Augmenting Neural Encoder-Decoder Model for
Natural Language Generation Tasks
Yichen Jiang
Department of Computer Science UNC Chapel Hill [email protected]
Abstract
Neural Encoder-Decoder model has been widely adopted for grounded language generation tasks. Such tasks usually require translation of data from one domain to a different domain, including machine translation (language to language), image captioning (image to language), and text summarization (long article to short summary). In this thesis, we aim to improve Neural Encoder-Decoder model for two different generation tasks: text summarization and image captioning. For summarization, we aim to improve the encoder of a popular pointer-generator model by adding a ‘closed-book’ decoder without attention and pointer mechanism. We argue that such a decoder forces the encoder to be more selective on the information encoded in its memory state since it can’t rely on the extra information provided by the attention and copy modules, and hence improves the entire model. On the CNN/Daily Mail dataset, our model outperforms the baseline significantly in terms of ROUGE and METEOR metrics and receives higher saliency scores, for both cross-entropy and reinforced setups. For image captioning, we propose a framework based on Conditional Generative Adversarial Network (CGAN), which jointly trains a a generator that produces captions conditioned on the image, and a discriminator that evaluates the probability of the caption being generated or not. We present a series of experiments to show that our CGAN-based model consistently and significantly outperforms strong baseline trained with maximum likelihood, which is not achieved by previous work that adopted a similar approach.
1
Introduction
Natural Language Generation (NLG) is a Natural Language Processing (NLP) task of automatically generating natural language. Most NLG tasks are grounded, which means the model need to generate the language from a given instance of data like image, text(language), knowledge base, etc. Therefore, grounded NLG can be generalized to translating data from the source domain to the target domain of natural language. Such tasks include machine translation (one language to another language), text summarization (long stories to short summaries), QA (question to answer), image captioning (image to description), etc. Models that perform well in grounded Natural Language Generation tasks need to understand the data in source domain (data that needs to be translated to natural language), as well as the language in target domain (desired output in natural language).
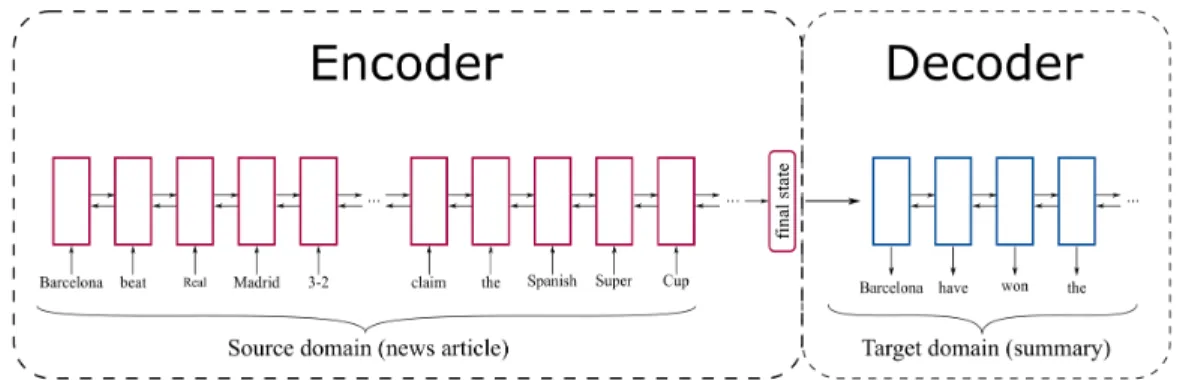
After the arriving of Deep Learning era, there have been a large number of studies that tried to apply neural networks to NLG tasks. Among them are a specific class of models called Encoder-Decoder model that serves as the basic architecture of state-of-the-art systems in a lot of language generation tasks. An Encoder-Decoder model has two components: an encoder that encodes the data in source domain to a fixed-size vector, and a decoder that takes this vector as input and generate natural language in the target domain. Fig. 1 provides an visualization of a typical Encoder-Decoder model.
In this thesis, we focus on two NLG tasks, automatic text summarization and image captioning, by augmenting the baseline Encoder-Decoder architecture with more intuitive components. In both tasks, our proposed models achieved statistical significant improvements on their baselines respectively, in a number of automatic metrics. In summarization particularly, our model obtained state-of-the-art results among neural models on a challenging long-text summarization dataset, in terms of ROUGE scores.
Automatic text summarization Summarization is the task of condensing a long passage to a shorter version that only covers the most salient information from the original text. Extractive summarization models Jing and McKeown (2000); Knight and Marcu (2002); Clarke and Lapata (2008); Filippova et al. (2015) pick words and phrases from the source text to form a summary, while an abstractive model samples words from a fixed-size vocabulary instead of copying from text directly. Recent successes in neural Encoder-Decoder attention models Sutskever et al. (2014); Bahdanau et al. (2014) have fueled a lot of studies Rush et al. (2015); Nallapati et al. (2016); Chopra et al. (2016); Zeng et al. (2016); Gu et al. (2016); Gulcehre et al. (2016) in abstractive summarization. While these works led to powerful summarizers with strong pointer decoders Vinyals et al. (2015a), here we focus on the encoder of an Encoder-Decoder model and aim to improve its ability to memorize salient information from the source passage. Specifically, we build upon the pointer-generator See et al. (2017), but add another ‘closed book’ decoder that has neither pointer nor attention. We provide both intuition and evidence of its contribution to a better summarization model in the following paragraphs.
