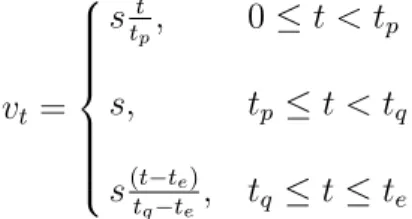A Software Implementation Progress Model
Dwayne Towell
June 28, 2004
ACKNOWLEDGEMENTS
I would like to thank my wife, Lydia, for her support and understanding. I could not have done this work without her support.
I would also like to thank my advisor, Dr. Jason Denton, for his guidance and critical review. His understanding of and advice about the academic world was an invaluable aid during my transition and this work.
Many thanks go Terry Hamm and Roger Arce for access to project archives that made this study possible. Without their support this would still only be an idea. Additional thanks go to friends and family who supported this work by many dierent contributions. They include Roger Bonzer, Dr. Mike Frazier, Dr. Rusty Towell, Marta E. Calderon-Campos, and countless others. Thank you all.
This work is dedicated to Ayrea and Robert, my children and the world's greatest kids, hands down.
TABLE OF CONTENTS
ACKNOWLEDGMENTS ii
LIST OF TABLES vii
LIST OF FIGURES viii
I. INTRODUCTION 1
1.1 Need for Models 3
1.2 Model Requirements 4
1.3 Implementation Progress Model Requirements 6
II. RELATED WORK 9
2.1 Implementation Evaluation and Control 10
2.2 Time-Series Shape Metrics 13
2.3 Process Models 15
III.RESEARCH DESIGN 18
3.2 Implementation Progress Model 21
3.3 Model Interpretive Value 25
3.4 Data Requirements 28
3.5 Data Collection 31
3.6 Data Source 32
IV.EFFORT METRICS 34
4.1 Source Lines of Code 34
4.2 McCabe Complexity 36
4.3 Halstead Volume 38
4.4 Other Metrics 40
V. RESULTS 42
5.1 Alternative Models 42
5.2 Model Fitting Results 44
5.5 Conforming Cases 61 VI.CONCLUSIONS 67 6.1 Limitations 67 6.2 Interpretation 68 6.3 Future Work 69 REFERENCES 71
ABSTRACT
Current software project management techniques rely on collecting metrics to provide the progress feedback necessary to allow control of the project; however, interpretation of this data is dicult. A software implementation progress model is needed to help interpret the collected data. Criteria for an implementation progress model are developed and an implementation progress model is proposed. Findings from the studied projects suggest the model is consistent with the observed behav-ior. In addition to quantitative validity, the model is shown to provide meaningful interpretation of collected metric data.
LIST OF TABLES
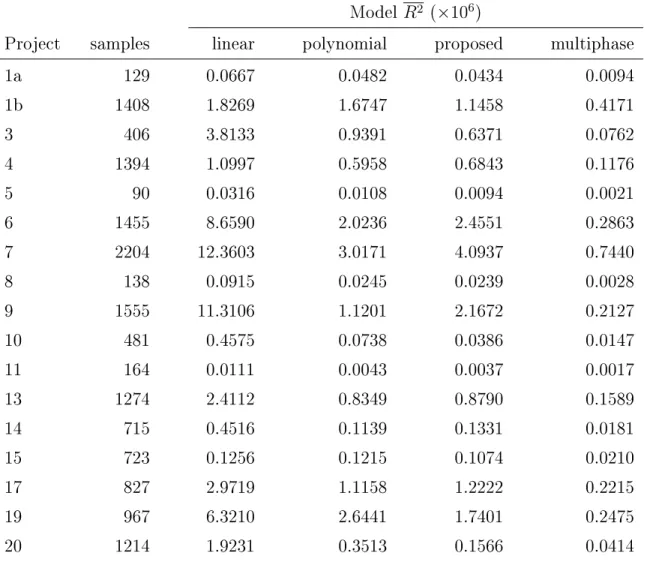
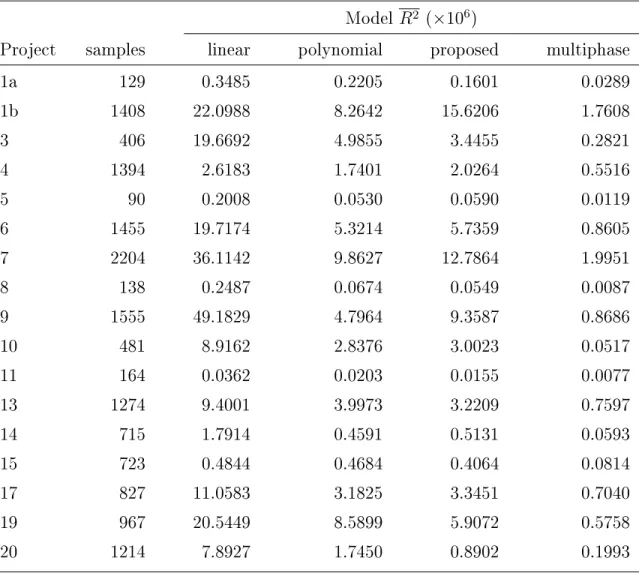
5.1 Average squared residual error (R2) for implementation progress models measuring source lines of code changed (SLOCC) by project. 53 5.2 Average squared residual error (R2) for implementation progress models
measuring code churn (CHURN) by project. 54
5.3 Average squared residual error (R2) for implementation progress models measuring cyclomatic complexity change (MCC) by project. 55 5.4 Average squared residual error (R2) for implementation progress models
measuring Halstead length change (HLC) by project. 56
5.5 Source lines of code change (SLOCC) progress model parameters and
R2 relative to linear R2. 62
5.6 Code churn (CHURN) progress model parameters and R2 relative to
linearR2. 63
5.7 Cyclomatic complexity change (MCC) progress model parameters and
R2 relative to linear R2. 64
5.8 Halstead length change (HLC) progress model parameters and R2
LIST OF FIGURES
3.1 Accumulated change metrics for a typical project by day. 19 3.2 Idealized implementation velocity as a function of time. 23 3.3 Idealized implementation progress as a function of time. 23 5.1 Progress measured via accumulated Halstead length change (HLC) for
project nine and progress model curves (with R2). 45
5.2 Progress measured via accumulated cyclomatic complexity change (MCC) for project ten and progress model curves (withR2). 47 5.3 Weekly progress measured via accumulated cyclomatic complexity change
(MCC) for project ten and velocity model curve. 48
5.4 Progress measured via accumulated code churn (CHURN) for project
fteen and progress model curves (withR2). 49
5.5 Progress measured via accumulated cyclomatic complexity change (MCC) for project four and progress model curves (withR2). 50 5.6 Source lines of code change (SLOCC) average squared residual error
(R2) relative to linear R2. 57
5.7 Code churn (CHURN) average squared residual error (R2) relative to
linearR2. 58
5.8 Cyclomatic complexity change (MCC) average squared residual error
(R2) relative to linear R2. 59
5.9 Halstead length change (HLC) average squared residual error (R2)
CHAPTER I INTRODUCTION
Modern software development practices rely on periodically collected software metric data to provide management with feedback about the project and the process used to develop it. Metric data is most commonly used in the area of quality as-sessment. Well-dened metrics exist to report on quality attributes such as expected number of remaining faults. However, other areas, such as implementation progress, make much less use of metric data for feedback. Metrics, such as total source lines of code, could be used to report on implementation progress but measures such as these have not been leveraged as strongly as quality assessment has used its mea-sures. Metric data is widely regarded as a valuable management feedback tool, yet it is generally not used to monitor implementation progress.
