Contents lists available atScienceDirect
Journal of Computer and System Sciences
www.elsevier.com/locate/jcssAgnostic active learning
✩
Maria-Florina Balcan
a, Alina Beygelzimer
b,
∗
, John Langford
c aCarnegie Mellon University, Pittsburgh, PA 15213, USAbIBM T. J. Watson Research Center, Hawthorne, NY 10532, USA cYahoo! Research, New York, NY 10011, USA
a r t i c l e i n f o a b s t r a c t
Article history: Received 1 June 2007
Received in revised form 18 June 2008 Available online 18 July 2008 Keywords:
Active learning Agnostic setting Sample complexity Linear separators
We state and analyze the first active learning algorithm that finds an
-optimal hypothesis in any hypothesis class, when the underlying distribution has arbitrary forms of noise. The algorithm, A2 (for Agnostic Active), relies only upon the assumption that it has
access to a stream of unlabeled examples drawni.i.d. from a fixed distribution. We show that A2achieves an exponential improvement (i.e., requires onlyO(ln1)samples to find an
-optimal classifier) over the usual sample complexity of supervised learning, for several settings considered before in the realizable case. These include learning threshold classifiers and learning homogeneous linear separators with respect to an input distribution which is uniform over the unit sphere.
©2008 Elsevier Inc. All rights reserved.
1. Introduction
Traditionally, machine learning has focused on the problem of learning a task from labeled examples only. In many applications, however, labeling is expensive while unlabeled data is usually ample. This observation motivated substantial work on properly using unlabeled data to benefit learning, and there are many examples showing that unlabeled data can significantly help [4,9,10,27,29,31–33].
There are two main frameworks for incorporating unlabeled data into the learning process. The first framework is semi-supervised learning [17], where in addition to a set of labeled examples, the learning algorithm can also use a (usually larger) set of unlabeled examples drawn at random from the same underlying data distribution. In this setting, unlabeled data becomes useful under additional assumptions and beliefs about the learning problem. For example, transductive SVM learning [27] assumes that the target function cuts through low density regions of the space, while co-training [10] assumes that the target should be self-consistent in some way. Unlabeled data is potentially useful in this setting because it allows one to reduce the search space to a set which is a-priori reasonable with respect to the underlying distribution.
The second setting, which is the main focus of this paper, isactive learning[18,21]. Here the learning algorithm is allowed to draw random unlabeled examples from the underlying distribution and ask for the labels of any of these examples. The hope is that a good classifier can be learned with significantly fewer labels by actively directing the queries to informative examples.
As in passive supervised learning, but unlike in semi-supervised learning, the only prior belief about the learning problem here is that the target function (or a good approximation of it) belongs to a given concept class. For some concept classes such as thresholds on the line, one can achieve an exponential improvement over the usual sample complexity of supervised learning, under no additional assumptions about the learning problem [18,21]. In general, the speedups achievable in active
✩ A preliminary version of this paper appeared in the 23rd International Conference on Machine Learning, ICML 2006.
*
Corresponding author.E-mail addresses:[email protected](M.-F. Balcan),[email protected](A. Beygelzimer),[email protected](J. Langford). 0022-0000/$ – see front matter ©2008 Elsevier Inc. All rights reserved.
learning depend on the match between the data distribution and the hypothesis class, and therefore on the target hypothesis in the class. The most noteworthy non-trivial example of improvement is the case of homogeneous (i.e., through the origin) linear separators, when the data is linearly separable and distributed uniformly over the unit sphere [21,23,24]. There are also simple examples where active learning does not help at all, even in the realizable case [21].
Most of the previous work on active learning has focused on the realizable case. In fact, many of the existing active learn-ing strategies arenoise seekingon natural learning problems, because the process of actively finding an optimal separation between one class and another often involves label queries for examples close to the decision boundary, and such examples often used a large conditional noise rate (e.g., due to a mismatch between the hypothesis class and the data distribution). Thus the most informative examples are also the ones that are typically the most noise-prone.