The intuition is as followed: imagine there are two students learning to do abstractive summarization from scratch. During training, Student A is allowed to constantly look back at the passage when writing the summary (like a pointer-generator), while Student B has to occasionally write the summary without looking back (like our 2-decoder model with a non-attention/copy decoder). During the final test, both students can look at the passage while writing the summary. Student B will write better summaries after training because s/he is sometimes not allowed to look at the paragraph when writing summaries, and is hence forced to learn to distill important information from the input document. In terms of back-propagation intuition, during the training of an attentional Encoder-Decoder model (e.g., See et al. (2017)), most gradients are back-propagated to the encoder’s hidden state through the attention layer. This encourages the encoder to correctly encode salient words at the current encoding steps, but does make sure that this information is not forgotten by the encoder afterwards. However, for a plain LSTM (closed-book) decoder without attention, its only connection with the encoder is through the memory state. Hence, its loss amplifies the gradient flow in the memory state, and encourages the encoder to memorize only important information. Thus, we jointly train the two decoders, which share one encoder, by optimizing the sum of their losses. This approximates the training routine of Student B as the sole encoder has to perform well for both decoders. During inference, we only employ the pointer decoder due to its copying advantage over the closed-book decoder, similar to the situation of Student B being able to refer back to the passage during the test for best performance (but is still trained hard to do well in both situations). Figure (to be made) shows an example of our model generating a summary that covers the original passage with more saliency than the baseline model.
Empirically, we tested our 2-decoder model on the CNN/Daily Mail dataset Hermann et al. (2015); Nallapati et al. (2016), and it surpassed the strong pointer-generator baselines significantly on both ROUGE Lin (2004) and METEOR Denkowski and Lavie (2014) metrics. This holds true both for a cross-entropy baseline as well as a policy-gradient reinforcement learning setup Williams (1992). Our 2-decoder model also achieves improvements on a test-only DUC-2002 setup. We further show that this model achieved higher saliency (computed using blanks in the original CNN/Daily Mail cloze-Q&A dataset) than the pointer-generator baselines, and hence enabled the encoder to memorize more important information from the input document.
Image captioning Image captioning is the task of accurately describing the visual contents of images using natural language. It has many real-world applications, including assistance to the visually-impaired, text-based image retrieval, and human-machine interaction. The last few years have seen significant progress on this task Mao et al. (2014); Vinyals et al. (2015b); Xu et al. (2015); You et al. (2016); Yao et al. (2016); Vinyals et al. (2017), as demonstrated by the MSCOCO Lin et al. (2014) leaderboard updates. This progress has been achieved via a series of innovations in CNN, RNN, Encoder-Decoder architecture with attention, and reinforcement learning models, by using one or more human-annotated image-caption pair datasets like MSCOCO and Flikr30k. Models from most
Figure 1: Vanilla Encoder-Decoder model
works mentioned above are trained by maximum likelihood (teacher forcing). Such models suffers from exposure bias
In our work, we designed a framework based on a Conditional Generative Adversarial Network (CGAN) Mirza and Osindero (2014), which was originally proposed for conditioned image generation. We adapt this to conditioned language generation, where our Encoder-Decoder generator G models the conditional distribution of captions given an image, and our discriminator D tries to discriminate captions generated by G from human-generated captions given the same image. The generator is stabilized with maximum likelihood pretraining and then in the joint training phase, the generator is optimized to produce captions that D considers to be ‘true’.
Unlike image generation, where the generative function is continuous and deterministic, text gen-eration is a sequential (one word at a time) sampling procedure. This sampling process is non-differentiable, and hence we use policy gradient methods to jointly optimize our generator G with rewards from discriminator D (similar to Yu et al. (2017)). Finally, we also improve the speed and stability of a previous CGAN-based image captioning model Dai et al. (2017) (that focused on the task of increasing caption diversity): by discarding their Monte-Carlo rollouts and by using a mixed RL+ML loss function for the generator. Empirically, we present a series of experiments to show that our novel image captioning model significantly outperforms simple Encoder-Decoder baselines trained with the same number of image-caption pairs in terms of several metrics.
In the next section, we give a brief introduction to Encoder-Decoder model and its attention module. Then we present our novel models for summarization and image captioning in section 3 and 4, which are followed with related works, our experimental setup and results.
2
Encoder-Decoder Model
Encoder-Decoder model Sutskever et al. (2014) can be used for the task of translating data from source domain to a target domain. The translation starts with the encoder encoding the source data to a fixed size vector. This vector is then passed to the decoder as input, and the decoder generates the corresponding data in target domain. The architecture of the encoder and decoder can be neural networks of any form. For image captioning (image to text), the encoder is a convolutional neural network (CNN) that encodes the image to a feature map, and the decoder is a recurrent neural network (RNN) that generates the caption from this feature map. For text summarization or machine translation (text to text), both encoder and decoder are RNN. Fig. 1 shows an example of Encoder-Decoder model for text summarization.
2.1 Attention
The bottleneck of a vanilla Encoder-Decoder model as the one in Fig. 1 is the fact that decoder has to generate target domain data from a fixed-size vector only. The information that can be encoded in this vector is limited, and RNN encoder is known for its tendency to forget information from early
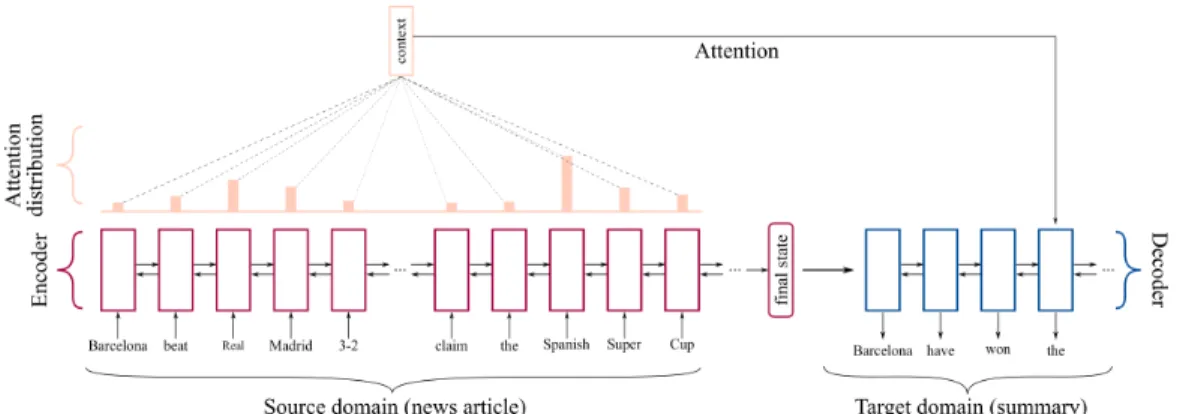
Figure 2: Encoder-Decoder model with attention
encoding steps (first sentence in a long article). Therefore, Bahdanau et al. (2014) augmented the Encoder-Decoder model with an shortcut connection between the decoder and encoder’s entire history of hidden state. This strategy further developed into the attention mechanism: the shortcut connection is analogous to attending source data at different encoding steps. This is enabled by an attention distribution that yields a weighted sum of encoder’s hidden states at all time steps, and incorporate this vector into decoder’s decision process. Fig. 2 provides a visualization of an Encoder-Decoder model with attention. In the next two sections, we describe the details of using Encoder-Decoder model with attention mechanism for two NLG tasks, summarization and image captioning.
