Reconstructing Ownership Architectures
To Help Understand Software Systems
Ivan T. Bowman and Richard C. Holt
University of Waterloo
Waterloo, Ontario, Canada
itbowman@acm.org, holt@plg.uwaterloo.ca
Abstract
Recent research suggests that large software sys-tems should have a documented system architec-ture. One form of documentation that may help de-scribe the structure of software systems is the orga-nization of the developers that designed and imple-mented the software system.
We suggest that anownership architecture that
documents the relationship between developers and source code is a valuable aid in understanding large software systems. If this document is not available, then we can reconstruct it based on the system im-plementation and other documentation. We exam-ine Linux as a case study to demonstrate how to reconstruct and use this type of architecture.
The reconstructed Linux ownership architecture provides information that complements other types of architectural documentation. It identifies experts for system components, shows non-functional de-pendencies, and provides estimates of the quality of components. Ownership architectures also allow us to find problems such as under-staffed subsystems and components that risk abandonment.
Submitted to IWPC’99 Version 2.19
1 INTRODUCTION
Research [8, 11, 14, 15, 16, 18] suggests that large software systems should have a documented sys-tem architecture. An aid to program understand-ing, this documentation is recognized as a mech-anism for improving software quality and reduc-ing development costs. Unfortunately, not all soft-ware systems have up-to-date and accurate archi-tectural documentation. Several researchers have shown [8, 10, 12, 19, 20] that it is possible to re-construct a software architecture based on the im-plementation of the system and the documentation that does exist. This reconstructed architecture typ-ically identifies a decomposition of the software system into a hierarchy of subsystems, and shows interactions between these subsystems. There are several forms of interaction that have been used, in-cluding control flow, data flow, and type dependen-cies. These reconstructed architectures have proven to be useful tools for understanding and evaluating large systems. However, these reconstructed archi-tectures do not consider the organization of the de-velopers that created the system. This organization is an important aspect of large software systems, and this information is useful when attempting to understand various aspects of software systems.
The relationship between the organization of a design team and the design product has long been recognized. Conway’s hypothesis [5], formulated
by Brooks [3] asConway’s law, states that the or-ganization of a software system will be congru-ent to the organization of the team that designed the system. This is perhaps an oversimplification, but the concept is recognized as a valid forward-engineering concern. For example, Coplien [6] provides several patterns for organizing developers depending on the desired structure of a system. For systems developed by a large number of ers, it is reasonable to consider how the develop-ers of the system are organized into communicating teams.
The organization of system developers can be vi-sualized using anownership architecture.1 This
ar-chitecture relates developers to the code that they develop.
In a previous paper [1] we showed that owner-ship architectures are useful when reconstructing the concrete (as-built) architecture of a software system because they can be used to predict the de-pendencies that are found between components. In the current paper, we show that ownership architec-tures are a useful formalism for describing impor-tant relations in large software systems.
It is interesting to note that Linux and Mozilla (two of the systems we studied [1]) included docu-mentation of the software developers and the code they worked on. There seems to be two reasons for these groups to maintain this documentation. First, it provides a resum´e of a developer’s accomplish-ments. Secondly, it identifies the developers that are responsible for components of the system. The Mozilla effort explicitly identifies moduleowners, and all changes to a module must be approved by the owner. The ownership concept is also well un-derstood by developers in other development cul-tures; Perryet al.[13] describe how developers at AT&T responded to requests for authorization to change code they were responsible for. The mean-ing and extent of code ownership seems to vary be-tween different development cultures, but it seems to be a concept that is generally understood and used by developers.
Although the Linux and Mozilla systems docu-ment the files that developers have worked on or are responsible for, the large number of developers and files makes it difficult to visualize the overall 1We have coined the termownership architecturebecause this structure is similar to a conceptual or concrete architecture. Other terms that could be used instead for this structure are own-ership diagramorownership view.
structure. If we cluster developers and files into related groups, we can view higher level abstrac-tions and more easily understand the overall sys-tem structure. In addition to being very low-level information, the ownership documentation of the Mozilla and Linux systems may be out of date or inaccurate. Thus, it seems that the problems of recreating an ownership architecture for an exist-ing system are similar to the problems of recreatexist-ing a concrete architecture in that existing documenta-tion may be too low-level, outdated, or inaccurate [2].