Consider an active learning algorithm which searches for the optimal threshold on an interval using binary search. This example is often used to demonstrate the potential of active learning in the noise-free case when there is a perfect threshold separating the classes [18]. Binary search needs O
(
ln1)
labeled examples to learn a threshold with error less than, while learning passively requires O
(
1)
labels. A fundamental drawback of this algorithm is that a small amount of adversarial noise can force the algorithm to behave badly. Is this extreme brittleness to small amounts of noise essential? Can an exponential decrease in sample complexity be achieved? Can assumptions about the mechanism producing noise be avoided? These are the questions addressed here.1.1. Previous work on active learning
There has been substantial work on active learning under additional assumptions. For example, the Query by Committee analysis [24] assumes realizability (i.e., existence of a perfect classifier in a known set), and a correct Bayesian prior on the set of hypotheses. Dasgupta [21] has identified sufficient conditions (which are also necessary against an adversarially chosen distribution) for active learning given only the additional realizability assumption. There are several other papers that assume only realizability [20,23]. If there exists a perfect separator amongst hypotheses, any informative querying strategy can direct the learning process without the need to worry about the distribution it induces—any inconsistent hypothesis can be eliminated based on a single query, regardless of which distribution this query comes from. In the agnostic case, however, a hypothesis that performs badly on the query distribution may well be the optimal hypothesis with respect to the input distribution. This is the main challenge in agnostic active learning that is not present in the non-agnostic case. Burnashev and Zigangirov [14] allow noise, but require a correct Bayesian prior on threshold functions. Some papers require specific noise models such as a constant noise rate everywhere [16] or Tsybakov noise conditions [5,15].
The membership-query setting [1,2,13,26] is similar to active learning considered here, except that no unlabeled data is given. Instead, the learning algorithm is allowed to query examples of its own choice. This is problematic in several applications because natural oracles, such as hired humans, have difficulty labeling synthetic examples [8]. Ulam’s Problem (quoted in [19]), where the goal is find a distinguished element in a set by asking subset membership queries, is also related. The quantity of interest is the smallest number of such queries required to find the element, given a bound on the number of queries that can be answered incorrectly. But both types of results do not apply here since an active learning strategy can only buy labels of the examples it observes. For example, a membership query algorithm can be used to quickly find a separating hyperplane in a high-dimensional space. An active learning algorithm cannot do so when the data distribution does not support queries close to the decision boundary.
1.2. Our contributions
This paper presents the firstagnosticactive learning algorithm, A2. The only necessary assumption is that the algorithm has access to a stream of examples drawni.i.d.from some fixed distribution. No additional assumptions are made about the mechanism producing noise (e.g., class/target misfit, fundamental randomization, adversarial situations). The main contribu-tion of this paper is to prove the feasibility of agnostic active learning.
Two comments are in order:
(1) We define the noise rate of a hypothesis class H with respect to a fixed distribution P on labeled examples as the minimum error rate of any hypothesis in H on P (see section 2 for a formal definition). Note that for the special case of so-calledlabel noise(where for each example, the probability that it is mislabeled with respect to the best hypothesis is a fixed constant) these definitions coincide.
(2) We regard unlabeled data as being free so as to focus exclusively on the question of whether or not agnostic active learning is possible at all. Substantial follow-up work to this paper has successfully optimized unlabeled data usage to be on the same order as passive learning [22].
A2 is provably correct (for any 0
<
<
1/
2 and 0< δ <
1/
2, it outputs an-optimal hypothesis with probability at least 1
−
δ
) and it is never harmful (it never requires significantly more labeled examples than batch learning). A2provides exponential sample complexity reductions in several settings previously analyzed without noise or with known noise con-ditions. This includes learning threshold functions with small noise with respect toand hypothesis classes consisting of
homogeneous (through the origin) linear separators with the data distributed uniformly over the unit sphere in
R
d. The last example has been the most encouraging theoretical result so far in the realizable case [23].The A2 analysis achieves an almost contradictory property: for some sets of classifiers, an
-optimal classifier can be output with fewer labeled examples than are needed to estimate the error rate of the chosen classifier with precision
from random examples only.
