Encoding Sentences with Graph Convolutional Networks
for Semantic Role Labeling
Diego Marcheggiani
1Ivan Titov
1,2 1ILLC, University of Amsterdam
2
ILCC, School of Informatics, University of Edinburgh
[email protected]
[email protected]
Abstract
Semantic role labeling (SRL) is the task of identifying the predicate-argument struc-ture of a sentence. It is typically re-garded as an important step in the stan-dard NLP pipeline. As the semantic rep-resentations are closely related to syntac-tic ones, we exploit syntacsyntac-tic information in our model. We propose a version of graph convolutional networks (GCNs), a recent class of neural networks operating on graphs, suited to model syntactic pendency graphs. GCNs over syntactic de-pendency trees are used as sentence en-coders, producing latent feature represen-tations of words in a sentence. We ob-serve that GCN layers are complementary to LSTM ones: when we stack both GCN and LSTM layers, we obtain a substantial improvement over an already state-of-the-art LSTM SRL model, resulting in the best reported scores on the standard benchmark (CoNLL-2009) both for Chinese and En-glish.
1 Introduction
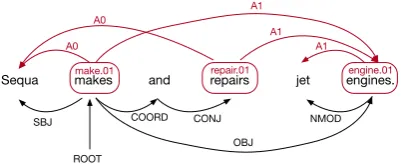
Semantic role labeling (SRL) (Gildea and Juraf-sky,2002) can be informally described as the task of discovering who did what to whom. For ex-ample, consider an SRL dependency graph shown above the sentence in Figure1. Formally, the task includes (1) detection of predicates (e.g.,makes); (2) labeling the predicates with a sense from a sense inventory (e.g., make.01); (3) identifying and assigning arguments to semantic roles(e.g.,
Sequais A0, i.e., an agent / ‘doer’ for the corre-sponding predicate, andengines is A1, i.e., a pa-tient / ‘an affected entity’). SRL is often regarded
Sequa makes and repairs jet engines.
SBJ COORD
OBJ
CONJ NMOD
ROOT
A1
A1 A1 A0
A0
[image:1.595.311.512.261.343.2]make.01 repair.01 engine.01
Figure 1: An example sentence annotated with se-mantic (top) and syntactic dependencies (bottom).
propose one way how to address this limitation. Specifically, we rely on graph convolutional networks (GCNs) (Duvenaud et al., 2015; Kipf and Welling,2017;Kearnes et al.,2016), a recent class of multilayer neural networks operating on graphs. For every node in the graph (in our case a word in a sentence), GCN encodes relevant in-formation about its neighborhood as a real-valued feature vector. GCNs have been studied largely in the context of undirected unlabeled graphs. We in-troduce a version of GCNs for modeling syntactic dependency structures and generally applicable to labeled directed graphs.
One layer GCN encodes only information about immediate neighbors and K layers are needed to encodeK-order neighborhoods (i.e., informa-tion about nodes at most K hops aways). This contrasts with recurrent and recursive neural net-works (Elman,1990;Socher et al.,2013) which, at least in theory, can capture statistical dependencies across unbounded paths in a trees or in a sequence. However, as we will further discuss in Section3.3, this is not a serious limitation when GCNs are used in combination with encoders based on recurrent networks (LSTMs). When we stack GCNs on top of LSTM layers, we obtain a substantial improve-ment over an already state-of-the-art LSTM SRL model, resulting in the best reported scores on the standard benchmark (CoNLL-2009), both for En-glish and Chinese.1
Interestingly, again unlike recursive neural net-works, GCNs do not constrain the graph to be a tree. We believe that there are many applica-tions in NLP, where GCN-based encoders of sen-tences or even documents can be used to incor-porate knowledge about linguistic structures (e.g., representations of syntax, semantics or discourse). For example, GCNs can take as input combined syntactic-semantic graphs (e.g., the entire graph from Figure 1) and be used within downstream tasks such as machine translation or question an-swering. However, we leave this for future work and here solely focus on SRL.
The contributions of this paper can be summa-rized as follows:
• we are the first to show that GCNs are effec-tive for NLP;
• we propose a generalization of GCNs suited 1The code is available at https://github.com/
diegma/neural-dep-srl.
to encoding syntactic information at word level;
• we propose a GCN-based SRL model and obtain state-of-the-art results on English and Chinese portions of the CoNLL-2009 dataset;
• we show that bidirectional LSTMs and syntax-based GCNs have complementary modeling power.
2 Graph Convolutional Networks
In this section we describe GCNs of Kipf and Welling (2017). Please refer to Gilmer et al. (2017) for a comprehensive overview of GCN ver-sions.
GCNs are neural networks operating on graphs and inducing features of nodes (i.e., real-valued vectors / embeddings) based on properties of their neighborhoods. InKipf and Welling(2017), they were shown to be very effective for the node clas-sification task: the classifier was estimated jointly with a GCN, so that the induced node features were informative for the node classification prob-lem. Depending on how many layers of convolu-tion are used, GCNs can capture informaconvolu-tion only about immediate neighbors (with one layer of con-volution) or any nodes at mostK hops aways (if Klayers are stacked on top of each other).