An implementation progress model is presented and shown to identify project phase boundaries, express the rate of implementation during each phase, and allow objective comparisons between projects. This study provides a framework to help interpret periodically collected implementation data. This work develops a model for interpreting implementation progress. The proposed progress model uses existing implementation artifact metrics, matches our intuitive understanding of the imple-mentation progress, and allows project estimation based on parameter estimates.
Well-dened and proven metrics exist for many areas of software development including especially quality assessment. Implementation progress has no such
estab-lished metrics. Several existing metrics measure size-related attributes. While these size-related metrics may have been originally developed to support quality assess-ment, they can be used to monitor progress in terms of size. Project size is important because it is invariably used to estimate the resources needed and assess the project's status with regard to the schedule (DeMarco 1982; Albrecht and John E. Ganey 1983; Lind and Vairavan 1989; Jorgensen 1995). This compelling management need for feedback about implementation progress should demand its use. Its absence may be because metrics have not been established to support implementation progress feedback.
The lack of proven implementation progress metrics has been a barrier to any attempt to monitor implementation progress. However, the lack of a proven metric is not insurmountable. Size metrics are abundant and deriving a progress metric from a size metric can be accomplished by taking the dierence in consecutive size measurements. A far larger barrier than the lack of a metric is the lack of a proven implementation progress model. Periodically collected data is rich in detailed infor-mation but is not inherently meaningful. A model provides a specic interpretation of the data and allows meaning to be extracted. An implementation progress model will allow periodically collected implementation data to be interpreted.
1.1 Need for Models
Models bridge the gap between concrete sampled data and expectations. On a small scale, models act as predictors to set expectations over the next few data samples. For example, a defect model may indicate the number of faults to be found in the next release candidate. The degree to which the actual number of faults discovered diers from the predicted value can be an indication of unexpected circumstances within the project. For instance, an unusually low value (when compared with the predicted value) may indicate fewer code changes were made than expected, or that less testing was performed than expected. Management has been forewarned; an investigation can be made and the appropriate response can be taken. This small scale feedback provides valuable and timely feedback to management within the scope of the project.
In addition to this small scale feedback, models provide feedback on a larger scale, outside the scope of a single project. Large scale feedback assumes an entire project can be boiled down to its essence. Large scale feedback is less concerned with local variations and more concerned with the overall picture portrayed by the data. This essential portrait is regularly required by management, with or without a formal model. Without a formal model members of management must rely on guesses and antidotal evidence. In contrast to this haphazard approach, a formal model es-tablishes a rigorous evaluation. A formal model eses-tablishes the critical parameters within the system. Using a formal model, projects may be evaluated or compared in
terms of the model parameters. Model parameters allow evaluation and comparisons to be based on defendable data rather than guesses and hearsay. Additionally, given estimated values for the parameters, the model can make predictions about the out-come. This relationship between parameters (input) and predictions (output) codies a causal eect believed to be true within the system.
1.2 Model Requirements
The primary purpose of a model is to provide a documented method of in-terpreting a set of data. In many cases the interpretation is masked by the sheer quantity and detail of the data available. Information is revealed when the data is interpreted in a particular way. The interpretation results can be used to evaluate past performance, assess the current situation, and make predictions about future performance. The interpretation can also be used to compare multiple data sets. Results from the same model, applied to several data sets, allow the data sets to be easily compared in terms of the model. The model provides a systematic method for comparing projects.
One type of model interprets series data by attempting to t collected data to a family of curves. The single curve which best ts the data is used to describe the data in terms of the model. The specic values used to generate the best tting curve are considered parameters of the model. Parameters of a model reveal one or more dimensions of the collected data. In this case, parameters can be considered an
output of the model. Collected data is the input and results summarizing that data are produced. Parameters can also be used as input resulting in expected sample data. When used in this way, models make predictions based on estimated parameters. In either case, the expected progress as dened by the model is given by the model curve. The model equation and a specic set of parameters dene the model curve.
A valuable model is one that produces a clear and concise interpretation of the data. Part of this interpretation is in the form of the specic values for the model parameters. For example, consider two models, one uses only two parameters while the other has eight parameters. Even though the eight-parameter model may predicts the data twice as well, it may not be the better model if its parameters have no particular meaning or are hard to estimate.
Models should have as few parameters as possible while still modelling the data with sucient accuracy. Fewer parameters means the model is easier to under-stand. Part of understanding a model is understanding the relationships between the parameters. Parameters are related by the aects each has on the others. Knowing the trade-os between parameters is necessary to understand a model. This is easier if the model contains fewer parameters.
In addition to relatively few parameters, individual model parameters should be understandable. Understandable parameters produce simple results with meaning. On the other hand, meaningless parameters do not help to simplify or interpret the data since they must again be interpreted. Parameter meaning is even more important
when the model is used as a predictor for new projects. In this case, model parameters must be estimated before any data has been collected. If the individual parameters are well understood better estimates for each will be made. Better estimates will produce better predictions.
Related to individual parameter meaning is the parameter unit. Model pa-rameters should be expressed in well-known units, rather than new or arbitrary ones. Parameters with direct interpretations allow the model results to be easily understood and used. Well-known units are also much easier to estimate. Again, this allows for better predictions.
Model parameters should be few in number, directly interpretable, and mea-sured in existing units. These properties give the model parameters the most meaning and thus give the model the most clarifying power.
1.3 Implementation Progress Model Requirements
In addition to general model requirements, an implementation progress model must be compatible with existing models. Implementation progress is not a new con-cept. An informal progress model already exists; it can be seen in project vocabulary and assumptions. For example, project members speak of getting over the learning curve and being up to speed. This informal model is commonly used to answer common project status queries, such as:
What is the expected completion date based on the current pace? What was the size of the total eort for that project?
What fraction of the total eort is currently done?
What fraction of the total eort will be done by a certain date?
A proposed implementation model should serve the same purpose as the informal model. The model must help provide answers to questions about implementation speed and progress of current and future projects.
The informal progress model captures another key attribute of implementa-tion progress. The informal model acknowledges that project speed is not constant throughout a project: projects ramp up and slow down. These phrases refer to project speed and suggest the ability or desire to determine implementation velocity. As envisioned by experienced project managers, this velocity increases at the begin-ning and decreases near the end (McConnell 1998). A formal implementation progress model should be informed by this experience and capture the canonical variations in velocity during implementation.
In summary, the desired attributes of a formal implementation progress model include: relatively few parameters, understandable parameters, well-known parameter units, consistency with informal progress model, and the ability to answer manage-ment questions involving size and velocity.
The next chapter (II) discusses supporting work indicating the need for a progress reference model. Chapter III describes the proposed implementation progress model, hypothesis, and research process. The specic metrics used are presented in Chapter IV including description, discussion and support for each. Results from
actual projects are presented in Chapter V. Finally, conclusions and directions for future study are in Chapter VI.
