International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)277
Evaluation of Text Detection and Localization Methods in
Natural Images
M. Swamy Das
1, B. Hima Bindhu
2, A. Govardhan
31 Department of Computer Science and Technology, CBIT, Hyderabad ,INDIA 2 Department of Computer Science and Technology, CBIT, Hyderabad ,INDIA
3 School of Information and Technology, JNTU, Hyderabad ,INDIA
Abstract — Over the past years many algorithms have been proposed addressing the challenges in automated systems to detect and localize the text information present in natural images. Applications like Keyword based image search, Text based image indexing, Tourist guide and Image text translation systems are dependent on this automated systems. The purpose of this paper is to compare the three basic methods for text extraction in natural images: edge-based,
connected-component based and texture-based. The
algorithms are implemented and applied to an image set with different text size, font styles and text language. Performance is evaluated based on the precision rate and recall rate for each method on the same image set.
Keywords—Connected Component, Edge based, Localization, Text Detection, Texture based.
I. INTRODUCTION
Recent studies in the field of research on the content retrieval from images and videos identified a wide variety of applications that require automated systems for text extraction. One such recently developed application is the mobile banking application provided by the banking institutions that facilitates the customers to carry out the transactions even on passing the image of the cheque to the server. All other such applications include Tourist guide which facilitate the tourists to understand the display boards though they are unfamiliar with the local language of that place and Image text translation systems to help the visually impaired people and also tourists. Every such application relies on a Textual Information Extraction (TIE) system which can efficiently detect, localize and
extract the text information present in the natural images. The Fig.1 shows the phases of a text extraction system,
[image:1.612.325.544.258.424.2]any text extraction system has mainly two phases. The first phase is to detect and localize the text present in the image. And the second phase is the Recognition stage where the detected text regions are given to OCR which recognizes the characters and gives the textual output.
Figure 1: Text Extraction System
The first phase of a TIE system which is preprocessing of the image to detect and localize the text present in images with properties such as different orientations, contrast, alignments, font styles, color, resolution, size and the text languages against a complex background .The second phase is the Recognition phase which is post processing of the image uses the current OCR techniques handling only the text against a monochrome background hence the detection and localization of text from the images with complex background is a challenging task. Research on text detection and localization is carried out since 1990s and numerous text detection algorithms have been proposed .All these approaches are majorly classified into three categories edge-based, connected-component based and texture based techniques. This paper describes the three techniques and implements them to compare by evaluating the performance.
The rest of the paper is organized as follows: The detailed survey related to the various methods of text extraction in natural scenes is described in section 2, Approach for the implementation of three techniques is presented in section 3, Experimental results of performance analysis is presented in section 4, Section 5 concludes the work and presents the future recommendations.
Text Detection and Localization
Recognition (OCR) Input image
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)278
II. RELATED WORK
Several papers have been reported in the literature and numerous algorithms are proposed for text extraction in natural images and videos. All these algorithms are proposed considering the different properties of text that helps to distinguish the text regions from the other regions in the natural scenes.
A focus of attention based system for text region localization has been proposed by Liuand Samarabandu in [10]. The intensity profiles and spatial variance is used to detect text regions in images. A Gaussian pyramid is created with the original image at different resolutions or scales. The text regions are detected in the highest resolution image and then in each successive lower resolution image in the pyramid.
The approach used in [11, 12] utilizes a support vector machine (SVM) classifier to segment text from non-text in an image or video frame. Initially text is detected in multi scale images using edge based techniques, morphological operations and projection profiles of the image [12].These detected text regions are then verified using wavelet features and SVM. The algorithm is robust with respect to variance in color and size of font as well as language. The existing techniques are categorized into edge based detection, connected component based detection and texture based detection.
A. Edge based detection method
Edge based method focus on high contrast between the background and text and the edges of the text boundary are identified and merged. Later several heuristics are required to filter out the non - text regions.
B. Connected-component based detection method
Connected component based methods use bottom up approach to group smaller components into larger components until all regions are identified in the image. A geometrical analysis is later needed to identify text components and group them to localize text regions.
C. Texture based method
Texture based method is a feature based algorithm which involves the construction of gray-level co-occurrence matrix [7]. This matrix is used to calculate the features like contrast, homogeneity, dissimilarity and which are the results for feature extraction in texture based method.