More formally, consider an undirected graph
G = (V,E), where V (|V| = n) and E are sets of nodes and edges, respectively. Kipf and Welling(2017) assume that edges contain all the self-loops, i.e.,(v, v) 2 E for anyv. We can de-fine a matrix X 2 Rm⇥n with each its column xv 2 Rm (v 2 V) encoding node features. The vectors can either encode genuine features (e.g., this vector can encode the title of a paper if citation graphs are considered) or be a one-hot vector. The node representation, encoding information about its immediate neighbors, is computed as
hv=ReLU 0
@ X
u2N(v)
(W xu+b)
1 A, (1)
whereW 2Rm⇥mandb2Rmare a weight ma-trix and a bias, respectively; N(v) are neighbors of v; ReLU is the rectifier linear unit activation function.2 Note thatv 2 N(v)(because of
self-loops), so the input feature representation ofv(i.e. xv) affects its induced representationhv.
2We dropped normalization factors used in Kipf and
Lane disputed those estimates ReLU( ·) ReLU( ·) ReLU( ·) ReLU( ·)
W
(1) sel
f
W
(1) sel
f
W
(1) sel
f
W
(1) sel
f
Wsubj(1)
W(1)obj
Wnmo(1) d
W(1)nmo d
W(1) obj
W(1)subj
ReLU( ·) ReLU( ·) ReLU( ·) ReLU( ·)
W
(2) sel
f
W
(2) sel
f
W
(2) sel
f
W
(2) sel
f
Wsubj(2)
W(2)subj
W(2) obj
W(2)obj
Wnmo(2) d
W(2)nmo d
… … … …
NMOD
[image:3.595.93.283.84.295.2]SBJ OBJ
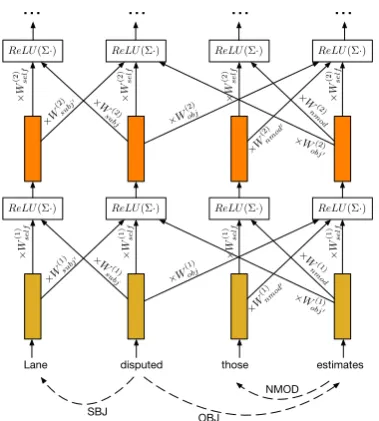
Figure 2: A simplified syntactic GCN (bias terms and gates are omitted); the syntactic graph of the sentence is shown with dashed lines at the bottom. Parameter matrices are sub-indexed with syntactic functions, and apostrophes (e.g.,subj’) signify that information flows in the direction opposite of the dependency arcs (i.e., from dependents to heads).
As in standard convolutional networks (LeCun et al.,2001), by stacking GCN layers one can in-corporate higher degree neighborhoods:
h(k+1)
v =ReLU
0
@ X
u2N(v)
W(k)h(k) u +b(k)
1 A
wherekdenotes the layer number andh(1)v =xv.
3 Syntactic GCNs
As syntactic dependency trees are directed and la-beled (we refer to the dependency labels as syn-tactic functions), we first need to modify the com-putation in order to incorporate label information (Section3.1). In the subsequent section, we incor-porate gates in GCNs, so that the model can decide which edges are more relevant to the task in ques-tion. Having gates is also important as we rely on automatically predicted syntactic representations, and the gates can detect and downweight poten-tially erroneous edges.
3.1 Incorporating directions and labels
Now, we introduce a generalization of GCNs ap-propriate for syntactic dependency trees, and in
general, for directed labeled graphs. First note that there is no reason to assume that information flows only along the syntactic dependency arcs (e.g., frommakestoSequa), so we allow it to flow in the opposite direction as well (i.e., from depen-dents to heads). We use a graphG= (V,E), where the edge set contains all pairs of nodes (i.e., words) adjacent in the dependency tree. In our example, both(Sequa, makes)and (makes,Sequa) belong to the edge set. The graph is labeled, and the label L(u, v)for(u, v) 2 E contains both information about the syntactic function and indicates whether the edge is in the same or opposite direction as the syntactic dependency arc. For example, the la-bel for(makes,Sequa)issubj, whereas the label for(Sequa, makes)issubj0, with the apostrophe
indicating that the edge is in the direction oppo-site to the corresponding syntactic arc. Similarly, self-loops will have labelself. Consequently, we can simply assume that the GCN parameters are label-specific, resulting in the following computa-tion, also illustrated in Figure2:
h(vk+1) =ReLU 0 @ X
u2N(v)
WL(k(u,v) )hu(k)+b(Lk()u,v)
1 A.
This model is over-parameterized,3 especially
given that SRL datasets are moderately sized, by deep learning standards. So instead of learning the GCN parameters directly, we define them as
WL(k()u,v)=Vdir(k)(u,v), (2) wheredir(u, v)indicates whether the edge(u, v)
is directed (1) along, (2) in the opposite direction to the syntactic dependency arc, or (3) is a self-loop;Vdir(k)(u,v) 2 Rm⇥m. Our simplification cap-tures the intuition that information should be prop-agated differently along edges depending whether this is a head-to-dependent or dependent-to-head edge (i.e., along or opposite the corresponding syntactic arc) and whether it is a self-loop. So we do not share any parameters between these three very different edge types. Syntactic functions are important, but perhaps less crucial, so they are en-coded only in the feature vectorsbL(u,v).