1.3. Lower bounds
It is important to keep in mind that the speedups achievable with active learning depend on the match between the distribution over example-label pairs and the hypothesis class, and therefore on the target hypothesis in the class. Thus one should expect the results to be distribution-dependent. There are simple examples where active learning does not help at all in the model analyzed in this paper, even if there is no noise [21]. These lower bounds essentially result from an “aliasing” effect and they are unavoidable in the setting we analyze in this paper (where we bound the number of queries an algorithm makes before itcan proveit has found a good function).1
In the noisy situation, the target function itself can be very simple (e.g., a threshold function), but if the error rate is very close to 1
/
2 in a sizeable interval near the threshold, then no active learning procedure can significantly outperform passive learning. In particular, in the pure agnostic setting onecannothope to achieve speedups when the noise rateη
is large, due to a lower bound ofΩ(
η22
)
on the sample complexity of any active learner [28]. However, under specific noise models (such as a constant noise rate everywhere [16] or Tsybakov noise conditions [5,15]) and for specific classes, one can still show significant improvement over supervised learning.1.4. Structure of this paper
Preliminaries and notation are covered in Section 2, then A2 is presented in Section 3. Section 3.1 proves that A2 is correct and Section 3.2 proves it is never harmful (i.e., it never requires significantly more samples than batch learning). Threshold functions such as ft
(
x)
=
I(
x>
t)
and homogeneous linear separators under the uniform distribution over the unit sphere are analyzed in Section 4. Here and in the rest of the paper, I(
·
)
is the indicator function which is 1 if its argument is true, and 0 otherwise. Conclusions, a discussion of subsequent work, and open questions are covered in Section 5. 2. PreliminariesWe consider a binary agnostic learning problem specified as follows. Let X be an instance space and Y
= {−
1,
1}
be the set of possible labels. Let H be the hypothesis class, a set of functions mapping from X to Y. We assume there is a distribution D over instances in X, and that the instances are labeled by a possibly randomized oracle O. The ora-cle O can be thought of as taking an unlabeled example x in, choosing a biased coin based on x, then flipping it find the label−
1 or 1. The error rate of a hypothesis h with respect to a distribution P over X×
Y is defined as errP(
h)
=
Prx,y∼P[
h(
x)
=
y]
. The error rate errP(
h)
is not generally known since P is unknown, however the empirical versionerrP
(
h)
=
Prx,y∼S[
h(
x)
=
y] =
1Sx,y∈SI(
h(
x)
=
y)
is computable based upon an observed sample set S. Letη
=
minh∈H
(
errD,O(
h))
denote the minimum error rate of any hypothesis in H with respect to the distribution(
D,
O)
induced by D and the labeling oracle O. The goal is to find an-optimal hypothesis, i.e. a hypothesish
∈
H with errD,O(
h)
withinof
η
, whereis some target error.
The algorithm A2 relies on a subroutine, which computes a lower bound LB
(
S,
h, δ)
and an upper bound UB(
S,
h, δ)
on the true error rate errP(
h)
ofhby using a sample S of examples drawni.i.d.from P. Each of these bounds must hold for allhsimultaneously with probability at least 1−
δ
. The subroutine is formally defined below.Definition 1.A subroutine for computing LB
(
S,
h, δ)
and UB(
S,
h, δ)
is said to belegalif for all distributions P over X×
Y, for all 0< δ <
1/
2 andm∈
N
,LB
(
S,
h, δ)
errP(
h)
UB(
S,
h, δ)
holds for allh
∈
Hsimultaneously, with probability 1−
δ
over the draw of Saccording to Pm.Classic examples of such subroutines are the (distribution independent) VC bound [34] and the Occam Razor bound [11], or the newer data dependent generalization bounds such as those based on Rademacher Complexities [12]. For concreteness, a VC bound subroutine is stated in Appendix A.
