Software Infrastructure for Natural Language Processing
Full text
Figure
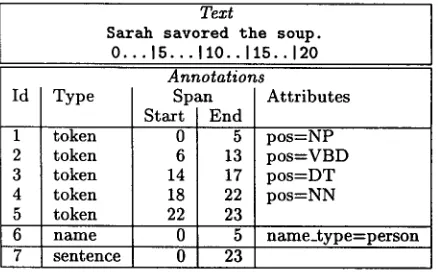
Related documents
The purpose of this study was to report the effects of match related fatigue on the physical performance of professional rugby union players in different position
Specifically, we want to establish how often 1/2 and 2/3 shares and rent contracts would be chosen by landlords facing realistic levels of output variance and skewness, assuming
As stated above, Cb Cel9A/Cel48A is the major biomass active enzyme present in the exo- proteome; when combined with either Cb Cel9B/Man5A or Cb Xyn10A/Cel48B we observe
More specifically, we tested an attribution question hypothesis (stating that the use of consensus and distinctiveness depends on whose causal role people assess), an
♦ Fall 2002-2003: College of Arts and Sciences Student Retention Committee, ULM ♦ Fall 2002-2003: Chair, Department of Biology Undergraduate Curriculum.
More information about the Child Count Application, including instructions for importing and exporting your student data, is in the December 1, 2013 Special Education Child
In ’n latere voordrag voor die Algemene Vergadering van hierdie Kommissie, het hy ([1989] 2000h:241–244) aangevoer dat die Wêreldraad van Kerke op die regte pad is om eenheid