3.2 Edge-wise gating
Uniformly accepting information from all neigh-boring nodes may not be appropriate for the SRL 3Chinese and English CoNLL-2009 datasets used 41 and
setting. For example, we see in Figure1that many semantic arcs just mirror their syntactic counter-parts, so they may need to be up-weighted. More-over, we rely on automatically predicted syntactic structures, and, even for English, syntactic parsers are far from being perfect, especially when used out-of-domain. It is risky for a downstream ap-plication to rely on a potentially wrong syntactic edge, so the corresponding message in the neural network may need to be down-weighted.
In order to address the above issues, inspired by recent literature (van den Oord et al., 2016; Dauphin et al.,2016), we calculate for each edge node pair a scalar gate of the form
g(k) u,v=
⇣ h(k)
u ·ˆvdir(k)(u,v)+ ˆb(Lk()u,v)
⌘ , (3)
where is the logistic sigmoid function,
ˆ
v(dirk)(u,v) 2 Rm andˆb(k)
L(u,v) 2 Rare weights and
a bias for the gate. With this additional gating mechanism, the final syntactic GCN computation is formulated as
h(vk+1)=ReLU(
X
u2N(v)
gv,u(k)(Vdir(k)(u,v)hu(k)+b(Lk()u,v))). (4)
3.3 Complementarity of GCNs and LSTMs
The inability of GCNs to capture dependencies between nodes far away from each other in the graph may seem like a serious problem, especially in the context of SRL: paths between predicates and arguments often include many dependency arcs (Roth and Lapata, 2016). However, when graph convolution is performed on top of LSTM states (i.e., LSTM states serve as inputxv = h(1)v to GCN) rather than static word embeddings, GCN may not need to capture more than a couple of hops.
To elaborate on this, let us speculate what role GCNs would play when used in combinations with LSTMs, given that LSTMs have already been shown very effective for SRL (Zhou and Xu,2015; Marcheggiani et al., 2017). Though LSTMs are capable of capturing at least some degree of syn-tax (Linzen et al.,2016) without explicit syntactic supervision, SRL datasets are moderately sized, so LSTM models may still struggle with harder cases. Typically, harder cases for SRL involve ar-guments far away from their predicates. In fact, 20% and 30% of arguments are more than 5 to-kens away from their predicate, in our English and
A1
Classifier
J layers BiLSTM
Lane disputed those estimates
dobj nmod nsubj
K layers GCN
word representation
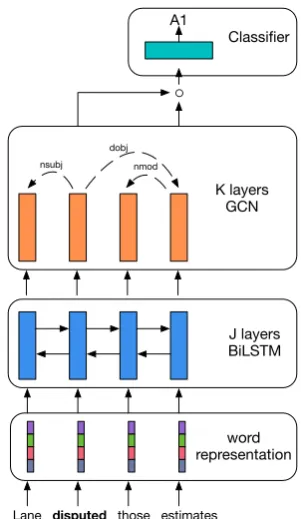
Figure 3: Predicting an argument and its label with an LSTM + GCN encoder.
Chinese collections, respectively. However, if we imagine that we can ‘teleport’ even over a sin-gle (longest) syntactic dependency edge, the ’dis-tance’ would shrink: only 9% and 13% arguments will now be more than 5 LSTM steps away (again for English and Chinese, respectively). GCNs pro-vide this ‘teleportation’ capability. These observa-tions suggest that LSTMs and GCNs may be com-plementary, and we will see that empirical results support this intuition.
4 Syntax-Aware Neural SRL Encoder
In this work, we build our semantic role la-beler on top of the syntax-agnostic LSTM-based SRL model ofMarcheggiani et al.(2017), which already achieves state-of-the-art results on the CoNLL-2009 English dataset. Following their ap-proach we employ the same bidirectional (BiL-STM) encoder and enrich it with a syntactic GCN. The CoNLL-2009 benchmark assumes that predicate positions are already marked in the test set (e.g., we would know thatmakes,repairsand [image:4.595.334.485.82.342.2](i.e., markingmakesasmake.01) we use of an off-the-shelf disambiguation model (Roth and Lapata, 2016; Bj¨orkelund et al., 2009). As in Marcheg-giani et al.(2017) and in most previous work, we process individual predicates in isolation, so for each predicate, our task reduces to a sequence la-beling problem. That is, given a predicate (e.g.,
disputedin Figure3) one needs to identify and la-bel all its arguments (e.g., lala-bel estimatesas A1 and labelthoseas ‘NULL’, indicating thatthoseis not an argument ofdisputed).
