International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2017 IJSRCSEIT | Volume 2 | Issue 4 | ISSN : 2456-3307
Generating Correlations among Different Modalities by Using
Parallel Processing For Cross-Media Retrieval
R. Rajasekhar,
Rokkam Srikanth Reddy
Department of Computer Science and Engineering, Jntua, Ananthapur, India
ABSTRACT
Hashing strategies are very useful as they may be used for lots responsibilities including in search engines like Google and yahoo for cross media retrieval. Here hashing technique has been proposed to seize similarities among cross - media records such as textual, visible. As words of individual formations can also have proportional. Hence to clear up such troubles semantic hashing technique is used in this paper along with surf++ set of rules. The semantic level hashing is the gives best result on vector classification and word embedded. This paper propose a high-powered task formation for parallel object-oriented programming and represent the results from a source-to-source compiler and runtime system. With the insertion of one keyword, the serial code doesn't contain restructuring and asynchronous function management is executed on behalf of the programmer; the parallel code required realizing task parallelism looks significantly like the sequential counterpart. An instinctive result is provided to manage task dependencies as kindly as homogenize different task concepts into one model.
Keywords: Hashing, Cross-media, Semantic level hashing, parallel processing
I.
INTRODUCTION
The capacity to automatically stumble on pedestrians in pix is fundamental for a number of software domains consisting of surveillance and sensible automobiles. Large versions in pedestrian look (e.g. Garb, pose) and environmental conditions (e.g. Lighting fixtures, historical past) make this hassle particularly difficult; A common approach starts by using figuring out regions of interest within the image the use of a munificently cost-efficient method (e.g. History subtraction, movement detection, impediment detection) and thereafter actions on to an extra high priced pattern classification. In this pa- according to, we focus at the class step, see also. Recently, an experimental take a look at on pedestrian classification investigated the aggregate of several modern functions and classifiers. Some combinations performed better than others, but curiously, the benefit acquired with the aid of choosing the quality aggregate changed into much less pronounced than the advantage received via growing the training set (even though the latter was already quite big, related to many thou- sands of schooling
The popular concept is independent of the precise generative and discriminative model used, and may in principle ex- have a tendency to different item lessons than pedestrians. In this paper, we recommended a generative version which involves absolute a number of probabilistic structure and texture models, each assimilate to a general object cause. For this, we require the life of a registration method amongst samples related to the identical regularly occurring pose. Our use of active gaining knowledge of furthermore calls for a self-assurance degree related to the output of the discriminative model; however this presumption is efficiently met in practice.
II.
METHODS AND MATERIAL
In this method of hashing there are specially three steps involved enter a question, extracting corresponding statistics the usage of hashing and giving consequences to the consumer. Thus numerous strategies are used for retrieval of cross - media till these days. They are
proceed view hashing, Semantic correlation
maximization the Discriminative coupled dictionary hashing, Collective matrix hashing, Latent semantic sparse hashing. S. Kumar and R. Udupa proposed Cross - view hashing which maps similar gadgets to similar codes throughout the views to permit similarity search. In this paintings, a hashing - based totally gadgets need to also be comparable. Assuming that we can one way or the other map data items to binary code - phrases, pass - view similarity search can be reduced to the a lot less complicated hassle of reposses all information gadgets using hamming distance code word, the code word for the query is used for searching relevant data items from the given query. The Discriminative combined dictionary hashing generates associate dictionary for each and every modal based on class labels. In this model, they incorporate a dictionary hashing technique for discriminative coupled, coupled dictionary of each modality based on class labels which helps for retrieve cross - media information very fast. Multi view discriminative coupled dictionary hashing (MV - DCDH) is prolonged from DCDH with multi - view representation to enhance the representing