1 In recent work, Balcan et al. [6,7] have shown that in an asymptotic model for Active Learning where one bounds the number of queries the algorithm makes before it finds a good function (i.e. one of arbitrarily small error rate), but not the number of queries before it can prove or it knows it has found a good function, one can obtain significantly better bounds on the number of label queries required to learn.
seti←1,Di←D,Hi←H,Hi−1←H,Si−1← ∅, andk←1. (1)while DisagreeD(Hi−1)( min
h∈Hi−1 UB(Si−1,h, δk)− min h∈Hi−1 LB(Si−1,h, δk)) >
set Si← ∅,Hi←Hi,k←k+1 (2)while DisagreeD(H i) 1 2DisagreeD(Hi) ifDisagreeD(Hi)(min h∈HiUB(Si,h, δk)−hmin∈HiLB(Si,h, δk))
(∗)returnh=argminh∈HiUB(Si,h, δk).
else Si=rejection sample 2|Si| +1 samplesxfromDsatisfying ∃h1,h2∈Hi:h1(x)=h2(x). Si←Si∪ {(x,O(x)):x∈Si},k←k+1 (∗∗)Hi= {h∈Hi: LB(Si,h, δk, ) min h∈Hi UB(Si,h, δk)},k←k+1 end if end while Hi+1←Hi,Di+1←Direstricted to{x:∃h1,h2∈Hi:h1(x)=h2(x)} i←i+1 end while
returnh=argminh∈Hi−1UB(Si−1,h, δk).
Algorithm 1.A2 (allowed error rate, sampling oracle forD, labeling oracleO, hypothesis class H).
3. TheA2agnostic active learner
At a high level, A2 can be viewed as a robust version of the selective sampling algorithm of [18]. Selective sampling is a sequential process that keeps track of two spaces—the current version space Hi, defined as the set of hypotheses in H consistent with all labels revealed so far, and the currentregion of uncertainty Ri, defined as the set of all x
∈
X, for which there exists a pair of hypotheses in Hi that disagrees onx. In roundi, the algorithm picks a random unlabeled example fromRiand queries it, eliminating all hypotheses in Hiinconsistent with the received label. The algorithm then eliminates thosex∈
Rion which all surviving hypotheses agree, and recurses. This process fundamentally relies on the assumption that there exists a consistent hypothesis in H. In the agnostic case, a hypothesis cannot be eliminated based on its disagreement with a single example. Any algorithm must be more conservative without risking eliminating the best hypotheses in the class.A formal specification of A2 is given in Algorithm 1. Let H
i be the set of hypotheses still under consideration by A2 in roundi. If all hypotheses inHi agree on some region of the instance space, this region can be safely eliminated. To help us keep track of progress in decreasing the region of uncertainty, defineDisagreeD
(
Hi)
as the probability that there exists apair of hypotheses inHithat disagrees on a random example drawn from D:
DisagreeD
(
Hi)
=
Prx∼D∃
h1,
h2∈
Hi: h1(
x)
=
h2(
x)
.
HenceDisagreeD
(
Hi)
is the volume of the current region of uncertainty with respect toD.It is important to understand that the ability to sample from the unlabeled data distribution D implies that ability to compute DisagreeD
(
Hi)
. To see this, note that: DisagreeD(
Hi)
=
Ex∼DI(
∃
h1,
h2∈
Hi: h1(
x)
=
h2(
x))
is an expectation over unlabeled points drawn from D. Consequently, Chernoff bounds on the empirical expectation of a{
0,
1}
random variable imply thatDisagreeD(
Hi)
can be estimated to any desired precision with probability 1 using an unlabeled dataset with sizelimiting to infinity.
Let Di be the distribution D restricted to the current region of uncertainty. Formally, Di
=
D(
x| ∃
h1,
h2∈
Hi: h1(
x)
=
h2(
x))
. In round i, A2 samples a fresh set of examples S from Di,
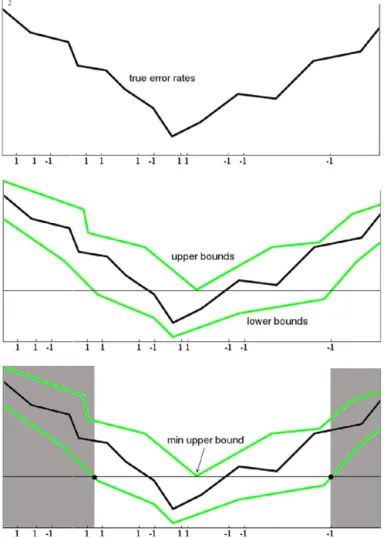
O, and uses it to compute upper and lower bounds for all hypotheses in Hi. It then eliminates all hypotheses whose lower bound is greater than the minimum upper bound. Fig. 3.1 shows the algorithm in action for the case when the data lie in the[
0,
1]
interval on the real line, and His the set of thresholding functions. The horizontal axis denotes both the instance space and the hypothesis space, superim-posed. The vertical axis shows the error rates. Round i completes when S is large enough to eliminate at least half of the current region of uncertainty.Fig. 3.1.A2in action: sampling, bounding, eliminating.
