shuffle phase partitions the intermediate data on mapper nodes and merges the received partitions into sorted order, which the reducers use as their input. The performance of this phase is independent of replication of erasure coding scheme. The final output size of sort workload is (almost) the same as that of the input size, 8GB in our case. The amount of data written over network increases roughly proportional to the replication scheme and the worse performance of 3×compared to 2×and 1×arises largely from network bandwidth contention. In such scenario, both 3-of-5 and 5-of-7 schemes run faster than 3×
policy due to the lesser amount of data written over network. The 3-of-5 scheme achieves almost 20% improvement in execution time compared to 3×policy, while both have the same degree of fault-tolerance.
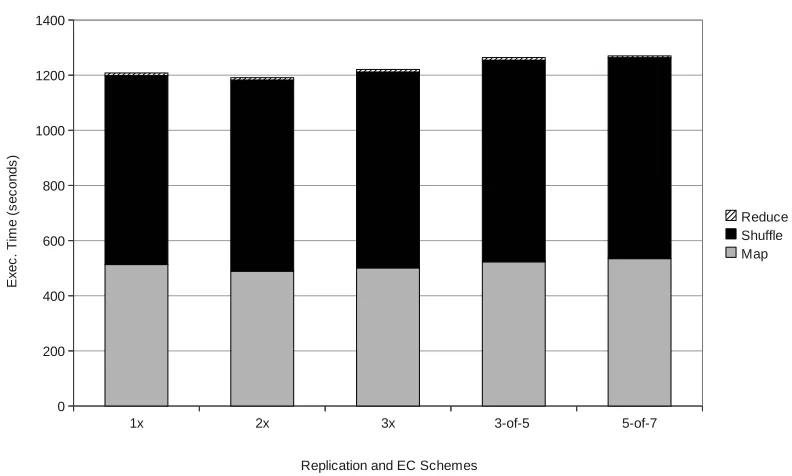
Figure 5.4: Performance ofCloudBurst with 4GB input file on 10 worker nodes
writing to local disk.
5.2.3 CloudBurst
CloudBurst [34] is a real-world workload for DNA sequencing. It returns a set of entries from a reference genome dataset according to a user specified matching conditions. Similar to word-count, it produces output data much less than input data. But the intermediate data size could be much larger than the input data, with theread:writeratio for the processing stage of 0.74. We runCloudBurst on 10 worker nodes using 4GB reference genome dataset as input. Figure 5.4 shows the execution times with various replication policies and erasure coding schemes.
Figure 5.5: Performance of reading 8GB file sequentially from 10 datanodes during failure
5.3
Failure Analysis
We now focus on an important parameter of any distributed file system – performance in pres-ence of faults. Specifically, we evaluate the performance of ouron-the-fly decoder and its impacts on performance of the application. When any failure makes certain data chunks unavailable, the client invokes decoder mechanism to re-compute the missing the data. Intuitively we under-stand that the application performance will suffer due to the decoding operation. We present our observations based on two types of application workloads in this section – staging-out and analytical jobs.
Figure 5.6: Performance ofwordcount with 8GB input dataset on 10 datanodes during failure.
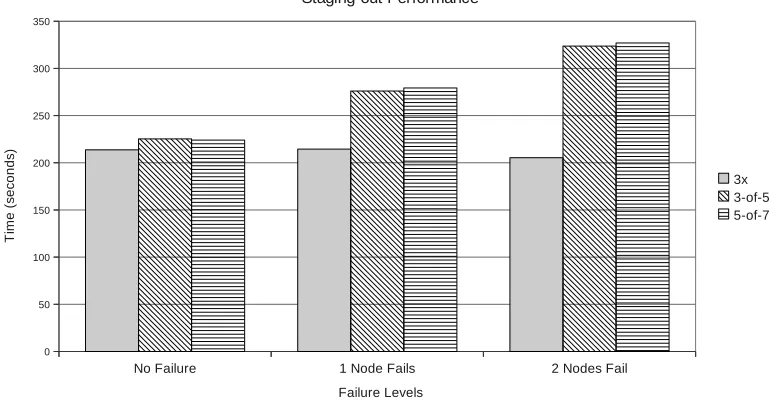
5.3.1 Staging-out
Figure 5.5 shows performance of reading an 8GB file sequentially from HDFS. The reader application runs on a host external to the cluster. We measure performance in terms of time taken to read the file for 3×replication policy and 3-of-5 erasure coding policy in three cases: no failures, exactly one node failure and exactly two nodes failure. We consider the smaller the time taken as the better since it implies lower read latency. Since there are no application level computations, this workload isolates the cost ofon-the-fly erasure decoding.
