2017 2nd International Conference on Artificial Intelligence: Techniques and Applications (AITA 2017) ISBN: 978-1-60595-491-2
Fine-grained Opinion Extraction with Mixed Network Model
Pan ZHANG, Hong-rong CHENG
*, Teng-yuan CAI
and Qi-he LIU
School of Information and Software Engineering, University of Electronic Science and Technology of China, Chengdu 610054, P.R. China
*Corresponding author
Keywords: Opinion mining, Entity extraction, Network model.
Abstract. With the development of opinion mining, the relevant areas are being valued more than before. As the foundation of opinion mining, the performance of opinion extraction is significant for the opinion mining results.
Among the present methods of opinion extraction, many of them take advantages of the relation features. Unlike other models which use relations in an independent way, in this paper we propose a mixed network model which interactively uses two relations as well as other lexical and syntactic features to solve the extraction problem. A series of experiments show that our model outperforms other baseline models and has a further potential of improvement.
Introduction
The extraction task is fundamental for opinion mining, also called sentiment analysis. The trend of opinion extraction is generally from coarse-grained document-level to sentence-level, and then to fine-grained entity-level. Standard machine learning methods like SVM are used in [1,2] to analyze reviews on a document-level analysis. The researches such as [3,4] study about the subjectivity feature on sentence-level analysis. And in [5,6] bring up the joint model to solve extraction task on entity-level.
The critical task in entity-level is to extract entities from a whole sentence. Rule-based methods once were the main approaches for opinion extracting [8]. Recently there has been a growing interest in the statistical-based methods and statistical-rule-mixed methods. In these methods, the opinion relations between entities are proven to be a kind of valuable feature for extraction [6]. In this paper, we adopt the ways of Y&C [5] to define two kinds of relations. Here is an example from MPQA corpus [9]:
Sally (holder) is satisfied (opinion) with her new camera (target).
In the above example, the opinion, the target of the opinion and the holder of the opinion annotated by subscripts are the three categories of entities. The two kinds of relations are IS-ABOUT and IS-FROM, the former one indicates that an opinion is about a target, the latter one indicates that an opinion is from a holder.
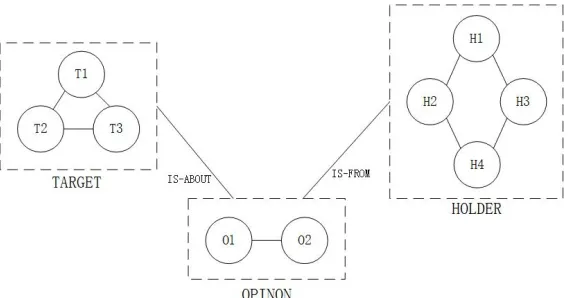
In this paper, we use relations between entities to create a mixed network model as Figure1 shown, it combines several features to extract opinion entities, with a preliminary input from a CRFs sequence labeling process. In Figure1, the vertexes such as T1 to T3 are words in sentences. Each cluster circled by dotted line indicates an opinion expression, which can contain one or more words. The edges between clusters are either the IS-FROM or IS-ABOUT opinion relations, edges within clusters indicate that the words can form an entity. Since the model uses the two relations interactively, we call it relation based mutual extraction model (RMEM).
Figure 1. Relation based mutual extraction model.
Related Work
If the entities can be identified accurately, it could provide much valuable information for the follow-up analysis. For instance, the detection of opinions and their corresponding targets of one product is of much value to reflect the views of customers in different aspects of product.
There are many previous researches devoted to extract entities in sentences. In Liu and Xu [11], a network model is brought up to extract entities of the product reviews. In [12], a small graph is used for locating the verb expressions. In [5], Y&C proposed the first joint inference model in which a sequence labeling method was used to extract entities roughly, then relation features are added, and an ILP formulation was used to jointly evaluate whether an entity should be extracted. The [13] proposed a MLN model to tackle the extraction problem. Their idea are similar to Y&C, but they used MLN model instead of the ILP one. The RMEM we proposed has the same input as [5,13], which is the preliminary extraction result of the CRFs, but we our model connects two kinds of relations which can provide more information.
