2017 2nd International Conference on Manufacturing Science and Information Engineering (ICMSIE 2017) ISBN: 978-1-60595-516-2
Collaborative Filtering Algorithm Based
on Weighted Synthesis Method of
Eigenvalues Factors
Yunfei Zi, Yeli Li, Huayan Sun and Xu Han
ABSTRACT
The traditional collaborative filtering algorithm has brought the fundamental change to the present net-business intelligent recommendation, but it is more and more high that the user to the recommendation precision and the personalization request, this algorithm to the user-project non-rational judgment flaw and the sparsity and so on question, seriously affects the recommendation precision and the personalization. Based on these problems, in this paper, a collaborative filtering recommendation algorithm based on factor weighted synthesis is proposed, which calculates the similarity between the user-project's scoring, the dump, the eigenvalues, and so on, and the Matrix is based on the division of the weight vector with the characteristic factor value of the project and the user. Secondly, the recommendation set is obtained by the factor weighted synthesis method, so as to achieve accurate, personalized and highly effective recommendation. The experimental results show that the algorithm can effectively improve the accuracy of similarity calculation to solve the problem of data sparsity and grading, and improve the precision, individuation and execution efficiency of the proposed method.1
INTRODUCTION
The continuous transformation of Internet technology, human society into the era of large data, since the media data, publishing data, social network data, electrical and commercial data, etc. become an important part of people's reality and virtual life. In order to solve the contradiction between the massive data and the
user's latent demand in the big data age, the precision and personalized recommendation system are derived and widely used in the electric business. Personalized Recommender system saves time, space and other cost for users to obtain hidden demand, and it is also the best way to solve information overload. With the increase of the user's dependence on the net purchase and the latent demand is not satisfied, the precision and personalized recommendation system in the electric business industry is also an unprecedented importance. The referral system is a user's rating of the project, enjoy and study the user's preferences, interests to achieve precision, personalized recommendation, among them, collaborative filtering recommendation algorithm for the most widely recommended algorithm, compared to the traditional based on content, utility, knowledge, association Rules of recommendation algorithm, collaborative filtering recommendation algorithm easy to implement, High degree of automation, the ability to deal with complex unstructured objects is widely used in electricity, since the media and so on. At the same time, although the collaborative filtering algorithm in the electrical, the social network personalized recommendation domain obtains the more successful application, but along with the Internet data assumes the exponential growth, the data content complexity unceasingly enhances and so on the question highlighted, also exposes own limitation, the collaborative filtration recommendation algorithm's [1-4] disadvantage has: (1) The problem of sparsity of data. When the recommendation system is confronted with mass information analysis, the user search information is very small, which can easily result in the sparsity of the user-project evaluation matrix. (2) The issue of new goods. For new users and new projects without scoring, the accuracy of the first recommendation is poor. (3) Scalability issues. As users and projects grow in progression, identifying "nearest neighbors" encounters an extensibility bottleneck.
The existing collaborative filtering recommendation algorithm[5-10]mainly through the user's historical behavior, hobbies and so on to achieve personalized recommendations, such as according to User A and B, a high degree of similarity, a to the project iam interested, can be inferred that B may also be interested in project
I, but the recommendation process ignores the project I itself is a number of fuzzy feature factor( , ,..., )x x1 2 xn composition, The weights of many feature factors are
different in the project, which greatly reduces the precision and personalization of the recommendation, and consumes the resources such as time, data and so on. such as user A's interest in the computer, the application of collaborative filtering recommendation algorithm of thought User B may be recommended computer series books, but the computer is a vague concept, it contains hardware, software, and so on, there areN a set of fuzzy feature factors, so maybe user a like is the
rate, but also can't meet the target user's precision and personalized recommendations.
In the user network, the user's demand is divided into the explicit demand and the recessive demand, the explicit demand is refers to the user to have the clear goal demand, the latent demand is refers to the user not to have the explicit goal but may need certain project's demand, in the explicit demand data information insufficient condition, Efficient use of hidden demand data information to achieve more accurate and personalized recommendations for users, this method can reduce the proposed algorithm in the matrix sparsity and the impact of new items, but did not fundamentally solve the user-project characteristics of ambiguity and weight ratio.
