International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
163
An Adaptive Intelligent Look-ahead Scheduling Algorithm for
Heterogeneous Multi-Cluster Systems
Savita Mahajan
1, Rasleen kaur
21Student, M.Tech., 2Assistant Professor,Computer Science and Engineering, Global Institute of Management and Emerging
Technologies, Amritsar, India
Abstract—In this paper, an adaptive intelligent look-ahead scheduling algorithm for heterogeneous multi-cluster systems has been proposed. Principle improvement has been done in an integrated processor allocation and job scheduling approach where different allocation decisions are made dynamically according to the current workload type and system configurations. Additionally, algorithm best suited to both single-site allocation and multi-site co-allocation in heterogeneous multi-cluster systems. In the end, the high performance improvement of the proposed technique in terms of average turnaround time and system utilization, subject to different system load and speed heterogeneity is analyzed.
Keywords—Job scheduling, Processor allocation, Multi-cluster system, heterogeneity
I. INTRODUCTION
Job scheduling and processor allocation are two important aspect of heterogeneous multi-cluster computing. The architecture of HMC consists of 2 components: firstly, Central job scheduler or Meta-scheduler, which is commonly used to dispatch all submitted jobs. Secondly, central queue, also called as waiting queue which is used to acquire all those jobs submitted by meta-scheduler. The central job scheduler has two significant operations to perform out of which one is job scheduling and other is processor allocation. The function of job scheduling is to decide the execution order of jobs whereas processor allocation function is to decide which cluster(s) to allocate the job to.
II. JOB SCHEDULING ALGORITHMS
The function of job scheduling is to decide the execution order of jobs.
A. Space sharing algorithms
It gives the requested resources to the job until the job is completely executed. It has low overhead and high parallel efficiencies [2].
Static scheduling:
Scheduling performed at compile time, and then jobs are allocated to individual processors before execution.
The allocation remains same during the execution. Most static scheduling methods needs to gather information needed for the scheduler to make further decisions, according to what kind of resources are necessary for job [3].
Dynamic scheduling:
Scheduling is performed at run time and it can support dynamic load balancing and fault tolerance. Load balancing could share the load between nodes, even when job is in its execution state.
Adaptive Scheduling:
It combines static and dynamic scheduling. The static scheduling function is to collect information required for the scheduler to make decisions on what kinds of resources are compulsory and function of dynamic scheduling is load balancing of job‘s loop [4].
B. Time sharing algorithms
The time on a processor is divided into many discrete intervals or time slots which are assigned to unique jobs.
III. PROCESSOR ALLOCATION ALGORITHMS
Processor allocation is concerned with assignment of required number of processors for incoming job from available sites [12, 13].
A. Single-site allocation
First-fit:
Allocate the first cluster found in the searching process that has enough available processors for the waiting job. The system can stop searching as soon as it finds a cluster that has enough available processors.
Worst-fit:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
164
Best-fit:
Allocate the site with the least available processors that is enough for the waiting job. The system must search each site. This policy yields the least leftover processors for the selected site [2, 3].
Most-fit:
This policy tries to allocate the job to a cluster which produces a leftover processor distribution, tending to the most number of immediate subsequent job allocations. It requires a more complex searching process, involving simulated allocation activities, to determine the target cluster. For each cluster which has enough processors for the waiting job, the system performs a series of simulated
activities, based on the best-fit policy, to measure how
many immediate subsequent allocations can follow the allocation decision. After each cluster has been checked, the system selects the cluster with the largest number of immediate subsequent allocations to perform current job allocation [12].
B. Multi-site co-allocation
Fixed order:
The system maintains a list of all the sites in the computing grid. The order of that list is fixed. Every time the system pick up a site from the list according to the stable order until the total number of available processors on all selected sites is larger than or equal to the requirement of the waiting parallel job [6,8].
Larger first:
The system first sorts the sites in the computing grid into decreasing order according to the number of available processors. Then, the system repeatedly picks up a site according to the sorted order until the total number of available processors on all selected sites is larger than or equal to the requirement of the waiting parallel job [8].
Smaller first:
In contrast to larger-first, the system first sorts the sites in the computing grid into increasing order according to the number of available processors. Then, the system repeatedly picks up a site according to the sorted order until the total number of available processors on all selected sites is larger than or equal to the requirement of the waiting parallel job [6, 10].
