2016 International Conference on Artificial Intelligence: Techniques and Applications (AITA 2016) ISBN: 978-1-60595-389-2
Sentiment Analysis of Tourism Micro-blog Comments
Wan-li SONG
1,2,3and Jun-hua WANG
31
Key Laboratory of Trusted Cloud Computing and Big Data Analysis, School of Information Engineering, Nanjing XiaoZhuang University, Nanjing, China, 211171
2
Nanjing Vocational Institute of Transport Technology, Nanjing, China, 211188 3
College of Computer and Information, Hohai University, Nanjing, China, 210098
Keywords: Micro-blog comment, Web crawler, Words segmentation, Sentiment analysis, TF-IDF.
Abstract. Recent years, an amount of tourism micro-blog comments on the Internet have become an important source of information for potential customers and to improve the service quality. These micro-blog comments do help to research tourism resources or services before making decisions. Thus, sentiment analysis of tourism micro-blog comments has become a hot issue in the field of natural language processing and text mining. We designed a system called SASTMC by using web crawler, Chinese words segmentation, emotion words dictionary and an improved TF-IDF algorithm. It enhances expression ability of sentiment information of text words. Experiments on Sina micro-blog comments datasets demonstrate that our method can do the task well.
Introduction
With the development of the living level and the internet environment, more and more people start touring and writing their comment text on the micro-blog website pages. Interactions between online users are also more frequent. The tourism micro-blog comments contain opinions with different emotional tendency and personal semantic information. Thus, mining these comments has vital benefit for both consumers and businesses. It helps the consumers to choose the right services and products and also helps the businesses to improve their services.
Related Work
At present, the analysis of sentiment tendency mainly includes two kinds of methods which are based on sentiment dictionary and machine learning [1].
The method based on emotion dictionary is to analyze and calculate the sentiment polarity of the text, and get a sentiment polarity value. Turney et al. [2] analyze the emotional tendency by calculating the SO-PMI value of the reference words and the estimated words. Zhu et al. [3] proposed two methods which were based on semantic similarity and semantic correlation field using HowNet. These methods calculated the similarity of the words to be estimated and the benchmark words which are pre-selected separately, then obtained the sentiment tendency of the words. Zhang et al. [4] proposed a method which use of expression images combined with the emotional words to construct Chinese emotion dictionary. This method improves the accuracy of classification by constructing Bayesian Classifier, and using entropy to optimize the corpus.
performance of supervised method is limited. Supervised methods have poor portability. Usually supervised methods need to carry on the training in the other domain using new field training data. Unsupervised methods are generally based on the statistical analysis of the data. These methods calculated the micro-blog sentiment distribution by probability model, and then analysis sentiment. In 2009, Lin et al. [8] proposed an improved model based on LDA (Dirichlet Allocation Latent) model, called JST model. The JST model makes a 4-layer probability model, which gets the sentiment distribution of each topic by obtaining the correspondence between statistical labels and label sentiment theme. In 2013, Ding et al [9]. proposed HDP-LDA (Hierarchical Dirichlet Process-Latent Dirichlet Allocation) model. This model takes advantage of automatically determining the number of theme by the HDP model to mine phrase sentiment tendency. But this method needs to identify phrases of POS tagging, so phrase recognition accuracy will affect the results of the analysis. At the same time this model needs to set a large number of parameters and reduces the portability. Sentiment analysis methods based on topic model achieved more accurate results than the traditional methods. But it is found that training and processing of the topic model is not applicable to large-scale data through a large number of experiments and practice. In this kind of model, it is assumed that the data is subject to exponential distribution, but do not fit to the data in the real environment, especially the data on the Internet, which obeys the long tail distribution [10]. This kind of methods is too much emphasis on the high frequency data from the induction of semantic, ignoring the low frequency data processing, so it is not suitable for the description of the micro-blog text.
Above all the methods, this article apply the sentiment dictionary method to construct the micro-blog sentiment analysis system, and then analyze the sentiment tendency.
Approach
In this section we present an approach for constructing prototype for analyzing the sentiment for tourism micro-blog, which enables the user to conveniently specify analyzing conditions. We first give an overview of the approach and then explicate its algorithms.