We examined the Linux system to evaluate how a detailed ownership architecture can be recon-structed from a system implementation. This re-constructed architecture provides information that is not available in other forms of architectural doc-umentation. As we will discuss in Section 2.1, ownership architectures identify experts for sys-tem components, show non-functional dependen-cies, and provide quality estimates for components. This information is useful for understanding sys-tems. In addition, as described in Section 2.2, we can use ownership architectures to find problems such as under-staffed subsystems and components that are at risk of being abandoned.
1.1 Paper Organization
The remainder of this document is organized as fol-lows. Section 2 describes ownership architectures. Section 3 describes the method we used to recon-struct the ownership architecture of Linux. Sec-tion 4 describes the ownership architecture we re-constructed from the Linux implementation. Fi-nally, Section 5 draws conclusions from this work.
2 OWNERSHIP
ARCHITEC-TURES
An ownership architecture shows how developers are grouped into teams, and shows the code that these teams have worked on. Documentation of this organization is useful for all large systems (for ex-ample, those with more than ten developers). For systems where the concept of code ownership is used (which includes all of those in our experi-ence), the ownership architecture indicates which developer or team owns each component of the sys-tem.
We define an ownership architecture as follows. The elements of an ownership architecture are source files, subsystems, developers, and teams. We use subsystems to group source files, and teams to group developers. Figure 1 shows an E/R di-agram of the elements of ownership architectures and how they are related. Subsystems can contain subsystems and source files, and similarly teams can contain (sub)teams and developers. We record ahacked2 relation between a developer and each
source file that he or she has modified.
Subsytem Team
contain
Source File Developer contain hacked
contain contain
Figure 1: Ownership Architecture Elements
Figure 2 shows a simple example of an owner-ship architecture. This sample architecture con-tains four source files (F1, F2, F3, F4), four
devel-opers (D1, D2, D3, D4), two subsystems (S1and
S2), and two developer teams (T1andT2).
S1 F1 F2 S2 F3 F4 Legend: Subsystem Source File Developer Team Developer hacked all T1 D1 D2 D4 T2 D3 hacked
Figure 2: Sample Ownership Architecture
Figure 2 shows that the files in subsystem S1
2We use the termhackedsince that is the term predominantly used by Linux developers.
were hacked by the developers in teamT1, and the
files inS2were hacked by the developers in team
T2. We use edges with a double arrow head to indi-cate that the hacked relation applies to all contained
files or developers. For example, bothD3andD4
modified bothF3andF4. By replacing four edges
with one, this convention reduces clutter in the dia-gram.
FileF3was hacked not only byT2but also by
D2. This shared developer might lead us to suspect thatF3is somehow related toS1(perhaps a feature was implemented with code in both subsystems). This is an example of how ownership architectures can help us to make hypotheses about program de-pendencies.
2.1 Ownership Architectures for
Soft-ware Understanding
Ownership architectures provide several benefits to developers who are attempting to understand a soft-ware system.
Identification of Experts. No matter how ac-curate documentation is, it is often more effective to talk to a developer who understands the code that is documented. If a developer is having dif-ficulty understanding a subsystem, the ownership architecture can suggest a set of developers who are likely to be experts on the subsystem. This use of a subsystem expert was noted by Perryet al.[13]; they found that developers received phone calls for advice about systems they had previously worked on. Sim and Holt [17] also found that newcom-ers to a development team relied on expert mentor-ing because there was insufficient accurate docu-mentation available; most of the system knowledge resided primarily in the heads of the system devel-opers and maintainers.
Non-Functional Dependencies. When recon-structing a software architecture, it is natural to ex-amine dependencies that occur in the source code. Relations such as function calls, data accesses, and data type dependencies have been used to help un-derstand large systems. However, this approach cannot easily detect relationships that are not man-ifested in the system’s source code. For example, in Linux we found that one team was responsible for porting Linux to the Amiga hardware platform. This team implemented a number of device drivers, and all of these drivers implemented functionality for Amiga hardware devices. We were not able to
classify these device drivers as Amiga drivers using only the source code since they share no common routines, data, nor data types. However, this clas-sification is strongly suggested by the ownership architecture. With some notable exceptions, most Linux developers worked on fairly specialized ar-eas of the operating system. This means that if a developer worked on portions of multiple subsys-tems, we may reasonably hypothesize some rela-tionship between these portions.
