2017 2nd International Conference on Computer Engineering, Information Science and Internet Technology (CII 2017) ISBN: 978-1-60595-504-9
Association Analysis of Complex Product Digital
Prototype Data Based on the Improved
FP-Growth Algorithm
CAN XU, LIBING LIU, ZHIHONG TAN and SHIRONG SUN
ABSTRACT
The data of complex product digital prototype with complex relationships have massive, high-dimensional features. Its relevance mining and performance evaluation is a difficult problem. Data mining algorithms can be used to solve the data feature association problem of complex performance. This paper presents an improved FP-Growth algorithm. Improved algorithm adds the weight setting of each dimension attribute to avoid generating redundant false rules due to the uneven distribution of attributes. It constructs the function to map the attribute name and the weighted support count, and reduces the number of times of traversing the frequent item list. It divides the subset of each dimension attribute and constructed the conditional pattern tree of each dimension subset to improve the efficiency of the original algorithm. Based on the improved FP-Growth algorithm, taking the digital prototype data of the bag filter as an example, the parameter combination model was analyzed from the multidimensional angle. It generated the best parameter combination association rule of the bag filter wind performance. It is proved that the improved FP-Growth algorithm is effective and efficient.
KEYWORDS
Digital Prototype, Data Mining, Association Rules, the Improved FP-Growth Algorithm, Bag Filter, Parameter Combination.
INTRODUCTION
Digital prototype is the main part of the process for complex product innovation and development. It is computer mathematical model of simulation which based on geometric model [1], and it can accurately and comprehensively reflect the characteristics of product appearance, function and behavior. Therefore, in recent years, digital prototype has gradually replaced the physical prototype to test product performance. Depending on the function, the digital prototypes contain structural prototypes, functional prototypes, structural and functional prototypes [2]. The large-scale and high-complexity features in the design process make the digital prototyping system produce massive, high-dimensional and complex data. Therefore, the analysis of complex product digital prototype is still a difficult problem. At present, the research of digital prototype data of complex product is mainly based on engineering experience or independent qualitative analysis of single discipline, which lacks practical guidance significance.
_________________________________________
In this paper, the data mining association rule technology is used to analyze the data correlation of the digital prototype of the bag filter, and the optimal control reference range of the digital prototype process parameters is explored.
Agrawal first proposed the concept of data mining association rules in 1993[3]. Apriori algorithm as the most classic algorithm of association rules, needs to repeatedly scan the database and generates a large number of candidate items. The algorithm is inefficient. Han et al. proposed the frequent pattern mining algorithm FP-Growth [4], which only scans the database twice and does not produce the candidate set. It is an order of magnitude faster than the Apriority algorithm. At present, FP-Growth algorithm has been applied in the data association research in power, aviation, railway, chemical industry [5-8]. However, when faced with massive data, the efficiency of the algorithm is still not high. Therefore, the researchers have proposed a number of FP-Growth improved algorithms: frequent pattern mining based on factorization[9], frequent pattern mining algorithm based on hash table[10], an improved algorithm based on B transaction clustering[11], batch incremental mining algorithm[12], an improved FP-Growth algorithm based on MapReduce[13] and so on. However, when the database attributes are too many, how to reduce the number of frequent item lists, and to avoid the depth and width of the FP tree construction to be too complex and huge, remains to be studied. In addition, the FP-Growth algorithm is relatively few studied in the field of digital prototype, and how to improve the algorithm so that it could produce valuable combination of parameters from a large number of simulation samples is also a difficult problem to be studied.
Based on the above FP-Growth algorithm disadvantages and the characteristics of digital prototype data, this paper proposes an improved FP-Growth algorithm. The multi-dimensional attributes in the database are introduced into different attribute weights to avoid a large number of misleading frequent patterns due to the differences of attribute importance and uneven distribution in the database. Then, calculating the weight support count of each attribute and constructing the hash function to realize the mapping between each dimension attribute and the weight support. So, it can avoid the effect of the algorithm by repeatedly traversing the frequent item list. Third, the subset of each dimension attribute is divided, and the conditional model tree of the subset is constructed to improve the efficiency. Finally, this paper used the improved FP-Growth algorithm to analyze the data correlation of the large-scale environmental protection equipment bag filter digital prototype as an example, and obtained the parameter combination which affected the wind performance. At the same time, the feasibility and superiority of the improved algorithm is improved.
THE IMPROVED FP-GROWTH ALGORITHM
Fp-growth algorithm basic theory
FP-tree. The mining of the database becomes the mining of the FP-FP-tree. After that, the calculation of the frequent itemsets support count is only needed in the FP-tree. And the algorithm no longer needs to scan the entire database.