Many scholars based on the lack of collaborative filtering recommendation algorithm [11-15], the improvement of different latitude, but have not been completely resolved, in order to solve the traditional recommendation algorithm for user-project precision, personalized recommendation process of the existence of the characteristics of fuzzy factors and weight bias problem, In this paper, a method of collaborative filtering recommendation based on factor weighted synthesis is proposed. Through the user in the system structure, semi-structured and unstructured data record, construct user-project characteristic factor weighting model, calculate the weight and value of user-project core characteristic factor, combine the similarity degree of user-project collaborative filtering recommendation algorithm to find nearest neighbor, finally to the user- The project carries on the comprehensive preliminary award and the final value optimization, thus realizes to the user explicit, the recessive demand high efficiency, the precision, the personalization recommendation. The experimental results show that the proposed algorithm improves the accuracy of the nearest neighbor recommendation, and improves the precision of the personalized recommendation system and optimizes the recommended quality.
TRADITIONAL COLLABORATIVE FILTERING RECOMMENDATION ALGORITHM
Implementation of Collaborative Filtering Recommendation Algorithm
(a) User-project data collection and preprocessing.
(b)Based on the cleaning data to calculate the user-project similarity, select a number of nearest neighbors or the highest degree of similarity N users or projects.
(c)Recommend the user or project with the highest degree of N similarity to the corresponding project or user.
Evaluation And Calculation of Correlation Degree
In the collaborative filtration recommendation system, D( , , )U I R is used to represent the user-project data source, U (User User1, 2,...,Usern) for user set,
U n,I (Item Item1, 2,...,Itemm)for project set, I m, The user's scoring matrix
for the item isR m n, where Rijrepresents the userUserithe projectItemjscore,
[image:4.612.153.443.355.459.2]and the table 1 is the scoring matrix R.
TABLE 1. USER-PROJECT SCORING MATRIX.
USER
ITEM
1
Item Item2 ... Itemm
1
User R11 R12 ... R1m
2,
User R21 R22 ... R2m
... ... ... ...
n
User Rn1 Rn2 ... Rnm
The common methods of computer similarity in collaborative filtering recommendation algorithms are:
(a) Cosine similarity (Cosine similarity): The degree of similarity between computer users by two or more users of the scoring data not less than two products. Set the user's scoring vector with the user's scoring vector, and then the computer two user's cosine of the scoring vector is worth the user-project similarity:
( , ) cos( , ) a b
sim a b a b
a b
(1)
Where:a b represents the internal product of the user A and the user B score
(b) Pearson correlation coefficient (Pearson correlation coefficient): Through the user to the product evaluation data calculates two sets of data and a line's fitting degree, if the two user similarity degree high will form the diagonal. Set the user to
x and y, mx for the user x for all products of the scoring data, mxk for user x to
the k project score data, then the Pearson correlation coefficient formula is:
2 2
( ) ( )
( , ) ( 2 )
( ) ( )
k x k x y k y
k x k x k y k y
m m m m
s i m x y
m m m m
After calculating the similarity, we find the nearest neighbor, Zum is the nearest
neighbor, the calculation of the project s prediction score.
1 1 ( , )( ) ( , ) um um xs x Z u a s u Z a
Å sim u x
Å sim u m m
m m
x
(3)
The above mx is the average score of all the scoring data for x in Zum, and mu
is the mean value of the target user u based on all project scoring data.
1s uw T w s u m Å T m
(4)
s
T is the sum of the items, and muw indicates the value of u for product w.
WEIGHTED SYNTHESIS METHOD OF EIGENVALUES FACTORS
The user, the project information itself has the characteristic factor weight ratio, but the characteristic factor weighting more can the objective, the accurate expression thing itself.
In the actual recommendation process, users and projects are composed of multiple feature attributes, and feature attributes [22-24] do not have a strict, accurate demarcation line, and all of them constitute the fuzzy feature set describing the user-project itself, and each of the fuzzy feature sets is made up of several characteristic factors interacting with each other. And each characteristic factor can be represented by a feature fuzzy set, the user-project domain can be represented as the Descartes product of n factor set, i.e.
1 2 ... n
Set AiUi (i1, 2,..., )n ,Ai is a subset of a user or project feature factor set,
A U ,A is a user-project feature factor set A A1, 2,...,An compound.
Weighted Average Method
Recommend a project to a user based on the user's own interests, and interest preference is the user's occupation, gender, education level, living environment and many other factors decided and affected, and each factor has a number of eigenvalues, and each feature factors determine the project or the user's own proportion of the differences exist, Therefore, the characteristic factors that endow the feature fuzzy concentration can make the recommender system more precise, efficient and personalized than the weight of the user-project.