Since A2 does not label examples on which the surviving hypotheses agree, an optimal hypothesis in Hi with respect to Di remains an optimal hypothesis in Hi+1 with respect to Di+1. Since each roundi cutsDisagreeD
(
Hi)
down by half,the number of rounds is bounded by log1. Sections 4 gives examples of distributions and hypothesis classes for which A2 requires only a small number of labeled examples to transition between rounds, yielding an exponential improvement in sample complexity.
When evaluating bounds during the course of Algorithm 1, A2 uses a schedule of
δ
according to the following rule: the kth bound evaluation has confidenceδ
k=
k(kδ+1), for k1. In Algorithm 1, k keeps track of the number of bound computations andi of the number of rounds.Note.It is important to note that A2does not need to know
η
in advance. Similarly, it does not need to knowDin advance. 3.1. CorrectnessTheorem 3.1(Correctness). For all H , for all
(
D,
O)
, for all valid subroutines for computing UB and LB, for all0<
<
1/
2and 0< δ <
1/
2, with probability1−
δ
, A2returns an-optimal hypothesis or does not terminate.
Note.For most “reasonable” subroutines for computing UB and LB, A2 terminates with probability at least 1
−
δ
. For more discussion and a proof of this fact see Section 3.2.Proof. The first claim is that all bound evaluations are valid simultaneously with probability at least 1
−
δ
, and the second is that the procedure produces an-optimal hypothesis upon termination.
To prove the first claim, notice that the samples on which each bound is evaluated are drawni.i.d.from some distribution over X
×
Y. This can be verified by noting that the distributionDi used in roundi is precisely that given by drawingxfromthe underlying distribution D conditioned on the disagreement
∃
h1,
h2∈
Hi: h1(
x)
=
h2(
x)
, and then labeling according to the oracleO.Thekth bound evaluation fails with probability at most k(kδ+1). By the union bound, the probability that any bound fails is less then the sum of the probabilities of individual bound failures. This sum is bounded by
∞k=1k(kδ+1)=
δ
.To prove the second claim, notice first that since every bound evaluation is correct, step
(
∗∗
)
never eliminates a hypoth-esis that has minimum error rate with respect(
D,
O)
.Let us now introduce the following notation. For a hypothesish
∈
H andG⊆
Hdefine: eD,G,O(
h)
=
Prx,y∼D,O|∃h1,h2∈G:h1(x)=h2(x) h(
x)
=
y,
fD,G,O(
h)
=
Prx,y∼D,O|∀h1,h2∈G:h1(x)=h2(x) h(
x)
=
y.
Notice that eD,G,O
(
h)
is in fact errDG,O(
h)
, where DG is D conditioned on the disagreement∃
h1,
h2∈
G: h1(
x)
=
h2(
x)
. Moreover, given anyG⊆
H, the error rate of every hypothesishdecomposes into two parts as follows:errD,O
(
h)
=
eD,G,O(
h)
·
DisagreeD(
G)
+
fD,G,O(
h)
·
1−
DisagreeD(
G)
=
errDG,O(
h)
·
DisagreeD(
G)
+
fD,G,O(
h)
·
1
−
DisagreeD(
G)
.
Notice that the only term that varies with h
∈
G in the above decomposition, is eD,G,O(
h)
. Consequently, finding an-optimal hypothesis requires only bounding errDG,O
(
h)
·
DisagreeD(
G)
to precision. But this is exactly what the negation
of the main while-loop guard does, and this is also the condition used in the first step of the second while loop of the algorithm. In other words, upon termination A2 satisfies
DisagreeD
(
Hi)
min h∈Hi UB(
Si,
h, δ
k)
−
min h∈Hi LB(
Si,
h, δ
k)
,
which proves the desired result.2
3.2. Fall-back analysis
This section shows thatA2is never much worse than a standard batch, bound-based algorithm in terms of the number of samples required in order to learn. (A standard example of a bound-based learning algorithm is Empirical Risk Minimization (ERM) [35].)