Fp-growth algorithm improvement ideas
First, the classical FP-Growth algorithm considers the importance of each dimension attribute uniform and ignores the difference of the frequency of each attribute in the database. However, the scale of digital prototype system is large, modeling, simulation time costs are high; the number of samples is limited. In limited samples, the distribution of attributes and the frequency of occurrence are uneven. Therefore, when the traditional algorithm defaults to the same distribution and importance of attributes, it will ignore the low frequency occurrence but important attributes, resulting in redundancy and false rules. Meanwhile the combination of the attribute explosion will reduce the efficiency of the algorithm.
The improved FP-Growth algorithm considers the frequency and importance of each dimension attribute, and introduces the concept of attribute weight. Assuming D is the sample database, the database properties collection is as follows:
1 2 m
I = {I , I , , I }. The corresponding attribute weights are:W = {W , W ,1 2 , W }m ,
j
0W 1, j = {1, 2, ,m}. If wsupport is the weighted support, minwsupport is
the weighted support threshold.X, Yis two attributes in the database, XY =. Then the weighted support of the attribute X is
j j I X
wsupport(X) = ( W ) support(X)
(1)The weighted support of“X Y”is
j
j I X Y
wsupport(X Y) = ( W ) support(X Y)
(2)
The weight of each attribute is determined by the support vector machine prediction method and the sample frequency statistics method. If the attribute X satisfies the condition wsupport(X)minwsupport , it is a frequent item set. Therefore, the algorithm can increase the weighting of the attributes and calculate the weight support of each attribute. By comparing the support degree with the threshold, it can get the frequent item sets considering the influence factors of each attribute, so as to avoid the uneven distribution of the database attributes.
algorithm. The following Table I and Table II show the storage structure of the traditional algorithm and improved algorithm.
Finally, in the traditional FP-Growth algorithm, the FP-tree construction process uses “null” as the root node, and the whole FP-tree is constructed directly from the original database. If the database contains a large number of multi-dimensional attributes, each transaction attribute dimension is much, the overall FP-tree depth and width will be too complex and large. The efficiency of the algorithm will be seriously affected. The improved FP-Growth algorithm divides each dimension in the multidimensional attribute into several subsets, and constructs the conditional pattern tree of each dimension subset directly. This will greatly improve the tree's structural efficiency. All of the generated frequent patterns are still merged into a frequent pattern set for the entire database.
The improved fp-growth algorithm implementation
The implementation process of the improved FP-Growth algorithm is:
1)Data preprocessing. Enter the preprocessed sample database, each dimension attribute weight and weighted support threshold.
2)Scan the database, calculate the weighted support count of attributes and record.
3)Construct a hash function. The independent variable is the attribute name, and the dependent variable is the storage address of the attribute. The weighted support of the independent variable is read by the storage address. The mapping of independent variable and its weighted support is done by a hash function.
4)Scan the database again, delete the property whose weighted support is less than the threshold. Then sort the database transactions in descending order according to the weighted support count.
5)In the new database, we use the recursive way to create the conditional FP-tree with the dimension attribute as the root node.
6)Merge all the frequent itemsets.
[image:4.612.89.506.504.615.2]7)Set the best confidence threshold to get the association rules.
TABLE I. FP-GROWTH ALGORITHM STORAGE STRUCTURE.
Logical address Item name Weighted support
0 I1 2
1 I2 3
2 I3 3
3 I4 3
4 I5 4
5 I6 4
6 I7 6
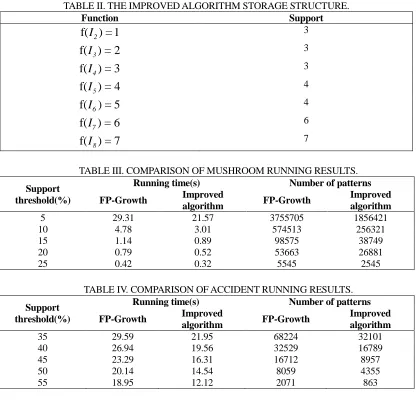
TABLE II. THE IMPROVED ALGORITHM STORAGE STRUCTURE.
Function Support
f( ) = 1I2 3
f( ) = 2I3 3
f( ) = 3I4 3
f( ) = 4I5 4
f( ) = 5I6 4
f( ) = 6I7 6
f( ) = 7I8 7
TABLE III. COMPARISON OF MUSHROOM RUNNING RESULTS.