CHAPTER II RELATED WORK
Previous work applying software metrics to the development process has pri-marily been targeted at tasks before and after implementation. Much work has been done in the pre-implementation stages to improve eort prediction and estimation (Al-brecht and John E. Ganey 1983; Lind and Vairavan 1989; Jorgensen 1995; Boraso, Montangero, and Sedehi 1996; Turski 2002). Metrics have also been used to evaluate architectural design before implementation. Signicant work has been done in the post-implementation stages to predict failure rates, both for a product as a whole as well as for individual modules (Jelinski and Moranda 1971; Goel and Okumoto 1979; van Solingen and Berghout 1999; Fenton and Neil 1999; Schneidewind 1999). However, substantially less work has been published regarding the use of metrics for assessment, monitoring, or control of the implementation stage itself.
DeMarco asserts you can't control what you can't measure (DeMarco 1982, page 3). Indeed, every researcher proposing, defending, or merely discussing a metric agrees the reason behind metrics and measuring is to gain some degree of understand-ing and control over the complex process of software development (Fenton and Neil 2000). Recent studies have focused attention on how to use the vast array of data generated by existing measures.
Published works emphasizing how to use the potentially enormous data avail-able can be coarsely divided into three groups. Many works assert metrics should be
used to assist in monitoring, evaluation and control of projects during the implemen-tation phase (DeMarco 1982; Basili and Rombach 1988; Boehm 1988; Lott 1993; van Solingen and Berghout 1999; Kirsopp 2001). Other researchers recommend speci-cally that time-series metrics data be used to monitor and evaluate projects (DeMarco 1982; McConnell 1998; Schneidewind 1999). Finally, several researchers emphasize the insight gained from causal models over correlative models (Powell 1998; Fen-ton and Neil 2000; Turski 2002). They suggest models which provide an inherent causes-relationship are more valuable than simpler correlation models.
2.1 Implementation Evaluation and Control
DeMarco presents a development process relying on steadily improving es-timates to provide feedback and control during all phases of software development (DeMarco 1982). Metrics collected at each stage of development provide raw data for creating an improved estimate for the next stage. Metrics from the current project as well as previous projects are used to inform decisions. Inherent throughout his work is the requirement for continuing feedback via improving estimates, allowing the devel-opment eort to be directed. A compelling case supporting estimate reviews, process metrics, cost models and quality improvement is developed. DeMarco identies and recommends metrics appropriate for each stage of development.
In discussing appropriate metrics for the implementation stage DeMarco al-ludes to process metrics such as compilation rate but does not explore them. The
primary implementation measure is code weight, which is dened as a product of two dimensions: size and complexity. DeMarco denes code size as information content within a program. He recommends using Halstead's volume metric (Halstead 1977) to nd size. Several alternatives for measuring complexity are presented, but McCabe's cyclomatic complexity measure (McCabe 1976) is recommended. Using these two dimensions as parameters, an algorithm is presented for computing implementation weight. Historical data from similar projects and environments is also used to provide scaling factors. According to DeMarco, the primary motivation for computing imple-mentation weight is to improve future project estimates. However, he also calls it a project predictor, that is, it should predict the nal size of the project accurately. According to the system presented by DeMarco, the measure should be taken once near the middle of implementation. The progress model described in this study may provide a better estimate of implementation size. Since the proposed model considers the complete project history, not simply a single point in time, it is less susceptible to anomalies.
Boehm takes a broader approach to development feedback than simply fo-cusing on improved estimates. He introduces a software development methodology whose principle goal is risk management (Boehm 1988). His spiral model of software development relies on risk evaluation as the impetus for each unit of work, whether the work unit is a prototype, design document, or code. Risk management implies the ability to control what is being managed. This agrees with DeMarco's argument
that our need to measure the software development process stems from our desire to control the process (DeMarco 1982). Boehm's methodology assumes feedback metrics exist to inform the risk evaluation process, but does not dictate specic measures or measurement processes.
Addressing the selection of appropriate metrics for quality control, Solingen and Berghout dened the Goal/Question/Metric Method (GQM) of improving soft-ware quality (van Solingen and Berghout 1999). GQM integrates metrics into the development process in order to answer questions about quality raised by corporate goals. Their methodology relies on the ability to follow the connection between cor-porate goals and specic metrics, in both directions. Measurements are dened by goals and the results interpreted in terms of those goals. In the area of quality control, well developed process models exist to help dene and interpret metrics. However, implementation models in general, and implementation progress in particular, have not been as well developed.
Kirsopp addresses the need to capture development models and enough data to evaluate them. He strongly argues that the software development process needs measurements for feedback and that the integration must be close, detailed and ap-propriate (Kirsopp 2001). Organizations must support metrics outside of a single project in order to validate the process, validate the results, and collect historic data. All three of these are required to assist future project estimates. An experience fac-tory provides a reposifac-tory for captured experiences and models, allowing reuse within
an organization. Kirsopp cites the TAME (Tailoring a Metric Environment) Project (Basili and Rombach 1988) as a working example of an experience factory.
Lott provides an alternative approach; instead of suggesting or analyzing met-rics, he studied several available and proposed software engineering environments (Lott 1993). Many of these environments include integrated tools for collecting nu-merous metrics about various development artifacts created. Lott suggests collected data can be used to guide development and to call attention to atypical patterns wor-thy of investigation. In this regard, he assumes time-series data will be collected and evaluated. Inherent in this idea is the development of a canonical pattern or typical shape for a particular metric. Unfortunately, neither Lott nor the systems studied dene how to select or interpret the automatically collected measurements.
2.2 Time-Series Shape Metrics
In addition to estimation, DeMarco briey notes that process metrics, such as compilation rate, can be used to identify project dysfunction and impending problems (DeMarco 1982). Periodic sampling of a metric allows the value measured to be graphed against time. For some measures, such as compilation rate, healthy projects may all have similar shapes when viewed as time-series data. If this is the case, unhealthy projects can be detected if or when they deviate from the canonical shape. For example, DeMarco suggests compilation rates that continue at a steady rate without showing any decline may be an indication of a thrashing development team.
While this particular evaluation may not apply to all development environments, the idea of a healthy canonical shape can be applied to all environments. In another instance, he recommends reporting test progress as a graph showing measurements against time. Time-series graphs make it clear how test progress has been proceeding and how its trends change over time. In general, comparing the current project with similar historic projects using graphs can highlight abnormal trends which may be an indicator of trouble. Given DeMarco's emphasis on continuous monitoring and improvement, it is surprising he does not suggest using implementation artifact metrics, such as size or complexity, to monitor implementation progress.
Schneidewind used time-series metrics to create a method for evaluating pro-cess stability (Schneidewind 1999). He illustrates its use by evaluating the propro-cess stability of the NASA Space Shuttle ight software development eorts. Schnei-dewind emphasizes that metric trends are a signicant indicator of the underlying process and monitoring the trends can provide feedback about the process. To quan-tify these trends, he introduces two new classes of indirect metrics. A change metric is computed using dierences in consecutive values of a traditional metric. This met-ric can be viewed as the derivative of the primary metmet-ric. The other class of indirect metric introduced is the shape metric. A shape metric is derived from the curve of the time-series metric data when graphed against time. For example, one shape met-ric suggested is the time at which the failure rate is highest. Lower values for this metric may indicate process stability, while higher values may indicate instability in
the development process. A strong case is presented for the use of time-series data, and indirect metrics derived from it, in the context of process stability. Monitoring progress during the development stage using change and shape metrics is an obvious extension of this study.