IV. LITERATURE SURVEY
D.D. Sharma, D.K. Pradhan [1] proposes a multi-user environment for dynamic processor allocation in hypercube multi-computers.
For both cubic and non-cubic allocation, two algorithms have been proposed that uses the concept of processor allocation through dynamic binary tree in addition to an array of free lists. The simulation results state that time complexities are reduced from polynomial to exponential that is remarkable performance improvement over the existing algorithms by taking into account the parameters such as average delay in making a request, average allocation time, average de-allocation time and memory overhead . V. Hamscher, et al. [2] presents the typical scheduling structures of grid computing which is known as best fit i.e. allocate the site with the minimum available processors which is enough for the waiting job . The various job scheduling algorithms and job selection policies relevant to these structures have been proposed and explained. Different simulations carried out to calculate different aspects, considering combinations of several job and machine model. Backfill technique seems to benefit the hierarchical scheduling under a common scheduling structure whereas first come; first serve (FCFS) gives better results in comparison to backfill on using central job pool. E. Carsten, et al. [3] presents the possible benefits that can be obtained on sharing jobs between single sites in grid computing environment. It also addresses the effect of parallel multi-site job execution on different sites.
Simulations on several scheduling algorithms by
considering multi-site job execution under different machine configurations with different workload types from real traces shows the major improvement by reducing
average response time of job. Jemal H. Abawajy , S. P.
Dandamudi [4] presents a dynamic parallel processor
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
165 Simulations results indicate that using conservative and easy backfilling combine in backfilling procedure shows better results in comparison to non-adaptive algorithm. K.-C. Huang, H.-Y. Chang [7] explores that job scheduling and processor allocation are two major techniques for enhancing the performance of cluster computing systems. Developing an integrated approach for job scheduling and processor allocation can enhance the overall system performance by reducing the 20 times waiting ratio of a job. Anca I. D. Bucur ,Dick H. J. Epema [8] used Distributed ASCI Supercomputer (DAS) (multi-cluster) system in her research and studied the performance of
co-allocation. Co-allocation is a technique in which a parallel
job is broken into components and each component can be processed in a different cluster. Co-allocation allows jobs to be mapped across cluster boundaries. In doing so, resource fragmentation is reduced and system utilization is increased. In this paper site and cluster are used interchangeably. K.-C. Huang, et al [9] explains that in grid computing grid consist of interconnected sites to join and be a part of it. Grid helps in performance improvement of contributing sites that is achieved through feasible and effective load sharing. It proposes the fastest first policy in single site job execution which chooses the fastest available processor for executing job. It also explains the load sharing policies defined on feasibility and heterogeneity on
computational grid. The significant performance
improvement is achieved in heterogeneous computational grid (K.-C. Huang, P. C. Shih, Y. C. Chung, 2007). O. Sonmez, et al [10] addresses the benefits of using co-allocation in multi-cluster grid environment. It emphasizes that by considering latency factor in resource allocation phase of co-allocation improves the performance of overall
system particularly for communication intensive
applications. P.-C. Shih, et al [11] describes that in a
heterogeneous grid environment; overall system
performance is highly affected by two major factors those are speed heterogeneity and resource fragmentation that respond differently under different workload sources and system configuration. This work is focused on analyzing existing processor allocation algorithms relative strengths. After examining algorithms new processor allocation algorithms adaptive intelligent has been proposed that take speed heterogeneity and resource fragmentation into consideration and is combination of best fit and fastest first scheduling policy. Kuo-Chan Huang Kuan-Po Lai [12] this paper explains that the multi-cluster system architecture suffers from the issue of resource fragmentation in which no single cluster is being able to provide accommodation for a job, where the total number of processors in the entire grid or cloud is enough for each job.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
166
V. PROPOSED METHODOLOGY
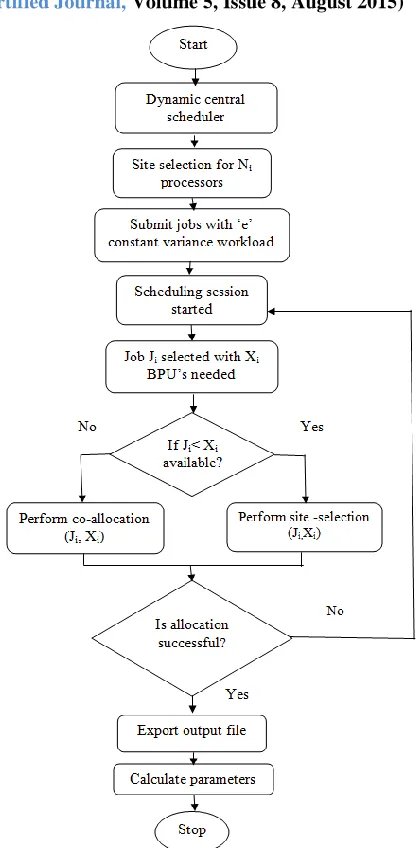
The proposed adaptive intelligent look-ahead (AIL) scheduling algorithm work as follows when a job is submitted to the system. Firstly the incoming jobs are scheduled according to least arrival time using First come, first serve (FCFS) algorithm which is job scheduling phase. Secondly, after jobs are scheduled site selection policy is applied. The algorithm proposed is capable of working with both single-site system and multi-site co-allocation system of multi-cluster systems. Thirdly, processor allocation to the jobs takes place through Best fit algorithm.