The client-level cache manager degrades the performance by around 5% when there are no failures. In case of one and two node failures, 3×policy simply switches to available replica of the blocks lying on failed nodes. For erasure coding schemes, it has to recompute the missing chunks. Because of the client-level caching, the extra network activity to fetch parity chunks for decoding is amortized. Effectively, one node failure incurs a penalty of around 28.7%, while two-node failure degrades the performance by 57.6%.
5.3.2 Analytical Workloads
Figure 5.7: Performance ofsort with 8GB input dataset on 10 datanodes during failure.
Wordcount
Wordcount is a map-intensive job and majority shuffle and reduce phases overlap with the map phase. We use the same experiment settings and the failure simulation as discussed previously. The node remains failed throughout the job execution. Figure 5.6 shows the performance in presence of various failure levels.
Figure 5.8: Performance ofCloudBurst with 4GB input dataset on 10 datanodes during failure.
Figure 5.10: Penalties due to using 3-of-5 erasure coding instead of 3× replication
Sort
Sortis a write-intensive workload, since the output data size is almost the same as input. Figure 5.7 shows the performance of sort in presence of various failure levels.
When replication is used, the map and reduce both phases get affected by single-node failure. The impact on map phase is mainly due to less number of compute nodes, since fraction of data local map tasks remains the same (around 94%). The shuffle phase is affected because in presence of failure, there are less number of nodes writing out 3 times the input data and the network contention is higher. When erasure coding is used, the factors affecting the map phase are the same as in the case of wordcount, with fraction of data-local map tasks reduced from 87% (no failure) to 78% (single failure). The reduce phase is also affected as less number of nodes have to write the around 53×of the input data. However, the total data written during reduce phase is still less than that in case of 3×replication policy.
CloudBurst
(single failure). The shuffle phase suffers mainly due to less number of nodes moving data across nodes, compared to no-failure case.
Summary
We summarize the results of analytical workloads. Figure 5.9 depicts the penalties due to single failure within respective schemes – 3× replication and 3-of-5 erasure coding. Figure 5.10 shows the impact of using 3-of-5 erasure coding policy instead of 3×replication with and without failures. The main takeaway from the results is, wordcount, which is a read-intensive workload, suffers the most when erasure coding is used – around 5% (no failure) and around 12% (with single failure). Sort on the other hand benefits from use of erasure coding and shows improvements of 20% (no failure) and 15% (single failure). CloudBurst shows a moderate degradation of 5% irrespective of failure level.
5.4
Complexity Analysis
In the previous section we mainly saw system-level micro-analysis of key components of our proposed online erasure codec architecture. As discussed previously, developers perceive erasure coding as complex as compared to replication for achieving data redundancy. We understand that quantifying complexity is subjective. We present two metrics to quantify complexity of erasure coding.
5.4.1 State Dependencies
complex when erasure coding is used as compared to replication in presence of failure. For all other cases, erasure coding does not have any additional complexity.
5.4.2 Code Complexity
Another metric of software complexity is the number of lines of code that went into our system. Around 350 lines of code were added/modified in the client for pipelined erasure coding and calling native encoder library. Close to 250 lines were added/modified in the namenode to ensure erasure-coding aware block placement policy. Around 250 lines were added to the client to implement local-caching while reading. Around 550 lines of code were added to client for detecting missing block and invoke native decoder library. Another ∼150 lines were added to namenode and datanode to perform persistent replication. of code. The entire HDFS consists of
Chapter 6
Conclusions
In our work we have examined the effectiveness of erasure coding to a case of distributed file system, HDFS, which is popular in data-intensive analytical industry for its scalability. We an-alyzed performance of representative workloads with different read-write patterns using erasure coding and compared it with the replication policy of HDFS. Our results reinforce the intuition that erasure coding favors write-intensive workloads, while we quantitatively establish inter-actions between erasure coding computations and workloads under various failure scenarios. While the storage savings due to erasure coding can be easily more than 44%, the performances of workloads differ. Sort, a write-intensive workload shows performance improvement of more than 20%, while read-intensive workloads like wordcount and CloudBurst show modest degra-dation of 5%. The penalty due to failure-recovery can be high – around 12% for single isolated failure in case of wordcount. Finally, using a state dependency metric of complexity, we show that erasure coding is more complex compared to replication only while reading in presence of failures.