McConnell understands typical code growth on a project to contain three distinct phases (McConnell 1998). In the rst phase, architectural development and detailed design generate very little code. The second phase provides staged deliveries and includes detailed design, coding, and unit testing. During this phase code growth is very high. During nal release, the third phase, code growth slows to a crawl. McConnell shows a graph depicting a typical code growth pattern for a well-managed project. He indicates the phase transitions occur at approximately 25% and 85% of the total development time, but acknowledges that this varies to some degree. His main point is periodic monitoring of code size is a valuable feedback tool for managers. No details are given about the specic metric(s) involved or the process used to collect the data. The proposed progress model claries how metrics are used and provides a specic interpretation of the three phases documented by McConnell.
2.3 Process Models
Powell expands the role of software measurement to explicitly include not only prediction and control but also assessment and understanding (Powell 1998). He makes arguments for assessment similar to those presented by Boehm and DeMarco
for prediction and control. Regardless of the motive, measurements are always based on assumptions about the process in which the measurement is taken. Powell states it is impossible to talk about measurements without implying some form of [process] model (Powell 1998, page 5). Before measurements can be taken, and before metrics can be determined, a model of the development environment must be chosen.
Fenton and Neil proposed using Bayesian belief networks (BBNs) to model development environments (Fenton and Neil 2000). BBNs integrate causality, uncer-tainty, and expert subjective input to generate answers and assist in decision making. They observe the current lack of metrics in common practice, within the software development community, and blame a lack of realistic decision making models. Many existing models are simplistic in that they show strong correlations between measures but do not properly model causality. Using BBNs allows better causality modelling to be achieved. This allows the answers generated to be both more accurate and traceable. BBNs encode beliefs about the causality of a process in the network. The parameters can be populated with known values, known distributions or even sus-pected distributions. Answers computed show not only the likely result but its range and distribution. BBNs provide a general solution to the problem of model encoding. Turski presents a model for understanding the observed rate of software growth as a function of time (Turski 2002). Using the number of modules as the dependent variable and uniform interrelease intervals as the independent variable, he shows size correlates strongly with the third root of time (size = √3
the bases of Lehman's Laws of Software Evolution (Lehman, Ramil, Wernick, and Perry 1997), Turski uses a simple mental model to understand the same relationship. He suggests envisioning a system as a sphere with surface modules being easy to modify while interior modules are much harder to modify. With this model in mind, it is easy to see that the proportion of easy modules to hard modules tends toward zero as the project (sphere) grows with time.
Turski believes that simple and manageable models, such as that described above, provide powerful insights into understanding the forces at work in software development. In particular, models which exhibit causal relationships rather than simple statistical correlations provide not only better interpretation but improved understanding of the process. He suggests similar back-of-an-envelope models be developed precisely because they are simple to understand and intuitive. He expresses concern that so few causal-model-based arguments have been presented in the litera-ture to date. The progress model proposed here includes such a simple and intuitive interpretation of the implementation process.
CHAPTER III RESEARCH DESIGN
This chapter presents the implementation progress model studied and proce-dures used in the study. First, the proposed model is described in detail along with the rationale for it. This is followed by a description of the analysis process. Then, the data required for the study is discussed. Finally, a summary of where appropriate projects were found and how the data was collected is presented.
3.1 Existing Progress Models
Project managers have developed an intuition about what should occur during a software development eort. An implementation progress model should be consis-tent with this experience. A condensed version of this collective wisdom is presented by McConnell (McConnell 1998). He uses code growth as an measure of progress and provides a nominal code growth pattern as well as a range of normal variations for well-run projects. An appropriate progress model should reect the basic shape of accepted norms such as those presented by McConnell.
Another constraint on choosing an appropriate implementation progress model is its interpretive power. Interpretation of metric data relies on some understanding of or belief about the underlying process. For example, changes in the rate of progress in an otherwise stable environment may indicate the project has transitioned to a
0 10000 20000 30000 40000 50000 60000 70000 0 50 100 150 200 250 days ac cu m u la te d p ro g re ss
source lines of code change code churn / 2
cyclomatic complexity change * 5 Halstead length change / 5
Figure 3.1: Accumulated change metrics for a typical project by day.
new phase. This assumes the rate of progress is dependent on the project state. This process of drawing meaning from data, such as when a phase ends, is interpretation. An implementation progress model must approximate actual project data col-lected. Figure 3.1 shows several common metrics sampled from the implementation phase of one project studied. The values have been arbitrarily scaled to allow si-multaneous viewing of the four measures. The similar shape observed between data sets suggests the metrics are highly correlated. This observation has been shown previously (Lind and Vairavan 1989; Lake and Cook 1994).
The data in Figure 3.1 is very similar to that described by McConnell. Each data series has approximately the same shape, an S-like curve. Initially the project makes very little headway, but over a period of about seventy days the rate of progress improves. During this time the project experiences a period of increasing speed as resources are added and things get up to speed. For the next 100 days the metrics show approximately linear progress. Here the project experiences a time of continuous, even-paced development during which much of the work is accomplished. This is the period of highest eciency for the project. Finally, during the last eighty days progress continues but at a steadily slowing pace. The project experiences a time of lower eciency as it nears completion and attention to detail is paramount.
This graph demonstrates the important characteristics of typical progress data. Overall progress is not linear with time, but approximately linear progress occurs during the middle of the project. This sample and experience suggest the beginning and end of the project contribute the least to overall progress. This means the fastest pace occurs during the middle of the project while the ends are slower paced. The slope of the progress curve indicates the speed of progress. The graph is consistent with both expectations about progress and speed. The slope of progress (velocity) can be used to determine how and when the project transitioned from ramping up to its sustainable rate of progress. Likewise, near the end of the project, a slope change indicates a change in velocity which may indicate a change in process and possibly goals.
The typical slow startup phase may be partly due to resources being added, team members establishing relationships, and processes developing within the project group. McConnell suggests detailed requirements understanding and architecture may still be under development during the startup phase as well (McConnell 1998). Steady fast development begins only after this initial investment period. As the project nears completion the rate of progress decreases. This slowing may be due to ineciencies related to critical paths, loss of resources, defect removal and attention to detail required to meet nal deliveries.
DeMarco acknowledges this non-linear relationship in his advice about when to collect implementation metrics (DeMarco 1982). He strongly advocates the need for feedback throughout the development process, however recommends only a single sampling of size metrics near the middle of the implementation phase. This incon-sistency is understandable after examining his assumptions. DeMarco uses a linear model which is required to pass through the origin and the current project implemen-tation weight (size). It can be easily seen in Figure 3.1 the only time an origin-based, linear model will be accurate is if the sample point is near the middle of the project.
3.2 Implementation Progress Model
Before attempting to characterize implementation progress for a complete project, it is appropriate to consider a denition for implementation progress. Soft-ware implementation is the activity of creating artifacts which contribute to the goal
of delivering a working system. Implementation progress is the amount of change in an artifact over the time needed to produce the change. Progress is best measured as the sum of many changes rather than any single measure. This is due to the volatile nature of implementation; code may be added, removed, moved or changed. The sum of these individual measurements is a better approximation of the total progress than any single measurement. This is similar to the way an odometer is a better measure of distance travelled than simply the distance from the starting point.
An individual implementation progress measurement captures implementation artifact change over time. Change over time is velocity, so individual progress mea-surements attempt to capture implementation velocity. If implementation velocity is in anyway analogous to velocity found in the natural world, it cannot change in-stantaneously. It is reasonable to assume implementation velocity does not change instantly, so the rst derivative (velocity) of the implementation progress model must be continuous.