Ji – job to be scheduled
Xi – Number of BPU‘s required
Step 1: Start dynamic central scheduler initializing different
parameters.
Step 2: Submit job with ‗e‘ constant variance workload
Step 3: Scheduling session get started after job are
submitted.
Step 4: For each job Ji to be scheduled apply job selection
algorithm in which jobs are scheduled according to lest arrival time.
Step 5: Check the status of all the sites for available
processors.
Step 6: If number of BPU‘s needed is less than available
processors in any site perform site selection using
site_selection (Ji, Xi) algorithm and calculate the
parameters.
Step 7: Else if the number of BPU‘s needed is greater than
Number of available processors in any site Perform
co-allocation using co-allocate (Ji, Xi ) algorithm.
Step 8: If a processor allocation is not successful then
[image:4.612.338.546.122.546.2]returns to step 4.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
167
VI. EXPERIMENTAL SETTINGS
The public downloadable workload type used is of TUV supercomputer. It has been reported that workload characteristics and different system configuration can have major impact when evaluating the performance of a AIL scheduling algorithm. In order to consider those effects, the simulation configuration includes a variety of workload source, system configuration, level of speed heterogeneity and level of system loading. For workload source, we use a number of public downloadable workload logs and models from parallel workload archive to avoid favoritism caused by precise workload characteristic.
The results are deduced through sequence of simulations which are carried on for both the possible strategies such as Multi-pool configuration and Multi-site execution. The proposed system model is subjected to different workload conditions and there are sets of 5000 jobs per simulation. The traces are generated considering various situations such as diverse arrival rate coefficients, different service rate coefficients, different work load conditions with specific parameters such as arrival rates and services rates fixed.
LOAD_VARIES_WITH_FIXED_SERVICERATE (In
[image:5.612.319.568.403.494.2]terms of Mean Response Time (MRT)) (‗ar‘ varies, Cov-9), (sr=0.06, Cov-3)
TABLE I Workload
Load Varies/ar MRT
Load=10%, ar=0.4 79.6
Load=20%, ar=0.8 273.36
Load=30%, ar=1.2 900.12
Load=40%, ar=1.6 1355.6
Load=50%, ar=2.0 1551.64
Load=60%, ar=2.4 1755.63
Load=70%, ar=2.8 1835.38
Load=80%, ar=3.2 1961.22
Load=90%, ar= 3.6 2019.66
Table 1 shows the workload characteristics such as load variance, arrival rate and mean response time.
Various values obtained after running the traces of 5000 jobs in different work-load conditions when the arrival rates and service rate and coefficients of arrival rate are fixed, whereas a coefficient of service rate varies.
All experiments are performed under various simulation configurations, together with the combinations of the subsequent parameters such as speed heterogeneity having 3 standards 0.1, 0.2, and 0.3, and system loading as low, medium, high. Three levels of system loading, namely low (SL = 0.50), medium (SL = 0.75), and high (SL = 1), are considered in the simulations.
VII. RESULTS AND DISCUSSION
Performance result of public downloadable workload with low system loading, medium system loading, high system loading, and performance improvement with respect to different system loading (SL) and speed heterogeneity (SH).