Quality Estimates. The experience level of de-velopers varies widely between individuals. This variance can affect how much confidence develop-ers have in the correctness of system components. For example, if a developer is looking for an ex-ample of how to code a particular operation, he or she would prefer to use an example developed by an expert as opposed to a newcomer to the system. By showing which developers worked on a given source file, ownership architectures help develop-ers estimate the the quality of code based on their confidence in the experience of the developers that wrote the code.
2.2 Evaluation Using Ownership
Ar-chitectures
Ownership architectures provide information that helps developers understand large software sys-tems. They can also be used to evaluate a system for several qualities. They can detect code that risks being abandoned, they can predict subsystems that have local understaffing or overstaffing, and they can predict whether the current organization pro-vides sufficient coverage of developers for ongoing maintenance of each subsystem.
Abandonment. If a system is actively main-tained, it is likely that there is some developer that has worked on each source file in the system, and some set of these people are likely to be owners or potential owners of the file. However, there may be some source files in a system that have not been modified by any of the current system developers. All authors of the file may have left the organiza-tion. If no developer owns a source file or
subsys-tem, it is referred to as abandoned. Abandoned
source files are a source of risk in software sys-tems since the ‘live’ knowledge in the form of ex-pert developers is no longer available. Modifica-tions take longer and are risky if they are performed
by developers who are not familiar with the code3.
An ownership architecture can be used to identify source files and subsystems that are at risk of be-ing abandoned. If a critical subsystem has only been hacked by one developer, then the system’s organizers might require that an extra developer be-come familiar with the system to avoid the risk of abandoning the subsystem. Similarly, if a devel-oper plans to leave an organization, the ownership architecture can be used to find the subsystems that would subsequently be abandoned; this can be used to assign replacement developers.
Understaffing / Overstaffing. In addition to the risks of subsystems becoming abandoned, owner-ship architectures can be used to discover areas of the system that have the wrong number of develop-ers: either too many or too few developers can re-duce development efficiency. If many subsystems depend on a single subsystem with insufficient de-velopers, then the dependent developers may wait too long for modifications by the subsystem’s own-ers. Additional developers can be assigned to alle-viate this situation, although as Brooks warns [3], this is not a simple solution. A converse problem is that of too many developers. If too many develop-ers are assigned to work on a small subsystem, they may not be able to adequately partition the work.
Ownership Coverage. A related issue to devel-opment bottlenecks is the idea of ownership cov-erage. When a large system is planned, it is com-monly designed as a hierarchy of subsystems. The ownership architecture shows what developers are expected to work on which subsystems. The ar-chitecture can be used to show that all subsystems have sufficient development resources; that is, there is sufficient ownership coverage.
3 RECONSTRUCTION
METHOD
Since many systems do not have a documented ownership architecture, we would like to be able to reconstruct the architecture from the implemen-tation and documenimplemen-tation. To reconstruct the ar-chitecture, we need to determine what developers 3In one development organization known to the authors, de-velopers are anxious to avoid modifying abandoned subsystems lest they involuntarily adopt them and gain additional respon-sibilities. These abandoned subsystems are referred to astar babies.
have worked on the system, and which source files they have worked on. This section describes the ap-proach we used to extract this information from the Linux system. We considered three sources of this information: source control logs, documentation, and copyright notices.
Source Control Logs. If a system’s source code is maintained in a source control system, then we can determine all of the modifications made by each developer. The Linux system uses CVS [4] to store source code. We found that source con-trol logs didn’t report all of the authors that had contributed to source files. In some cases, code was brought into Linux from other development ef-forts; the original authors of a file may not even have worked on the Linux kernel. In these cases and others, it appears that files were checked in to the source control system by someone other than the author.
Credits File. The Linux documentation includes a Credits file that lists developers that have con-tributed to the Linux system, along with the general areas of the system that they have worked on. This documentation makes it easy to determine devel-opers that have worked on the Linux system, but it does not specify which source files were modified by each developer. In addition, there is no guaran-tee that this documentation is up-to-date and accu-rate.