Overview of our Approach
The main idea of the analyzing system is that the system creates a interface for the users to browse and lets the users specify analyzing conditions by means of simple form-based operations. After the user completes the specifying of the analyzing conditions, the tool can automatically analyze the sentiment of the text from three kinds of inputs: one is single micro-blog text which is input in the textArea, another one is text file which path is input in the file-textField and the other one is text down loading from web pages which URL is input in the URL-textField. To achieve this, we design the following four algorithms: (1) Data Downloading algorithm (Algorithm 1): It obtains all the data written by the users in the micro-blog website pages with you specified on the interface of our system by crowding the web pages and then saved in the text data file for the user to analyze ( or real-time processing ); (2) Words Segmenting algorithm (Algorithm 2): It prepares the recourses to compute the score of the text and to get the main words that what are the micro-blog talking about; (3) Score Computing algorithm (Algorithm 3): It automatically matches the words to the sentiment words base to get the corresponding scores of the words and add them together to generate the final score of the micro-blog text; (4) Main words Getting algorithm (Algorithm 4): It gets the final words by extending the TF-IDF (term frequency/inverse document frequency) algorithm and get the only one main word by comparing the distance of the word with the biggest score and the one of main words which is nearest to it in one sentence. Last find the word which has the shortest distance.
Algorithm Design
In the following, we detail the processing steps of the four algorithms.
username and password of the micro-blog website. Secondly, the algorithm matches all the pattern of the web page. Finally, the algorithm gets the data we need from all the information of the web page. Actually, the algorithm can get all of that we need.
Algorithm 1. dataDownloading(filename, URL, username, password) Input: filename: The file to save the data.
url: The URI of the comment page.
username: The username to log in the comment page. password: The password to log in the comment page. Output: file: The file stores the comments.
1: get the page according to URL.
2: login in according to username and password.
3: DomNodeList obtain all the DOM elements from the page. 4: for each element in DomNodeList do
5: Cleanse data in this element.
6: Obtain the comments in his element. 7: for each comment do
8: transform the comment into text. 9: write it to file.
10: endfor 11: endfor 12: return file.
Words Segmenting Algorithm (Algorithm 2). The input of Algorithm 2 is the text to be separated to single sentence and segmented to single word which will be used in the next algorithm. The output is the different kinds of segmentation result, words with part of speech or not.
Algorithm 2. wordsSegmenting(text)
Input: sentence: The sentence to be segmented. Output: list:
1: result segment sentence into words with its part of speech. 2: result1 .
3: result2 .
4: for each term in list do 5: add it to result1.
6: if term is not a stop-word then 7: add it to result2.
8; endif 9: endfor
10: add resul, resul1 and result2 to list. 11: return list
Score Computing Algorithm (Algorithm 3). The input of Algorithm 3 are the motion words list and the words segmented by algorithm 2. The output is the list of the score and the sequence of the words ordered by their own sentiment score.
Algorithm 3. scoreComputing(synonyms, keywords) Input: synonyms: thesaurus of synonyms.
keywords: The keywords to be calculated. Output: all: The set of results
1: all .
2: for each keyword in keywords do 3: for each synonym in synonyms do
6: put synonym and 0-its score into ma or mm accordingly. 7: if keyword is double negative then
8: put synonym and its score into ma or mm accordingly. 9: endif
10: else
11: put synonym and its score into ma or mm accordingly. 12: endif
13: endif 14: endfor 14: endfor
15: caculate the average score of the synonyms and put them into emWord. 16: for each keyword do
17: for each word1 in list do
18: num calculate the similarity between word1 and keyword. 19: if num is bigger than 0.1 then
20: if keyword is negative then
21: put synonym and 0-its score into map. 22: if keyword is double negative then 23: put synonym and its score into map. 24: endif
25: else
26: put synonym and its score into map. 27: endif
28: endfor 29: endfor
30: calculate the score of the keywords in map and put it into scores 31: calculate the average score and put it into emWord
32: calculate the sum score sum.
33: calculate the highest score keyword bbb and its score maxNum. 34: put emWord, sum ,bbb and maxNum into all.
35: return all.
Mainwords Getting Algorithm (Algorithm 4). The input of Algorithm 4 are the text of sentences and the index of the words. The output is the list of mainwords.
Algorithm 3. mainwordsGetting(str, wordPoses) Input: str: The plain text to be segmented. WordPoses; lexicon to be compared. Output: list: The result list.