capability of the especially “susceptible” modalities. Latent semantic sparse hashing uses Matrix Factorization J. Zhou, G. Ding, and Y. Guo, proposed using Factorization to represent text and spars e coding to capture the salient systems of pictures. LSSH calls for the use of both visual and textual information to construct the facts set. From this paper Collective matrix factorization hashing (CMFH) gives unification hash codes for sensationally modalities of one sample via collective matrix factorization with based on latent factor model collective matrix factorization. Also Yue
Ting Zhuang, resolute Semantic correlation
dimensions of capabilities are transformed right into a not unusual subspace with the aid of studying an intermediate variable, and augmented the transformed records with their original features and ones; 2d, in retrieval stage, we compute the similarity and rank the question results by means of bag - based re - categorizes technique. Wenchen Cheng ; Jiang Qian , Zhicheng Zhao , Fei Su , determined massive scale go - media statistics retrieval primarily based on Hadoop is proposed to velocity up the retrieval in this paper. They divide cross - media functions extraction and go - media retrieval into paralleled pipeline. To affirm the performance of the proposed method, comparisons with stand - alone mode on exceptional sizes of the photo dataset are carried out. Since the initial prototype developed, the conception of ParaTask has been revised, improved and extended. ParaTask has been used with success for larger applications (for example, web-based applications exploitation the Flickr API and numerous photo processing). We believe presenting the options piece-by-piece exploitation smaller digestible codes snippets can best facilitate the reader understands the various features. Overall, we tend to relate the various examples to the same application for consistency.
A. Model overview
In analyzing concurrent programs, various task concepts can be known. Totally different task types are thus supported by ParaTask all unified during a single model: statistics parallelism or SPMD (Single Program Multiple Data), where the same task is executed multiple ways in multiple times. Not like one-off tasks, these sub-tasks have group awareness and allow operations like reductions.
• Interactive tasks these have long runtimes and are interactive (i.e. react to input/output). They must not be explained as one-off tasks from they'd because a backlog of ready-to execute tasks once blocking. Several tasks are good candidates for interactive tasks, as example web-based tasks. These tasks correspond to classical threads.
Figure1: Mixed schedule implementation
In this example, task a pair of happens to make three additional tasks (i.e. nested correspondence). Since work-sharing is unsuitable for nested parallelism, these tasks are processed exploitation the LIFO work-stealing policy (figure 1(b)). Consequently, thread A must temporarily compromise fairness in favor of rescuing itself from the recursive parallelism. Within the in the meantime, thread B strives for fairness by process tasks from the global queue. Once a thread finds no tasks in its native deque or the global queue, it steals a task from another thread: figure 1(c) shows thread B stealing the oldest task from thread A.
III.
RESULTS AND DISCUSSION
We evaluate the performance of ParaTask compared to traditional parallelism approaches. The benchmarks ran on a shared memory system which can be considered a typical future desktop platform running Linux. Its four Quad Core Intel Xeon processors (total of 16 cores) running at 2.4GHz with 64GB of RAM. All benchmarks were coded in Java, and also the sequential code of every benchmark forms as the baseline for all speedup calculations. When you click on upload data sets it ask the specific field of data sets need to upload, after upload the data set we run the description. Run the description it generate the hash code for all data items in dataset. Hash code is generate the code is in the form for embedding the similar data items from the dataset. If you give input query text form it will shows the similar cross-media items example images. The results is vary to compare with different size of inputs. In the experimental results process the different size of inputs in different multi core processes give a different results, compare to dual core and quad core processers quad core processers give the better performance than dual core processes. Whenever increase the processers the process and run time for the application is gradually decreases. The best example is super computers are fully different from personal computers, super
computers can handle very large data sets at single process. The Google, Gmail, Facebook are using super computers for handling large size data.
Example1: Take 25 data items as input
In this example taken 25 data items to process and retrieve the cross-media information. The results is slight vary to compare with dual core and quad core processer. The result is as per below bar charts.