Experience suggests implementation velocity begins and ends at zero while being at its highest in the middle. The simplest implementation velocity graph, con-sistent with experience, consists of three linear segments. Implementation velocity begins at zero. It increases linearly until the maximum sustainable velocity for im-plementation has been reached. The velocity remains constant until near the end of implementation when it begins to decrease. Implementation velocity constantly decreases until it reaches zero.
project time
Figure 3.2: Idealized implementation velocity as a function of time.
project time
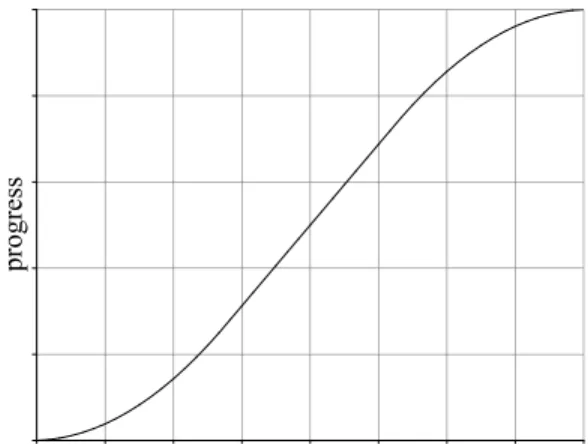
Figure 3.3: Idealized implementation progress as a function of time.
Figure 3.2 shows the idealized implementation velocity for a project as a func-tion of time. The horizontal, center phase represents the steady, ecient development observed in the middle of the implementation phase. The positive slope at the left represents increasing velocity as implementation gathers speed. This increasing pace may be the result of adding resources or team members establishing roles within the project. The negative slope at the end of the graph shows the implementation phase decreasing speed as the end approaches. The slowing may be due to ineciencies related to critical paths, loss of resources, and attention to detail required to meet nal deliveries. Slope changes in a graph showing velocity are good indicators of a change in the environment, such as mode of development or goal for the project. In the idealized graph shown in Figure 3.2 the slope changes indicate respectively that, the project has reached its maximum sustainable velocity, and the team is attempting to complete all tasks rather than maintain velocity.
The idealized graph shown here is symmetric; however, symmetry is not com-mon in practice and is not required by the model presented. The idealized velocity as a function of time (vt) can be described using four parameters.
vt= stt p, 0≤t < tp s, tp ≤t < tq s(t−te) tq−te, tq ≤t ≤te (3.1)
Equation 3.1 gives the velocity as a function of time, where s is the maximum
sus-tained velocity, tp and tq are the times of the phase transitions, and te is the time at the end of implementation. Time may be measured in any real unit, such as days. Pseudo-time units such as releases, deliveries, or builds are not recommended unless an equal amount of resources are spent during each interval. Velocity is measured in size of metric change per time unit, such as lines of code per day.
Integration of the idealized velocity for a project produces idealized progress as a function of time (pt). pt= s2tt2 p, 0≤t < tp st− 1 2stp, tp ≤t < tq s(t 2−2t et+t2q+tpte−tptq) 2(tq−te) , tq ≤t≤te (3.2)
Figure 3.3 shows an idealized implementation progress curve as a function of time. Equation 3.2 gives the implementation progress as a function of time. Progress is measured in accumulated metric change to date, such as total lines of code changed.
The proposed model is consistent with ideas proposed by others. Schneidewind suggests artifact metric trends may be used to study the stability of the development process (Schneidewind 1999). He denes process stability as continued improvement in an artifact metric over time. This relationship between artifact metrics and process metrics is stated clearly by Woodings and Bundell. They assert the derivative with respect to time of a valid product metric is a valid process metric (Woodings and Bundell 2001). The product metric, in the proposed model, is any size-related measure of code. The derivative of size is growth or implementation velocity, a measure of the implementation process.
3.3 Model Interpretive Value
Time-series data sets are rich sources of raw data. However, the metric data itself does not directly characterize the project progress. Trends within a data set contain much of the global meaning (DeMarco 1982; Schneidewind 1999). Extracting meaning from this data remains dicult due to noise inherent in both the sampling mechanism and the process being measured. Extracting meaningful information from the data relies on a belief about or understanding of the process which produced it and its essential variables. The model allows the process data to be interpreted. Or, in other words, any modelling is an interpretation of the principle mechanisms operating within the process.
Models with fewer parameters are preferred to models with many parameters. Fewer model parameters reduces ambiguity and avoids overtting. As the number of parameters in a model grows the likelihood that non-orthogonal parameters exist increases. Non-orthogonal parameters allow multiple sets of parameter values (so-lutions) to model the data equally well. If multiple parameter values produce an equally good t the model does not help dierentiate between the solutions. A model resulting in a single solution does not require an external dierentiator and thus its solution has captured more meaning. Another reason few parameters are preferred is to avoid overtting. Overtting occurs when the model attempts to capture details at or below the level of noise in the system. When overtting occurs the model loses generality and become specic to a particular data set or sets. To avoid overtting only parameters required by the interpretation are included in the model.
As described above the model includes four parameters (s,tp,tq,te). However, care must be taken when counting model parameters. Other projection models do not include specic knowledge of the terminal condition. The terminal condition is external in these models. Using these models, identifying the end time, for example, is a property of the model parameters and the total size. In this example, total size is eectively an additional parameter required to determine the end time. However, total size is not a parameter determined by tting. Similarly, te is not determined by tting; it is simply taken to be the maximum time in the data set. The proposed model uses only three parameters which require tting. Since implementation progress
has been seen to be both convex and concave, three parameters can be considered a minimum parameter set.
A model expressing results in concrete units provides better insight than an otherwise similar model using arbitrary or ambiguous units. The proposed model does not include any scaling factors, constants, or other arbitrary parameters. The proposed model uses only two units: time and change. Both time and metric-change are well-know units, understandable, and have obvious meaning to both de-velopers and managers. An intuitive understanding of the units, time and metric-change, allows them to be easily used in planning and evaluation. Because they are well-known, they require no special experience or rules of thumb normally associ-ated with scaling factors, constants and other invented parameters. By using concrete units the model results may be easily related back to the project. This allows the results to be directly used to advice management about the project.
The proposed progress model helps answer speed and estimation questions. The model parameters can be directly used to answer management questions about project size and the speed of development. By providing a solution in readily usable form, predictions for what if scenarios are easily computed.
The proposed model allows for project implementation comparisons. Models allow data collected from dierent projects to be compared. Results from the same model applied to dierent data sets can be compared, revealing dierences in the projects. A model also allows projects to be compared across time or under dierent
circumstances. As more project results become available, historic baselines can be de-veloped. Eventually canonical proles for each set of circumstances can be produced. Proles, baselines and the ability to compare projects allow better predictions to be made.
3.4 Data Requirements
Before project implementation can be evaluated or compared, data about the implementation must be collected. The implementation progress model proposed as-sumes an appropriate measure of progress is available. Ideally this measure would report eort expended wisely, real progress made, or even percent of work com-pleted. Unfortunately these highly-desirable metrics are not available. Instead, a surrogate measure is used with the knowledge that the dimension sampled is not the actual quantity desired (Fenton 1991). In this case, the quantity sought is imple-mentation progress. Choosing an accurate surrogate measure of progress depends on one's denition of progress. It may seem tempting to include all activities involved in implementation when dening this dimension. However, the many activities re-quired during implementation are quite diverse. This diversity is so large that the only measures they have in common are time (or money) required to complete them. Measuring resources expended is valuable because it allows results (progress) to be compared with expenses. In order to allow this comparison, resource measurements must be independent from progress measurements.