3
Summarization Model
3.1 Pointer-Generator
The pointer-generator network proposed in See et al. (2017) is an Encoder-Decoder with attention mechanism. At each decoding step, the model can either sample a word from its vocabulary, or copy a word directly from the source passage. This is enabled by the attention mechanism Bahdanau et al. (2014), which includes a distribution aiover all encoding steps, and a context vector h∗t that is the
weighted sum of encoder’s hidden states. The probability of generating w at step t is modeled as below: eti= vTtanh(Whhi+ Wsst+ battn) ati= softmax(eti) h∗t =X i atihi (1)
where v, Wh, Ws, and battnare learnable parameters. hiis encoder’s hidden state at ithencoding
step, and stis decoder’s hidden state at tthdecoding step. The distribution ati can be seen as the
amount of attention at decode step t towards the ithencoder state. Therefore, the context vector h∗tis
the sum of the encoder’s hidden states weighted by attention distribution at. The context vector h∗tis concatenated with the decoder state stto produce the logits for the vocabulary distribution Pvocabat
decode step t:
Pvocabt = softmax(V2(V1[st, h∗t] + b1) + b2) (2)
where V1, V2, b1, b2are learnable parameters. To enable copying out-of-vocabulary words from
source text, a pointer similar to Vinyals et al. (2015a) is built upon the attention distribution and controlled by the generation probability pgen.
ptgen= σ(Uh∗h∗t+ Usst+ Uxxt+ bptr) Ppgt (w) = p t genP t vocab(w) + (1 − p t gen) X i:wi=w ati (3)
where Uh∗, Us, Ux, and bptrare learnable parameters. xtand stare the input token and decoder’s
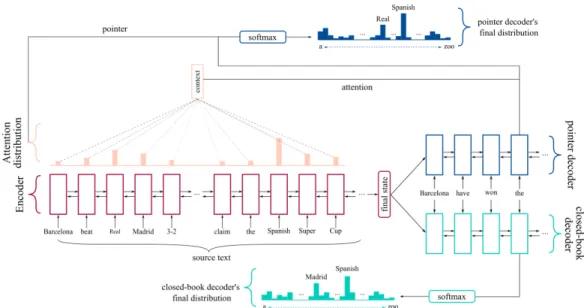
Figure 3: Our 2-decoder model with a pointer-generator decoder and a closed-book decoder.
model’s behavior of copying from text versus sampling from vocabulary. Here the word w comes from the extended vocabulary, which is the union of the preset vocabulary and all words appearing in the source passage. We train the model by minimizing the negative log-likelihood.
Lpg= 1 T T X t=1 − log Ppgt (w|x1:t) (4)
where T is the maximum decoding step.
See et al. (2017) also applies coverage mechanism to punish repetition. They maintained a coverage vector ctas the sum of attention distribution over all previous decoding steps 1 : t − 1. This vector is incorporated in calculating the attention distribution at current step t:
ct= t−1 X t0=0 at0 eti= vTtanh(Whhi+ Wsst+ Wccti+ battn) (5)
where Wsis a learnable parameter. They define the coverage loss covloss and combine it with the
primary loss Eqn. 4 to form a new loss function: losstloss=X i min(ati, cti) Ltotal= 1 T T X t=1
(− log Ppgt (w|x1:t) + λlosstcov)
(6)
3.2 Closed-Book Decoder
As shown in Bahdanau et al. (2014), the attention distribution aipartly depends on decoder’s hidden
state st, which is derived from decoder’s memory state ct. Therefore, if ctdoes not encode salient
information from the source passage, or encodes too much unimportant information, the decoder will have a hard time to locate the encoder’s states with attention. To enhance encoder’s memory so that only important information will be encoded into the memory state ct, we add a closed-book decoder
that shares the same encoder with the pointer decoder (see Fig. 3). During training, we optimize the sum of negative log likelihoods from the two decoders:
L = 1 T T X t=1 −(log Pt pg(w|x1:t) + log Pcbt(w|x1:t)) (7)
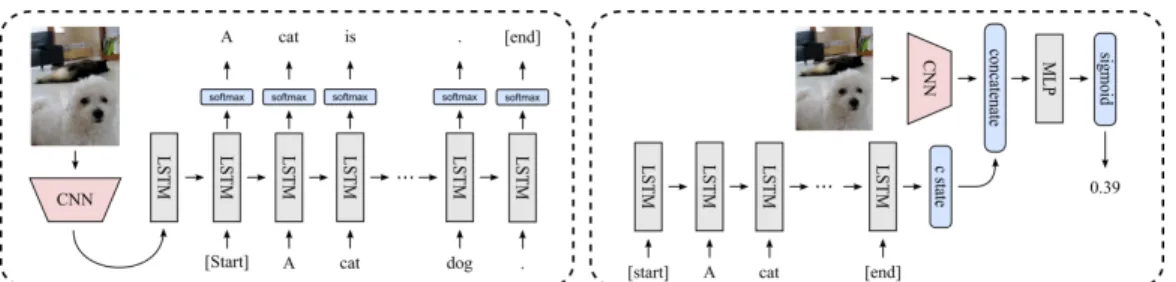
Figure 4: Conditional Generative Adversarial Network for image captioning. Generator is on the left and Discriminator on the right.
where Ppgtakes the form in Eqn. 3 and Pcbis the cross-entropy loss from the closed-book decoder.