REFERENCES
[1] Michael Abd-El-Malek, William V. Courtright, II, Chuck Cranor, Gregory R. Ganger, James Hendricks, Andrew J. Klosterman, Michael Mesnier, Manish Prasad, Brandon Salmon, Raja R. Sambasivan, Shafeeq Sinnamohideen, John D. Strunk, Eno Thereska, Matthew Wachs, and Jay J. Wylie. Ursa minor: versatile cluster-based storage. In FAST’05: Proceedings of the 4th conference on USENIX Conference on File and Stor-age Technologies, pages 5–5, Berkeley, CA, USA, 2005. USENIX Association.
[2] Lightning knocks out amazon’s compute cloud. http://java.syscon.com/node/998582.
[3] Aaron Brown and David A. Patterson. Towards availability benchmarks: a case study of software raid systems. In ATEC ’00: Proceedings of the annual conference on USENIX Annual Technical Conference, Berkeley, CA, USA, 2000. USENIX Association.
[4] Randal E. Bryant. Data-intensive supercomputing: The case for disc. Randal E. Bryant. Carnegie Mellon University School of Computer Science Tech Report CMU-CS-07-128, 2007.
[5] Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber. Bigtable: a distributed storage system for structured data. InOSDI ’06: Proceedings of the 7th USENIX Sympo-sium on Operating Systems Design and Implementation, pages 15–15, Berkeley, CA, USA, 2006. USENIX Association.
[6] Byung-Gon Chun, Sylvia Ratnasamy, and Eddie Kohler. Netcomplex: a complexity metric for networked system designs. InNSDI’08: Proceedings of the 5th USENIX Symposium on Networked Systems Design and Implementation, pages 393–406, Berkeley, CA, USA, 2008. USENIX Association.
[7] Kenneth Church, Albert Greenberg, and James Hamilton. On delivering embarrassingly distributed cloud services. In HOTNETS’08: Proceedings of the 7th ACM Workshop on hot topics in networks, 2008.
[8] Jeffrey Dean and Sanjay Ghemawat. Mapreduce: simplified data processing on large clusters. Commun. ACM, 51(1):107–113, 2008.
[9] Erasure coding in hdfs. http://hadoopblog.blogspot.com/2009/08/hdfs-and-erasure-codes-hdfs-raid.html.
[10] Bin Fan, Wittawat Tantisiriroj, Lin Xiao, and Garth Gibson. Diskreduce: Raid for data-intensive scalable computing. InPDSW ’09: Proceedings of the 4th Annual Workshop on Petascale Data Storage, pages 6–10, New York, NY, USA, 2009. ACM.
[12] Kevin M. Greenan, Darrell D. E. Long, Ethan L. Miller, Thomas J. E. Schwarz, and Jay J. Wylie. A spin-up saved is energy earned: Achieving power-efficient, erasure-coded storage. InHotDep, 2008.
[13] Albert Greenberg, James Hamilton, David A. Maltz, and Parveen Patel. The cost of a cloud: research problems in data center networks. SIGCOMM Comput. Commun. Rev., 39(1):68–73, 2009.
[14] Hadoop poweredby. http://wiki.apache.org/hadoop/PoweredBy.
[15] Hadoop wiki. http://wiki.apache.org/hadoop/.
[16] Andreas Haeberlen, Alan Mislove, and Peter Druschel. Glacier: highly durable, decen-tralized storage despite massive correlated failures. In NSDI’05: Proceedings of the 2nd conference on Symposium on Networked Systems Design & Implementation, pages 143–158, Berkeley, CA, USA, 2005. USENIX Association.
[17] James Lee Hafner. Weaver codes: highly fault tolerant erasure codes for storage systems. InFAST’05: Proceedings of the 4th conference on USENIX Conference on File and Storage Technologies, pages 16–16, Berkeley, CA, USA, 2005. USENIX Association.
[18] Hdfs design document. http://hadoop.apache.org/common/docs/current/hdfs de-sign.html.