Copyright and Change Notices. Most of the source files in the Linux system have a copyright notice in a comment at the top of the file. This no-tice identifies the original author of the file. Most of the source files also contain comments identify-ing changes made by various developers through-out the file’s life time. These comments are kept in a file even if it is imported from another system or if it is moved within the Linux system. It ap-pears that the developers in the Linux system were generally careful to maintain copyright and change notices within the source files.
We decided to use copyright and change notices from the source files to determine which develop-ers had worked on each source file. The Credits file was not sufficiently precise, and the source control logs did not identify all of the developers that had worked on source files. We found that the copyright and change notices appear to provide sufficient in-formation to determine the developers that had ac-tually worked on each source file.
We manually examined copyright and change
notices within comments of the system source files to associate developer names with source files. We found that, in the case of Linux, some develop-ers used several variations of their name in dif-ferent source files. For example, some developers used only initials in some files but their full names in others. We resolved all spellings of developer names into a single identifier.
Although our extraction approach was specific to Linux, we believe that a similar approach could be used to extract the hacked relation for other soft-ware systems.
4 THE LINUX OWNERSHIP
ARCHITECTURE
We examined the Linux kernel, version 2.0.27. The kernel is an interesting case study because it is a widely used large system (comprising 800 KLOC). Further, the Open Source licensing of the system means there are no restrictions on discussing im-plementation details.
Using the method described in Section 3, we extracted the hacked relation. A developer was recorded as havinghackeda file if his or her name appears in a copyright notice or change log item in the source file. This can be interpreted as a list of developers that have contributed to a source file, ei-ther directly or through migration of code. Table 1 shows the number of files, developers, and relations that we found. We found that some of the source files did not have any copyright notices or change logs within comments. We omitted these files from our architecture.
#.cFiles 781 # Files Without Copyright Notice 82 # Developers 453 # Hacked Relations 1676
Table 1: Summary of ExtractedhackedRelation With 1676 relations between developers and files, it is necessary to group files into subsystems and developers into teams in order to understand the ownership structure. We will first discuss how we grouped files into subsystems, then how we grouped developers into teams.
We used a clustering of source files that we had previously created in a case study [2] to reconstruct
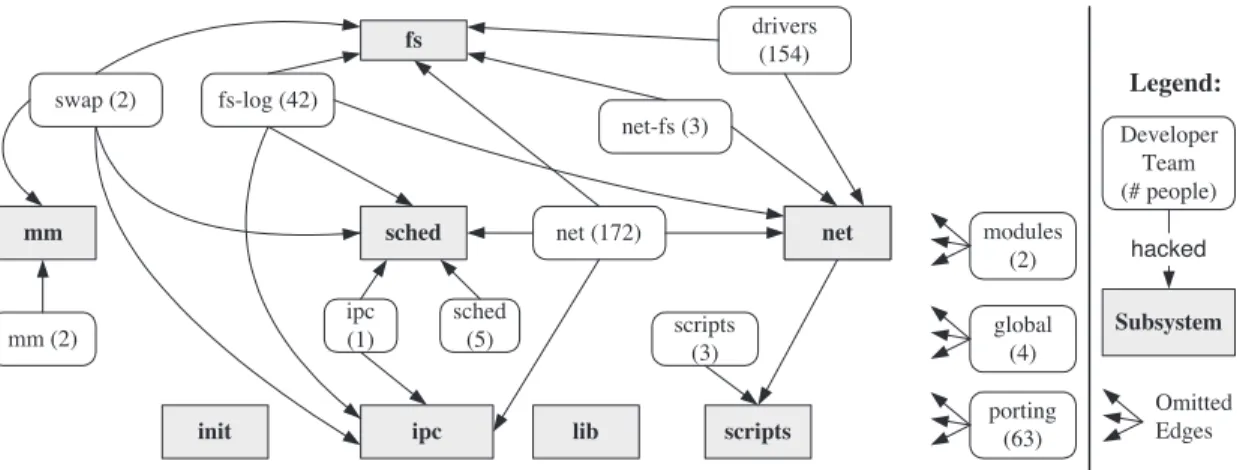
Legend: Subsystem hacked Developer Team (# people) fs mm sched net ipc scripts init lib drivers (154) fs-log (42) net (172) modules (2) ipc (1) net-fs (3) sched (5) mm (2) global (4) porting (63) scripts (3) swap (2) Omitted Edges net
Figure 3: Linux Ownership Architecture
the Linux concrete architecture. During this pro-cess, we used the Portable Bookshelf [9] to help us by diagramming the ownership architecture. Fig-ure 3 shows our reconstruction of the Linux owner-ship architecture at the highest level of abstraction. This figure shows the top-level subsystems and the top-level teams. Edges from a team indicate the subsystems that were hacked by members of the team, and parentheses indicate how many develop-ers are in each team. Three of the teams (modules, global, andporting) modified all the subsystems in the Linux kernel. We omitted the edges from these teams to improve the readability of the diagram.
