Cross Lingual Cross Platform Rumor Verification Pivoting on Multimedia Content
Full text
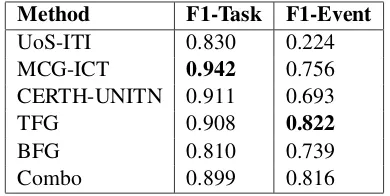
Figure







Related documents
[6] European Language Label of Labels: “The European Label is an award that encourages new initiatives in the field of teaching and learning languages, rewarding new techniques
Under the brand “Askaynak”, Kaynak Tekniði manufactures welding electrodes and welding wires primarily used by the welding manufacturing industry, while the “Kobatek” brand of
Tender shall be handed over to AO (HCD), Room No.C-01, Ministry of External Affairs Housing Complex, Plot No.1, Sector-2, Dwarka, New Delhi-110075 (on or before the due date and
It is expected that new and improved recreation services will be an important element in achieving many of the visitor program objectives for the park. This will be achieved
The results showed the presence of significant differences between the pre and post measurement for the range of motion for the elbow joint in favor of the post measurement a all
Banks kept their deficiency to priority sector lending with NABARD and the latter in turn chanelised these resources to the state governments through RIDF.. NABARD pays interest
As primary care workload complexity and demand increase, primary care practices are restructuring to team-based models of care by including interdisciplinary members such
