Review Paper on Recognizing Emotions Using Multimodal Information From Spontaneous Non-basic & micro expressions
5
0
0
Full text
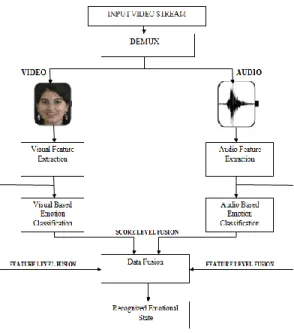
Figure
Related documents