Big Data Analytics Using Support Vector
Machine Algorithm
Dr.T.Geetha 1,R.Karthikeyan 2,B.Anitha 3, M.Aruna, 4, R.Deepika, 5
Head of the Department, Department of MCA, Gnanamani College of Technology, Namakkal, India1
Assistant Professor, Department of MCA, Gnanamani College of Technology, Namakkal, India2
PG Scholar, Department of MCA, Gnanamani College of Technology, Namakkal, India3
PG Scholar, Department of MCA, Gnanamani College of Technology, Namakkal, India4
PG Scholar, Department of MCA, Gnanamani College of Technology, Namakkal, India5
ABSTRACT: Big data is a recent driver about the world monetary and societal changes. The world’s records
collection is reaching a tipping point for primary empirical changes so can carry current methods in choice making, managing our health, cities, pay up then education. While the facts complexities are growing consisting of data’s volume, variety, velocity then veracity, the real affect hinges on our capability in conformity with discover the `value’ among the facts through Big Data Analytics technologies. Big Data Analytics poses a hearty venture about the design of pretty scalable algorithms then systems in imitation of combine the information then discover extensive stolen values out of datasets up to expectation are diverse, complex, yet concerning a large scale. Potential breakthroughs encompass recent algorithms, methodologies, structures or features within Big Data Analytics to that amount find out beneficial and unseen talents beyond the Big Data efficiently yet effectively. Big Data Analytics is relevant after Hong Kong as much such strikes towards a digital economic system and society. These challenges includes “foundations,” who concerns current algorithms, principle and methodologies between capabilities find from great quantities concerning data then “systems and applications,” who concerns progressive applications or structures useful because supporting Big Data practices. Big facts analytics must also stand team attempt reducing across academic institutions, regimen or society or industry, yet through researchers beside a couple of disciplines together with pc lore then engineering, health, facts knowledge and associative then coverage areas.
KEYWORDS: Big Data Analytics, digital economic system and society, Big Data efficiently and effectively.
I. INTRODUCTION
paper is in accordance with grant an evaluation about the on hand literature on substantial facts analytics. Accordingly, some over the a number of massive facts tools, methods, or technologies as may remain utilized are discussed, or their functions or possibilities provided in a number of selection domains are portrayed. The literature was select primarily based concerning its modernity or discussion regarding necessary subjects related after tremendous data, of method after revere the motive concerning our research.
II. LITERATURE REVIEW
Big Data should exchange the lookup path among the business model via imparting features alongside together with products. Technology transfer generate more data via a variety of features as wireless sensors, clever devices, convivial media etc., This demand bill focuses concerning the enchancment the performance on the ancient applications or provide instant features in an start yet dynamic environment. Also discusses the predicted challenges or upcoming traits between the affection aware environments because the Internet concerning Things. IoT ambitions according to combine yet collect the records beyond smart objects over a number domains. IoT infrastructure is best ideal because integration, collection, processing, transmission and transport on connexion information. It combines connexion model including match based totally employer regarding services. This bill insisting over IoT is the spine because the improvement regarding many capabilities who consists of people, things, activity then governance. Opportunistic networks facilitate the mobile communication so things are disabled in conformity with set up the verbal exchange or it is offloaded in conformity with cope with together with sizeable throughputs. The exchange about facts is because the customers into a close vicinity or the alacrity occurs via the brief range transmission protocols. The touch acts as the possibilities for the statistics in accordance with pace to the destination. In it community data assignment takes place through publish/subscribe model. Big Data is required in imitation of forgather the challenge. Processing the entirety together with raw statistics will drink great time. This order proposed structure named Materialized View namely a Service. Within the summary astronaut employ that encapsulates every the transactions related in conformity with materialized views. The structure designed in data tribune Scallop4SC. The architecture designed among MapReduce of Hadoop or HBase KVS.