The sample complexitym
(
, δ,
H)
required by a batch algorithm that uses a subroutine for computing LB(
S,
h, δ)
and UB(
S,
h, δ)
is defined as the minimum number of samplesm such that for all S∈
Xm,|
UB(
S,
h, δ)
−
LB(
S,
h, δ)
|
for allh
∈
H. For concreteness, this section uses the following bound onm(
, δ,
H)
stated as Theorem A.1 in Appendix A:m
(
, δ,
H)
=
642 2VHln 12
+
ln 4δ
.
Here VH is the VC-dimension of H. Assume that m
(
2, δ,
H)
m(,δ,2 H), and also that the functionm is monotonically increasing in 1/δ
. These conditions are satisfied by many subroutines for computing UB and LB, including those based on the VC-bound [34] and the Occam’s Razor bound [11].Theorem 3.2.For all H , for all
(
D,
O)
, for all UB and LB satisfying the assumption above, for all0<
<
1/
2and0< δ <
1/
2, the algorithm A2makes at most2m(
, δ
,
H)
calls to the oracle O , whereδ
=
δN(,δ,H)(N(,δ,H)+1)and N
(
, δ,
H)
satisfies N(
, δ,
H)
ln1lnm(
,
N(,δ,H)(Nδ(,δ,H)+1),
H)
. Here m(
, δ,
H)
is the sample complexity of UB and LB.Proof. Let
δ
k=
k(kδ+1) be the confidence parameter used in the kth application of the subroutine for computing UB and LB. The proof works by finding an upper bound N(
, δ,
H)
on the number of bound evaluations throughout the life of the algorithm. This implies that the confidence parameterδ
kis always greater thanδ
=
N(,δ,H)(Nδ(,δ,H)+1).Recall that Diis the distribution overxused on theith iteration of the first while loop.
Consider i
=
1. If condition 2 of Algorithm A2 is repeatedly satisfied then after labelingm(
, δ
,
H)
examples from D 1 for all hypothesesh∈
H1, UB(
S1,
h, δ
)
−
LB(
S1,
h, δ
)
simultaneously. Note that in these conditions A2safely halts. Notice also that the number of bound evaluations during this process is at most log2m
(
, δ
,
H)
.On the other hand, if loop
(
2)
ever completes and i increases, then it is enough, if you finish when i=
2, to have uniformly for allh∈
H2,(This follows from the exit conditions in the outer while-loop and the ‘if’ in Step 2 of A2.) Uniformly bounding the gap between upper and lower bounds over all hypothesesh
∈
H2to within 2, requiresm
(
2, δ
,
H)
m(,δ,H)
2 labeled examples fromD2and the number of bound evaluations in round i
=
2 is at most log2m(
, δ
,
H)
.In general, in roundiit is enough to have uniformly for allh
∈
Hi, UB(
Si,
h, δ
)
−
LB(
Si,
h, δ
)
2i−1,
and which requiresm
(
2i−1, δ
,
H)
m(2,δi−1,H) labeled examples from Di. Also the number of bound evaluations in round i is at most log2m(
, δ
,
H)
.Since the number of rounds is bounded by log21, it follows that the maximum number of bound evaluations throughout the life of the algorithm is at most log21log2m
(
, δ
,
H)
. This implies that in order to determine an upper boundN(
, δ,
H)
only a solution to the inequality:N
(
, δ,
H)
log2 1log2m
,
δ
N(
, δ,
H)(
N(
, δ,
H)
+
1)
,
H is required.Finally, adding up the number of calls to the label oracle O in all rounds yields at most 2m
(
, δ
,
H)
over the life of the algorithm.2
Let VH denote the VC-dimension of H, and letm
(
, δ,
H)
be the number of examples required by the ERM algorithm. As stated in Theorem A.1 in Appendix A, a classic bound onm(
, δ,
H)
ism(
, δ,
H)
=
642(
2VHln(
12)
+
ln(
4δ))
. Using Theo-rem 3.2, the following corollary holds.Corollary 3.3.For all hypothesis classes H of VC-dimension VH, for all distributions
(
D,
O)
over X×
Y , for all0<
<
1/
2and 0< δ <
1/
2, the algorithm A2requires at mostO˜
(
12(
VHln1+
ln1δ))
labeled examples the oracle O .2Proof. The form ofm
(
, δ,
H)
and Theorem 3.2 implies an upper bound on N=
N(
, δ,
H)
. It is enough to find the small-est N satisfying Nln 1ln 64
2 2VHln 12
+
ln 4N2δ
.