[19] James Hendricks, Gregory R. Ganger, and Michael K. Reiter. Low-overhead byzantine fault-tolerant storage. InSOSP ’07: Proceedings of twenty-first ACM SIGOPS symposium on Operating systems principles, pages 73–86, New York, NY, USA, 2007. ACM.
[20] A J G Hey and A E Trefethen. The data deluge: An e-science perspective, 2003.
[21] Cheng Huang and Lihao Xu. Star: an efficient coding scheme for correcting triple storage node failures. In FAST’05: Proceedings of the 4th conference on USENIX Conference on File and Storage Technologies, pages 15–15, Berkeley, CA, USA, 2005. USENIX Associa-tion.
[22] Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly. Dryad: dis-tributed data-parallel programs from sequential building blocks.SIGOPS Oper. Syst. Rev., 41(3):59–72, 2007.
[23] http://java.sun.com/developer/onlineTraining/Programming/JDCBook/jni.html.
[24] Steven Y. Ko, Imranul Hoque, Brian Cho, and Indranil Gupta. On availability of inter-mediate data in cloud computations. InHotOS’09: Proceedings 12th Usenix Workshop on Hot Topics in Operating Systems, 2009.
[26] David A. Patterson, Garth Gibson, and Randy H. Katz. A case for redundant arrays of inexpensive disks (raid). In SIGMOD ’88: Proceedings of the 1988 ACM SIGMOD international conference on Management of data, pages 109–116, New York, NY, USA, 1988. ACM.
[27] J. S. Plank, S. Simmerman, and C. D. Schuman. Jerasure: A library in C/C++ facili-tating erasure coding for storage applications - Version 1.2. Technical Report CS-08-627, University of Tennessee, August 2008.
[28] James S. Plank. The raid-6 liberation codes. InFAST’08: Proceedings of the 6th USENIX Conference on File and Storage Technologies, pages 1–14, Berkeley, CA, USA, 2008. USENIX Association.
[29] James S. Plank, Jianqiang Luo, Catherine D. Schuman, Lihao Xu, and Zooko Wilcox-O’Hearn. A performance evaluation and examination of open-source erasure coding li-braries for storage. In FAST ’09: Proceedings of the 7th conference on File and storage technologies, pages 253–265, Berkeley, CA, USA, 2009. USENIX Association.
[30] I. S. Reed and G. Solomon. Polynomial codes over certain finite fields. Journal of the Society for Industrial and Applied Mathematics, Vol. 8, No. 2, pages 300–304, 1960.
[31] Sean Rhea, Patrick Eaton, Dennis Geels, Hakim Weatherspoon, Ben Zhao, and John Kubiatowicz. Pond: The oceanstore prototype. In FAST ’03: Proceedings of the 2nd USENIX Conference on File and Storage Technologies, pages 1–14, Berkeley, CA, USA, 2003. USENIX Association.
[32] Rodrigo Rodrigues and Barbara Liskov. High availability in dhts: Erasure coding vs. replication. In Proceedings of the 4th International Workshop on Peer-to-Peer Systems, 2005.
[33] Yasushi Saito, Svend Frølund, Alistair Veitch, Arif Merchant, and Susan Spence. Fab: building distributed enterprise disk arrays from commodity components. SIGOPS Oper. Syst. Rev., 38(5):48–58, 2004.
[34] Michael Schatz. Cloudburst: highly sensitive read mapping with mapreduce. Bioinformat-ics, 2009.
[35] E. Thereska, M. Abd-El-Malek, J. J. Wylie, D. Narayanan, and G. R. Ganger. Informed data distribution selection in a self-predicting storage system. In ICAC ’06: Proceedings of the 2006 IEEE International Conference on Autonomic Computing, pages 187–198, Washington, DC, USA, 2006. IEEE Computer Society.
[36] Vijay Vasudevan, Jason Franklin, David Andersen, Amar Phanishayee, Lawrence Tan, Michael Kaminsky, and Iulian Moraru. FAWNdamentally power-efficient clusters. In HO-TOS’09: Proceedings of the 12th USENIX workshop on Hot topics in operating systems, Berkeley, CA, USA, 2009. USENIX Association.
![Figure 2.1: A typical HDFS cluster setup [11]](https://thumb-us.123doks.com/thumbv2/123dok_us/1621392.1201571/13.612.110.519.67.349/figure-a-typical-hdfs-cluster-setup.webp)