The semantic role labeler we propose is com-posed of four components (see Figure3):
• look-ups of word embeddings;
• a BiLSTM encoder that takes as input the word representation of each word in a sen-tence;
• a syntax-based GCN encoder that re-encodes the BiLSTM representation based on the au-tomatically predicted syntactic structure of the sentence;
• a role classifier that takes as input the GCN representation of the candidate argument and the representation of the predicate to predict the role associated with the candidate word.
4.1 Word representations
For each wordwiin the considered sentence, we create a sentence-specific word representationxi. We represent each word w as the concatenation of four vectors:4 a randomly initialized word
em-bedding xre 2 Rdw, a pre-trained word
embed-dingxpe2Rdw estimated on an external text
col-lection, a randomly initialized part-of-speech tag embedding xpos 2 Rdp and a randomly
initial-ized lemma embedding xle 2 Rdl (active only if
the word is a predicate). The randomly initialized embeddingsxre,xpos, andxle are fine-tuned dur-ing traindur-ing, while the pre-trained ones are kept fixed. The final word representation is given by x=xre xpe xpos xle, where represents the concatenation operator.
4.2 Bidirectional LSTM layer
One of the most popular and effective ways to represent sequences, such as sentences (Mikolov et al., 2010), is to use recurrent neural networks 4We drop the index ifrom the notation for the sake of
brevity.
(RNN) (Elman, 1990). In particular their gated versions, Long Short-Term Memory (LSTM) net-works (Hochreiter and Schmidhuber, 1997) and Gated Recurrent Units (GRU) (Cho et al.,2014), have proven effective in modeling long sequences (Chiu and Nichols,2016;Sutskever et al.,2014).
Formally, an LSTM can be defined as a func-tionLST M✓(x1:i)that takes as input the sequence x1:i and returns a hidden state hi 2 Rdh. This state can be regarded as a representation of the sentence from the start to the position i, or, in other words, it encodes the word at position i along with its left context. However, the right context is also important, so Bidirectional LSTMs (Graves,2008) use two LSTMs: one for the for-ward pass, and another for the backfor-ward pass, LST MF and LST MB, respectively. By con-catenating the states of both LSTMs, we cre-ate a complete context-aware representation of a word BiLST M(x1:n, i) = LST MF(x1:i) LST MB(xn:i). We follow Marcheggiani et al. (2017) and stackJlayers of bidirectional LSTMs, where each layer takes the lower layer as its input.
4.3 Graph convolutional layer
The representation calculated with the BiLSTM encoder is fed as input to a GCN of the form de-fined in Equation (4). The neighboring nodes of a nodev, namelyN(v), and their relations tovare predicted by an external syntactic parser.
4.4 Semantic role classifier
The classifier predicts semantic roles of words given the predicate while relying on word repre-sentations provided by GCN; we concatenate hid-den states of the candidate argument word and the predicate word and use them as input to a classi-fier (Figure3, top). The softmax classifier com-putes the probability of the role (including special ‘NULL’ role):
p(r|ti, tp, l)/exp(Wl,r(ti tp)), (5)
where ti and tp are representations produced by the graph convolutional encoder, l is the lemma of predicate p, and the symbol / signifies pro-portionality.5 As FitzGerald et al. (2015) and
Marcheggiani et al.(2017), instead of using a fixed matrixWl,ror simply assuming thatWl,r = Wr,
5We abuse the notation and refer aspboth to the predicate
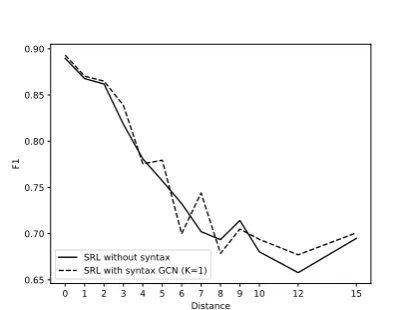
Figure 4: F1as function of word distance. The
distance starts from zero, since nominal predicates can be arguments of themselves.
we jointly embed the rolerand predicate lemmal using a non-linear transformation:
Wl,r=ReLU(U(ql qr)), (6)
whereUis a parameter matrix, whereasql 2 Rd0 l
and qr 2 Rdr are randomly initialized
embed-dings of predicate lemmas and roles. In this way each role prediction is predicate-specific, and, at the same time, we expect to learn a good represen-tation for roles associated with infrequent predi-cates. As our training objective we use the cate-gorical cross-entropy.
5 Experiments
5.1 Datasets and parameters
We tested the proposed SRL model on the English and Chinese CoNLL-2009 dataset with standard splits into training, test and development sets. The predicted POS tags for both languages were pro-vided by the CoNLL-2009 shared-task organizers. For the predicate disambiguator we used the ones fromRoth and Lapata(2016) for English and from Bj¨orkelund et al.(2009) for Chinese. We parsed English sentences with the BIST Parser ( Kiper-wasser and Goldberg,2016), whereas for Chinese we used automatically predicted parses provided by the CoNLL-2009 shared-task organizers.
For English, we used external embeddings of Dyer et al. (2015), learned using the structured skip n-gram approach of Ling et al.(2015). For Chinese we used external embeddings produced with the neural language model of Bengio et al. (2003). We used edge dropout in GCN: when
Figure 5: Performance with dependency arcs of given type dropped, on Chinese development set.