Using the inequality lna
ab−
lnb−
1 for alla,
b>
0 and some simple algebraic manipulations, the desired upper bound on N(
, δ,
H)
holds. The result then follows from Theorem 3.2.2
4. Active learning speedups
This section gives examples of exponential sample complexity improvements achieved by A2. 4.1. Learning threshold functions
Linear threshold functions are the simplest and easiest to analyze class. It turns out that even for this class, exponential reductions in sample complexity are not achievable when the noise rate
η
is large [28]. We prove the following three results:(1) An exponential improvement in sample complexity when the noise rate is small (Theorem 4.1).
(2) A slower improvement when the noise rate is large (Theorem 4.2). In the extreme case where the noise rate is 1
/
2, there is no improvement.(3) An exponential improvement when the noise rate is large but due to constant label noise (Theorem 4.3). This shows that for some forms of high noise exponential improvement remains possible.
All results in this section assume that subroutines LB and UB in A2 are based on the VC bound.
Theorem 4.1.Let H be the set of thresholds on an interval. For all distributions
(
D,
O)
where D is a continuous probability distribution function, for any<
12and16η
, the algorithm A2makesO
ln 1ln ln
(
1δ)
δ
calls to the oracle O on examples drawni.i.d.from D, with probability1
−
δ
.Proof. Consider roundi
1 of the algorithm. Forh1,
h2∈
Hi, letdi(
h1,
h2)
be the probability thath1 andh2 predict differ-ently on a random example drawn according to the distribution Di, i.e.,di(
h1,
h2)
=
Prx∼Di[
h1(
x)
=
h2(
x)
]
.Let h∗ be any minimum error rate hypothesis in H. Note that for any hypothesis h
∈
Hi, we have errDi,O(
h)
di(
h,
h∗)
−
errDi,O(
h∗)
and errDi,O(
h∗)
η
/
Zi, where Zi=
Prx∼D[
x∈ [
loweri,
upperi]]is a shorthand forDisagreeD(
Hi)
and[
loweri,
upperi]denotes the support of Di. Thus errDi,O(
h∗)
di(
h,
h∗)
−
η
/
Zi.We will show that at least a 12-fraction (measured with respect to Di) of thresholds in Hi satisfy di
(
h,
h∗)
14, and these thresholds are located at the ends of the interval[
loweri,
upperi]. Assume first that both di(
h∗,
loweri)
14 anddi(
h∗,
upperi)
14, then let li and ui be the hypotheses to the left and to the right of h∗, respectively, that satisfy di(
h∗,
li)
=
14 anddi(
h∗,
ui)
=
14. Allh∈ [
loweri,
li] ∪ [ui,
upperi]satisfydi(
h∗,
h)
14 and moreoverPrx∼Di
x∈ [
loweri,
li] ∪ [ui,
upperi] 1 2.