3.3 Reinforcement Learning
Following Paulus et al. (2017), we also use a self-critical policy gradient training algorithm Rennie et al. (2016); Williams (1992) for both our baseline and 2-decoder model. For each iteration, we sample a summary ys = ws
1:T +1, and greedily generate a baseline summary ˆy, both according to
Ppg. Then these two summaries are fed to a reward function r that evaluates their closeness to the
ground-truth. We choose ROUGE-L scores as the reward function r as in previous work Paulus et al. (2017). The RL loss function is as follows:
Lrl= 1 T T X t=1 (r(ˆy) − r(ys)) log Ppgt (wt+1s |ws 1:t) (8)
We train our reinforced model using the mixture of Eqn. 8 and Eqn. 7. Paulus et al. (2017) showed that a pure RL objective would lead to summaries that receive high rewards but are not fluent. The mixed loss function is as followed.
Lmixed = γ ∗ Lrl+ (1 − γ) ∗ Lpg (9)
4
Image Captioning Model
4.1 Baseline
The baseline we used is a standard Encoder-Decoder model as in Vinyals et al. (2015b). At initial step, encoded image vector f (I) is fed into decoder LSTM and outputs an initial state. At each following step t = 1, ..., T − 1, the word wtfrom human-generated caption is fed into decoder, which outputs
a conditional distribution P(w∗t+1|w1:t, f (I)) for w∗t+1∈ vocabulary. Maximum likelihood optimizes
the parameters by minimizing the negative conditional log-likelihood LM L(I, w1:T) given N training
(I, w1:T) pairs: − N X n=1 T −1 X t=1 log P(wn,t+1|f (In), wn,1, ..., wn,t) (10)
We also incorporated the forehead mentioned attention mechanism Bahdanau et al. (2014); Xu et al. (2015) to get a stronger baseline.
4.2 A CGAN-based Framework
In a typical GAN setting, the generator G and discriminator D are trained jointly, as D tries to distinguish between real and generated data and G is updated in order to generate samples that D would classify as being real. In Conditional GAN Mirza and Osindero (2014), the generator takes random noise z and a condition, which is image I in our case, as input. The complete loss function L(Gθ, Dφ) to our model is:
Ec∈C(I)[log Dφ(I, c)] + E[log(1 − Dφ(I, Gθ(z|I)))] (11)
where C(I) denotes the set of human generated captions about image I. The second expectation is w.r.t. the sequential sampling procedure. Our overall C-GAN framework is represented in Fig. 4.
Generator After being trained with maximum likelihood and evaluated for later comparison, the baseline is used as the pre-trained generator of our GAN in the next phase of training. Dai et al. (2017) incorporated random noise z by concatenating it with the image embedding I. We simply discard z in our generator because we think the sequential sampling procedure has already introduced randomness into the generation process. Empirical results also show no difference in performance with z present or not.
Discriminator The goal of our discriminator D is, given an image-caption pair (I, c), to approxi-mate the probability of c being human-generated conditioned on I. D has a CNN and a LSTM to encode both visual and textual information. The output of CNN encoder and the final state of LSTM encoder is concatenated and fed into a 2-layer MLP to get the final score. Following Reed et al. (2016) and Dai et al. (2017), we update D using this loss function:
LD(φ) = α × Ec∈C(I)[− log Dφ(I, c)]
+ β × E[− log(1 − Dφ(I, Gθ(I)))]
+ γ × Ec∈Cc(I)[− log(1 − Dφ(I, c))]
(12)
where Cc(I) represents human-generated captions for images other than I.
Training G with Policy Gradient In order to overcome the difficulty of non-differentiability caused by sampling, we followed previous work Dai et al. (2017); Yu et al. (2017) to adopt Policy Gradient Sutton et al. (2000). In this setting, the generation of discrete words in a sentence is a sequence of actions. The decision to take what action is based on a Policy Network πθ, which outputs
a distribution of all possible actions at that step. In our case, πθis simply the generator Gθwithout the
last sampling step. After the entire sequence cT = w1:T is sampled, it is fed into discriminator Dφ
and outputs an approximate of the reward R(w1:T|I). This reward is used to calculate state-action
value Q(w1:t−1, wt|I): where Q(w1:t−1, wt|I) is the state-action value for a particular action wtat
statew1:t−1given image I, and should be calculated as follow:
Q(w1:t−1, wt|I) = Ewt+1:T[R(w1:t; wt+1:T|I)] (13)
Previous work Dai et al. (2017); Liu et al. (2016) used Monte Carlo Rollout to approximate this expectation. Here we simply use the terminal reward R(w1:T|I) as an one-sample estimate of Eqn. 13
with large variance. Experiment presented in Table 7 shows that without rollouts, our model is able to perform well enough in terms of performance on evaluation metrics. To compensate for the variance, for each image I we sample M sentences instead of just one. The detailed derivation is in supplementary materials and we just present the complete loss function of G as followed:
∇θJ (θ|In) = 1 N N X n=1 1 M M X m=1 T X t=2 [∇θlog πθ(wmt |w m 1:t−1, In) × Q(w1:t−1m , w m t |In)] (14)
Mixed Loss To alleviate the instability of approximating rewards with outputs from D, we reuse the loss function from maximum likelihood (ML) and update G w.r.t this mixed loss Wu et al. (2016); Paulus et al. (2017); Pasunuru and Bansal (2017):
LG(θ) = γJ (θ) + (1 − γ)LM L(θ) (15)
where LM Ltakes the form of Eqn. 10. This mixed loss encourages G to explore the action space and
select those actions that lead to higher scores from D through the reinforcement loss J (θ), but also ensures readability and fluency due to the cross-entropy loss LM L. Finally we have the loss function
for our generator G in the form of Eqn. 15 and discriminator D in the form of Eqn. 12.