System (English) P R F1
LSTMs 84.3 81.1 82.7
LSTMs + GCNs (K=1) 85.2 81.6 83.3 LSTMs + GCNs (K=2) 84.1 81.4 82.7 LSTMs + GCNs (K=1), no gates 84.7 81.4 83.0 GCNs (no LSTMs), K=1 79.9 70.4 74.9 GCNs (no LSTMs), K=2 83.4 74.6 78.7 GCNs (no LSTMs), K=3 83.6 75.8 79.5 GCNs (no LSTMs), K=4 82.7 76.0 79.2
Table 1: SRL results without predicate disam-biguation on the English development set.
computing h(vk), we ignore each node v 2 N(v) with probability . Adam (Kingma and Ba,2015) was used as an optimizer. The hyperparameter tuning and all model selection were performed on the English development set; the chosen values are shown in Appendix.
5.2 Results and discussion
In order to show that GCN layers are effective, we first compare our model against its version which lacks GCN layers (i.e. essentially the model of Marcheggiani et al.(2017)). Importantly, to mea-sure the genuine contribution of GCNs, we first tuned this syntax-agnostic model (e.g., the number of LSTM layers) to get best possible performance on the development set.6
We compare the syntax-agnostic model with 3 syntax-aware versions: one GCN layer over syn-tax (K = 1), one layer GCN without gates and two GCN layers (K= 2). As we rely on the same 6For example, if we would have used only one layer of
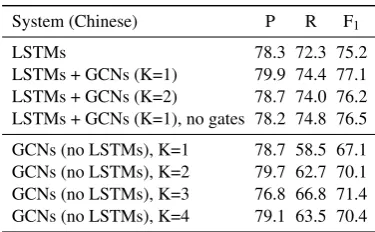
[image:6.595.84.289.77.232.2] [image:6.595.309.511.78.234.2]System (Chinese) P R F1
LSTMs 78.3 72.3 75.2
LSTMs + GCNs (K=1) 79.9 74.4 77.1 LSTMs + GCNs (K=2) 78.7 74.0 76.2 LSTMs + GCNs (K=1), no gates 78.2 74.8 76.5 GCNs (no LSTMs), K=1 78.7 58.5 67.1 GCNs (no LSTMs), K=2 79.7 62.7 70.1 GCNs (no LSTMs), K=3 76.8 66.8 71.4 GCNs (no LSTMs), K=4 79.1 63.5 70.4
Table 2: SRL results without predicate disam-biguation on the Chinese development set.
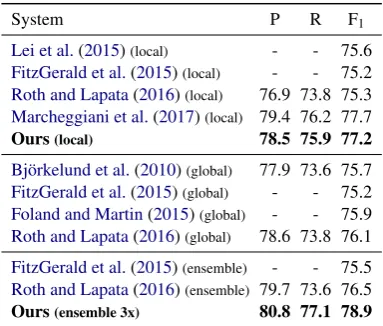
System P R F1
Lei et al.(2015)(local) - - 86.6
FitzGerald et al.(2015)(local) - - 86.7
Roth and Lapata(2016)(local) 88.1 85.3 86.7
Marcheggiani et al.(2017)(local) 88.7 86.8 87.7 Ours(local) 89.1 86.8 88.0
Bj¨orkelund et al.(2010)(global) 88.6 85.2 86.9
FitzGerald et al.(2015)(global) - - 87.3
Foland and Martin(2015)(global) - - 86.0
Swayamdipta et al.(2016)(global) - - 85.0
Roth and Lapata(2016)(global) 90.0 85.5 87.7
FitzGerald et al.(2015)(ensemble) - - 87.7
[image:7.595.92.280.78.194.2]Roth and Lapata(2016)(ensemble) 90.3 85.7 87.9 Ours(ensemble 3x) 90.5 87.7 89.1
Table 3: Results on the test set for English.
off-the-shelf disambiguator for all versions of the model, in Table1and2we report SRL-only scores (i.e., predicate disambiguation is not evaluated) on the English and Chinese development sets. For both datasets, the syntax-aware model with one GCN layers (K = 1) performs the best, outper-forming the LSTM version by 1.9% and 0.6% for Chinese and English, respectively. The reasons why the improvements on Chinese are much larger are not entirely clear (e.g., both languages are rela-tive fixed word order ones, and the syntactic parses for Chinese are considerably less accurate), this may be attributed to a higher proportion of long-distance dependencies between predicates and ar-guments in Chinese (see Section3.3). Edge-wise gating (Section 3.2) also appears important: re-moving gates leads to a drop of 0.3% F1for
En-glish and 0.6% F1for Chinese.