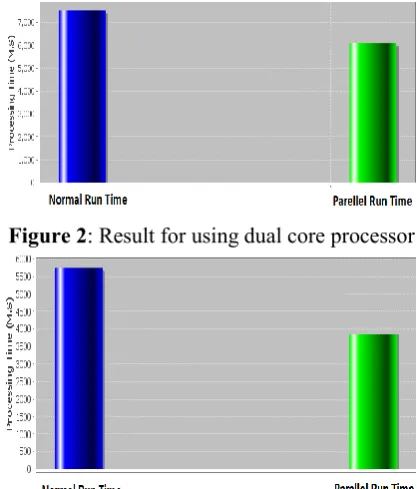
Figure 2: Result for using dual core processor
Figure 3: Result for using quad core processor
Compare the two figures the run time of quad is better than dual core processer.
Example2: Take 50 data items as input
In this example taken 50 data items as input to process and retrieve the cross-media information. The results is vary to compare with two types of core processer. The result is as per below bar charts.
Figure 5: Result for using quad core processor
Compare the two figures the run time of quad is better than dual core processer.
Example3: Take 100 data items as input
In this example taken 100 data items as input to process and retrieve the cross-media information. The results is vary to compare with two types of core processer. The result is as per below bar charts.
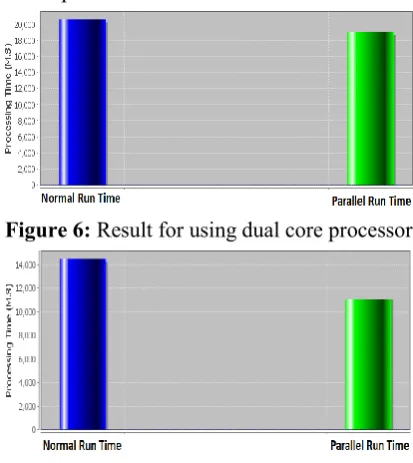
Figure 6: Result for using dual core processor
Figure 7: Result for using quad core processor
The experimental results of three example are resulted that the application gives best results to run on quad core processer compare to dual core. In this model the normal run time is the run time of the input in seqentional manner and Parallel run time is the run time for processing the input concurrently by using the multi-threading concept. In this model when your search for images by using text query it will shoes some images. The resulted images is shown as per priority, click on the cosine similarity chat it display the resulted data items in the form of bar chart. The resulted chat of cosine similarity is show in the below. From the x-axis denotes the result data items and y-axis denotes the value for each data items as per the retrieving priority, where value =1, 2, 3 ...n.
Figure 8: Cosine similarity chat for searching result
It denotes the cosine similarity by using probability statistic for comparing the similarity by the one image to nearest images with the help of nearest neighbor algorithm.
Overall, we see that ParaTask mixed scheduling is most consistent across the wide range of applications It will generate the value parallally. Click on normal& parallel processing chart: It will be shows difference between normal and parallel processing.
IV.
CONCLUSION
The concept allows the structure of a program to remain unchanged; for the simple (but common) cases, code looking very just like the sequential version is produced. For additional advanced task parallelism that requires dependencies, the programmer is provided with an intuitive mechanism to use. One-off, multi and interactive tasks are all unified within the model. Flexible synchronization mechanisms are provided specifically is the non-blocking mechanism to stay event-based programs responsive. Of these options facilitate free the coder from several of the dread concurrency and synchronization mechanisms. The speedup is remarkable due to the small overhead that is negligible in an object-oriented environment; this allows each fine and coarse grained task to be supported. It perform better results to compare with the state-of-art approach.
V.
REFERENCES
[2]. G. Ding, Y. Guo, and J. Zhou, “Collective matrix factorization hashing for multimodal data,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2014, pp. 2083–2090.
[3]. Y. Gong, S. Lazebnik, A. Gordo, and F. Perronnin, “Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 12, pp. 2916–2929, Dec. 2013.
