CellStore: Educational and Experimental XML-Native
DBMS
Jaroslav Pokorný1 and Karel Richta2 and Michal Valenta3 1
Charles University of Prague, Czech Republic, [email protected] 2
Czech Technical University of Prague, Czech Republic, [email protected] 3
Czech Technical University of Prague, Czech Republic, [email protected]
Abstract. The paper presents the CellStore project whose aim is to develop XML-native database engine for both educational and research purposes. In the paper we discuss the basic concepts of the system and its top-level architecture. Then we discuss individual parts of the systems. The discussion is focused mainly on already finished and tested subsystems - low-level storage (we designed and implement own binary storage model) naive XQuery imple-mentation, and transaction manager. We plan to extend the system in a way to be used as an experimental back-end for web-based application of Semantic web and specialized XML storages. The whole project is managed with focus on clear object-oriented design and test-driven development.
1. Introduction
The main goal of the CellStore project (CellStore 2007) is to develop XML-native database engine for both educational and research purposes. We need such an engine because our students can look inside the engine and create new components for this engine, e.g. in-built XSLT engine, a query optimizer, an index engine, etc. We can experiment with the engine and try to develop active extensions, combined stream processors, and many other new ideas, as they are formulated, e.g., in work of (Lou-pal 2006). Thus, XML native database can look like an experimental and develop-mental platform.
implementation can contribute to general trends in XML-native databases develop-ment.
This paper presents some interesting points of the CellStore design and imple-mentation. In Section 2 we state some issues related to XML database management systems. In Section 3 we discuss the basic concepts of the system CellStore and its top-level architecture. Then we talk about individual parts of the system. Section 4 contains some conclusions and suggestions for a future work.
2. What is an XML Database Management System?
Suppose we have a large and continually growing set of XML documents. Then the reasons for storing them in a database system are the same as e.g. for relational data:
persistent storage, transactional consistency, recoverability, high availability, secu-rity, efficient search and update operations, and scalability.
2.1 XML DBMS definition
Any database management system (DBMS) is a set of programs which maintain the data and the data integrity and provide an interface for data definition and manipula-tion. By consensus in XML and database community, there is no official strict defini-tion of XML DBMS, but any XML DBMS must fulfil the following:
1. It defines a (logical) model for an XML document. This model is used when XML documents are stored and retrieved from the database. As a minimum, the model must include elements, attributes, PCDATA, and document order. 2. The fundamental unit of (logical) storage is an XML document.
3. It does not require having any particular underlying physical storage model. For example, it can be built on a relational, hierarchical, or object-oriented DBMS, or use a proprietary storage format such as indexed, compressed files.
2.2 XML DBMS classification
We call DBMS XML-enabled, when its core storage and processing model is not the XML data model (examples are, e.g., DB2, Oracle). On the other hand, we call DBMS XML-native, when it complies with the following conditions:
• The XML data model is the fundamental logical data model used both internally by the database and also exposed to database users when XML is the data type. • The XML data model is the fundamental unit of physical storage of all XML
data, without mapping to a different data model.
But let us mention also, that (Bourret 2005) said: “... native XML database first
gained prominence in the marketing campaign for Tamino .... it has never had a formal technical definition.”
2.3 Issues of building XML DBMS
To build a new XML DBMS, we have to make the following crucial decisions: • to choose an appropriate XML data model,
• to choose an appropriate storage model,
• to select some query and manipulating language, • to select methods for optimization and indexing, • to solve support for transactions and multi-user access, • to decide a support for applications development - API.
Based on the requirement (1) in Section 2.1 there is typically a common intuitive tree-like model supposed in the most of XML DBMSs. XML data model specifica-tions include XPath 1.0 data model (the older one treats XML data as a set), XPath 2.0 and XQuery 1.0 data model by W3C (2007) (latterly, it treats XML data as a sequence), and, e.g., a type system based model (XML-lambda introduced by (Pokorný 2000) treats XML data as type instances).
A common view on mentioned issues concerns the DBMS architecture. Today’s DBMS provide practically universal architecture applicable to many various types of tasks, i.e. by words of (Stonebraker et al 2005), “one size fits all”. In new DBMS architectures rather separated database servers “made to measure” are expected, in accordance with requirements of particular applications. Besides traditional fields, as OLAP, data warehouses, and text retrieval, other candidates for separate engines are data streams processing, sensor networks, scientific databases, and, particularly, native XML databases.
Considering native XML databases, a solution with a separate engine is also our choice.
2.4 Storage models
Storage models for XML data use a file system, a mapping XML data to relational or object-relational models, mappings XML data to object-oriented models, or a native XML storage. An attractive option is to store XML data in combination of two sys-tems: structured portion of XML data in relational database, and unstructured por-tion in native XML store.