We reconstructed eight top-level subsystems in the Linux kernel.
1. TheProcess Scheduler(sched) is responsible for allocating CPU resources to processes.
2. The Memory Manager(mm) provides each
process with a local view of system memory, and implements swapping.
3. The Inter-Process Communication (ipc)
subsystem provides support for communica-tion primitives such as shared memory and semaphores.
4. TheFile System(fs) allows user processes to access files on hardware devices. It provides abstractions for hardware devices and file sys-tems that are stored on the devices.
5. The Network Interface(net) supports
com-munication with other computers using a vari-ety of hardware interfaces and protocols. 6. TheInitialization(init) system is used when
the Linux kernel starts up. It initializes the
computer hardware, and initiates other sub-systems.
7. TheLibrary(lib) subsystem contains routines that are useful throughout the Linux kernel. 8. TheInstall Scripts (scripts) subsystem
con-tains scripts that are used to configure and in-stall a version of the Linux kernel.
We used system documentation to group devel-opers that had common roles. For example we found that a number of developers identified them-selves as having worked on device drivers. We grouped these developers together into thedrivers
team. We grouped developers based on
docu-mentation that stated what systems each developer had worked on. We reconstructed twelve top-level teams of developers. The teams that we created are not necessarily groups of interacting develop-ers, since we did not have access to records of their communication (Dutoit and Bruegge [7] use such records in their analysis).
The ipc, mm, net, scripts, and sched teams worked primarily on their associated subsystems. We found four teams that worked on the File
Sys-tem: theswapteam implemented swapping in the
Memory Manager, the fs-log team implemented
logical file systems, thedriversteam implemented device drivers for various hardware devices used in
the file system, and the net-fs team implemented
logical file systems that use the networking capa-bilities (such as Sun NFS).
In addition to these teams that worked primar-ily on one subsystem, we found found three teams of developers (modules,porting, and global) that
worked on almost all of the subsystems within the Linux kernel. First, we found that two developers
in themodulesteam made pervasive changes to
im-plement loadable modules. These changes affected
many of the kernel subsystems. Next, the
port-ingteam is responsible for implementing the Linux kernel on a variety of different hardware platforms, such as Sun Sparc, MIPS, PPC, and so on. These porting developers implemented platform-specific code in each of the top-level subsystems of the Linux kernel. Finally, we found one team (the globalteam) of four developers that appear to have worked on a majority of the Linux kernel. This team includes Linus Torvalds, the original author of Linux. These developers seem to have an exten-sive understanding of the entire Linux system.
Figure 3 shows the number of developers that have worked on each subsystem. These numbers suggest that the majority of the development effort for the Linux kernel has concentrated on the file system and the network interface. This is due to the wide variety of hardware devices and protocols that are implemented by Linux. The top-level own-ership architecture of the Linux kernel shows major subsystems and teams of developers, but doesn’t provide detailed information within theses subsys-tems and teams. For that, we need to look at lower levels of abstraction by examining the ownership architecture within subsystems of the Linux kernel. Due to size limitations, we will focus on only two of these subsystems in this paper. Section 4.1 de-scribes the ownership architecture of the Memory Manager subsystem, and Section 4.2 describes the ownership architecture of the Logical File System.