If user-project A u( ) is aggregated by nfeature set A u1( ),1 A u2( ),...,2 A un( )n ,
then the user-project feature itself is:
1
( ) n i i( )i i
A u A u
(5)
Among them: u( , ,..., )u u1 2 un U user-Project feature set,( , ,..., ) 1 2 n is
characteristic factor in user-project weight vector, and satisfies 1 1 n
i i
, ( 1, 2,..., )
i i n
reflects the importance of the first characteristic factor.
Multiplication Averaging Method
When the recommended user or project feature factor changes proportionally, such as a user's interest in the project feature set A has n feature subsets, where
each feature subset Ai is proportional to the product average method of computing
user-project recommendation candidate accuracy.
If the user-project feature set A u( ) is proportional to the( ( ))A ui i i
, and each feature subset ( )A ui i to the feature factor set A u( ) is necessary, when any ( )A ui i is
zero, the A u( ) are all zeros, then the product average method calculates the eigenvalues factor formula is:
1
( ) ( ( )) i n
i i
i
A u b A u
(6)
1
1 1
( ( )) ...( ( )) n
n n
b A u A u
Where: u( , ,..., )u u1 2 un U User-project feature set, ( , 1 2,...,n) is
characteristic factor in the user-project weight vector, b for the appropriate selected
constants, A u( ) [0,1] to ensure.
Mixed Method
If you decide the user-project feature factor set A u( )'s sub-eigenvalues factor ( )
i i
A u can be divided into two parts, some of the user-project characteristics by
weight ratio accumulation, part by product, then the calculation of user-project characteristics factor is:
1
1 1
( ) ( ( ) ) i ( ( ) ) m (8 )
m k
i i j m j m j
j i
A u b A u A u
Among them: Feature factor set u U , ( , 1 2,...,m), ( , ,..., ) 1 2 k is two
weights vector, and m k n 1, b is positive real number, weight ( , 1 2,...,m),
1 2
( , ,..., ) k through experiment to take point.
Collaborative Filtering Algorithm Based on Eigenvalues Factor Weighted Synthesis Method
According to the preceding article, the first algorithm realizes the target user U1
accurate, personalized implementation process.
First algorithm weighted synthesis method based on eigenvalues factor Input: Data information D( , , )U I R and weight vectors
Output: Generate recommendation set for user U1 egin
B :
1)To preprocess the original characteristic factors of users and projects;
2) Select the user U1 access records of the N items of the characteristic factor
value; 3)Repeat 4)For i1: {n
5) The importance of the eigenvalues of the i is obtained by weighted averaging
and product averaging for selected eigenvalue values; (Formula 5, 6)
6) Take out the most important first n values of each item characteristic factor,
1
1 1
( ) ( ( )) i ( ( )) m
m k
i i j m j m j
j i
A u b A u A u
7)}
8)Produce recommendation set;
End
The collaborative filtering recommendation algorithm based on factor weighted synthesis method by weighting the user-project characteristic factor value, the paper calculates the important degree of the characteristic factor for the user-project to produce the recommended candidate set for the target user or project, thus realizes the accurate and personalized recommendation.
Analysis of Algorithm Complexity
The complexity of the algorithm includes time and space complexity, and it is the benchmark to effectively measure the efficiency of algorithm execution. With the progress of technology, the efficiency of algorithm execution is decreasing with the dependence of data storage space. For the user-project similarity calculation, data storage space only needs to store user-project feature data, interactive data, recommended data, less space; at the same time, the increase in user-projects did not make the storage space grow geometrically, only linear growth And with the rapid development of hardware technology, the storage space is no longer a difficult problem in the computer age, so the design algorithm or measurement algorithm's execution efficiency usually points to the time complexity, the following is the time complexity analysis of this algorithm.
The process of calculating the target user-project and filter K-similarity is the core of the traditional collaborative filtering recommendation algorithm to calculate the time complexity, and combining with the calculation of the similarity between the recommendation set and the target project, the accurate score of N user-project is combined. Therefore, the time complexity of calculating the similarity between the M user-project and the target user-project is O N( M), and N,M order of magnitude, so the time complexity isO N( 2).
The collaborative filtering recommendation algorithm based on factor weighted synthesis method is used to compute the similarity eigenvector ( , ,..., )V V1 2 Vs of the
time complexity is O N( ) due to the consistency of N and M order of magnitude and the S of characteristic factors compared to n and M minima.