Stacking two GCN layers does not give any ben-efit. When BiLSTM layers are dropped altogether, stacking two layers (K = 2) of GCNs greatly im-proves the performance, resulting in a 3.8% jump in F1for English and a 3.0% jump in F1 for
Chi-System P R F1
Zhao et al.(2009) (global) 80.4 75.2 77.7
Bj¨orkelund et al.(2009) (global) 82.4 75.1 78.6
[image:7.595.315.506.79.146.2]Roth and Lapata(2016) (global) 83.2 75.9 79.4 Ours(local) 84.6 80.4 82.5
Table 4: Results on the Chinese test set.
nese. Adding a 3rd layer of GCN (K= 3) further improves the performance.7This suggests that
ex-tra GCN layers are effective but largely redundant with respect to what LSTMs already capture.
In Figure4, we show theF1 scores results on
the English development set as a function of the distance, in terms of tokens, between a candidate argument and its predicate. As expected, GCNs appear to be more beneficial for long distance de-pendencies, as shorter ones are already accurately captured by the LSTM encoder.
We looked closer in contribution of specific de-pendency relations for Chinese. In order to assess this without retraining the model multiple times, we drop all dependencies of a given type at test time (one type at a time, only for types appear-ing over 300 times in the development set) and ob-serve changes in performance. In Figure5, we see that the most informative dependency is COMP (complement). Relative clauses in Chinese are very frequent and typically marked with particle
Ñ(de). The relative clause will syntactically
de-pend onÑas COMP, so COMP encodes
impor-tant information about predicate-argument struc-ture. These are often long-distance dependencies and may not be accurately captured by LSTMs. Although TMP (temporal) dependencies are not as frequent (⇠2% of all dependencies), they are also important: temporal information is mirrored in se-mantic roles.
In order to compare to previous work, in Ta-ble 3 we report test results on the English in-domain (WSJ) evaluation data. Our model is lo-cal, as all the argument detection and labeling de-cisions are conditionally independent: their inter-action is captured solely by the LSTM+GCN en-coder. This makes our model fast and simple, though, as shown in previous work, global mod-eling of the structured output is beneficial.8 We
leave this extension for future work. Interestingly, 7Note that GCN layers are computationally cheaper than
LSTM ones, even in our non-optimized implementation.
8As seen in Table3, labelers ofFitzGerald et al.(2015)
[image:7.595.92.282.237.411.2]System P R F1 Lei et al.(2015)(local) - - 75.6
FitzGerald et al.(2015)(local) - - 75.2
Roth and Lapata(2016)(local) 76.9 73.8 75.3
Marcheggiani et al.(2017)(local) 79.4 76.2 77.7 Ours(local) 78.5 75.9 77.2
Bj¨orkelund et al.(2010)(global) 77.9 73.6 75.7
FitzGerald et al.(2015)(global) - - 75.2
Foland and Martin(2015)(global) - - 75.9
Roth and Lapata(2016)(global) 78.6 73.8 76.1
FitzGerald et al.(2015)(ensemble) - - 75.5
[image:8.595.91.283.79.242.2]Roth and Lapata(2016)(ensemble) 79.7 73.6 76.5 Ours(ensemble 3x) 80.8 77.1 78.9
Table 5: Results on the out-of-domain test set.
we outperform even the best global model and the best ensemble of global models, without using global modeling or ensembles. When we create an ensemble of 3 models with the product-of-expert combination rule, we improve by 1.2% over the best previous result, achieving 89.1% F1.9
For Chinese (Table4), our best model outper-forms the state-of-the-art model ofRoth and Lap-ata(2016) by even larger margin of 3.1%.
For English, in the CoNLL shared task, systems are also evaluated on the out-of-domain dataset. Statistical models are typically less accurate when they are applied to out-of-domain data. Con-sequently, the predicted syntax for the out-of-domain test set is of lower quality, which neg-atively affects the quality of GCN embeddings. However, our model works surprisingly well on out-of-domain data (Table 5), substantially out-performing all the previous syntax-aware mod-els. This suggests that our model is fairly robust to mistakes in syntax. As expected though, our model does not outperform the syntax-agnostic model ofMarcheggiani et al.(2017).
6 Related Work
Perhaps the earliest methods modeling syntax-semantics interface with RNNs are due to ( Hen-derson et al.,2008;Titov et al.,2009;Gesmundo et al., 2009), they used shift-reduce parsers for joint SRL and syntactic parsing, and relied on RNNs to model statistical dependencies across syntactic and semantic parsing actions. A more 9To compare to previous work, we report combined scores
which also include predicate disambiguation. As we use dis-ambiguators from previous work (see Section 5.1), actual gains in argument identification and labeling are even larger.
modern (e.g., based on LSTMs) and effective rein-carnation of this line of research has been pro-posed in Swayamdipta et al. (2016). Other re-cent work which considered incorporation of syn-tactic information in neural SRL models include: FitzGerald et al.(2015) who use standard syntac-tic features within an MLP calculating potentials of a CRF model;Roth and Lapata(2016) who en-riched standard features for SRL with LSTM rep-resentations of syntactic paths between arguments and predicates; Lei et al. (2015) who relied on low-rank tensor factorizations for modeling syn-tax. Also Foland and Martin(2015) used (non-graph) convolutional networks and provided syn-tactic features as input. A very different line of research, but with similar goals to ours (i.e. inte-grating syntax with minimal feature engineering), used tree kernels (Moschitti et al.,2008).