Support threshold(%)
Running time(s) Number of patterns
FP-Growth Improved
algorithm FP-Growth
Improved algorithm
5 29.31 21.57 3755705 1856421 10 4.78 3.01 574513 256321 15 1.14 0.89 98575 38749 20 0.79 0.52 53663 26881 25 0.42 0.32 5545 2545
TABLE IV. COMPARISON OF ACCIDENT RUNNING RESULTS.
Support threshold(%)
Running time(s) Number of patterns
FP-Growth Improved
algorithm FP-Growth
Improved algorithm
35 29.59 21.95 68224 32101 40 26.94 19.56 32529 16789 45 23.29 16.31 16712 8957 50 20.14 14.54 8059 4355 55 18.95 12.12 2071 863
Algorithm analysis and discussion
The improved algorithm was compared with the traditional algorithm as shown below in order to prove the feasibility of the improved algorithm. Test environment was Intel i5, 2GHz frequency, 2GB memory, Windows 7 operating system. Used C ++ for programming.
The experiment used Accident and Mushroom data sets as test data and tested two algorithms from both the running time and the number of frequent patterns. Table III and Table IV show the algorithm comparison of the running results under different support thresholds.
TABLE V. DATA COMPOSITION OF DIGITAL PROTOTYPE.
The data type Description
process parameters number of bags, bag height, filter bag length, filter bag parameters simulation data velocity field, pressure field, air trajectory
performance index calculated from the simulation document data, evaluate and compare the results of simulation experiments
APPLICATION OF THE IMPROVED FP-GROWTH ALGORITHM IN DIGITAL PROTOTYPE
Digital prototype data analysis
In this paper, the digital prototype data of large-scale environmental protection equipment bag filter are selected as the research object.
The bag filter digital prototype contains three types of data: process parameters, simulation data, performance index, as shown in Table V.
This paper chooses the data of the wind performance of bag filter digital prototype as an example to conduct correlation analysis. The wind performance of bag filter [14] refers to the air volume distribution uniformity. The merits of wind performance directly affect the work and safety of bag filter. When the air volume of each bag room is uneven, the bag room with large air volume would get more ash. So that the frequency of blowing increases, the filter bag is easy to be destroyed. On the contrary, the small air bag room, which cannot fully play a role in the filter bag, would result in waste of resources and affect work efficiency. So, it can be seen that the data analysis of the digital prototype wind performance is significant, and it is necessary to find the potential association rules between the parameters. Usually when the digital prototype simulation is completed, one would have the wind performance index. According to the different values of index, the wind performance level can be divided into several categories: Excellent, general and unqualified according to the previous experience of the research group [15].
In this paper, the data association of the bag filter digital prototype is analyzed. First of all, this paper selected the bag length, bag diameter, bag number, filtration speed, filter bag thickness, net air chamber height as the main research parameters according to the research results. These parameters are preprocessed, and then a subset of the multidimensional attributes are obtained, and the attribute symbols are as follows:
1)Bag length A (1-4): the bag length of 7.35m, 8.35m, 9.35m, 10.35m. 2)Filter bag diameter B (1-3): the bag diameter of 0.16m, 0.18m, 0.2m. 3)Number of bags C(1-3): the number of 6,8,10.
4)Filtration speed D(1-3): Set the filtration speed “1m / min” to "D1" as a separate study object; "D2" means the filtration speed range is (1,1.3) m / min; "D3" is (1.3, 1.6) m / min; "D4" is (1.6, 1.9) m/min.
5)The thickness of the filter bag E(1-4): "E1" means that the thickness is [0.5,1) mm; "E2" means that the thickness is [1,1.5) mm; "E3" is [1.5,2) mm; "E4" is [2,2.5) mm.
7)Level G (1-3): "G1" means that the wind performance index is excellent; "G2" means that the index is general; "G3" is unqualified.
[image:7.612.96.502.133.579.2]As shown in Table VI is a kind of bag filter digital prototype wind performance test database. After data processing, database is as shown in Table VII.
TABLE VI. EXAMPLES OF EXPERIMENTAL DATA.