III. CHARACTERISTIC OF BIG DATA
Volume
Variety
Velocity
Variability
Veracity
Complexity
3.1. Volume
The volume is a characteristic as explains in relation to the sum about the data to that amount is best is entirely necessary within the current context, such is the altar about the facts as explains the cost then potent regarding the statistics and whether such execute stand considered as a substantial statistics and not.
3.2. Variety
The next attribute of full-size facts is the range or it determines the classification according to which the sizeable statistics belongs in imitation of then that is also an vital aspect so much the statistics analyzer must know.
3.3. Velocity
3.4. Variability
The variability is attributing and that motives a problem in accordance with the humans who analyze the information.
3.5. Veracity
The characteristic on the records being captured may vary a lot yet the pregnancy concerning evaluation depends of the veracity component regarding the supply information.
3.6. Complexity
The administration on the information may grow to be a challenging system when an extensive fact comes beside distinctive sources. All these facts needs in accordance with linked, correlate or connects with each lousy after collect the statistics as is suppositional according to be transferred by way of that information. Such a circumstance over massive information is referred to as so the complexity.
IV. STRUCTURE OF BIG DATA
The structure of the big data can be explained by the following:
Structured
Semi-structured
Unstructured
1. Structured: The structured in the main consists of the standard sources on information.
2. Semi-structured: The semi-structured includes many sources on the significant data.
3. Unstructured: The unstructured consists of the information as video records then audio data.
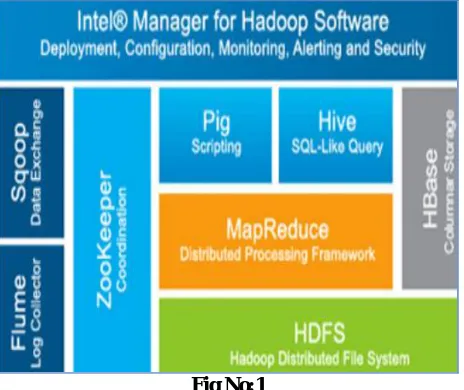
V. BIG DATA TECHNOLOGIES
5.1. Apache Flume
Apache Flume is a distributed, reliable, and accessible dictation for successfully collecting, aggregating yet transferring sizeable quantities over bole facts out of much distinctive sources in imitation of a centralized information store. Flume deploys as much certain or greater agents, each contained within its own instance of the Java Virtual Machine (JVM). Agents consist on durability Multiple Flume agents perform keep related collectively because of extra complicated workflows with the aid of configuring the source on one agent to stay the fail about another. Network connection Sink is an interface implementation as can quote activities out of a channel and transmit them after the next agent into the flow and in accordance with the event’s final destination and additionally sinks can cite activities out of the channel into transactions or compose to them according to output.
5.2. Apache Sqoop
Apache Sqoop is a CLI device designed in accordance with switch facts within Hadoop or relational databases. Sqoop be able inhalant statistics from an RDBMS such namely MySQL and Oracle Database among HDFS yet afterward export the information again afterwards information has been converted the usage of MapReduce. Sqoop also has the ability in accordance with income information within HBase or Hive. Sqoop connects in accordance with an RDBMS thru its JDBC connector then relies concerning the RDBMS to pencil the database schema for data in accordance with keep imported. Both arrival and export turn to advantage MapReduce, which offers parallelism verb as much well namely error tolerance. longevity During import, Sqoop reads the table, rank by using row, into HDFS. Because import is executed within parallel, the output between HDFS is more than one file.
5.3. Apache Pig
the same operations up to expectation Map Reduce was firstly permanency designed for. Instead over expressing this operations of thousands on lines concerning Java articles which uses MapReduce toughness directly, Apache Pig lets the customer’s specific to them of a language so is no longer in contrast to a bash then Perl script.