Beyond SRL, there have been many propos-als on how to incorporate syntactic information in RNN models, for example, in the context of neural machine translation (Eriguchi et al.,2017; Sennrich and Haddow, 2016). One of the most popular and attractive approaches is to use tree-structured recursive neural networks (Socher et al., 2013; Le and Zuidema,2014;Dyer et al.,2015), including stacking them on top of a sequential BiLSTM (Miwa and Bansal, 2016). An ap-proach ofMou et al.(2015) to sentiment analysis and question classification, introduced even before GCNs became popular in the machine learning community, is related to graph convolution. How-ever, it is inherently single-layer and tree-specific, uses bottom-up computations, does not share pa-rameters across syntactic functions and does not use gates. Gates have been previously used in GCNs (Li et al., 2016) but between GCN layers rather than for individual edges.
Previous approaches to integrating syntactic in-formation in neural models are mainly designed to induce representations of sentences or syntac-tic constituents. In contrast, the approach we pre-sented incorporates syntactic information at word level. This may be attractive from the engineering perspective, as it can be used, as we have shown, instead or along with RNN models.
7 Conclusions and Future Work
model, resulting in state-of-the-art results for Chi-nese and English. There are relatively straightfor-ward steps which can further improve the SRL re-sults. For example, we relied on labeling argu-ments independently, whereas using a joint model is likely to significantly improve the performance. Also, in this paper we consider the dependency version of the SRL task, however the model can be generalized to the span-based version of the task (i.e. labeling argument spans with roles rather that syntactic heads of arguments) in a relatively straightforward fashion.
More generally, given simplicity of GCNs and their applicability to general graph structures (not necessarily trees), we believe that there are many NLP tasks where GCNs can be used to incorporate linguistic structures (e.g., syntactic and semantic representations of sentences and discourse parses or co-reference graphs for documents).
Acknowledgements
We would thank Anton Frolov, Michael Schlichtkrull, Thomas Kipf, Michael Roth, Max Welling, Yi Zhang, and Wilker Aziz for their suggestions and comments. The project was supported by the European Research Council (ERC StG BroadSem 678254), the Dutch National Science Foundation (NWO VIDI 639.022.518) and an Amazon Web Services (AWS) grant.
References
Yoshua Bengio, R´ejean Ducharme, Pascal Vincent, and Christian Janvin. 2003. A neural probabilistic lan-guage model. Journal of Machine Learning Re-search, 3:1137–1155.
Anders Bj¨orkelund, Bernd Bohnet, Love Hafdell, and Pierre Nugues. 2010. A high-performance syntactic and semantic dependency parser. InProceedings of COLING: Demonstrations.
Anders Bj¨orkelund, Love Hafdell, and Pierre Nugues. 2009. Multilingual semantic role labeling. In Pro-ceedings of CoNLL.
Jason P. C. Chiu and Eric Nichols. 2016. Named entity recognition with bidirectional LSTM-CNNs.TACL, 4:357–370.
Kyunghyun Cho, Bart van Merrienboer, C¸aglar G¨ulc¸ehre, Dzmitry Bahdanau, Fethi Bougares, Hol-ger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. InProceedings of EMNLP.
Yann N. Dauphin, Angela Fan, Michael Auli, and David Grangier. 2016. Language modeling with gated convolutional networks. arXiv preprint arXiv:1612.08083.
David K. Duvenaud, Dougal Maclaurin, Jorge Aguilera-Iparraguirre, Rafael Bombarell, Timothy Hirzel, Al´an Aspuru-Guzik, and Ryan P. Adams. 2015. Convolutional networks on graphs for learn-ing molecular flearn-ingerprints. InProceedings of NIPS.
Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, and Noah A. Smith. 2015. Transition-based dependency parsing with stack long short-term memory. InProceedings of ACL.
Jeffrey L. Elman. 1990. Finding structure in time.
Cognitive Science, 14(2):179–211.
Akiko Eriguchi, Yoshimasa Tsuruoka, and Kyunghyun Cho. 2017. Learning to parse and translate im-proves neural machine translation. arXiv preprint arXiv:1702.03525.
Nicholas FitzGerald, Oscar T¨ackstr¨om, Kuzman Ganchev, and Dipanjan Das. 2015. Semantic role la-beling with neural network factors. InProceedings of EMNLP.
William Foland and James Martin. 2015. Dependency-based semantic role labeling using convolutional neural networks. InProceedings of the Fourth Joint Conference on Lexical and Computational Seman-tics (*SEM).
Andrea Gesmundo, James Henderson, Paola Merlo, and Ivan Titov. 2009. Latent variable model of synchronous syntactic-semantic parsing for multiple languages. InProceedings of CoNLL.
Daniel Gildea and Daniel Jurafsky. 2002. Automatic labeling of semantic roles. Computational linguis-tics, 28(3):245–288.