4.1 Memory Manager Ownership
Ar-chitecture
The Memory Manager subsystem within Linux manages access to the physical memory of the
com-puter. The Memory Manager maps virtual
ad-dresses used by user processes into physical mem-ory addresses, and supports swapping to disk to al-low the system to run more processes than fit in physical memory.
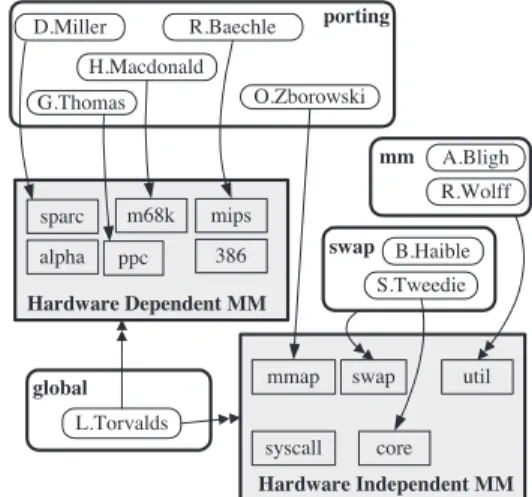
Figure 4 shows the ownership architecture of the Linux Memory Manager subsystem. There are two major subsystems within the Memory Man-ager: hardware-dependent code, which is specific to particular hardware platforms, and hardware-independent code which can be shared across
hard-ware platforms. Hardware Independent MM mmap core syscall util swap porting D.Miller O.Zborowski G.Thomas H.Macdonald R.Baechle swap B.Haible S.Tweedie mm A.Bligh R.Wolff global L.Torvalds sparc m68k mips ppc 386 alpha Hardware Dependent MM
Figure 4: Ownership Architecture of Memory Manager
In the teams shown in Figure 4, we have only shown developers who hacked code in the
Mem-ory Manager. The portingdeveloper team
devel-oped the hardware-dependent code for each of the supported memory platforms. The rest of the de-velopment in the Memory Manager was
accom-plished by two teams: the mm team contributed
to the utilsubsystem. The util subsystem of the
Memory Manager provides support for allocating memory for use by other subsystems within the
ker-nel. Theswapteam contributed to the development
of the memory swapping support within the
Mem-ory Manager. In addition to the work by the
port-ing,mmandswapteams, Linus Torvalds has
con-tributed to all of the subsystems within the Memory Manager.
The Memory Manager does not appear to have serious risks of subsystems becoming abandoned. Each of the subsystems has been modified by more than one developer (with the exception of the syscallsubsystem that provides a user-process in-terface to the Memory Manager).
4.2 Logical File Systems Ownership
Architecture
Thefssubsystem (see Figure 3) is responsible for abstracting both hardware devices and different logical file systems. The support for different file systems is implemented in the Logical File System
net-fs Net FS Unix FS porting vfat smbfs ncpfs
msdos fat umsdos
nfs hpfs minix xiafs ext ext2 sysv Remy Card ufs isofs procfs affs A.Cahalan 386 FS
G.David, J.Gelinas, F.Gockel, M.Nalis, H. Storner, J.Tombs,
P. Waltenberg G.Chaffee J.Gelinas W.Almesberger 386 FS E.Youngdale A.Rodriguez H.J.Widmaier, R.Burr M.Dobie, P.Willisson cd-rom E.Moenkberg P.Engstad V.Lendecke Rick Sladkey
A.Walker, F.La Roche, G.Knorr, G.Kuhlmann, J.Zapala, J. Bottomley, J.Peatfield, O.Kirch,
P.Eriksson, S.Thummler, W.S.Kok M.Mares,
M.Rausch
global Linux Torvalds A.Cox G.v.Wingerde
fs-swap S. Tweedie B.Haible
net E.Schoenfelder, G.J.Heim drivers F.N.van Kempen, M.Neuffer, D.ter Haar, J.Tranter, M.K.Johnson, P.Middelink Y.Arrouye FS D.Evans, P.Haible, P.Monday Q.F.Xia
Figure 5: Ownership Architecture of Linux Logical File Systems
subsystem, which is contained within thefs subsys-tem.
