SPAM COMMENT DETECTION IN
BLOG COMMENTS FROM BLOG RSS
FEED BY MODIFIED TF-IDF
ALGORITHM
FOUZIA SULTANA
Prof. Dept. of CSE, Stanley Charles Engg. College, Kurnool, Andhra Pradesh - 518001, India
DR. STEPHEN CHARLES
Principal, Stanley Charles Engg. College, Kurnool, Andhra Pradesh - 518001, India
DR. A. GOVARDHAN
Prof. in CSE and Director Evaluation JNTU Kukatpally, Hyderabad, Andhra Pradesh , India
[email protected] http://jntuh.ac.in
Abstract :
Publishing the opinions online through blog is growing day by day. Visibility of the blogs in search engines depends upon the page rank or PR of the blogs and PR depends upon number of links pointing to the blogs. Popular blog engines like word press; drupal allows comments system by means of which readers can leave comments after reading the blogs. Over the time automated engines are developed that can find the blogs that support comment system and publish automatic comments with links to particular websites. This is called blog spams. There are several techniques proposed to prevent blog spams but have failed to effectively detect the spams. In this work we propose a unique technique to detect blog spam based on modified TF-IDF algorithm to first find the relevancy of the comments with respect to the subject and further checking for repetition of the words in the comments. Generally automated blog commenting or spamming publish the same comments across multiple sites and blogs, therefore this method can effectively detect the spams. The proposed technique is verified with respect to several blogs with the consent of blog webmaster. Results show the effectiveness of the technique against some of the theoretical model as well as some of the commercially available model like aksimet.
Keywords: — Spam Comment Mining; Blog Sentiment Detection; TFID.
1. Introduction
Blog or web logs are essentially websites owned by webmasters who publish articles or Blogs on different topics. Most of the blogs comes with the provision for the readers to leave their comments on the blogs post improves the search engine ranking of those web sites. This is a major problem in maintaining the blogs as this Not only makes it difficult to moderate the comments but at the same time drops the ranking of the actual blogs. First Author Fouzia Sultana the corresponding author, is working as a Professor in Stanley Charles Engineering College Kurnool, Affiliated to JNTU Ananthapur, Andhara Pradesh, India.Permanent Address:H-No 4-601/90 B//2 , Banda Nawaz Colony ,Ring Road Gulbarga-585105.Karnataka State,India.
Some online software like StopForumSpam and Aksimet provides API driven support for spam prevention. The core method for detecting spams in these APIs is IP address based. The sites maintain a huge database of reported IP addresses and checks the IP address of the comments with that of the database.
But the spammers generally use proxy addresses and changes the IP address frequently, which makes it really difficult for the blog spam detection techniques to track the spam comments.
On the other hand manually searching each comments for the repetition through Google search is time consuming and inefficient. Hence a mechanism is needed to find the relevancy of the comments with the posted blog or article. Any comment that is general in nature and are already published somewhere is the Spammed one.
Finding the relevancy of the comments with the posts is also not easy. This is due to the fact that many blog spamming software automatically integrates the title of the post in the comment which makes it look like a unique comment.
Modified TF-IDF technique has been considered to be very effective in terms of detecting blog opinion, relevancy of comments, blog categorization and document similarity. Therefore in this work we use the same technique for detecting the spams in the blogs.
1. Related Work
As the spam detection problem in blogs can be considered to be similar to detecting an opinion in the blogs barring the fact that the spam detection must also incorporate the uniqueness of the opinion and that it must not have been generated from a banned IP address. Therefore in the related work section, we will analyze some of the literature that focus on extracting features from the documents and blogs which can be utilized to detect the similarity measure of the comments with blogs and other published comments in other blogs.
The approach described in this paper exploits Senti-WordNet [2] as lexical resource for Spam mining. The authors introduce a lexicon based method of analyzing the Spam even without any training data in this direction. Khurshid et al [3] have developed a method for identifying the words that may surprise a native speaker by comparing the distribution of all the words in a collection of randomly sampled financial texts with that of the same words in a reference collection of texts. More prolific keywords in financial texts, the chances are that such a word will be less prolific in general language texts. Once it identifies keywords, based on statistical criteria in our training collection of texts, then the system looks at the neighborhood of these keywords; and, then looks at the neighbourhood of the two word pairs and so on.This neighbourhood, established on strict statistical criteria, yields information bearing sentences in the financial domain and, it turns out sentences that typically carry sentimental information. These patterns are then used to build a finite state automaton. This automaton is then tested on an unseen set of texts – and the results vis-à-vis sentiment analysis is quite good. The authours in [4] have analyzed the various techniques for sentiment analysis in online data. Further they present a simplistic algorithm for the same which contains following.