Justin Gilmer, Samuel S. Schoenholz, Patrick F. Ri-ley, Oriol Vinyals, and George E. Dahl. 2017. Neu-ral message passing for quantum chemistry. arXiv preprint arXiv:1704.01212.
Alex Graves. 2008.Supervised sequence labelling with recurrent neural networks. Ph.D. thesis, M¨unchen, Techn. Univ., Diss., 2008.
James Henderson, Paola Merlo, Gabriele Musillo, and Ivan Titov. 2008. A latent variable model of syn-chronous parsing for syntactic and semantic depen-dencies. InProceedings of CoNLL.
Sepp Hochreiter and J¨urgen Schmidhuber. 1997. Long short-term memory. Neural Computation, 9(8):1735–1780.
Steven Kearnes, Kevin McCloskey, Marc Berndl, Vijay Pande, and Patrick Riley. 2016. Molecular graph convolutions: moving beyond fingerprints. Jour-nal of computer-aided molecular design, 30(8):595– 608.
Diederik Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. InProceedings of ICLR.
Eliyahu Kiperwasser and Yoav Goldberg. 2016. Sim-ple and accurate dependency parsing using bidirec-tional LSTM feature representations. TACL, 4:313– 327.
Thomas N. Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. InProceedings of ICLR.
Phong Le and Willem Zuidema. 2014. The inside-outside recursive neural network model for depen-dency parsing. InProceedings of EMNLP.
Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner. 2001. Gradient-based learning applied to document recognition. InProceedings of Intelligent Signal Processing.
Tao Lei, Yuan Zhang, Llu´ıs M`arquez, Alessandro Mos-chitti, and Regina Barzilay. 2015. High-order low-rank tensors for semantic role labeling. In Proceed-ings of NAACL.
Beth Levin. 1993. English verb classes and alterna-tions: A preliminary investigation. University of Chicago press.
Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard S. Zemel. 2016. Gated graph sequence neu-ral networks. InProceedings of ICLR.
Wang Ling, Chris Dyer, Alan W Black, and Isabel Trancoso. 2015. Two/too simple adaptations of word2vec for syntax problems. InProceedings of NAACL.
Tal Linzen, Emmanuel Dupoux, and Yoav Goldberg. 2016. Assessing the ability of LSTMs to learn syntax-sensitive dependencies.TACL, 4:521–535. Diego Marcheggiani, Anton Frolov, and Ivan Titov.
2017. A simple and accurate syntax-agnostic neural model for dependency-based semantic role labeling. InProceedings of CoNLL.
Tomas Mikolov, Martin Karafi´at, Luk´as Burget, Jan Cernock´y, and Sanjeev Khudanpur. 2010. Recurrent neural network based language model. In Proceed-ings of INTERSPEECH.
Makoto Miwa and Mohit Bansal. 2016. End-to-end re-lation extraction using lstms on sequences and tree structures. InProceedings of ACL.
Alessandro Moschitti, Daniele Pighin, and Roberto Basili. 2008. Tree kernels for semantic role label-ing.Computational Linguistics, 34(2):193–224.
Lili Mou, Hao Peng, Ge Li, Yan Xu, Lu Zhang, and Zhi Jin. 2015. Discriminative neural sentence mod-eling by tree-based convolution. InProceedings of EMNLP.
A¨aron van den Oord, Nal Kalchbrenner, Lasse Espe-holt, Koray Kavukcuoglu, Oriol Vinyals, and Alex Graves. 2016. Conditional image generation with PixelCNN decoders. InProceedings of NIPS. Sameer Pradhan, Kadri Hacioglu, Wayne H. Ward,
James H. Martin, and Daniel Jurafsky. 2005. Se-mantic role chunking combining complementary syntactic views. InProceedings of CoNLL. Vasin Punyakanok, Dan Roth, and Wen-tau Yih. 2008.
The importance of syntactic parsing and inference in semantic role labeling. Computational Linguistics, 34(2):257–287.
Michael Roth and Mirella Lapata. 2016. Neural se-mantic role labeling with dependency path embed-dings. InProceedings of ACL.
Rico Sennrich and Barry Haddow. 2016. Linguistic in-put features improve neural machine translation. In
Proceedings of WMT.
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment tree-bank. InProceedings of EMNLP.
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural net-works. InProceedings of NIPS.
Swabha Swayamdipta, Miguel Ballesteros, Chris Dyer, and Noah A. Smith. 2016. Greedy, joint syntactic-semantic parsing with stack LSTMs. InProceedings of CoNLL.
Cynthia A. Thompson, Roger Levy, and Christopher D. Manning. 2003. A generative model for semantic role labeling. InProceedings of ECML.
Ivan Titov, James Henderson, Paola Merlo, and Gabriele Musillo. 2009. Online projectivisation for synchronous parsing of semantic and syntactic de-pendencies. InProceedings of IJCAI.
Hai Zhao, Wenliang Chen, Jun’ichi Kazama, Kiyotaka Uchimoto, and Kentaro Torisawa. 2009. Multilin-gual dependency learning: Exploiting rich features for tagging syntactic and semantic dependencies. In
Proceedings of CoNLL.