TABLE II
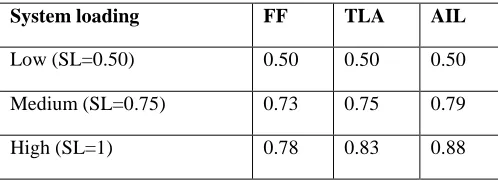
Evaluation of Average Utilization for FF, TLA, AIL
System loading FF TLA AIL
Low (SL=0.50) 0.50 0.50 0.50
Medium (SL=0.75) 0.73 0.75 0.79
High (SL=1) 0.78 0.83 0.88
[image:5.612.102.238.441.679.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
168 0
100000 200000 300000 400000 500000 600000 700000 800000 900000 1000000
0.1 0.2 0.3
Av
e
ra
ge
T
u
rn
ar
o
u
n
d
T
ime
Speed Heterogeneity
FF
TLA
[image:6.612.328.560.128.431.2]AIL
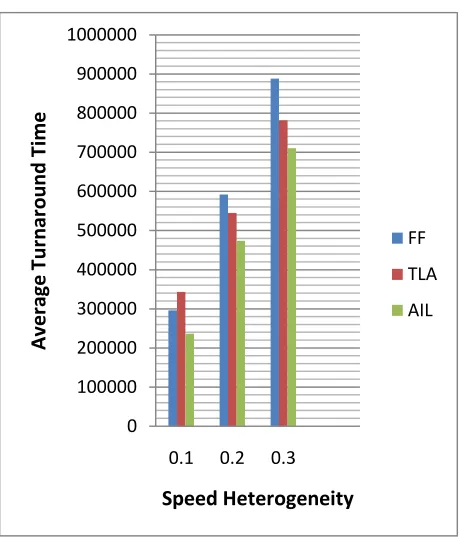
Figure 2: Performance result of workload with low system loading (0.50)
Fig.2 is showing that at low system loading (0.50) under different speed heterogeneity factors (0.1, 0.2 and 0.3), the effect of resource fragmentation much less noteworthy, which results in little performance difference. Moreover, low system loading results in less jobs waiting in the queue, offering little information for AIL to make a better allocation decision.
0 200000 400000 600000 800000 1000000 1200000 1400000 1600000 1800000
0.1 0.2 0.3
Av
e
ra
ge
T
u
rn
ar
o
u
n
d
T
ime
Speed Heterogeneity
FF
TLA
AIL
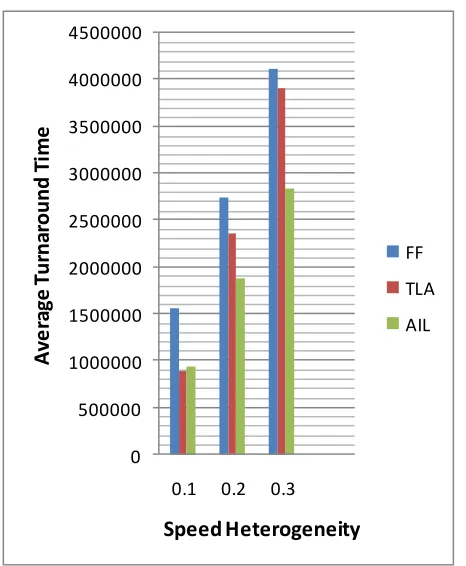
Figure 3: Performance result of workload with medium system loading (0.75)
[image:6.612.54.287.131.403.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
169 0
500000 1000000 1500000 2000000 2500000 3000000 3500000 4000000 4500000
0.1 0.2 0.3
A
ve
ra
ge
T
ur
na
ro
un
d
Ti
m
e
Speed Heterogeneity
FFTLA
[image:7.612.323.561.128.400.2]AIL
Figure 4: Performance result of workload with high system loading (1)
Fig.4 illustrate that at high system loading (1) under different speed heterogeneity factors (0.1, 0.2 and 0.3), the performance improvement ratio after implanting AIL technique has been reduced highly.
0 50000 100000 150000 200000 250000 300000 350000
D
if
fe
re
nc
e
in
A
TT
System Loading
SH=0.1
SH=0.2
[image:7.612.54.287.132.415.2]SH=0.3
Figure 5: Performance improvement with respect to different system loading (SL= 0.50, 0.75, 1) and speed heterogeneity (SH= 0.1, 0.2, 0.3).