Evaluation (positive/negative), Potency (powerful/unpowerful), Proximity (near/far), Specificity (clear/vague), Certainty (confident/doubtful) and Intensifiers (more/less)
Paula Chesley et al. in [5] presents a supervised learning based technique for blog classification without the data in the same domain. In this work authors make use of several features of three principal types for our classification task: textual features (exclamation points and question marks), parts-of-speech features, and lexical semantic features. None of the features of the parts of speech showed an impact on the classifications; hence for the reasons of space we do not discuss them further. Each post is then represented as a feature vector in an SVM classification.
An overall system of learning based classification has been explained in [6] which is the accuracy measure of such a system explained by figure 1.
The work of [6] is motivated by the fuzzy based sentimental classification as proposed by [7], which uses a manually constructed rule set for the same.
The paper [9] explains the feature extraction process for the Spam Comment mining. It explains that for any Spam mining first there must be an association with the genere or the heading or the subject of the base. This forms the preprocessing step in the proposed system.
Amitava Das and Sivaji Bandyopadhyay in their paper “Theme Detection an Exploration of Spam Subjectivity” [10] have proposed a mechanism of subjective analysis of any document or post. They present a part of speech based algorithm for identification of the subject with respect to the document.
Product Reputation Miner [12] extracts positive or negative Spams, based on a dictionary. Then it extracts characteristic words, co-occurrence words, and typical sentences for individual target categories. For each characteristic word or phrase they compute frequently co-occurring terms. However, their co-location based association of characteristic terms and co-occurring terms is known to be highly noisy [11].
[13] Explains the challenges in Blog mining and sentence extraction in blogs. They emphasized that Spam Comment mining in blogs are difficult due to several aspects like mis-spelled words, synonyms, emotions, and short terms and so on. These are the challenges that the proposed work is designed to overcome.
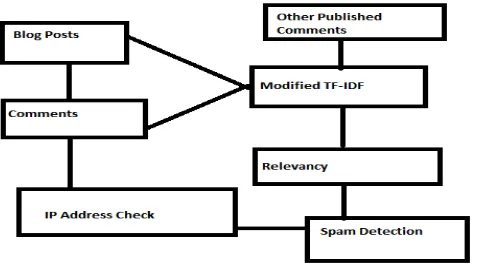
2. Proposed Work.
Fig. 1. Block Diagram of Proposed Work.
First, segment the blogs into sentences and sentences into words. The words are tagged based on wordNet tool for sentence segmentation and tagging.
(1) Once the words are tagged, find the similarity of the comments with respect to a specific subject matter based on the tags of the blogs.
(2) Similar items to the headings are ranked lower and are sorted at the bottom in comparison with the other comments. This is due to the fact that automated systems incorporates heading in the comment field and a human poster rarely mentions the heading in the comment.
(3)The high ranked blogs are scanned and forwarded for the deterministic words like “Great Post”, “Thanks for the post” and so on. The closeness measure with such words is performed on the high ranked comments and they are further categorized into Comments with Spam and blogs without Spam.
(4)Sorted comments are now checked for similarity with other comments posted elsewhere through Google search API. If they are found to be closed to huge number of other comments, they are marked as spam.
(5)Finally passed comments are checked for IP addresses. If IP address is matched with the database of black listed IP addresses, then comment is marked as spam.
For measuring the similarity we adopt the following approach.
Extract all the sentences minus the stop words from the documents. S={s1,s2,…sn}. Extract the Frequency Sentence matrix by calculating if a sentence has a particular term. S’={S11,S12,S13…Snm}, where Snm is the nth sentences frequency for mth word or term. Now create a Graph (V, E) with each sentence S’ at the vertex and if two sentences are similar, they are connected with an edge with Weight of the Edge.
The Weight is nothing but the cosine similarity between two sentences. Thus the sentence actually “recommends” sentences which like itself under this weight calculating mechanism. A long sentence that is similar with most of the sentences will obtain high rank a high Rank will suggest a high Spam value. Once a Graph is built, weight of each vertices are calculated as shown in Equations below.
3. Methodology
Term frequency Inverse document frequency [17] works by determining the relative frequency of words in a specific Document compared to the inverse proportion of that word over the entire document corpus. Intuitively, this Calculation determines how relevant a given word is in a particular document. In our modified algorithm we calculate TF-IDF as the summation of TF-IDF of the words as a summation of bigram, trigram and quadgram similarity of the words with the document, leaving out most common words.