5
Related Work
5.1 Summarization
Extractive and Abstractive Summarization Early models for automatic text summarization were usually extractive Jing and McKeown (2000); Knight and Marcu (2002); Clarke and Lapata (2008);
Filippova et al. (2015). For abstractive summarization, different early non-neural approaches were also applied, based on graphs Giannakopoulos (2009); Ganesan et al. (2010), discourse trees Gerani et al. (2014), syntactic parse trees Cheung and Penn (2014); Wang et al. (2016), and a combination of linguistic compression and topic detection Zajic et al. (2004). Recent neural-network models have tackled abstractive summarization using more advanced methods (e.g., hierarchical, coverage, distraction, etc.) Rush et al. (2015); Chopra et al. (2016); Nallapati et al. (2016); Chen et al. (2016); Takase et al. (2016). In order to usher the abstractive approach into the domain of long-text sum-marization, Nallapati et al. (2016) adapted the CNN/Daily Mail Hermann et al. (2015) dataset for long-text summarization, and provided an abstractive baseline Nallapati et al. (2016). The same author then published an extractive model in another work Nallapati et al. (2017) that significantly outperformed the abstractive baseline in terms of ROUGE scores.
Pointer Network Pointer network Vinyals et al. (2015a) is a kind of Encoder-Decoder network that models the distribution of elements from input sequence using attention Bahdanau et al. (2014) and is therefore able to copy those input elements to output directly. It is useful for automatic text summa-rization because summaries often need to copy/contain a large number of words that have appeared in the source text. This provides the advantages of both extractive and abstractive approaches, and usually includes a gating function to model the distribution for the extended vocabulary including the preset vocabulary and words from the source text Zeng et al. (2016); Nallapati et al. (2016); Gu et al. (2016); Gulcehre et al. (2016); Miao and Blunsom (2016); See et al. (2017).
Reinforcement Learning Teacher forcing style maximum likelihood (ML) training suffers from exposure bias Bengio et al. (2015), so recent work instead applies reinforcement learning style policy gradient algorithms (REINFORCE Williams (1992)) to directly optimize on metric scores Henß et al. (2015); Paulus et al. (2017).
5.2 Image Captioning
Image Captioning Generating natural language description for images has been studied comprehen-sively as a task that lies at the intersection of Computer Vision and Natural Language Processing. Recently, methods based on Deep Neural Network in both fields pushed the boundary of state-of-art image captioning result. Particularly, Convolutional Neural Network (CNN) achieved great improve-ment on image classification (Krizhevsky et al. (2012)) and inspired a huge branch of research on its properties. Recent works (Szegedy et al.; He et al. (2016); Szegedy et al. (2016)) continuously improve on the structure of CNN in both depth and width, and achieved super-human results on Ima-geNet(Deng et al. (2009)) image classification task. These works fuel the study on image captioning by providing stronger image model that can accurately capture visual contents and features from images. Encoder-Decoder (Seq2Seq) paradigm Sutskever et al. (2014), with attentionBahdanau et al. (2014), as well as policy gradient approaches Liu et al. (2016) have achieved significant improvements in supervised setups.
GANs and CGANs Generative Adversarial Network (GAN) was introduced in Goodfellow et al. (2014) to generate real-looking images. It has two components: a generative part G that, given a random noise z, generate an image that approximates the real-data distribution, and a discriminative part D that models the probability of an image being real as opposed to being generated by G. Throughout this adversarial training, G gradually learns to generate real-looking samples that follow the data distribution.
As one of the many variants, a Condition GAN (CGAN) Mirza and Osindero (2014) enabled directed data generation by providing an extra condition to generator, and has been used for image captioning Dai et al. (2017) and image-to-image translation Isola et al. (2016). Recent works extended the usage of GAN and CGAN to generating natural language words. Yu et al.Yu et al. (2017) first applied GAN to generate sequential data by using Policy Gradient with Monte Carlo Rollouts to back-propagate the gradients to their generator. However, their experiments were mostly conducted on synthetic data. More relevantly, Dai et al. Dai et al. (2017) proposed an image captioning model based on CGAN. Their work aimed at naturalness and diversity of the captions generated, at the cost of lower scores in basically all metrics.
6
Experiments
6.1 Dataset
For summarization, we use CNN/Daily Mail dataset Hermann et al. (2015); Nallapati et al. (2016), which is a large-scale, long-paragraph, abstractive summarization dataset. It has online news articles (781 tokens or ~40 sentences on average) with paired human-generated summaries (56 tokens or 3.75 sentences on average). The entire dataset has 287,226 training pairs, 13,368 validation pairs and 11,490 test pairs. We use the same version of data as See et al. (2017), which is the original text with no preprocessing to replace named entities. We also present results on a DUC-2002 test-only setup, where we reused our model trained on CNN/Daily Mail to generated summaries for DUC-2002, which contains 566 news articles with corresponding human-generated summaries.
For image captioning, our experiments were conducted on MSCOCO dataset Lin et al. (2014), which contains 82,081 training images and 40,137 validation images and each image has 5 human-generated captions. To better facilitate the training, we rearranged the dataset and produced a labeled training set of ~116,000 images and a validation set of ~6000 images. We evaluated the model on the MSCOCO hidden (non-public captions) test set that contains ~41,000 images.
6.2 Experimental setup
Summarization We trained our models on CNN/Daily Mail dataset. Our model is directly adapted from the source code of See et al. (2017), and we kept most of their settings for our model. The model is first trained to converge, and is trained with coverage loss See et al. (2017) for another 3k steps. Both our encoder and decoder LSTMs have hidden state dimension of 256, and the word embedding dimension is set to 128. Our preset vocabulary is same for source texts and target summaries, which has a total of 50k word tokens including special tokens for start, end, and out-of-vocabulary(OOV) signals. These word embeddings are learned from scratch instead of pretrained as in Nallapati et al. (2016). All of our teacher forcing models reported are trained with Adagrad Duchi et al. (2011) with learning rate 0.15 and an initial accumulator value of 0.1. The gradients are clipped to maximum norm of 2.0. Same as reported in See et al. (2017), we found Adagrad to be able to yield the best result, while Adam Kingma and Ba (2014) provides faster convergence in early phase of the training. The batch size is set to 16. Our model with closed-book decoder converged in about 270,000 iterations and achieved best result on validation set with another 3000 iterations with coverage added. This is similar to the numbers reported in See et al. (2017). Then we restore the best checkpoint and apply policy gradient. For this phase of training, we choose Adam optimizer Kingma and Ba (2014) because of its time efficiency, and the learning rate is set to 0.000001.