1: dataset FinalWord(str)
2: map obtain list3 from dataSet 3: score obtain totalScore from dataset 4 for each key in map do
5: for each wordPos in wordPoses do 6: if key is equals with wordPos then
7: mul multiply key`s value with wordPos`spinly 8: put key and mul into map
9: endif 10: endfor 11: endfor
Prototype Implementation and Experiment
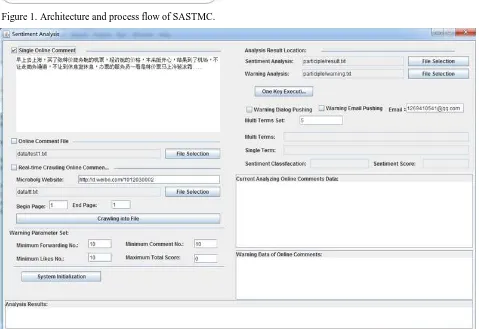
Based on the above approach and the proposed algorithms, we have implemented a prototype, called SASTMC, of the Sentiment Analysis System of Tourism Micro-blog Comments. Prototype architecture and process flow is illustrated in Figure 1.
[image:5.595.56.285.219.322.2]We use SASTMC to conduct experiments to verify the effectiveness of our proposed approach. SASTMC is developed by Java. The interface of SASTMC is shown in Figure 2. The test result is shown in table 1. The implementation indicates that our proposed approach is achievable using Java programming language. The experimental results on the micro-blog comments data set verify the effectiveness of our approach.
Figure 1. Architecture and process flow of SASTMC.
Table 1. A List of test results.
Total No. 238 92 50 338 TP No. 196 77 37 287 FP No. 42 15 13 51 Accuracy 82.4% 83.7% 74.0% 84.9%
Figure 2. Screenshot of user interface of SASTMC.
Summary
[image:5.595.60.539.319.648.2]implementation and experimental results indicate that the proposed approach is achievable using Java language and some information retrieval technologies applied in this paper.
Our future work mainly focuses on enhancing the algorithms to make SASTMC more effectively and exactly, and further verifying the effectiveness of the algorithms by using more real sentiment analysis conditions.
Acknowledgement
This work was partially supported by the following research grants: (1) the Research Foundation of Key Laboratory of Trusted Cloud Computing and Big Data Analysis of Nanjing XiaoZhuang University, (2) No. CXS1509 from the Jiangsu Students' Project for Innovation and Entrepreneurship Training Program, (3) No. JY1508 from the Research Foundation of Nanjing Vocational Institute of Transport Technology.
References
[1] S.C. Zhou, W.T. Qu, The analysis on the Chinese micro-blog emotion, Computer applications and software. 2013, 30(3):162-164.
[2] Turney P D, Littman M L. Measuring praise and criticism: Inference of semantic orientation from association, ACM Transactions on Information Systems. 2003, 21(4):315-346.
[3] Y.L, Zhu, J. Min, Y. Q. Zhou, X.Q. Huang, L.D. Wu, Semantic orientation computing based on HowNet, Journal of Chinese Information Process. 2006(1):140-146.
[4] S. Zhang, L.B. Yu, C.J. Hu, Sentiment analysis of Chinese micro-blog based on emotions and emotional words, Computer Science. 2012, 39(11A):146-148.
[5] B. Liu, L. Zhang, A survey of opinion mining and sentiment analysis. New York: Spring US, 2012: 415-463.
[6] B. L, J.L. Feng, Robust sentiment detection on twitter from biased and noisy data. Proceedings of the 23rd International Conference on Computational Linguistics, Uppsala, Sweden, 2010: 36-44.
[7] L.X. Xie, M. Zhou, M.S. Sun, Hierarchical structure based hybrid approach to sentiment analysis of Chinese micro blog and its feature extraction. Journal of Chinese Information Processing, 2012, 26(1): 73-83.
[8] C.H. Lin, Y.L. He, Joint sentiment topic model for sentiment analysis. Proceedings of the 18th ACM Conference on Information and Knowledge Management Hong Kong, China, 2009: 375-384.
[9] W.Y. Ding, X.L. Song, L.F. Guo, A novel hybrid HDP-LDA model for sentiment analysis. Proceedings of the 2013 IEEE/WIC/ACM International Joint Conference on Web Intelligence (WI) and Intelligent Agent Technology, Atlanta, USA, 2013, 1(1): 329-336.