File system approach is straightforward and popular, see, e.g., Xindice project by Apache (Apache 2007). It works effectively if we work with the whole documents. Problems are with effective querying. A lot of research had been done in mapping XML data to relational or object-relational model - for an overview; see (Mlýnková and Pokorný 2005). This approach uses relatively sophisticated and effective tech-niques, typically appropriate for simple structures, but it is problematic with complex or cyclic DTDs – it leads to deep nested SQL queries. Mapping to object-oriented models is typically based on DOM approach, where nodes (of XML document) are represented as unique objects. Relationships between nodes are represented by ob-ject's serialization. But this object-oriented approach seems to be unnecessary gen-eral; it does not take advantage of simplifications in XML model with respect to object-oriented native storage. An overview of an efficient way to store XML data inside an object-oriented DBMS gives, e.g. (Renner 2001).
According to (Wikipedia 2007), native storage for XML data maximally utilizes natural tree-structure of XML documents and, on the other hand, it tries to adapt other well-done features of DBMS systems (user-rights model, transactions, etc.).
3. The CellStore Project
When we have formulated aims for CellStore (see Introduction), we have to decide requirements for development environment. It should be easy to change of subsys-tems functionality; it will be purely object-oriented for development and design. It must enable component reusing and simple for use. We focus mainly on functional-ity not on GUI design. We require simple test-supported development, trace & log facilities for debugging and educational purposes, and rather “interpret” than “com-pilation”, due to immediate change propagation. At the end we select Smalltalk/X as the first development environment.
A part of our project is inspired by XTC1 (XML Transaction Coordinator) devel-oped at University of Kaiserslautern. Similarly to XTC we implemented XML en-gine in frame of five-layer data architecture as it was designed in (Härder and Router 1983) in the 80s. The main difference is in the low/level storage - the XTC project uses B-trees as data storage.
3.1 The Top-level Architecture of CellStore
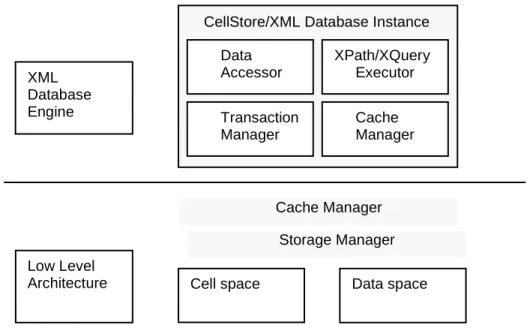
The architecture of CellStore database management system is shown in Fig. 1. The system has two basic levels – CellStore database instance and low-level engine. The low-level engine serves as the data and text storage, the instance accesses data through this low-level engine. Fig. 2 illustrates briefly, how the main components cooperate.
3.2 Storage Subsystem (Low-level Storage)
We developed a new method for storing XML data. The method is based on work of (Toman 2004) and partially inspired by solutions used in DBMSs of Oracle and Gemstone. Structural and data parts of XML document are stored separately. Of course, it increases necessary time to store and reconstruct documents. But on the
other hand, it provides a great benefit in disk space management especially in the case of documents update and also in query processing and indexing stored XML data.
Fig. 1: The Architecture of CellStore
Let us describe the storage model more in detail. The description is based on the first implementation version, because it is more illustrative. There exist improvements in the newer versions of CellStore, but they are not so important for this quick view.
XML data documents are parsed and placed in two different files during the stor-ing process – the cell file and the data file. The structure of each of them is described in an individual subsection. We will illustrate the structure of files by example of the following document:
<?xml version="1.0"?> <!DOCTYPE simple PUBLIC
"-//CVUT//Simple Example DTD 1.0//EN" SYSTEM simple.dtd"> <simple>
<!-- First comment --> <?forsomeone process me?> <element xmlns="namespace1"> First text <ns2:element xmlns:ns2="namespace2" attribute1="value1" ns2:attribute2="value2"> </ns2:element> <empty/> </element> </simple>
CellStore/XML Database Instance
Data Accessor XPath/XQuery Executor Transaction Manager Cache Manager XML Database Engine Cache Manager Storage Manager
Cell space Data space Low Level
Fig. 2: Main class model of CellStore
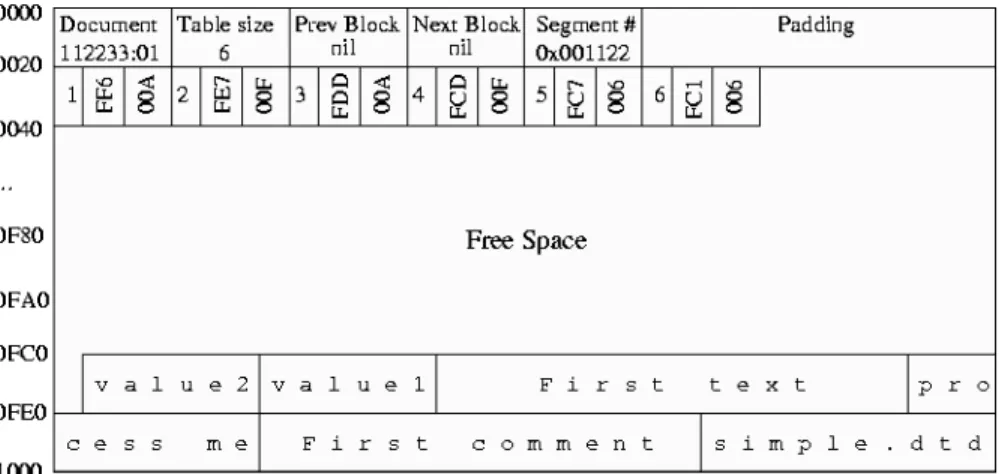
Cell-File Structure. This file consists of fixed-length cells. Each cell represents one
DOM object (document, element, attribute, character data, etc.) or XML:DB API object (collection or resource). Remind that this API is developed byXML:DB Ini-tiative for XML Databases (XML:DB 2003). Cells are organized into fixed-length
block.