Proposed Model
In this section we propose our model RMEM. The RMEM mainly comprises two parts:
Preliminary extraction
We adopt Conditional Markov Fields (CRFs) to preliminary extraction task, it is seen as a sequence labeling problem. We extract entities with traditional lexical and sematic features like POS tags and subjectivity. The sentences are formed by words with order, thus making them sequences. In a conditional probability model P
(
y|x)
, Y =(
y1,y2,…,yn)
is the sequence of labels,X =(x1,x2,…,xn) is the sequence of input, each x is a word. In the learning stage, giventraining data, the conditional probability model P
(
y|x)
is obtained by maximum likelihood estimation. In the predicting stage, given input X , the model would give the output y with
maxP
(
y|x)
.The conditional probability can be computed through the forward-backward algorithm.
Mixed network model
to opinion-target pairs and opinion-holder pairs. These two kinds of pairs become candidates respectively corresponding to IS-ABOUT and IS-FROM relations. The pairs that match human annotation are regarded as positive examples.
The network is regarded as a graph G =
(
V ,E)
, to quantify whether a word span should be extract as an entity, the words are given scores, the higher the score, the more likely the word span is an entity. In the network model, the words within an entity have different initial scores from words outside entity. Our purpose is to let the entities find each other through their relations, the practice is to make a random walk on the graph, which means to let one category of entities to decide the score of the other category. The training data we generate from the MPQA corpus are organized in opinion-holder pairs and opinion-target pairs. The opinion entities are connected both with holders and targets, thus they are co-decided by both targets and holders. We propose the following iterative formulas to update the scores of the vertexes:Sholder = µ1 × Wh × Sopinion +(1 − µ1) × Sholder. (1)
Starget = µ2 × Wt × Sopinion +(1 − µ2) × Starget (2)
Sopinion = µ3 × Wh × Sholder+ µ4 × Wt × Starget+(1 − µ3 − µ4) × Starget. (3)
The formulas show the entities cross decide each other’s value, the µ is a parameter to adjust how much influence one entity would have on the other, W is the weight matrix that record the relations between them, there are IS-FROM (Wh) and IS-ABOUT (Wt) matrix. The overall process are shown as Table 1.
Table 1. Mixed Network Model.
Input:
The preliminary extracted entities from CRFs
IS-ABOUT and IS-FROM relations (can be extracted through different methods) Output:
The entities (a group of words/vertexes) Procedure:
1: Create network model, each vertex is assigned with an initial value
2: Update the value of each vertex with our proposed iterative formula Eq.1,2,3. 3: After run a certain number of iterations, stop updating.
4: Extract the groups of vertexes whose values are higher than the threshold as entities
Experiment
Dataset and Evaluation Metrics
We implement our experiment on the version 3.0 MPQA dataset. This corpus consists of news documents in several different topics. The annotation we use in this paper are those ones that denote opinion expressions and relations between them. The three kinds of annotations that denote holder, opinion, and target are “agent”, “direct-subjective”, and “sTarget”, the IS-FROM and IS-ABOUT relations are generated form “attitude” and “targetFrame”.
The evaluation metrics we use for both entity extraction and relation extraction is the PRF (precision, recall, f-measure) evaluation system. Since an expression could contain more than one word, the border of word spans are hard to define, so we adopt the overlap criteria, which means that if a span overlaps with a gold standard then it is considered to be correct.
researches which have similarity to our work, thus they are suitable for comparison. We assemble the two relation extraction methods to mixed network model as our baselines.
CRFs: To preliminarily extract entities, we discard some badly annotated sentences, and organize the rest into a format that the words are separately put in lines, each word line contains the word itself, its POS tag, the subjectivity of this word (obtained from the WordNet Subjectivity Lexicon) and the label of this span. The labels are represented in the “IOB” format, which is a common tagging format used by many researches. To implement CRFs model, we use CRF++. We create a customized template file to make each word connect to their features and the adjacent words. Only one neighbor front and back of the current word is considered in this template. The hyper-parameter c is set to 2.25 after running a 10-fold cross validation. All the other parameters are set to default.
Adj method in [5]: The main practice of this method is to assume the adjacent entities are more likely to have relations (adjacency rule). We iterate the documents and match entities to their neighbors, the opinion-target pairs and opinion-holder pairs we get are results of relation extraction.
[image:4.612.126.483.328.384.2]Relation Extraction Method in [13]: The main practice of this method is to adopt both lexical features and dependency path to train the relation classifier. We generate the dependency path and distance (the words’ number between two different spans) from the document using Stanford coreNLP [14]. Because we chose a different corpus from [13], our classifier is trained by LIBSVM [15] instead of LIBLINEAR in [13] to fit the corpus’s size.