Figure 5 shows the ownership architecture for the Logical File System. The variety of logical file systems allow Linux to use file systems created by operating systems such as Minix, Xenix, MS-DOS, and the Amiga. Each file system is implemented independently of the others with no shared code or data. However, it is apparent from the organization of developers that there is similarity between some of these file systems. For example, the five file sys-tems that W. Almesberger hacked (msdos,fat,vfat, umsdos, andhpfswithin the386 FSsubsystem) ap-pear to be relatively isolated from the rest of the file systems. These five subsystems implement file
sys-tems that are compatible with other PC operating systems that are used on Intel 386 compatible com-puters, namely MS-DOS, Windows 95, and OS/2.
Similarly, thenfs,ncpfs, andsmbfssubsystems
within theNet FS subsystem seem related by the
developers that have worked on them. These
sub-systems were all hacked by the net-fs team, and
this team also hacked thenet subsystem, as seen
in Figure 3. The sharing of developers between theNet FSandnet subsystems suggests that these subsystems are related. In fact, these three subsys-tems (nfs,ncpfs, andsmbfs) implement file systems
that are distributed over a network. The nfs file
system is compatible with Sun’s NFS implementa-tion,ncpfsis compatible with Novell Netware, and
smbfsis compatible with Microsoft Windows 95.
The six subsystems within theUnix FS
subsys-tem at the bottom of Figure 5 also appear to be re-lated: they were all modified by S. Tweedie and R. Card, as well as a variety of other developers. We found that in fact these subsystems are related since they implement file systems that are similar to Unix file systems.
The procfs file system is used to report kernel
statistics. Several teams have hacked the procfs
subsystem, presumably to add statistics related to other subsystems in the kernel.
Another case where the ownership architecture
predicts the function of a subsystem is the isofs
subsystem near the top of Figure 5. A number of
developers have hacked theisofs subsystem. One
of these, E. Moenkberg, is a member of thecd-rom
subteam of thedriversteam. Thecd-romsubteam
developed device drivers for CD-ROM drives. This
suggests that theisofssubsystem might somehow
be related to CD-ROM drives. We found that in factisofsimplements the ISO 9660 file system that is commonly used on CD-ROMs.
Another interesting suggestion provided by the ownership architecture is the reason for the name
of the xiafs subsystem. We note that developer
Q.F. Xia hacked thexiafssubsystem; this indicates
that the name xiafs is eponymous; this saves us
from trying to interpret it as an acronym.
The predictive powers of ownership architec-tures are not perfect since developers have mul-tiple independent skills and interests. For exam-ple, E. Youngdale worked onaffs,isofs, andhpfs although there is no obvious dependency between these subsystems. However, the ownership archi-tecture has been able to suggest interesting rela-tions that we were not able to find using only the source code.
5 CONCLUSIONS
This paper has described the idea of anownership
architecturefor a software system, and has shown how such a structure is useful not only in forward engineering, but also as a document for system un-derstanding. We have demonstrated how an owner-ship architecture can be reconstructed from a sys-tem implementation and documentation, and we have shown an example ownership architecture for Linux.
Ownership architectures help us to identify sub-system experts so that we can use interviews to learn more about particular systems. They can sug-gest non-functional dependencies between subsys-tems that are related even when there is no source code dependency. Finally, ownership architectures can provide us with an estimate of the quality of a subsystem based on our confidence in the subsys-tem’s developers. Ownership architectures permit us to evaluate a software system for risks of code abandonment, local staffing problems, and overall developer coverage.
More generally, this paper suggests that owner-ship architectures help us understand important as-pects of large systems by providing a visualization of the organization of developers and the source files they have worked on.
Acknowledgments
We would like to thank Gary Farmaner for his sup-port with the Portable Bookshelf tools The contri-bution of the Linux developer community is grate-fully acknowledged. Susan Sim provided helpful feedback on an earlier draft of this paper.
About the Authors
Ivan T. Bowman is an MMath student in the Department of Computer Science at the Univer-sity of Waterloo. Bowman received his BMath de-gree from the Computer Science Department of the University of Waterloo in 1995. His research in-terests include software architecture, reverse engi-neering, and program visualization. (See WWW http://plg.uwaterloo.ca/˜itbowman).