EXPERIMENTAL SIMULATION AND ANALYSIS
Experimental Environment
The experimental environment of the performance analysis of the algorithm is supported by the Windows 7 operating system, and the related configuration is Intel Dual-core2.5G processor, programming language Python, 8G memory, 2.60GHz Dual-core CPU, MySQL database.
Data Collection
In order to compare the recommendation precision and efficiency between the collaborative filtering recommendation algorithm based on factor weighted synthesis method and the traditional user-project collaborative filtering recommendation algorithm, the experimental data are based on the MovieLens data
set provided (http: / /www grouplens org. . /)and maintained by the University of
Minnesota project team(GroupLens ). The data includes 945 users of 100,000
scoring data for 1681 movie projects, and a user at least has a scoring record for 25 films, with a rating of $number and a higher value for users. At the same time, the experimental data according to the needs of training set TrainSet and test set TestSetdivision, and there is no intersection.
Data Sparsity
Use the user's rating of the movie to express the degree of affection for the movie. The sparsity of data is:
1 100000 / (945 1681) 0.937049
Indicates that the data sparsity is very high.
Metrics
The absolute error method (MAE) in the statistical precision measurement applied in this paper is one of the most effective methods to measure the quality of recommended results. The smaller the MAE value indicates that the recommended
1 m
i i
i
testset
pred q MAE
item
(9)
Among them: itemtestset indicates the number of items in the project set,
1 2
{ , ,..., }
i N
pred pred pred pred is the evaluation score of the algorithm,
1 2
{ , ,..., }
i N
q q q q is the actual score of the test data.
Experimental Results
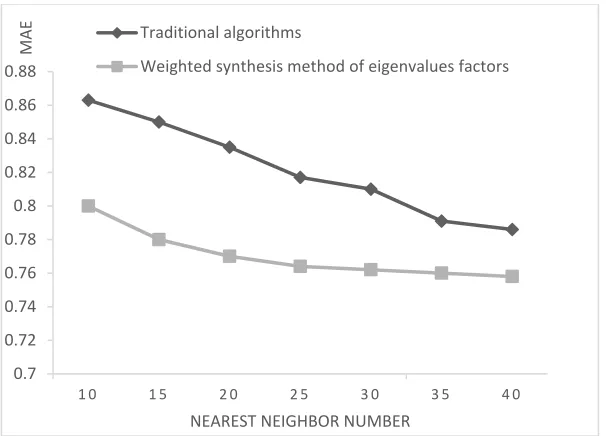
In this paper, the average absolute error value of the collaborative filtering recommendation algorithm based on the MovieLens data set for the traditional
[image:10.612.147.450.372.591.2]collaborative filtering algorithm and factor weighted synthesis method is compared and analyzed, as shown in Fig. 1. The number of recent neighbors will also affect the recommended effect, too little will reduce the recommended accuracy, too much will greatly increase the complexity of the algorithm, in the experiment to select the nearest neighbor of the number of 10~40.
Figure 1. MAE comparison of two algorithms.
Figure 1 shows that the average absolute error value (MAE) shows a downward
trend, whether based on the traditional filtering recommendation algorithm of the user or the project or the collaborative filtering recommendation algorithm based on
0.7 0.72 0.74 0.76 0.78 0.8 0.82 0.84 0.86 0.88
1 0 1 5 2 0 2 5 3 0 3 5 4 0
MAE
NEAREST NEIGHBOR NUMBER Traditional algorithms
the factor weighted synthesis method, but no matter the nearest neighbor number, as long as the nearest neighbor numbers are the same, The average absolute error value ( MAE ) of collaborative filtering recommendation algorithm based on factor
weighted synthesis method is lower than traditional recommendation algorithm, which shows that the proposed algorithm has high precision. Therefore, the collaborative filtering recommendation algorithm based on factor weighted synthesis method has obvious help to improve the precision and efficiency of the recommender system.
CONCLUSIONS
In this paper, the collaborative filtering recommendation algorithm based on the factor weighted synthesis method is used to calculate the importance of each characteristic factor value to the user-project by dividing the weight vector of the user-project characteristic factor value, thus accurately dividing the candidate set and improving the measure of similarity. Because the method of similarity measurement in each recommendation calculation directly affects the accuracy and personalization of the proposed project or user. At the same time, the algorithm can reduce the negative effect of sparsity by calculating the internal and external distance of the project or the user eigenvalue and the weighted calculation feature factor set. The future work is how to extend the recommendation algorithm of factor weighted synthesis and its application to related fields through matrix combined with time series and cloud model, which is the direction of next research.