All of the diverse implementation activities contribute to progress in their own way. Measuring each activity may be possible, but this approach does not easily produce a consolidated measure unless the individual metrics are summed. Summing many dierent metrics is fraught with problems such as identifying all components and determining the correct weights for each. To avoid dening a progress metric as the sum of many others, we dene implementation progress in terms of the one absolutely required engineering artifact necessary to deliver a software project: code. Here we dene implementation progress as a measure of the total eort captured in deliverable code. For environments and phases that emphasize code as the primary engineering delivery, this is an appropriate denition.
Limiting the search for a metric to an accurate measure of captured eort within code still leaves a dicult task. Many code metrics and variations have been proposed. A review of methods for quantifying software change covering many dier-ent research areas concludes: the most practical, successful measures to date appear to be based on simple atomic counts (Powell 1998, page 14). Even restricting a search to simple atomic count metrics leaves many options. Many of the metrics available today are primarily used for static analysis. For example, they may be used to predict the probability that a module contains a fault rather than the total amount of eort required to create it.
This study is interested in measuring progress in implementation artifacts. Progress was measured as artifact change over time. Existing units of internal change
were unavailable, so an appropriate unit was developed. Implementation artifact metrics traditionally used to statically measure size form the basis of the metrics used in this study. Since this study was interested in evaluating change as a function of time, the dierence between consecutive samples was used. The change metric is dened as the absolute dierence between consecutive samples of a size metric. This represents the change in the dimension of the size metric over the time interval between samples. Equation 3.3 shows ∆m,t is the change in a metric m at time t.
∆m,t =|mt−mt−1| (3.3)
The absolute value of each dierence was used. This assumes that the correct removal of code artifacts was approximately as challenging as correctly adding the code. This point could be contested by those claiming that removing code is easier than adding code. While that may be true, it cannot be claimed that the removal eort represents progress away from the goal, which would be the case if negative eort was permitted. To avoid introducing a weighting factor for negative changes, all changes were treated equally. These new metrics measure the size of change over the sample interval, or in other words, they give a measure of implementation progress. Existing artifact measures shown to be related to size were chosen for this study. Chapter IV discusses the specic details of each metric used.
3.5 Data Collection
In a team environment, software implementation occurs in parallel as each team member works semi-independently. From the perspective of the project source repository, development occurs simultaneously across many source les. This chaotic environment means capturing progress for a complete project requires summing the change from many individual source les. Similarly, multiple changes within a single le are accumulated to nd the total change across the time interval of interest.
Collecting measurements of implementation change would typically be done as each source le was submitted to the project source repository. This mechanism helps provide part of the real-time data needed to manage the project. For this study, live projects were not available, however project source repositories with version-control were available. These source repositories allow source les to be retrieved for any point in the history of the project. By retrieving each version of a le, a time-stamped series of intermediate les can be collected. This retroactive recovery of each version means the data collected is equivalent to what would have been collected live during the project implementation phase. For each version of a source le, the following pieces of raw data were collected: date and time, lename, version number, submission engineer, and the various eort metrics discussed in the next chapter. Additional derived pieces of data were computed including elapsed time in project, elapsed time since the le last changed, and other les submitted at the same time. Files were determined to be submitted at the same time if the same
author submitted both les and the recorded submission times diered by at most three minutes.
Several of the project data sets contained anomalies which were judiciously removed. Six of the data sets included unusual entries long after the completion date for the project. In some cases, this was evidently a mistaken submission of a le to the wrong repository. In other cases, this was evidence that a later, minor maintenance release of the project was produced. A gap of at least one month in the data was used to identify the end of the project. A future work may compare these projects against those without revisions to determine if the projects were shipped too soon. In addition to outliers near the end of the data set, three projects contained unusual events related to repository submissions. In two cases, a zero-length le was submitted to the repository immediately before being resubmitted correctly. In one case, several hundred lines of code were removed from a le only to be immediately added to another le. These three data events were considered to be the result of misuse of the repository and the events were removed. Finally, project one was discovered to included a prototype phase. Since the engineering team changed following completion of the prototype, it was treated as two projects (1a and 1b).
3.6 Data Source
Seventeen projects from a single company were studied. All projects were de-veloped using the same process. They were six weeks to eighteen months in length and
involved one to eight engineers. All projects produced multimedia software designed to be marketed to consumers for use with Microsoftr Windowsr and on Macintoshr personal computers between 1995 and 2002. Much of the total project eort for these projects was not software development but rather multimedia content development. Source and content development outside the usual denition of software was not con-sidered; only source les created by software engineers and containing source code was included in the study.
The projects studied were not on-going eorts such as the more typical sce-nario of software maintained for in-house use. The projects were intended for mass-distribution to consumers, maintenance changes were not anticipated or economically acceptable. Clear delivery dates exist after which no work was to be done. This is unlike some other environments, where software is deployed rather than delivered, and implementation evolves into a continuous cycle of maintenance. The progress model studied is expected to be meaningful when applied to each release of on-going projects, however additional studies will be needed to establish this. Results from this homogeneous group of projects should apply to initial development eorts of all projects and to projects without maintenance phases.
CHAPTER IV EFFORT METRICS
Three established metrics were used in the study. Two variations on the lines of code metric were considered. Also included are Halstead's volume measure and McCabe's cyclomatic complexity measure. These metrics have been studied together many times. Several studies showing the correlation with eort or faults have been published using these metrics (Lind and Vairavan 1989; Kafura and Canning 1985). Each of the metrics is described below including denition, references, and details about implementation within the study. Measures other than those studied here could be used and several suggestions for future investigation are included below. These additional metrics are not be included in this initial study.
4.1 Source Lines of Code
Software size can be measured using a count of source lines of code (SLOC) contained within the project. This metric includes many variations. The Software Engineering Institute has identied dozens of issues that should be considered when dening SLOC (Park 1992). These issues help dene what exactly counts as a line of code. Typically lines containing only white space and lines consisting of comment characters without any alphabetic characters are not counted. In addition to the preceding rule, physical lines containing both code and comments count as two lines
While some researchers continue to dismiss SLOC as a poor measure (Lehman, Ramil, Wernick, and Perry 1997), studies have shown strong correlations between SLOC and other properties such as eort, project duration, and quality. Lind and Vairavan even show it can outperform more complex measures (Lind and Vairavan 1989). One of the main arguments against this metric is its susceptibility to spoof-ing. For example, simply using a dierent formatting scheme will produce dierent results. Other intentional spoong eects are even easier to imagine. In this case, since the data was collected after the fact, the project engineers had no knowledge of this study. Lacking knowledge of the study and since no measurements were taken or published within the development environment, intentional spoong eects are not possible. Mitigating unintentional counting eects relies on consistent coding prac-tices or standards. In this case, the development environment strongly encouraged conformance to a consistent set of coding standards. Since similar coding standards were in eect for all projects, unintentional eects should be mitigated. In general, strong conformance with local standards should improve the quality of this type of metric.