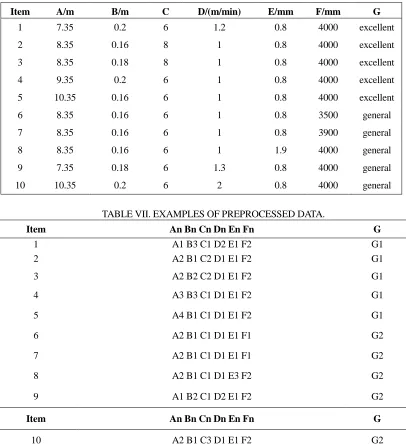
Item A/m B/m C D/(m/min) E/mm F/mm G
1 7.35 0.2 6 1.2 0.8 4000 excellent 2 8.35 0.16 8 1 0.8 4000 excellent 3 8.35 0.18 8 1 0.8 4000 excellent 4 9.35 0.2 6 1 0.8 4000 excellent 5 10.35 0.16 6 1 0.8 4000 excellent 6 8.35 0.16 6 1 0.8 3500 general 7 8.35 0.16 6 1 0.8 3900 general 8 8.35 0.16 6 1 1.9 4000 general 9 7.35 0.18 6 1.3 0.8 4000 general 10 10.35 0.2 6 2 0.8 4000 general
TABLE VII. EXAMPLES OF PREPROCESSED DATA.
Item An Bn Cn Dn En Fn G
1 A1 B3 C1 D2 E1 F2 G1 2 A2 B1 C2 D1 E1 F2 G1 3 A2 B2 C2 D1 E1 F2 G1 4 A3 B3 C1 D1 E1 F2 G1 5 A4 B1 C1 D1 E1 F2 G1 6 A2 B1 C1 D1 E1 F1 G2 7 A2 B1 C1 D1 E1 F1 G2 8 A2 B1 C1 D1 E3 F2 G2 9 A1 B2 C1 D2 E1 F2 G2
Item An Bn Cn Dn En Fn G
10 A2 B1 C3 D1 E1 F2 G2
TABLE VIII. ATTRIBUTE WEIGHTS.
Item Weights
A1, A2, A3, A4 0.5, 0.5, 0.5, 0.65 B1, B2, B3 0.5, 0.5, 0.6
C1, C2, C3 0.5, 0.5, 0.6 D1, D2, D3, D4 0.3, 0.5, 0.5, 0.6
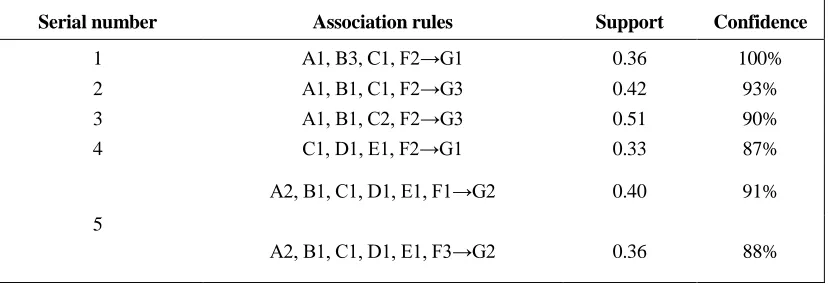
TABLE IX. EXAMPLES OF ASSOCIATION RULES.
Serial number Association rules Support Confidence
1 A1, B3, C1, F2→G1 0.36 100% 2 A1, B1, C1, F2→G3 0.42 93% 3 A1, B1, C2, F2→G3 0.51 90% 4 C1, D1, E1, F2→G1 0.33 87%
5
A2, B1, C1, D1, E1, F1→G2 0.40 91%
A2, B1, C1, D1, E1, F3→G2 0.36 88%
Experimental result analysis
The association rule mining based on the improved FP-Growth algorithm is carried out for the digital prototype wind performance database of the bag filter shown in Table VII. Set the weight support threshold to 30% and the confidence threshold to 80%. According to the number of sub-distribution of each dimension attribute and the importance of attribute in the sample database, the weights of dimension attributes are assigned as shown in Table VIII below. Run the improved FP-Growth algorithm to get effective association rules, as shown in Table IX for some examples.
1)According to rules 2 and 3 in Table IX: when the filter bag length is 7.35 m, the filter bag diameter is 0.16m, the bag thickness is 0.8mm, and the height of net air chamber is 4000mm, regardless of the bag number 6 or 8, as long as the filtration speed is between 1m/min and 2m/min, the wind performance would be worse and worse until unqualified.
2)According to rule 4:when the filter bag length is between 7.35m-10.35m, the diameter is 0.16m-0.2m, the bag number is 6, the thickness of filter bag is 0.8mm, the net chamber height is 4000mm, and when the filtration velocity is in the range of 1m/min-2m/min, only in the 1m/min, the wind performance would be perfect.
3)According to rule 5: when the bag length is 8.35m, diameter is 0.16m, the bag number is 6, the filtration speed is 1m/min, if the filter thickness is between 0.5mm to 1mm range, the net chamber height is between 3500mm to 4500mm range, except for 4000mm, the wind performance would be general.