Table 2. Relation Extraction.
IS-ABOUT IS-FROM
P R F P R F
Adj method in [5] 31.3 23.0 26.5 33.8 15.2 21.0 Relation Extraction Method in [13] 86.4 78.0 81.9 62.5 70.0 66.0
To further extract entities with our mixed network model, the CRFs result is used as input. A relation weight matrix is used to represent the relations between entities. Since the extraction of two different relations are separated, so in the Eq.4Wh and Wt cannot be merged together. We load the different relation extraction results to our network model separately to get entity extraction results. Then we compare their performances:
Table 3. Entity Extraction.
Opinion Target Holder
P R F P R F P R F
CRFs 41.2 63.5 50.0 16.8 55.4 25.8 56.2 82.0 66.7 Network Model + Adj method in [5] 63.3 36.4 42.3 17.2 47.3 25.2 57.3 83.6 68.0 Network Model + Relation Extraction Method in [13] 62.6 67.1 64.8 13.7 62.1 22.4 66.0 93.1 77.3 Network Model + Gold Standard 77.8 38.4 51.4 72.0 34.0 46.2 87.8 70.5 78.9
Results
Table 2 and Table 3 separately show the results of the two relation extraction methods and the entity extraction results. The entity extraction results are consists of preliminary extraction and network model extraction results with different relations features.
When we look at Table 2, the difference in data shows that relation extraction method in [13] has a much better performance than Adj method. It is reasonable because the former one adopt dependency path features. And we can see that the IS-ABOUT relation is more difficult to extract than the IS-FROM relation, one possible reason is that a target can be expressed in many more ways than a holder.
relation can lead to a better entity extraction result. The best result of target and holder are extracted by network model with gold standard relations. The increase in number indicates that a practical way to raise the performance of our network model would be to apply more accurate relations.
Conclusions
In this paper, we propose a relation based mutual extraction model (RMEM) to extract opinion-related entities. The extraction is divided into two parts. The preliminary extraction by CRFs and the further extraction by network model. From experiments we know our model can effectively utilize the information carried by the lexical features as well as opinion relation features. Our model can achieve better performance than the methods that only adopt sequence labeling or relation classifying methods. For further work, we plan to explore and search for more accurate features that can indicate the entities, and to load these features to our model to reach a better result.
References
[1]Pang B, Lee L, Vaithyanathan S. Thumbs up?: sentiment classification using machine learning techniques[J]. Proceedings of Emnlp, 2002:79–86.
[2]Turney P D. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews[J]. Proceedings of Annual Meeting of the Association for Computational Linguistics, 2002:417–424.
[3]Hatzivassiloglou V, Wiebe J M. Effects of adjective orientation and gradability on sentence subjectivity[C] Conference on Computational Linguistics. Association for Computational Linguistics, 2003:299–305.
[4] Ji G, Liu K, He S, et al. Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions[C]//AAAI. 2017.
[5]Yang B, Cardie C. Joint Inference for Fine-grained Opinion Extraction[C]//Meeting of the Association for Computational Linguistics. 2013:1640-1649.
[6]Zheng S, Hao Y, Lu D, et al. Joint Entity and Relation Extraction Based on A Hybrid Neural Network[J]. Neurocomputing, 2017.
[7]Santaholma M. Grammar Sharing Techniques for Rule-Based Multilingual NLP Systems[C]// 2007.
[8]Katiyar A, Cardie C. Investigating LSTMs for Joint Extraction of Opinion Entities and Relations[C]//Meeting of the Association for Computational Linguistics. 2016:919-929.
[9]Deng L, Wiebe J. MPQA 3.0: An Entity/Event-Level Sentiment Corpus[C]//Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2015:13231328.
[10]Zirn C, Niepert M, Stuckenschmidt H, et al. Fine-Grained Sentiment Analysis with Structural Features[J]. 2011.
[11]Liu K, Xu L, Zhao J. Extracting Opinion Targets and Opinion Words from Online Reviews with Graph Co-ranking[J]. National Laboratory of Pattern Recognition, 2014:314-324.
[12]Li H, Mukherjee A, Si J, et al. Extracting Verb Expressions Implying Negative Opinions[C]// AAAI. 2015.
[14]Manning C D, Surdeanu M, Bauer J, et al. The Stanford CoreNLP Natural Language Processing Toolkit[C]// Meeting of the Association for Computational Linguistics: System Demonstrations. 2014.