Image captioning For the encoder CNN we use an Inception-V3 Szegedy et al. (2016) pre-trained on ImageNet. The decoder is an one-layer LSTM with state size of 512 for both c and h. Attention mechanism Bahdanau et al. (2014); Xu et al. (2015) is incorporated to get a stronger baseline. Each symbol in the vocabulary is represented as a 512 dimensional dense word embedding vector that is randomly initialized.
In summary, we first pre-train G and D using maximum likelihood on labeled set until they converge. It is important to early stop the training before they overfit. Then we start to train G and D jointly by applying gradient descent on them alternatively. Note that G and D share the same word embedding map. This map is updated along with G in pre-training, and with both G and D in joint GAN-training. We do not update the embedding map during pre-training of D as it will break G.
We used Adam optimizer Kingma and Ba (2014) for both G and D. The learning rate is set to 0.0001 at pre-training of G and D, but we use a smaller value (0.00001 ~0.000001) to update G at joint training. The M in Eqn. 14 is set to 1, and γ in Eqn. 15 is set to 0.99.
7
Results
7.1 Summarization
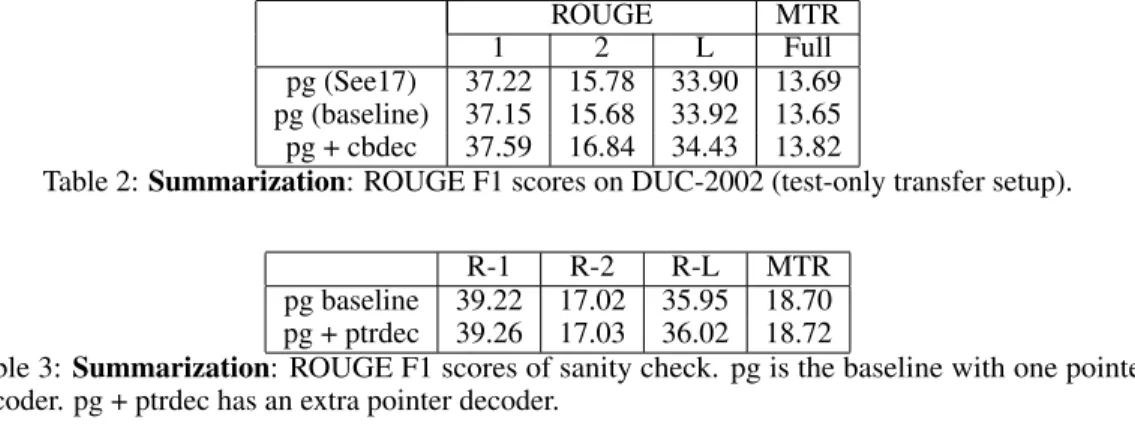
We report our evaluation results on CNN/Daily Mail dataset in Table 1. As shown, our pointer-generator with the extra closed-book decoder (pg+cbdec) receives significantly higher scores than the original pointer-generator (pg) from See et al. (2017) and our own pg baseline, in all ROUGE Lin
Figure 5: Summarization: Baseline makes factual errors and repeated itself (red), while our closed-book decoder model covers information that is not mentioned by baseline (green), while summarizing from a number of places in the source passage (blue).
ROUGE MTR 1 2 L Full pg (See17) 39.53 17.28 36.38 18.72 lead-3 (See17) 40.57 17.70 36.57 22.21 RL†(Paulus17) 39.87 15.82 36.90 pg (baseline) 39.22 17.02 35.95 18.70 pg + cbdec 40.05 17.66 36.73 19.48 RL + pg 39.67 17.36 36.45 20.84 RL + pg + cbdec 40.43 17.84 36.94 21.41
Table 1: Summarization: ROUGE F1 and METEOR scores on the test set. "pg+cbdec" is our adapted pointer-generator with closed-book decoder. Coverage mechanism is used in all models except the RL summ and lead-3 baseline. The result marked with † was trained and evaluated on the anonymized version of the data.
(2004) and METEOR Denkowski and Lavie (2014) metrics.1 In the reinforced setting, our 2-decoder
model (RL+pg+cbdec) again outperforms our strong RL baseline by a considerable margin (stat. significance of p < 0.001). In ROUGE-L score, our teacher-forcing model even beats the lead-3 baseline that generates summaries by selecting the first 3 sentences from the source text. We also evaluated our 2-decoder model on the DUC-2002 test-only transfer setup by decoding the entire dataset with our model pretrained on CNN/Daily Mail, again achieving some improvements (shown in Table 2) over the single-decoder baseline as well as See et al. (2017).
To further validate and sanity-check that the improvement is the result of the inclusion of our closed-book decoder and not due to some trivial effect of having two decoders, we ran a variant of our model with two duplicated attention-pointer decoders. Table 3 shows that this variant yields roughly the same scores as the single-decoder baseline, and hence proves that the improvements of our model are indeed achieved by the closed-book decoder.2
Saliency: We also evaluate our model’s ability to encode and address the most salient information from the source text. For this, we designed a keyword-matching test based on the original CNN/Daily Mailcloze blank-filling task. Each news article in the dataset is paired with a few extracted keywords that represent the most salient entities, including names, locations, etc. We count the number of
1
All of our improvements in Table 1 are statistically significant with p < 0.001 (using bootstrapped randomization test Efron and Tibshirani (1994)) and have a 95% ROUGE-significance level of at most ±0.25.
2
It is also important to point out that our model is not a 2-decoder ensemble, because we only use the pointer decoder during inference.
ROUGE MTR
1 2 L Full
pg (See17) 37.22 15.78 33.90 13.69 pg (baseline) 37.15 15.68 33.92 13.65 pg + cbdec 37.59 16.84 34.43 13.82
Table 2: Summarization: ROUGE F1 scores on DUC-2002 (test-only transfer setup).