At the same time, in order to prove the superiority of the improved FP-Growth algorithm, the FP-Growth algorithm was tested under the same conditions. The running time and the number of effective association rules are compared as shown in Table X below.
[image:8.612.90.505.671.721.2]The comparison results show that the improved FP-Growth algorithm is superior to the traditional Growth algorithm in running efficiency. And the improved FP-Growth algorithm generates fewer efficient rules than the traditional FP-FP-Growth algorithm, and reduces the false redundant output. Thus, the improved FP-Growth algorithm has certain advantages compared with the original algorithm in efficiency and accuracy.
TABLE X. COMPARISON OF RUNNING RESULTS.
Algorithm FP-Growth Improved algorithm
CONCLUSION
Based on the traditional FP-growth algorithm, this paper proposes an improved FP-Growth algorithm. The difference between the improved algorithm and the traditional algorithm is that:
1) The weights of attributes are introduced to avoid the redundant information generated by the uneven distribution of attributes in the database, so as to ensure the validity of the generation rules.
2) The hash function is constructed to realize the mapping between attributes and their weighted support. It is used to reduce the number of traversal frequent items and improve the efficiency of algorithm execution.
3) Multidimensional attribute block is to respectively construct FP-tree, generate frequent item subsets and merge them, so as to improve the efficiency of the structure of the tree.
Next, taking the digital prototype of bag filter as an example, the improved FP-Growth algorithm is used for data mining. And the characteristic relationship between the wind performance and the combinations of parameters is obtained. Under the same conditions, the traditional FP-Growth algorithm is used to compare experiments, which proves the superiority of the improved algorithm. However, since the sample data is limited, it is necessary to further apply and test the engineering practicability of the method from a large sample point of view. At the same time, when facing a huge database of digital prototype, the weight measurement is still insufficient. How to fast and reasonably consider the weight of each attribute is worthy of further study.
REFERENCES
1. Tan Jianrong, Liu Zhenyu. Digital protector key technology and product application [M]. Beijing: China Machine Press, 2007: 69-71.
2. Lin Shuainan, Zhang Xiaodong, Wang Pingyang, etc. Application of Digital Prototyping Technology in Design and Development of Electromagnetic Valves[J]. Mechanical Science and Technology for Aerospace Engineering, 2014, 01:104-108.
3. Agraeal R, Imielinski T, Swami A. Mining association rules between sets of items in large databases [J]. Proceedings of the ACM SIGMOD Conference on Management of Data, 1993(12): 207-216.
4. Han J, Kambr M. Data mining concepts and techniques [M]. San Francisco: Morgan Kaufmann Publishers, 2000.
5. Yan Hongwen, Xie Qilong. Research on Identifying Vulnerability of Power Grid Based on Multidimensional Association Rules [J]. Computer Applications and Software, 2015, 32(11):36-40. 6. Jia Meng, Shao Quan, Zhang Jinshi. Association Analysis of Civil Aviation Bird Strike Event
Based on FP-Growth Algorithm [J]. Journal of Safety and Environment, 2016, 16 (1): 110-113. 7. Wang Yanhui, Wang Shujun, Li Man, et al. Research on Correlation Failure Models of CRHX
EMU Traction System Based on the Improved FP--Growth Algorithm[J]. Journal of the China Railway Society, 2016, 38(9): 72-80.
8. Li Hongguang, Xia Lijun. Improved FP-growth Algorithm With Applications in TE Process Fault Diagnosis[J]. Journal of Beijing University of Technology, 2016, 42(5): 697-706.
9. Tohidi H, Ibrahim H. A frequent pattern mining algorithm based on FP-growth without generating tree [J]. Proceedings of Knowledge Management 5th International Conference, 2010(34) :723-728. 10. Li Yebai, Tang Hui, Zhang Chun, et al. Frequent Pattern Mining Algorithm Based on Improved
FP-tree[J]. Journal of Computer Applications, 2011, 31(1): 101-105.
12. Totad S G, Geeta R B, Reddy, et al. Batch incremental processing for FP-tree construction using FP-growth algorithm [J]. Knowledge and Information Systems, 2012, 33( 2):475-490.
13. Sun H, Zhang H X, Chen S P, et al. The study of improved FP-growth algorithm in map reduce [J]. Advances in Intelligent Systems Research, 2013, 52(6):250-253.
14. Kang Xuejuan. Digital Prototype of Bag Filter with Data Mining Technology and Application Research [D]. Hebei University of Technology, 2015.