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 8, August 2015)
170
VIII. CONCLUSION AND FUTURE SCOPE
In this review has shown that the existing techniques have ignored the issue such as if processor allocation method can operate with different scheduling methods. Increase in resource utilization rate is an important issue for resolution. Moreover, there is proposal for single site allocation of processor but no provision for multi-site co-allocation of processor in heterogeneous multi-cluster systems. Therefore to overcome these issues, an adaptive intelligent look-ahead (AIL) scheduling algorithm for heterogeneous multi-cluster systems has been proposed. The proposed technique shows upto an approximately 35% performance improvement over TLA method, optimizing average turnaround time, system performance and processor utilization.
As for future works, firstly other optimized algorithms such as Median Fit, Round Robin (RR), Fixed Order, Smaller First etc. in parallel scheduling can be used which require further studies. Secondly, moldable jobs can be used as presently all jobs used are assumed to be rigid in nature that is the required number of processors of each job cannot be changed after job submission.
REFERENCES
[1] D.D. Sharma, D.K. Pradhan, ―Processor allocation in hypercube
multicomputers: fast and efficient strategies for cubic and noncubic allocation‖, IEEE Transactions on Parallel and Distributed Systems, 1995, vol.6, pp. 1108–1122.
[2] V. Hamscher, et al., ―Evaluation of job-scheduling strategies for grid
computing‖, in: Proceedings of the 7th International Conference on High Performance Computing, HiPC-2000, 2000, pp. 191–202.
[3] E. Carsten, et al., ―On advantages of grid computing for parallel job
scheduling‖, in: Proceedings of the 2nd IEEE/ACM International Symposium on Cluster Computing and the Grid, CCGrid‘02, 2002, pp. 39–39.
[4] Jemal H. Abawajy , S. P. Dandamudi,”Parallel job scheduling
policies on cluster computing systems”, Carleton University Ottawa,
Ont., Canada, ACM 2004.
[5] K. Li, ―Job scheduling and processor allocation for grid computing
on metacomputers‖, Journal of Parallel and Distributed Computing, 2005, vol. 65, pp. 1406–1418.
[6] Z. Weizhe, et al., ―Multisite co-allocation algorithms for
computational grid‖, in: Proceedings of the 20th IEEE International Symposium on Parallel and Distributed Processing, IPDPS‘06, 2006, pp. 335–335.
[7] K.-C. Huang, H.-Y. Chang, ―An integrated processor allocation and
job scheduling approach to workload management on computing grid‖, in: Proceedings of the International Conference on Parallel
and Distributed Processing Techniques and Applications,
PDPTA‘06, Las Vegas, USA, 2006, pp. 703–709.
[8] Anca I. D. Bucur ,Dick H. J. Epema,‖ Scheduling Policies for
Processor Coallocation in Multicluster Systems‖ IEEE Transactions
on Parallel and Distributed Systems,2007, vol.18,pp. 958-972.
[9] K.-C. Huang, et al., ―Towards feasible and effective load sharing in a
heterogeneous computational grid‖, in: Proceedings of the 2nd International Conference on Advances in Grid and Pervasive Computing, GPC‘07, 2007, pp. 229–240.
[10] O. Sonmez, et al., ―On the benefit of processor coallocation in
multicluster grid systems‖, IEEE Transactions on Parallel and Distributed Systems 21 (2010) 778–789.
[11] P.-C. Shih, et al., ―Improving grid performance through processor
allocation considering both speed heterogeneity and resource fragmentation‖, The Journal of Supercomputing (2010) 1–27.
[12] Kuo-Chan Huang Kuan-Po Lai, ―Processor Allocation Policies for
Reducing Resource Fragmentation in Multi-Cluster Grid and Cloud Environments‖, IEEE 2010, pp 971 – 976.
[13] J. Ramírez-Alcaraz, et al., ―Job allocation strategies with user run time estimates for online scheduling in hierarchical grids‖, Journal of Grid Computing, 2011, vol.9 ,pp 95–116.
[14] Sid Ahmed MAKHLOUF, Belabbas YAGOUI , ‖Co-allocation in
Grid computing using Resources Offers and Advance Reservation Planning‖, Courrier du Savoir – N°14,2012, pp.73-79.
[15] Po-Chi Shih, Kuo-Chan Huang, Che-Rung Lee, I-Hsin Chung and