Richard C. Holt is a professor at the Univer-sity of Waterloo in the Department of Computer Science. Holt received his Ph.D. degree in Com-puter Science from Cornell University in 1971. His research has included work in operating systems, compiler development, and software construction methods. He is an author of the Turing program-ming language. His recent work has concentrated on Software Landscapes, which provide a visual formalism for software architectures. (See WWW http://plg.uwaterloo.ca/˜holt).
References
[1] Ivan T. Bowman and Richard C. Holt. Soft-ware architecture recovery using Conway’s
law. In Proceedings of CASCON’98, pages
123–133, Toronto, Ontario, November 1998.
[2] Ivan T. Bowman and Richard C. Holt. Linux as a case study: Its extracted software
archi-tecture. In Proceedings of ICSE’99, to
ap-pear, Los Angeles, California, May 1999.
[3] Frederick P. Brooks, Jr. The Mythical
Man-Month. Addison Wesley, Anniversary edition, 1995.
[4] Per Cederqvist. Version Management with
CVS. Signum Support AB, Box 2044, S-580
02 Linkoping, Sweden, November 1993.
[5] Melvin E. Conway. How do committees
in-vent? Datamation, 14(4):28–31, 1968.
[6] James O. Coplien. A Development Process
Generative Pattern Language, chapter 13, pages 183–237. Addison-Wesley, Reading, MA, 1995.
[7] Allen H. Dutoit and Bernd Bruegge. Com-munication metrics for software development
computer society. IEEE Transactions on
Software Engineering, 24(8):615–628, Au-gust 1998.
[8] P. J. Finnigan, R. C. Holt, I. Kalas, S. Kerr, K. Kontogiannis, H. A. M¨uller, J. Mylopou-los, S. G. Perelgut, M. Stanley, and K. Wong.
The software bookshelf. IBM Systems
Jour-nal, 36(4):564–593, October 1997.
[9] Ric Holt. Software bookshelf: Overview and construction. Available at:
http://turing.toronto.edu/, March 1997.
[10] Rick Kazman and S. Jeromy Carri`ere. View extraction and view fusion in architectural
understanding. In Proceedings of ICSR5,
Toronto, Canada, June 1998.
[11] Phillipe Kruchten. The 4+1 view model
of software architecture. IEEE Software,
12(6):42–50, November 1995.
[12] Gail C. Murphy, David Notkin, and Kevin Sullivan. Software reflexion models: Bridg-ing the gap between source and high-level
models. In Proceedings of the Third ACM
SIGSOFT Symposium on the Foundations of Software Engineering, pages 18–28, Wash-ington, DC, October 1995. IEEE Computer Society Press.
[13] Dewayne E. Perry, Nancy Staudenmayer, and Lawrence G. Votta. People, organizations,
and process improvement. IEEE Software,
11(4):36–45, July 1994.
[14] Dewayne E. Perry and Alexander L. Wolf. Foundations for the study of software
archi-tecture. ACM SIGSOFT Software
Engineer-ing Notes, 17(4):40–52, October 1992. [15] Mary Shaw, Robert DeLine, Daniel V. Klein,
Theodore L. Ross, and David M. Young. Ab-stractions for software architecture and tools
to support them. IEEE Transactions on
Software Engineering, 21(4):314–335, April 1995.
[16] Mary Shaw and David Garlan. Software
Ar-chitecture: Perspectives on an Emerging Dis-cipline. Prentice Hall Press, April 1996. [17] S.E. Sim and R.C. Holt. The ramp-up
prob-lem in software projects: A case study of
how software immigrants naturalize. In
Pro-ceedings of the 20th International Conference on Software Engineering, Kyoto, Japan, April 1998.
[18] Dilip Soni, Robert L. Nord, and Christine Hofmeister. Software architecture in indus-trial applications. InProceedings of the 17th International Conference on Software Engi-neering, pages 196–207, Seattle, Washington, April 1994.
[19] Vassilios Tzerpos, R.C. Holt, and Gary Far-maner. Web-based presentation of hierarchic
software architecture. In Workshop on
Soft-ware Engineering (on) the World-Wide Web, Boston, May 1997. International Conference on Software Engineering 1997.
[20] Kenny Wong, Scott R. Tilley, Hausi A. M¨uller, and Margaret-Anne D. Storey.
Struc-tural redocumentation: A case study. IEEE