New studies continue to cite SLOC as an independent variable for various studies. Its continued use has been attributed to its use as the null hypothesis of measures by Powell (Powell 1998). It is also regularly used to estimate projects and measure productivity. These studies and estimates substitute a specic SLOC metric for a true measure of the desired dimension. For example, Schneidewind uses
lines of code changed as a measure of total eort in his study of process stability (Schneidewind 1999). Jorgensen uses lines of code changed to measure maintenance task size in his study of maintenance task prediction models (Jorgensen 1995).
This study will consider two variations of SLOC. The simplest form counts the SLOC change (SLOCC) for each le submitted. SLOCC is the absolute dierence in SLOC between source les consecutively submitted to the repository. That is, it counts SLOC added or deleted from the previous version. The second form measures the number of lines actually changed between submissions by comparing the les. This second measure is sometimes referred to as code churn (CHURN) (El-Eman 2000). CHURN is the count of source lines inserted, deleted, or changed between source les consecutively submitted to the repository. It is probably a better metric than SLOCC since CHURN captures changed lines (which also represent real work based on arguments presented above) that are not captured by SLOCC alone.
4.2 McCabe Complexity
The second software size metric considered uses cyclomatic, or McCabe, com-plexity measure (MCM) as its basis (McCabe 1976). For a single function, cyclomatic complexity can be computed by adding one to the count of ow-control decision points. For several functions, its value is the count of all decision points plus the count of functions under consideration. This study used this denition and grouped functions by the source le in which they appeared.
MCM was originally proposed as an complexity evaluator of functions or mod-ules. MCM was invented before object-oriented development was available, so it only considers algorithmic size, not structural or object size. It has been studied almost as extensively as SLOC and many studies have shown that MCM and SLOC are highly correlated (Lake and Cook 1994; Lind and Vairavan 1989). Based on this reasoning, Andersson et al argue cyclomatic complexity is actually a measure of eort (Ander-sson, Enholm, and Törn ). They dene eort as program length times real average complexity (effort =length ×complexity). They demonstrate cyclomatic complexity
captures the product of the length dimension and the hidden dimension of real com-plexity. This nding indicates a measure based on MCM could provide an acceptable surrogate for captured eort.
This study considers changes in MCM to represent a measure of eort re-quired to achieve the change. This McCabe complexity change (MCC) is dened as the absolute dierence between MCM values of source les consecutively submitted to the repository. Ideally, several variations on this metric would be considered. For example, the MCM of the actual lines added, deleted, or changed. This measure is conceptually similar to the dierence between SLOCC and CHURN. Another inter-esting metric to consider is the sum of the complexity of all functions changed. This suggestion assumes that any change to a function requires at least some understanding of the entire function.
4.3 Halstead Volume
The third software size metric considered uses Halstead's Software Science measure of program implementation length (Halstead 1977). Halstead implemen-tation length (HIL) is dened as the total of operator count and operand count. Halstead denes operands as variables and constants; he denes operators as com-binations of symbols that aect the value or ordering of an operand. From these denitions and his example it is obvious that HIL varies only slightly from a count of tokens. Halstead does not provide a precise denition of operator or operands for the C++ programming language. Instead of attempting to arbitrarily map C++ constructs to Halstead operands and operators, a token count was used.
Halstead denes many metrics derived from the count of operators and oper-ands. From these he derived many more exotic Software Science metrics. Debate continues as to the theoretical and empirical validity of most of these measures (Fen-ton and Neil 1999). While many of these metrics have generally been disregarded, his denition of implementation size remains in use for much the same reason SLOC is usedit has an obvious meaning in most contexts and is easy to implement, esti-mate and understand. Albrecht studied the use of Halstead's implementation length estimate and function points as a tool for estimating projects (Albrecht and John E. Ganey 1983). He shows that for large projects estimated functions points can be used to predict HIL, which can be used to predict SLOC and implementation time.
One Software Science metric with potential appeal for this study is program-ming eort. Halstead describes programprogram-ming eort as the mental activity required to reduce a preconceived algorithm to an actual implementation in a language in which the implementor (writer) is uent (Halstead 1977, page 46). Unfortunately this denition is more restrictive than what we desire in that it does not include time to conceive the algorithm but rather seems to predict the time required to simply enter the code.
This study considers changes in HIL to represent a measure of the eort re-quired to achieve the change. Halstead length change (HLC) is dened as the absolute dierence between HIL values of consecutive source les submitted to the repository. Like the McCabe measures, ideally several other measures would be studied as well. For example, the sum of HIL for the lines actually changed seems appropriate. As above, this is based on the reasoning that changes in a line of code require an un-derstanding of at least that whole line. A similar argument can be made for the containing function, and to a lesser extent the containing class or module. Halstead also denes program volume in terms of the number of bits required to store it. Dif-ferences between total volume, rather than size, could be considered. Attempting to measure the volume of the current change could also be studied.
4.4 Other Metrics
The metrics selected for this study were chosen by a combination of factors including demonstrated utility and practicality. Other metrics could have been chosen and clearly they will need to be studied. For example, Lehman et al use module count as a surrogate for size in their study of software evolution (Lehman, Ramil, Wernick, and Perry 1997). Several other interesting metrics suspected of providing high-quality measures are described below.
One area of software size without an established and simple measure is that of object-oriented code. Lake and Cook show that MCM and SLOC alone miss at least one major dimension of object-oriented software (OOS) (Lake and Cook 1994). Using component analysis they show OOS has a dimension related to the number of classes, number of polymorphic functions, and number of inheritance lines. Their analysis did not address complete systems, only class trees and individual classes. Dening and evaluating a metric based on object-oriented attributes such as those listed above seems promising. A simple, practical measure for the extra dimension(s) found in OOS would be very useful.
Henry and Kafura created and studied a metric based on information ow (Henry and Kafura 1981). This measure might provide a better measure of overall size or complexity for OOS than the existing ones. However, it does not specically attempt to capture size or eort. It is also extremely complex to implement, so for these reasons it was not included in this study.
One other metric which could be considered is inspired by Strelzo (Strelzo and Petzold 2003). He uses dierences in Human compression (Human 1952) as a surrogate for the information distance between two versions of program source code. A similar algorithm could be used to generate a potentially better size-change metric. This is especially true if the dierences, rather than the complete source, were compressed using only the dictionary of the original source. This process would give the information distance for the change.
CHAPTER V RESULTS
Parameterized models provide an approximation of the sampled data for a particular data set. From a quantitative perspective, the model curve which most closely ts the data is considered the best, since it introduces the least error. Model t can be measured using the squared residual after subtracting the model curve from the sample data. To allow comparisons between data sets the average squared residual error (R2) is usually used. Large values of R2 indicate the model does not t the data. When comparing models, the model with the lowest R2 for a particular data set provides the closest approximation. In order to establish that a model is generally better, similar results should be obtained from multiple data sets covering the domain of interest.
5.1 Alternative Models
In addition to the proposed implementation progress model, three alternative models were chosen to provide a context for evaluating the t of the proposed model. The usual quantitative analysis for a new model is to show that it performs better than existing models. In this case, no established implementation progress model exists. Therefore, to provide a frame of reference, three alternative models were selected for comparative analysis.
The rst model was a standard linear approximation. The linear model curve is given by Equation 5.1. Linear approximation, with only two degrees-of-freedom, represents a practical lower-bound on the number of model parameters. Alternatively, it can be viewed as the model with the highest expected R2. It was chosen as a practical upper-bound on R2.
lineart=at+b (5.1)
Of the three alternative models, linear approximation is the only model with obvious interpretations for its parameters. The slope (a) represents the average
ve-locity. The y-intercept (b) can be interpreted as a correction factor necessary to
reduce error.
