Even Unassociated Features Can Improve Lexical Distributional Similarity
Full text
Figure


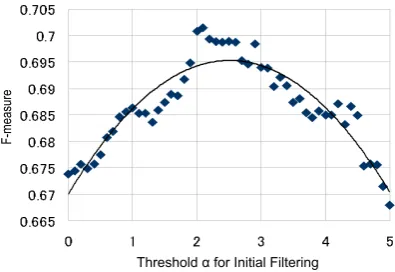
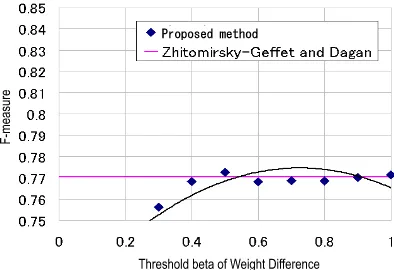
Related documents
Quantity discrimination is dependent on ratio, and since ratios of co-variables (cumulative surface area, brightness or contour length of stimuli in the small and large set) did
In order to understand the functions of EBV-miR-BART11 and FOXP1 in inflammation-induced cell proliferation, 5-8F, HK-1, and AGS cells with exogenous EBV-miR- BART11 or
In these fish the EOs are extended, non- homogeneous structures in which different regions generate different waveforms and, in the case of the wave components generated
Adaptation time course in cooling-sensitive response When a cooling stimulus is applied at the culture temperature, Paramecium cells swimming in a standard solution show a
Combined treatment with Nutlin-3 and cisplatin significantly decreased the clonogenic survival of wild- type TP53 ovarian cancer cells compared with either agent alone, and
In patients with low-grade lesions (WHO grade II), we observed a moderate Cho/ NAA ratio increase of up to 1.3, whereas anaplastic lesions exhibited a distinctly higher Cho/NAA
twitch muscles are active during slow swimming whereas the fast-twitch fibers are recruited during fast swimming, an assumption supported by twitch-time record- ings
Difference of precipitation in JJA between future projections and the base period in % for the ensemble minus standard deviation among members (left panel), ensemble (middle panel)