R-1 R-2 R-L MTR
pg baseline 39.22 17.02 35.95 18.70 pg + ptrdec 39.26 17.03 36.02 18.72
Table 3: Summarization: ROUGE F1 scores of sanity check. pg is the baseline with one pointer decoder. pg + ptrdec has an extra pointer decoder.
keywords that appear in our generated summaries, and found that the output of our best teacher-forcing model (pg+cbdec) contains 62.1% of those keywords, while the output provided by See et al. (2017) has only 60.5% covered. Our reinforced model (RL+pg+cbdec) further increases this percentage to 67.6%. The full comparison is shown in Table 4. This again demonstrates our model encoder’s ability to memorize important information and address them properly in the generated summary.
7.2 Image captioning
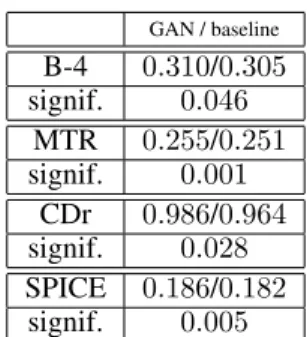
The evaluation results of our experiments is presented in Table 5. Compared to the baselines trained with maximum likelihood, our CGAN-based model generates captions that received considerably higher score in all metrics. Table 6 reports statistical significance levels3of these various
improve-ments, which is showed to be significant in all metrics.
Speed and Result Comparison with Rollouts Model Table 7 compares the CIDEr scores as well as the speed of the Monte Carlo rollouts model used by Dai et al. (2017), against our model without these rollouts (see Sec. 4.2). As shown, our model can achieve better performance at higher speeds.
8
Conclusion
In this thesis we augmented a standard Encoder-Decoder model for two Natural Language Generation tasks. For summarization, we added a second decoder that forces the encoder to present better representation in its memory state. We showed that our proposed model significantly outperforms the state-of-the-art pointer-generator baselines in terms of ROUGE and METEOR scores, as well as saliency (in both a teacher-forcing setup and a reinforcement learning setup). It also achieves improvements in a test-only transfer setup on the DUC-2002 dataset. For image captioning, we trained a discriminator along with the Encoder-Decoder generator, and optimize the entire model adversarially. Experiments showed that our CGAN-based model successfully surpassed baseline in terms of metric scores with statistically significant improvements. Overall, our experiments showed that designing more intuitive architecture is a promising direction for future studies in neural network and its application.
Acknowledgments
I’m grateful to have Prof. Bansal as my advisor. You accepted me into the group when I had no experience in research and NLP, and you kept pushing me to my potential and showed me how to be a qualified researcher (although I’m still not a very good one) that works hard and thinks critically. To Prof. Pozefsky, thanks for your kind advices and mentorship that dated back to the COMP523. You always inspire me and made me a better presenter during the tech-talk.
3
Stat. signif. is based on bootstrap test Efron and Tibshirani (1994); we split our val set into a smaller 2k val set and an internal 4k test set, because the CodaLab evaluation server does not provide individual scores of its test set captions. Here the model is tuned on the validation set of 2k images, following the same procedure described above.
saliency pg (See17) 60.4% pg (baseline) 59.6% pg + cbdec 62.1% RL + pg 65.1% RL + pg + cbdec 67.6%
Table 4: Summarization: Saliency scores.
BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR CIDEr
Vinyals et al. (2015b) 0.713 0.542 0.407 0.309 0.254 0.943 Mao et al. (2014) 0.716 0.545 0.404 0.299 0.252 0.917 Xu et al. (2015) 0.712 0.537 0.398 0.295 0.247 0.915 You et al. (2016) 0.731 0.565 0.424 0.316 0.250 0.943 baseline 0.712 0.537 0.398 0.295 0.247 0.915 GAN 0.711 0.538 0.400 0.299 0.250 0.934
Table 5: Image captioning: Results on MSCOCO test set.
And finally for my beloved friends and family members, thanks for the huge supports during my four years at UNC. You guys are always with me throughout my ups and downs. Hopefully my work can make you proud.
References
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. 2016. Spice: Semantic propositional image caption evaluation. In European Conference on Computer Vision, pages 382–398. Springer.
D. Bahdanau, K. Cho, and Y. Bengio. 2014. Neural Machine Translation by Jointly Learning to Align and Translate. ArXiv e-prints.
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. 2015. Scheduled sampling for sequence prediction with recurrent neural networks. In Advances in Neural Information Processing Systems, pages 1171–1179.
Qian Chen, Xiaodan Zhu, Zhenhua Ling, Si Wei, and Hui Jiang. 2016. Distraction-based neural networks for modeling documents. In IJCAI.
Jackie Chi Kit Cheung and Gerald Penn. 2014. Unsupervised sentence enhancement for automatic summarization. In EMNLP, pages 775–786.
Sumit Chopra, Michael Auli, and Alexander M Rush. 2016. Abstractive sentence summarization with attentive recurrent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 93–98.
James Clarke and Mirella Lapata. 2008. Global inference for sentence compression: An integer linear programming approach. Journal of Artificial Intelligence Research, 31:399–429.
Bo Dai, Dahua Lin, Raquel Urtasun, and Sanja Fidler. 2017. Towards diverse and natural image descriptions via a conditional gan. arXiv preprint arXiv:1703.06029.
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pages 248–255. IEEE.
Michael Denkowski and Alon Lavie. 2014. Meteor universal: Language specific translation evaluation for any target language. In Proceedings of the ninth workshop on statistical machine translation, pages 376–380.
John Duchi, Elad Hazan, and Yoram Singer. 2011. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul):2121–2159.
GAN / baseline B-4 0.310/0.305 signif. 0.046 MTR 0.255/0.251 signif. 0.001 CDr 0.986/0.964 signif. 0.028 SPICE 0.186/0.182 signif. 0.005
Table 6: Image captioning: Statistical significance levels (p values in bootstrap test) for our GAN versus baseline comparison, on BLEU4, METEOR, CIDEr, and SPICE Anderson et al. (2016) metrics.
CIDEr Min/epoch
GAN 0.941 71
GANrollouts 0.926 281
Table 7: Image captioning: CIDEr scores and speed (minutes per epoch) on a single GPU in the presence of rollouts or not.
Bradley Efron and Robert J Tibshirani. 1994. An introduction to the bootstrap. CRC press.