ACKNOWLEDGMENT
Fund project: National Natural Science Foundation of China(11603004), Beijing Natural Science Foundation (1173010), Beijing science and technology innovation service ability coordinated innovation project (PXM2016_014223_000025)
REFERENCES
1. Hao Huang, Jianqing Huang, Sotirios G. Ziavras, et al. A personalized recommendation algorithm based on Hadoop [C]// Electronics Information and Emergency Communication (ICEIEC), 2015 5th International Conference on. IEEE, 2015.
2. Qin Guangjie, Zhang Ying. Collaborative Filtering Recommendation Algorithm Based on Comprehensive Interest Measure. Computer Engineering, 2009(17).
3. Wei Suyun, Ye Ning. Collaborative filtering recommendation algorithm based on item category and interest. Journal of Nanjing University (Natural Sciences), 2013(2).
5. Adomavicus G, Tuzhilin A. Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-art andPossible Extensions [J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(6): 734-749.
6. Linden G., Smith B., York J. Amazon.com Recommendations: Item-to-item Collaborative Filtering [J]. IEEE Internet Computing, 2003, 7(1): 76-80.
7. Park C., Kim D., Oh J., et al. Improving top-K recommendation with truster and trustee relationship in user trust network [J]. Information Sciences, 2016, 374:100-114.
8. Pan J.C., Zhang X.M., Wang X. Improved Singular Value Decomposition Recommender Algorithm Based on User Reliability [J]. Journal of Chinese Computer System, 2016, 37(10): 2171-2176.
9. Zhang Chaoheng, He Xiaowei, Chen Yongbing. Collaborative filtering recommendation algorithm based on social network information. Computer Technology and Development, 2017(11).
10. Sun Guangfu, Wu Le, Liu Qi. Recommendations Based on Collaborative Filtering by Exploiting Sequential Behaviors. Journal of Software, 2013(3).
11. Fan Ying, Hao Linna, Yi Hua. The Research and application on the algorithm based on maximum expectation and collaborative filtering. Computer Technology and Development, 2017(11).
12. Wang Wei, Wang Hongwei, Meng Yuan. The collaborative filtering recommendation algorithm based on sentiment analysis of online reviews. Systems Engineering—Theory & Practice, 2014(12).
13. Pera M.S., Ng Y.K. Analyzing Book-Related Features to Recommend Books forEmergent Readers [C]. // Proceedings of the 26th ACM Conference on Hypertext & Social Media. ACM, 2015: 221-230.
14. Yang Fan. Research on collaborative filtering recommendation algorithm in e-commerce system. Tianjin: Hebei University of Technology, 2006.
15. Rong Huigui, Huo Shengxu, Hu Chunhua. User similarity-based collaborative filtering recommendation algorithm. Journal on Communications, 2014(2).
16. Li Hao, Zhang Haiying, Zhang Jun. A collaborative filtering recommendation algorithm based on user interest analysis. Microcomputer & Its Applications, 2017(15).
17. Guo Ningning, Wang Baoliang, Hou Yonghong. Collaborative Filtering Recommendation Algorithm Based on Characteristics of Social Network. Journal of Frontiers of Computer Science and Technology, 2017.
18. Qinghua Zhang, Kai Xu, Guoyin Wang.Fuzzy equivalence relation and its multigranulation spaces [J]. Information Sciences, 2016.
19. Liang Hu, Wenbo Wang, Feng Wang, et al. The Design and Implementation of Composite Collaborative Filtering Algorithm for Personalized Recommendation [J]. Journal of Software, 2012: 2040-2045.
20. Hai Yang. Improved Collaborative Filtering Recommendation Algorithm Based on Weighted Association Rules [J]. Applied Mechanics and Materials, 2013: 94-97.
21. Feng Ming Liu, Hai Xia Li, Peng Dong. A Collaborative Filtering Recommendation Algorithm Combined with User and Item [J]. Applied Mechanics and Materials, 2014: 1878-1881.
22. Cacheda F., Carneiro V., Fernández D., et al. Comparison of collaborative filtering algorithms: limitations of current techniques and proposals for scalable, high-performance recommender systems [J]. ACM Trans on the Web,2011, 5(1): 1-33.
23. Luo Xin, Zhou Mengchu, Xia Yunni, et al. An efficient non-negative matrix-factorization-based approach to collaborative filtering for recommender systems [J]. IEEE Trans on Industrial Informatics, 2014, 10(2): 1273-1284.