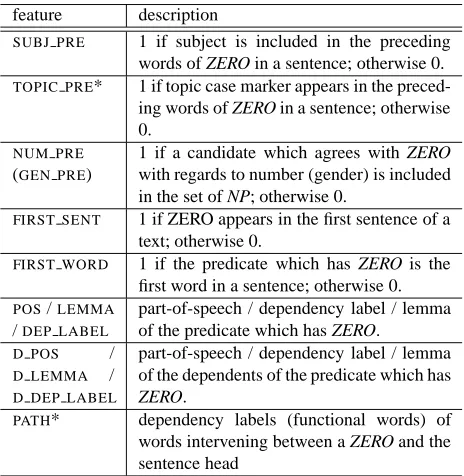
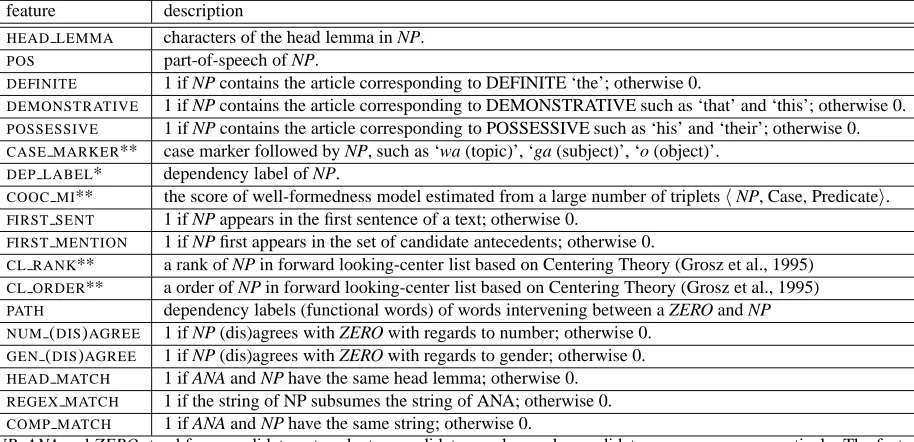
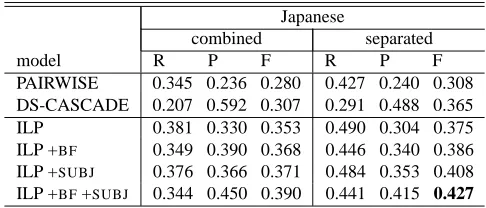
A Cross Lingual ILP Solution to Zero Anaphora Resolution
Full text
Figure


Related documents
We study the construction and the convergence of the Ishikawa iterative pro- cess with errors for nonexpansive mappings in uniformly convex Banach spaces.. Some recent
How- ever, this work suggests that the temperature, abundance and velocity distributions in Abell 576 are consistent with a scenario where the cluster is passing through a line of
Several studies show that programmers are postponing software maintenance activities that improve software quality, even while seeking high-quality source code for themselves
The results of the current study demonstrate gender differ- ences in several spatio-temporal parameters, indicating a difference in gait patterns between genders with knee OA
The isotopic composition of lead can be used to identify the principal sources of the lead to which the cemetery population of Isola Sacra was exposed.. The isotopic composition
Socio-demographic, clinical and radiographic baseline factors were assessed for association with outcome at six-weeks follow-up evaluated by Shoulder Pain and Disability Index
Participants with skin cancer who searched the Internet themselves for information related to their diagnosis were more likely to be younger (mean age 52.5 vs 64.4, p o .001), to
A considerable proportion of the subjects in the Low Pain group experienced severe or extreme difficulty performing the high demand activities measured by the KOOS Sport