III. APPROACH
The major goal of this paper is to implement, test, and compare the three approaches for text region extraction in natural images, and to evaluate performance of these algorithms. The algorithms are from Liu and Samarabandu in [2, 3] and Gllavata, Ewerth and Freisleben in [4] S. A. Angadi and M. M. Kodabagi in [1]. The comparison is based on the accuracy of the results obtained, and precision and recall rates. The technique used in [2, 3] is an edge-based text extraction approach, Technique used in [4] is a connected-component based approach, And the technique used in [1] is an texture-based text extraction approach.
A. Algorithm for edge based text region extraction [2,3]
The basic steps of the edge-based text extraction algorithm are given below
1. Create a Gaussian pyramid by successively
filtering the input image with Gaussian kernel
2. Down sample the image in each direction by half.
3. Convolve the resultant image with directional
filter at different orientation kernels for edge detection.
4. Create a feature map associating a weight factor
with each pixel to classify it as candidate or not for text region
5. Carryout the dilation operation to enhance the text
regions by eliminating non text regions
6. Perform area based filtering to eliminate noise
blobs present in the image.
7. Create final output image with text in white pixels
against a plain black background.
B. Algorithm for Connected Component based text region extraction [4]
The basic steps of the connected-component text extraction algorithm are given below
1. Convert the input image to YUV color space
(luminance+chrominanace), use only
luminance(Y) channel for further processing.
2. Convert the image into gray scale using only Y
channel
3. Compute the edge image for Y channel gray
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)279
4. Sharpen the edge image by convolving it with
sharpen filter.
5. Compute horizontal and vertical projection files
considering the sharpened edge image as the input intensity image.
6. Segment the candidate text regions based on
adaptive threshold values calculated for vertical and horizontal projections.
7. Perform gap filling to eliminate possible non-text
regions.
C. Algorithm for texture based text region extraction [1]
The texture based procedure given in [1] consists of five
phases: (1)Background suppression in DCT
domain,(2)Text feature extraction ,(3)Texture
classification,(4)Merging ,(5)Refinement. The basic steps of the texture based text extraction algorithm are given below.
1. Divide the input image into 8x8 blocks and apply
DCT for each block
2. Suppress the background of image using high pass
filter
3. Perform inverse DCT on each block to obtain
processed image
4. Divide the processed image into 50X50 blocks
5. Calculate the features homogeneity and contrast at
00, 450, 900, 1350 orientations for each block
using gray-level co-occurrence matrix.
6. Filter the non-text blocks using text features and
discriminant functions.
7. Merge the obtained text blocks into text regions
8. Refine the size of the detected text regions to
cover the missed text present in undetected blocks and unprocessed regions.
IV. RESULTS AND ANALYSIS
The experimentation of the three detection algorithms was carried out on a dataset containing 30 different images. The sample list for the test images and results obtained are shown in the Figure 2. The performance of each algorithm has been evaluated based on its precision rate, average recall rate and average run time obtained. The precision and recall rates are calculated as
Precision Rate=
Recall Rate=
False positives are the non-text regions in the image and have been detected by the algorithm as text regions. False negatives are the text regions in the image and have not been detected by the algorithm.
Both precision and recall rates are useful as measures to determine the accuracy of each algorithm in eliminating the non-text regions and locating the correct text regions.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)280
Figure 2: Result Images of Three detection Methods Serial
number a)Original image b)Result of Edge based approach c) Result of connected component based approach
d)Result of Texture based approach
1
ResultR
es
ul
t
2
ResultRe
su
lt
3
Re
su
lt Resu
lt
4
Result Result5
Result Result
6
Result Result
[image:4.612.104.569.138.687.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)281
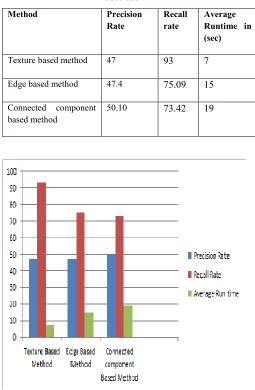
TABLE I
COMPARISION OF THE THREE METHODS ON THE COMMON TEST SET
Method Precision
Rate
Recall rate
Average Runtime in (sec)
Texture based method 47 93 7
Edge based method 47.4 75.09 15
Connected component based method
[image:5.612.46.301.172.562.2]50.10 73.42 19
Figure 3: Performance Measure of three Methods
The graph in Figure 3 shows that the average precision rate obtained by the connected component (50.10%), The edge based algorithm (47.4%) and Texture based algorithm (47) are very close to each other. The average recall rates obtained by the texture based algorithm (93%)is higher than those obtained by the connected component algorithm (74.32%) and edge based algorithm (75.09).