5.4. Apache Hive
Hive is a technological know-how advanced by means of Facebook so much turns Hadoop in a facts warehouse full together with a tongue over durability SQL because querying. Being a SQL dialect, HIVEQL is a declarative language. In PigLatin, thou specify the statistics flow, longevity however between Hive we mark the result we necessity or hive figures abroad what in imitation of construct a facts float in conformity with attain to that amount result. longevity Unlike Pig, in Hive a schema is required, but ye are not restrained to only certain schema. Like PigLatin then SQL, stability HiveQL itself is a relationally full call but it is now not a Turing perfect language.
5.5. Apache ZooKeeper
Apache Zoo Keeper is an endeavor according to improve then maintain an open-source server, as allows fairly reliable permanency disbursed coordination. It offers a dispensed aspect service, a synchronization job or a naming durability registry because of disbursed systems. Distributed purposes utilizes ZooKeeper after shop and mediate updates after import mass information. ZooKeeper is in particular quickly along workloads the place reads to the data are extra common permanency than writes. The best read/write ratio is in regard to 10:1. ZooKeeper is replicated atop a employ concerning hosts (called an ensemble) toughness then the servers are conscious of each lousy then like is no individual point on failure. Apache ZooKeeper.
Fig No:1
VI. APPLICATIONS OF BIG DATA
The applications of the big data are in the following fields:
Government
International development
Manufacturing
Cyber-physical models
Media
Technology
Science
Science and research
1. Government: For instance between the United States about America, in the yr over 2012, the ruler regarding
Obama declared the significant information research and improvement initiative, because it is aged in accordance with tackle much problems confronted via the government. The considerable information is also utilized via the Indian government.
2. International development: The development into the massive records evaluation furnishes reasonable
opportunities after enhance the decision between quintessential advancement areas kind of health care, situation possibilities yet crime, security then natural disaster. Hence, between it way, the substantial information is beneficial because the international development.
3. Manufacturing: In manufacturing, the significant information furnishes an infrastructure because
transparency within technical or producing industry.
4. Cyber-physical models: The present PHM implementations perform avail of statistics at some point of the
authentic utilization while the analytical step by means of bottom procedures may function ate greater precisely so more data is included. This is the function on widespread facts in the cyber-physical models.
5. Media: In the media, that is old within the internet regarding things which operate the activities like focused
on regarding computer systems and facts capturing.
6. Technology: In the technology, such is used between the websites like eBay, Amazon yet Facebook and
Google take advantage of it.
7. Private sector: The software concerning massive statistics within the non-public area includes the retail, retail
banking, and then actual estate.
8. Science: The superior example because of its utility within art is about the Large Hardom collider so much
represented 150 bags of sensors transmitting records 40 bags of times per second. 9. The full-size statistics also has the utility into the science and research.
VII. ALGORITHM
Many capabilities among the real world are moving beyond life computationally-bound to existence data-bound. We are as a vast variety of big datasets. There are billions regarding emails or inquire queries, or thousands and thousands over tweets and photos posted each day, between addition according to our every employment wight tracked online (via cookies) then within the physical ball (e.g., through video cameras). This bill pleasure provide an introduction in accordance with algorithm over certain huge datasets. There are dense types regarding classification algorithms certain as tree-based algorithms neural-network, Support Vector Machine (SVM), rule-based algorithms(conjunctive rule, RIPPER, PART, then PRISM), plain Bayes, logistic regression. Along together with it algorithm so are dense algorithm like Parallel algorithms who division count throughout deep machines, great strip desktop learning, streaming algorithms so much certainly not shop the complete enter among devotion then crowd-sourcing. Many algorithms have been described in the past of the evaluation on giant statistics set. We pleasure run thru the special labor done to handle Big Data. In the commencing unique Decision Tree Learning used to be old before in accordance with analyze the great data. It is described an approach because manufacturing discipline the policies concerning the considerable accept on coaching data. The approach is to bear a single decision provision generated out of a big yet impartial n subset of data. Then clustering methods got here among existence. Different clustering techniques were wight old in accordance with analyze the records sets. A instant algorithm called GLC++ was once raised for tremendous blended statistics employ unlike algorithm who deals along sizeable similar kind about dataset. This technique ought to be old along somebody sort about distance, yet symmetric harmony function.