Database block is the smallest I/O unit of transfer between disk and low-level storage cache. Only the cells from one document can be stored in one block. The set of blocks describing the structure of the whole document is called segment. Each block starts with header with a bitmap describing the density of the block. This stor-ing strategy is effective also in the case of repeated changes of deletstor-ing stored docu-ments.
Inside the cell structure internal pointers are used to represent parent-child and sibling relationships of nodes. Each cell consists of eight fields. The meaning of some fields can differ with different types of cells. The following cell types are in the system: character data, attribute, document, document type, processing instruction, comment, XML Resource, and collection.
Name Content Reason
Head 1 byte The type of cell.
Parent cell pointer Pointer to parent cell. Child cell pointer Pointer to the first child.
Sibling cell pointer Pointer to the next cell brother (NIL if there is no one).
D1, D2, D3, D4
depends on type Contain either data or pointers (possibly to text file or tag file) depending to the type of cell.
Tab 1: The general structure of cells
The example content of cell-file structure is shown in Fig 3.
Fig. 3: Cell-file structure
Text File Structure. This file contains all text data (i.e. contents of DOM's text
ele-ments and attributes). The data is organized into blocks too. One block belongs just to one document. The set of data blocks belonging to one document is called again a
segment. Text pointer is a pointer to text file. It consists from the text block# and the record#.
Each text block contains a translation table which accepts the record number and returns the offset and the length of the data block. This is effective for storing data changes. The translation table grows from the end of block, while data grows from the beginning.
The translation table contains the number of actual records for these purposes. The header of a text block contains also the pointer to the root of its cell node. It is useful for fulltext searching - for the case we need documents containing some pat-terns. The example content of text file structure is shown in Fig. 4.
Fig. 4: Text-file structure
Tag File Structure. This structure is used for storing the names of XML tags
(ele-ments, attributes, namespaces, etc). It is supposed that this structure will fit all into memory. This structure is used often for reconstruction of document as well as stor-ing the document. Each record of this structure has also its reference counter.
Low-level subsystem was fully implemented. Its stability had been tested on INEX data set. INEX is the set of articles from IEEE; see (Gövert and Kazai 2002) for an overview. It contains approximately 12 000 individual XML documents (without figures), total size of the set is about 500MB.
Current version of low-level subsystem allows individual setting of cell, cell-pointer, and block sizes. We did not do experiments with different values of these parameters yet.
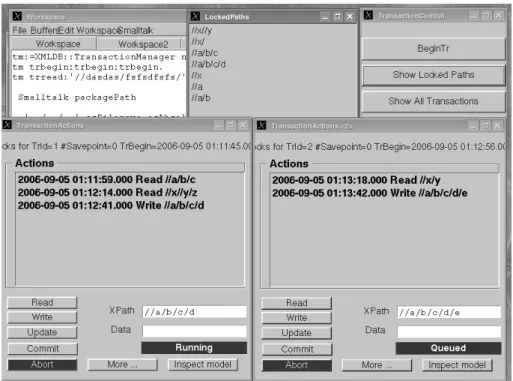
3.3 Transaction Manager
Actual prototype implementation of Transaction Manager is based on taDOM model developed by (Haustein et al 2003). The implementation provides a transaction man-ager GUI inspector, which presents actual transaction states and mutual dependen-cies. Fig. 5 shows a simple simulation. There are two transactions in the system. The first one reads sequentially paths (nodes) //a/b/c, //x/y/z and then modifies the path //a/b/c/d. The second transaction tries to read the path //x/y, which is locked for reading by the first transaction. Because the lock is for reading, the second transaction is successful, it obtains the data. Then the second transaction tries to write the path //a/b/c/d/e. At this moment the transaction is queued, because the parent node of the path node e is exclusively locked by the first transaction. We can also see all locked paths in the upper-middle window (the lock type is not depicted here).