Katja Filippova, Enrique Alfonseca, Carlos A Colmenares, Lukasz Kaiser, and Oriol Vinyals. 2015. Sentence compression by deletion with lstms. In EMNLP, pages 360–368.
Kavita Ganesan, ChengXiang Zhai, and Jiawei Han. 2010. Opinosis: a graph-based approach to abstractive summarization of highly redundant opinions. In Proceedings of the 23rd international conference on computational linguistics, pages 340–348. ACL.
Shima Gerani, Yashar Mehdad, Giuseppe Carenini, Raymond T Ng, and Bita Nejat. 2014. Abstractive summarization of product reviews using discourse structure. In EMNLP, volume 14, pages 1602– 1613.
George Giannakopoulos. 2009. Automatic summarization from multiple documents. Ph. D. disserta-tion.
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 27, pages 2672–2680. Curran Associates, Inc.
Jiatao Gu, Zhengdong Lu, Hang Li, and Victor OK Li. 2016. Incorporating copying mechanism in sequence-to-sequence learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics.
Caglar Gulcehre, Sungjin Ahn, Ramesh Nallapati, Bowen Zhou, and Yoshua Bengio. 2016. Point-ing the unknown words. In ProceedPoint-ings of the 54th Annual MeetPoint-ing of the Association for Computational Linguistics.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778.
Stefan Henß, Margot Mieskes, and Iryna Gurevych. 2015. A reinforcement learning approach for adaptive single-and multi-document summarization. In GSCL, pages 3–12.
Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 2015. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems, pages 1693–1701.
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. 2016. Image-to-image translation with conditional adversarial networks. arXiv preprint arXiv:1611.07004.
Hongyan Jing and Kathleen R. McKeown. 2000. Cut and paste based text summarization. In Proceedings of the 1st North American Chapter of the Association for Computational Linguistics Conference, NAACL 2000, pages 178–185, Stroudsburg, PA, USA. Association for Computational Linguistics.
Diederik Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Kevin Knight and Daniel Marcu. 2002. Summarization beyond sentence extraction: A probabilistic approach to sentence compression. Artificial Intelligence, 139(1):91–107.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105.
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out: Proceedings of the ACL-04 workshop, volume 8. Barcelona, Spain.
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context. Springer International Publishing, Cham.
S. Liu, Z. Zhu, N. Ye, S. Guadarrama, and K. Murphy. 2016. Improved Image Captioning via Policy Gradient optimization of SPIDEr. ArXiv e-prints.
Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, Zhiheng Huang, and Alan Yuille. 2014. Deep captioning with multimodal recurrent neural networks (m-rnn). arXiv preprint arXiv:1412.6632.
Yishu Miao and Phil Blunsom. 2016. Language as a latent variable: Discrete generative models for sentence compression. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.
M. Mirza and S. Osindero. 2014. Conditional Generative Adversarial Nets. ArXiv e-prints. Ramesh Nallapati, Feifei Zhai, and Bowen Zhou. 2017. Summarunner: A recurrent neural network
based sequence model for extractive summarization of documents. In AAAI, pages 3075–3081. Ramesh Nallapati, Bowen Zhou, Ça˘glar G˙ulçehre, Bing Xiang, et al. 2016. Abstractive text
sum-marization using sequence-to-sequence rnns and beyond. In Computational Natural Language Learning.
Ramakanth Pasunuru and Mohit Bansal. 2017. Reinforced video captioning with entailment rewards. arXiv preprint arXiv:1708.02300.
Romain Paulus, Caiming Xiong, and Richard Socher. 2017. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304.
Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, and Honglak Lee. 2016. Generative adversarial text-to-image synthesis. In Proceedings of The 33rd International Conference on Machine Learning.
Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jarret Ross, and Vaibhava Goel. 2016. Self-critical sequence training for image captioning. arXiv preprint arXiv:1612.00563.
Alexander M Rush, Sumit Chopra, and Jason Weston. 2015. A neural attention model for abstractive sentence summarization. In Empirical Methods in Natural Language Processing.
Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics.
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pages 3104–3112.
Richard S Sutton, David A McAllester, Satinder P Singh, and Yishay Mansour. 2000. Policy gradient methods for reinforcement learning with function approximation. In Advances in neural information processing systems, pages 1057–1063.
C Szegedy, W Liu, Y Jia, P Sermanet, S Reed, and D Anguelov. & rabinovich, a.(2015). going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9.
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. 2016. Re-thinking the inception architecture for computer vision. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Sho Takase, Jun Suzuki, Naoaki Okazaki, Tsutomu Hirao, and Masaaki Nagata. 2016. Neural headline generation on abstract meaning representation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1054–1059.
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. 2015a. Pointer networks. In Advances in Neural Information Processing Systems, pages 2692–2700.
Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. 2015b. Show and tell: A neural image caption generator. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. 2017. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE transactions on pattern analysis and machine intelligence, 39(4):652–663.
Mingxuan Wang, Zhengdong Lu, Hang Li, and Qun Liu. 2016. Memory-enhanced decoder for neural machine translation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics.
Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforce-ment learning. Machine learning, 8(3-4):229–256.
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144.
K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhutdinov, R. Zemel, and Y. Bengio. 2015. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. ArXiv e-prints. T. Yao, Y. Pan, Y. Li, Z. Qiu, and T. Mei. 2016. Boosting Image Captioning with Attributes. ArXiv
e-prints.
Quanzeng You, Hailin Jin, Zhaowen Wang, Chen Fang, and Jiebo Luo. 2016. Image captioning with semantic attention. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Lantao Yu, Weinan Zhang, Jun Wang, and Yong Yu. 2017. Seqgan: Sequence generative adversarial
nets with policy gradient. In AAAI, pages 2852–2858.
David Zajic, Bonnie Dorr, and Richard Schwartz. 2004. Bbn/umd at duc-2004: Topiary. In Proceedings of the HLT-NAACL 2004 Document Understanding Workshop, Boston, pages 112– 119.
Wenyuan Zeng, Wenjie Luo, Sanja Fidler, and Raquel Urtasun. 2016. Efficient summarization with read-again and copy mechanism. arXiv preprint arXiv:1611.03382.