The average run time of Texture based method(7 sec ) is very fast in giving results compared to edge based method(15 sec) and texture based method(19 sec).
V. CONCLUSIONS AND FUTURE SCOPE
The Texture based method detects text regions with an overall Precision (47 %) Recall (93 %) and average run time (7 sec). Thus it is more efficient compared to that of the performance obtained with edge based method and connected component based method. We observed that none of the methods, texture based, connected component based and Edge detection based methods are not good enough to detect the text regions. In order t to reduce the false positives, we can apply edge detection based method in the detected regions.
Each of the algorithms is by itself quite robust in extracting text regions from natural images. These algorithms can be combined to produce more efficient outputs. Both the approaches edge based as well as connected component based algorithm does not take into consideration the removal or noise or unwanted clutter from the test images before or after the computations. A morphological cleaning operation can be employed which helps in reducing the number of false positives obtained and achieving a higher precision rate.
REFERENCES
[1] Angadi, S.A. and Kodabagi, M.M, Text region extraction from low resolution natural scene images using texture features, 2ndInternational Advance Computing Conference , IEEE,2010. [2] Xiaoqing Liu and Jagath Samarabandu, An Edge-based text region
extraction algorithm for Indoor mobile robot navigation, Proceedings of the IEEE, July 2005.
[3] Xiaoqing Liu and Jagath Samarabandu, Multiscale edge-based Text extraction from Complex images, IEEE, 2006.
[4] Julinda Gllavata, Ralph Ewerth and Bernd Freisleben, A Robust algorithm for Text Detection in images, Proceedings of the 3rd international symposium on Image and Signal Processing and Analysis, 2003.
[5] Anoual, H. and Aboutajdine, D. and Elfkihi, S. and Jilbab, A, Features extraction for text detection and localization, I/V Communications and Mobile Network (ISVC)
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)282
[7] Partio, M. and Cramariuc, B.and Gabbouj, M. and Visa, A, Rock texture retrieval using gray level co-occurrence matrix, Proc. of 5th Nordic Signal Processing Symposium
[8] Shehzad Muhammad Hanif and Lionel Prevost, Texture based Text Detection in Natural Scene Image: A help to blind and visually impaired persons, Conference & Workshop on Assistive Technologies for People with Vision & Hearing Impairments Assistive Technology for All Ages CVHI 2007, M.A. Hersh (ed.) [9] C.P. Sumanthi, T. Santhanam and N.Priya, Techniques and
Challenges of automatic Text Extraction in Complex Images: A Survey,Journal of Theoretical and Applied Information Technology, january 2012
[10]Xiaoqing Liu and Jagath Samarabandu, A Simple and Fast Text Localization Algorithm for Indoor Mobile Robot Navigation, Proceedings of SPIE-IS&T Electronic Imaging, SPIE Vol. 5672, 2005.
[11]Qixiang Ye, Qingming Huang, Wen Gao and Debin Zhao, Fast and Robust text detection in images and video frames, Image and Vision Computing 23, 2005.
[12]Qixiang Ye, Wen Gao, Weiqiang Wang and Wei Zeng, A Robust Text Detection Algorithm in Images and Video Frames, IEEE, 2003. [13]Y. Zhong, K. Karu, and A.K. Jain, Locating Text in Complex Color Images, Pattern Recognition, vol. 28, no. 10, pp. 1,523-1,536, Oct. 1995.
[14]V. Wu, R. Manmatha, and E.M. Riseman, An Automatic System to Detect and Recognize Text in Images, Technical Report 99-40, Computer Science Dept., Univ. of Massachusetts, Amherst, 1999 [15]V. Wu, R. Manmatha, and E.M. Riseman, Finding Text In Images,