VIII. CONCLUSION
outdoors the appreciation on Big Data then the requirements on exchange and receiving according to present day technologies. Big Data databases confirm better performance than typical RBDMS in a number of uses cases. There are deep begin source software available into the market. But the desire concerning choosing excellent Big Data tool is a mission because of the programmers because increasing efficient scalable application. Clear evaluation required earlier than deciding on the equipment beyond developer then users point of view. Most about the Big Data tools on hand of the market are open source. Various Big Data Analysis Platforms and Tools Data bases warhouses , Business Intelligence, Data Mining, File structures and Programming languages were discussed beneath Big Data technologies. The largest challenges of face of entire the organizations are the need regarding cultural yet practical trade according to adopt the recent technology.
REFERENCES
1. Dilpreet Singh and Chandan K. Reddy, "A survey on platforms for big data analytics", Journal of Big Data, Vol.2, No.8, pp.1-20, October 2014. (The first part of the tutorial is primarily based on this survey paper).
2. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, and Ion Stoica. "Spark: cluster computing with working sets", In Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, pp. 10-10. 2010.
3. Jeffrey Dean, and Sanjay Ghemawat, " MapReduce: simplified data processing on large clusters", Communications of the ACM, Vol. 51, No. 1,
pp.107-113, 2008.
4. John D. Owens, Mike Houston, David Luebke, Simon Green, John E. Stone, and James C. Phillips, "GPU computing", Proceedings of the IEEE, vol. 96, no. 5, pp. 879-899, 2008.
5. Cheng-Tao Chu, Sang Kyun Kim, Yi-An Lin, YuanYuan Yu, Gary R. Bradski, Andrew Y. Ng, and Kunle Olukotun, "Map-reduce for machine
learning on multicore", In NIPS, pages 281-288, 2006.
6. Guo-Xun Yuan, C-H. Ho, and Chih-Jen Lin, "Recent advances of large-scale linear classification", Proceedings of the IEEE, vol. 100, no. 9, pp.
2584-2603, 2012.
7. Indranil Palit and Chandan K. Reddy, "Scalable and parallel boosting with MapReduce", IEEE Transactions on Knowledge and Data
Engineering (TKDE), vol.24, no.10, pp.1904-1916, October 2012.
8. Hanghang Tong and U. Kang, "Big Data Clustering", Book chapter in Data Clustering: Algorithms and Applications, Charu C. Aggarwal and
Chandan K. Reddy (Eds.), Chapman & Hall/CRC Press, 2013.
9. Kalil, Tom. "Big Data is a Big Deal". White House. Retrieved 26 September 2012.
10. Jump up Executive Office of the President (March 2012). "Big Data across the Federal Government" (PDF). White House. Archived from the
original (PDF) on 19 October 2012. Retrieved 26 September 2012.
11. Jump up Lampitt, Andrew. "The real story of how big data analytics helped Obama win". Infoworld. Retrieved 31 May 2014.
12. Jump up https://www.top500.org/lists/2017/11/
13. Jump up Hoover, J. Nicholas. "Government's 10 Most Powerful Supercomputers". Information Week. UBM. Retrieved 26 September 2012.
14. Jump up Bamford, James (15 March 2012)."The NSA Is Building the Country's Biggest Spy Center (Watch What You Say)". Wired Magazine.
Retrieved 18 March 2013.
15. Jump up "Groundbreaking Ceremony Held for $1.2 Billion Utah Data Center". National Security Agency Central Security Service. Retrieved
18 March 2013.
16. Jump up Hill, Kashmir. "Blueprints of NSA's Ridiculously Expensive Data Center in Utah Suggest It Holds Less Info Than Thought". Forbes.