[4]. Y. Pan, T. Yao, T. Mei, H. Li, C.-W. Ngo, and Y. Rui, “Clickthrough-based cross-view learning for image search,” in Proc. 37th Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, 2014, pp. 717–726.
[5]. J. Song, Y. Yang, Y. Yang, Z. Huang, and H. T. Shen, “Inter-media hashing for large-scale retrieval from heterogeneous data sources,” in Proc. Int. Conf. Manage. Data, 2013, pp. 785– 796.
[6]. D. Zhai, H. Chang, Y. Zhen, X. Liu, X. Chen, and W. Gao, “Parametric local multimodal hashing for cross-view similarity search,” in Proc. 23rd Int. Joint Conf. Artif. Intell., 2013, pp. 2754–2760.
[7]. D. Zhang and W.-J. Li, “Large-scale supervised multimodal hashing with semantic correlation maximization,” in Proc. 28th AAAI Conf. Artif. Intell., 2014, pp. 2177–2183.
[8]. G.E.Hinton, “Learning distributed
representations of concepts,” in Proc. 8th Annu. Conf. Cognitive Sci. Soc., 1986, pp. 1–12. [9]. T. Mikolov, M. Karafiat, L. Burget, J. Cernockỳ,
and S. Khudanpur, “Recurrent neural network
based language model,” in Proc.
INTERSPEECH, 2010, pp. 1045–1048.
[10]. D. Zhang, J. Wang, D. Cai, and J. Lu, “Self-taught hashing for fast similarity search,” in Proc. 33rd Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, 2010, pp. 18–25.
[11]. Y. Zhuang, Y. Yang, F. Wu, and Y. Pan, “Manifold learning based cross-media retrieval: A solution to media object complementary nature,” J. VLSI Signal Process. Syst. Signal, Image Video Technol., vol. 46, pp. 153–164, 2007.
[12]. F. Wu, H. Zhang, and Y. Zhuang, “Learning semantic correlations for cross-media retrieval,” in Proc. IEEE Int. Conf. Image Process., 2006, pp. 1465–1468.
[13]. J.L.Elman, “Distributed representations, simple recurrent networks, and grammatical structure,” Mach. Learn., vol. 7, pp. 195– 225, 1991.
[14]. Y. Gong, S. Kumar, V. Verma, and S. Lazebnik, “Angular quantization-based binary codes for fast similarity search,” in Proc. Adv. Neural Inf. Process. Syst., 2012, pp. 1196–1204.
[15]. K. Grauman and R. Fergus, “Learning binary hash codes for largescale image search,” in Proc. Mach. Learn. Comput. Vis., 2013, pp. 49–87. [16]. D. Zhang, J. Wang, D. Cai, and J. Lu,
“Self-taught hashing for fast similarity search,” in Proc. 33rd Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, 2010, pp. 18–25.
[17]. Y. Yang, Y.-T. Zhuang, F. Wu, and Y.-H. Pan, “Harmonizing hierarchical manifolds for multimedia document semantics understanding and cross-media retrieval,” IEEE Trans. Multimedia, vol. 10, no. 3, pp. 437–446, Apr. 2008.
[18]. E. P. Xing, R. Yan, and A. G. Hauptmann, “Mining associated text and images with dual-wing harmoniums,” in Proc. 21st Conf. Uncertainty Artif. Intell., 2005, pp. 633–641. [19]. Q. Zhang, Y. Zhang, H. Yu, and X. Huang,
“Efficient partial duplicate detection based on sequence matching,” in Proc. 31st Annu. Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, 2010, pp. 571–578.
[20]. N. Giacaman and O. Sinnen. “Parallel Task for
parallelizing object-oriented desktop
applications,” In Proc. of 11th IEEE Int. Workshop on Parallel and Distributed Scientific and Engineering Computing (PDSEC-10) (in conjunction with IPDPS2010), Atlanta, USA, April 2010. IEEE Press.
[21]. N. Giacaman and O. Sinnen. “Parallel Task for
parallelising object-oriented desktop