3.4 XQuery Executor
Our actual (naive) XQuery implementation2 is according to XQuery 1.0 specification by W3C, although it is not complete yet. Its design is strictly modular and ready for further development. The details are out of the scope of this article, but they were published in (Vraný and Žák 2007).
Fig. 6 shows XQuery console - a simple front-end for XQuery executor. The query presented here uses two different data sources - CellStore storage and external data file. The query should return names of authors stored in the database and cited in the external article.
Fig. 6: XQuery console
4. Conclusions
The paper describes basic concepts of the CellStore project, which we consider as a good starting point to many future work and experiments.
Here are several topics which are actually in the stage of design or implementation: • XQuery Update Facilities by W3C specification,
• database Cache Manager,
• another locking protocols implementation, • index engine implementation,
• GUI database management console with at least following tools:
o XML initialization and data management (import, export, internal structure browser, etc.),
o improved XQuery console (including inner XQuery representation browser),
o improved Transaction Manager, and
o Cache Manager browser, and
o light web-based database management console.
5. Acknowledgments
This research has been partially supported by the National Program of Research, Information Society Project No. 1ET100300419, and also by Ministry of Education of Czech Republic under research program MSM 6840770014, and also by the grant of GACR No. GA201/06/0648 “Intelligent Web Technologies”, and also by the grant of GACR No. GA201/06/0756 “Development of a Native Storage for XML Data”.
References
Apache (2007) Xindice. http://xml.apache.org/xindice/ Bourret, R. (2005) XML and Databases. Avalable at
http://www.rpbourret.com/xml/XMLAndDatabases.htm Bourret, R. (2007) XML Database Products. Avalable at
http://www.rpbourret.com/xml/XMLDatabaseProds.htm CellStore Homepage (2007) http://cellstore.felk.cvut.cz/wiki
Gövert, N. and Kazai, G. (2002) Overview of the INitiative for the Evaluation of XML re-trieval (INEX) 2002. In: Proc. of the first Workshop of the INitiative for the Evaluation of XML Retrieval (INEX), Dagstuhl, pp.1-17.
Haustein, M. and Härder, T. (2003) taDOM: A Tailored Synchronization Concept with Tun-able Lock Granularity for the DOM API. In: Proc. ADBIS'03, (Eds. L. Kalinichenko, R. Manthey, B. Thalheim, U. Wloka), Springer-Verlag LNCS 2798, pp.88-102.
Härder, T. and Reuter, A. (1983) Concepts for Implementing and Centralized Database Man-agement System. In: Proc. Int. Computing Symposium on Application Systems Develop-ment, March 1983, Nürnberg, B.G. Teubner-Verlag, pp.28-104.
Lapis, G. (2005) XML and Relational Storage. Are they mutually exclusive? Avalable at http://idealliance.org/proceedings/xtech05/papers/02-05-01/
Loupal, P. (2006) Querying XML by Lambda Calculi. In: Proceedings of the VLDB 2006 Ph.D. Workshop, Soul, Korea, CEUR Workshop Proceedings, Vol. 170.
Mlýnková, I. and Pokorný, J. (2005) XML in the World of (Object-)Relational Database Systems. In: Proc. of the 13th International Conference on Information Systems Develop-ment 2004, Vilnius, Lithuania, Springer Science+Business Media, Inc., pp.63–76. Pokorný, J. (2000) XML functionally. In: Proc. of IDEAS 2000 (Desai, B.C, Kioki, Y. and
Toyama, M., editors), IEEE Comp. Society, pp.266–274.
Renner, A. (2001) XML Data and Object Databases: The Perfect Couple? In: Proceedings of the 17th International Conference on Data Engineering (ICDE .01)
Stonebraker, M. and Çetintemel, U. (2005) “One Size Fits All” An Idea Whose Time Has Come and Gone. In: Proc. Conference ICDE, Tokyo, Japan, pp.2-11.
Toman, K. (2004) Storing XML Data in a Native Repository. In: Proc. of DATESO 2004, CEUR Workshop Proceedings, Vol. 98, pp.51-62.
Vraný, J. and Žák, J. (2007) A modular XQuery implementation. In: Proc. of DATESO 2007, CEUR Workshop Proceedings, CEUR Workshop Proceedings, Vol. 235, pp.47-54. Wikipedia about XML. Avalable at http://en.wikipedia.org/wiki/XML
W3C XML sources. Avalable at http://www.w3.org
XML:DB (2003) Application Programming Interface for XML Databases. http://xmldb-org.sourceforge.net/xapi/