The second alternative model chosen was a multiphase, piecewise parabolic approximation. It contains eleven degrees-of-freedom; its model curve is shown in Equation 5.2. This model was chosen to represent a practical lower-bound onR2. No suggestion is made as to the interpretation of the individual model parameters.
multiphaset= at2+bt+c, 0≤t < tp dt2+et+f, t p ≤t < tq gt2+ht+i, t q ≤t < te (5.2)
This model was chosen to provide a reasonable lower-bound for R2 given an extremely data conforming model. The multiphase model equation contains the
pro-posed model equation as a special case. Since the propro-posed model consists of three pieces, the multiphase model is piecewise with three segments as well. Where the proposed model consists of two parabolic segments and one linear segment; the mul-tiphase model allows three parabolic segments. The proposed model is smooth, its rst derivative is continuous; the multiphase model equation makes no such guaran-tees.
The third model was a third-degree polynomial approximation, with four degrees-of-freedom. The polynomial model curve is shown in Equation 5.3. A third-degree polynomial approximation provides enough exibility to model the s-curve observed. It also provides a model of approximately the same degrees-of-freedom as the proposed model. Again, no interpretation of the individual model parameters is suggested.
polynomialt =at3+bt2+ct+d (5.3)
5.2 Model Fitting Results
Evaluations of each metric for each project were performed. The three alter-native models described above and the proposed model were used. Model parameters were found for each to minimize R2. Representative projects are discussed below.
Figure 5.1 shows progress measured via accumulated HLC and model curves for project nine. As expected, the linear model provides a poor t for the data and the
0 50000 100000 150000 200000 250000 300000 350000 0 50 100 150 200 250 days measured progress linear (381,596,000) polynomial (35,019,000) proposed (66,508,000) multiphase (6,711,000)
Figure 5.1: Progress measured via accumulated Halstead length change (HLC) for project nine and progress model curves (with R2).
multiphase model ts the data very accurately. Both the polynomial and proposed models provide ts between the linear and multiphase models. The polynomial model exhibits wild swings near the ends. These swings are typical of polynomial curves which tend to favor data points near the center rather than the ends. In this case, the polynomial model suggests a negative amount of accumulated work had been accomplished until about day forty of the project. Similarly, it indicates reverse-progress begins to occur around day 220. In almost all cases, these polynomial model swings suggest negative progress occurs at the beginning and end of the project.
Because of this, using the polynomial model to make predictions would be dicult and error-prone.
The average squared residual error (R2) for each model is given in the legend of Figure 5.1. The values agree with a visual assessment of the t except in the case of the polynomial model. While the lower R2 for the polynomial model is more desirable, the polynomial t suers extensively from undesirable swings near the ends. These swings violate a basic expectation of accumulated progress, that is it should be monotonically increasing. While the proposed model has a larger R2, it is monotonically increasing and behaves as expected. This behavior appears to support in-project predictions better than the polynomial model.
In this project, most of the proposed modelR2 can be seen to occur in the rst third of the project. Each of the other three metrics show similar results; this may indicate early eorts are not as eciently captured by the metrics as later eorts. It may also indicate the project pace was unpredictably high (in violation of the implied model) during the later part of the project. Without additional information about the project, or its context, a determination cannot be made.
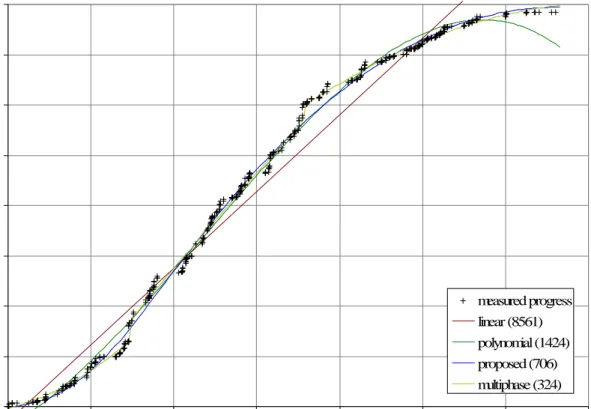
Figure 5.2 shows progress measured via accumulated MCC and model curves for project ten. In addition to the general observations noted above, two observa-tions can be made from this graph. First, discontinuities in the multiphase model are visibly apparent, occurring at about day thirty and 72. Discontinuities severely reduce the predictive value of a model because no inuence occurs across a
disconti-0 200 400 600 800 1000 1200 1400 1600 0 20 40 60 80 100 120 140 days measured progress linear (8561) polynomial (1424) proposed (706) multiphase (324)
Figure 5.2: Progress measured via accumulated cyclomatic complexity change (MCC) for project ten and progress model curves (with R2).
nuity. In addition, the discontinuity locations cannot be predicted without all data. Second, unlike project nine, R2 for the proposed model is less than half the R2 for the polynomial model.
Implementation progress for this project follows closely the proposed model curve. This suggests the process used was healthy and the project was consistently on track. Figure 5.3 shows weekly accumulated progress measured via MCC and the velocity model curve for the project. Directly measuring velocity is not possible because measurements taken represent progress. Due to the sporadic nature of source
0 50 100 150 200 250 0 2 4 6 8 10 12 14 16 18 weeks v el o ci ty measured data velocity model
Figure 5.3: Weekly progress measured via accumulated cyclomatic complexity change (MCC) for project ten and velocity model curve.
submissions determining average velocity is dicult. Accumulated weekly progress is used as a surrogate for velocity. Again, the model curve suggests the project was well managed. The model indicates implementation velocity reached a sustainable level within the rst month of development. This continued for about three weeks, then the velocity began to decrease. The relatively long deceleration period may be worth investigating, it may indicate the project experienced trouble nishing. However, considering the short development period, it may indicate the startup was unusually
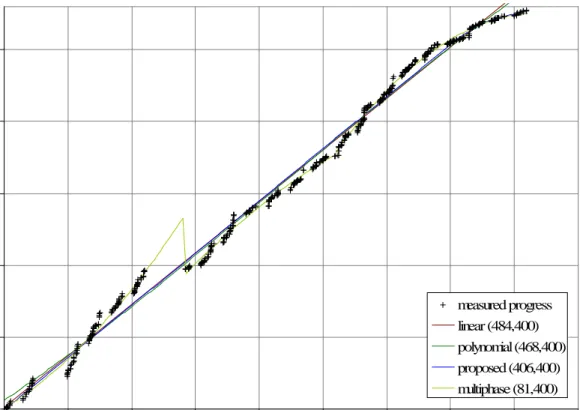
0 5000 10000 15000 20000 25000 0 20 40 60 80 100 120 140 160 180 days measured progress linear (484,400) polynomial (468,400) proposed (406,400) multiphase (81,400)
Figure 5.4: Progress measured via accumulated code churn (CHURN) for project fteen and progress model curves (withR2).
5.3 Anomalous Data Sets
Results from some data sets were ambiguous. For example, Figure 5.4 shows progress measured via accumulated CHURN and model curves for project fteen. Neither the polynomial nor the proposed model provides a signicant improvement over the linear model. Numerically, the multiphase model is signicantly better than the others, however it suers extensively from a discontinuity around day fty.
It is worth noting the large gaps in collected data around days fteen and fty, and the periodic gaps of one to two days near the beginning of the project.