The systems developed without any Learning based classifiers are generally classified in two major categories: 1) Occurrence based Thresholding and Weighted thresholding as proposed by the system.
Results
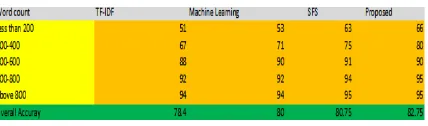
Experiments are conducted for various categories of blogs which are first categorized into blogs with different post word count. The feeds are extracted from blogs with different Google page rank. It was observed that for short blogs comments were also short which lead to many false detection. Another observed fact was that for Low PR sites comments are less moderated which resulted in many general comments and out of the context comments that did not help analyzing the Spam about the subject. Experimental results are presented in figure 4.
Fig. 2. Results depicting the comparision of results in present and proposed system
It is quite clear from the table above that proposed technique fares well in cumulative results against technique proposed by [18], StopforumSpam (AKSIMET),
Where
4. Conclusion
Spam Comment is an important aspect of web mining and the web data analysis because major issues and news are posted as blogs these days. Number of blog readers and blog commenter’s are also increasing day by day. Therefore it becomes important to develop tools which can, not only extract correlated blogs but also gets an overview of independent and in turn generalized overview of the blogs. Many algorithms are proposed in this direction. Most of these works are organized to detect the Spam in the blogs only and do not present a comprehensive overview of the entire technique of fetching the RSS blog data and analyze them on the fly. In this work we have developed an entire lifecycle of fetching and analyzing the blogs and the comments for Spam. The technique is based on similarity of the blog with its subject matter and the presence of Spam in such correlated blogs. The result shows a significant similarity with human perception. The only limitation of this method is that the XML parsing had to be separately designed for different blog machines like drupal, wordpress, BlogSpot and blogger. A comprehensive framework can be built that can extract the comments and posts irrespective of the type Blog Engine. Further a machine learning technique can be used along with the proposed technique for better results.
References
[1] Kerstin Denecke. (2008). How to Assess Customer Spams Beyond Language Barriers? IEEE.
[2] [8] Esuli A; Sebastiani F. (2006). A Publicly Available Lexical Resource for Spam Mining. SentiWordNet-LREC.
[3] Khurshid Ahmad.(2006).Multi-lingual Sentiment Analysis of Financial News Streams, Grid Technology for Financial Modeling and Simulation – Palermo, (Italy)
[4] Erik Boiy et al.(June 2007).Automatic Sentiment Analysis in On-line Text, Proceedings ELPUB Conference on Electronic Publishing – Vienna, Austria.
[5] Paula Chesley et al. Using Verbs and Adjectives to Automatically Classify Blog Sentiment.
[6] Kushal Dave; Steve Lawrence; David M. Pennock (2003) Mining the Peanut Gallery: Spam Extraction and Semantic Classification of Product Reviews,ACM 1581136803/ 03/0005
[7] P. Subasic ; A. Huettner. (Aug .2001).Affect analysis of text using fuzzy semantic typing. IEEE-FS, 9: pp. 483–496. [8] Feng Jin; Minlie Huang and Xiaoyan Zhu. (ICCI 2009).A Query-specific Spam Summarization System, Prlc.lib IEEE . [9] Jeonghee Yi;Wayne Niblack, (2005). Sentiment Mining in WebFountain, IEEE.
[10] Amitava Das; Sivaji Bandyopadhyay,(2009). Theme Detection an Exploration of Spam Subjectivity, IEEE.
[11] K. Dave; S. Lawrence, and D. M. Pennock.(2003). Mining the peanut gallery: Spam extraction and semantic classification [12] of product reviews. In Proceedings of the Int. WWW Conference.
[13] S. Morinaga et al (2002).Mining product reputations on the web. In Proceedings of [14] the ACM SIGKDD Conference.
[15] Malik Muhammad Saad Missen,; Mohand Boughanem and Guillaume Cabanac.(2009 ). Challenges for Sentence Level Spam Detection in Blogs, Eigth IEEE/ACIS International Conference on Computer and Information Science.
[16] Malik Muhammad Saad Missen; Mohand Boughanem.(2009).Sentence-Level Spam-Topic Association for Spam Detection in Blogs, International Conference on Advanced Information Networking and Applications Workshops.
[17] Farhad Oroumchian et al. N-Gram And Local Context Analysis For Persian Text Retrieval, [18] http://sentistrength.wlv.ac.uk/: Sentiment words database.