Now suppose that di
(
h∗,
loweri)
14. Let ui be the hypothesis to the right of h∗ with di(
h∗,
upperi)
=
12. Then all h∈
[
ui,
upperi]satisfydi(
h∗,
h)
14 and moreoverPrx∼Di[
x∈ [
ui,
upperi]]1
2. A similar argument holds fordi
(
h∗,
upperi)
14. Using the VC bound, with probability 1−
δ
, if|
Si| =O ln1 δ(
18−
Zη i)
2,
then for all hypothesesh
∈
Hi simultaneously,|
UB(
Si,
h, δ)
−
LB(
Si,
h, δ)
|
18−
Zηi holds. Note thatη
/
Zi is always upper bounded by 161.Consider a hypothesis h
∈
Hi with di(
h,
h∗)
14. For any such h, errDi,O(
h)
di(
h,
h∗)
−
η
/
Zi1 4
−
η
Zi, and so
LB
(
Si,
h, δ)
41−
Zηi−
(
18−
Zηi)
=
18. On the other hand, errDi,O(
h∗)
η Zi, and so UB
(
Si,
h ∗, δ)
η Zi
+
1 8−
η Zi=
1 8. Thus A 2 eliminates allh∈
Hiwithdi(
h,
h∗)
14. But that means DisagreeD(
Hi
)
12DisagreeD
(
Hi)
, thus terminating roundi. 3 Each exit fromwhileloop(
2)
decreasesDisagreeD(
Hi)
by at least a factor of 2, implying that the number of executionsis bounded by log1. The algorithm makes O
(
ln(
δ1)
ln(
1))
calls to the oracle, whereδ
=
N(,δ,H)(Nδ(,δ,H)+1) andN(
, δ,
H)
is an upper bound on the number of bound evaluations throughout the life of the algorithm.The number of bound evaluations required in round i is O
(
lnδ1)
, which implies that N(
, δ,
H)
should satisfycln
(
N(,δ,H)(Nδ(,δ,H)+1))
ln(
1)
N(
, δ,
H)
, for some constantc. Solving this inequality completes the proof.2
Theorem 4.2 below asymptotically matches a lower bound of Kääriäinen [28]. Recall that A2 does not need to know
η
in advance.Theorem 4.2.Let H be the set of thresholds on an interval. Suppose that
<
12 andη
>
16. For all D, with probability1
−
δ
, the algorithm A2requires at mostO˜
(
η2ln1δ2
)
labeled samples.Proof. The proof is similar to the previous proof. Theorem 4.1 implies that loop (2) completes
Θ(
logη1)
times. At this point, the minimum error rate of the remaining hypotheses conditioned on disagreement becomes sufficient so that the algorithm may only halt via the return step(
∗
)
. In this case,DisagreeD(
H)
=
Θ(
η
)
implying that the number of samples required is˜
O(
η2ln1 δ 2
)
.2
The final theorem is for theconstant label noisecase wherePry∼O|x[h∗
(
x)
=
y] =
η
for allx∈
X. The theorem is similar to earlier work [14], except that we achieve these improvements with a general purpose active learning algorithm that does not use any prior over the hypothesis space or knowledge of the noise rate, and is applicable to arbitrary hypothesis spaces. Theorem 4.3.Let H be the set of thresholds on an interval. For all unlabeled data distributions D, for all labeled data distributions O , for any constant label noiseη
<
1/
2and<
12, the algorithm A2makes O(
(1−12η)2ln
(
1)
ln(
ln(1 δ)
δ
))
calls to the oracle O on examples drawni.i.d.from D, with probability1−
δ
.The proof is essentially the same as for Theorem 4.1, except that the constant label noise condition implies that the amount of noise in the remaining actively labeled subset stays bounded through the recursions.
Proof. Consider roundi
1. For h1,
h2∈
Hi, letdi(
h1,
h2)
=
Prx∼Di[
h1(
x)
=
h2(
x)
]
. Note that for any hypothesish∈
Hi, wehave errDi,O
(
h)
=
di(
h,
h∗)(
1−
2η
)
+
η
and errDi,O(
h∗)
=
η
, whereh∗ is a minimum error rate threshold.3 The assumption in the theorem statement can be weakened toη<
As in the proof of Theorem 4.1, at least a 12-fraction (measured with respect to Di) of thresholds in Hi satisfy di
(
h,
h∗)
14, and these thresholds are located at the ends of the support[
loweri,
upperi]ofDi.The VC bound implies that for any
δ
>
0 with probability 1−
δ
, if|
Si| =O(
(1ln(1/δ−2η))2)
, then for all hypotheses h∈
Hi simultaneously,|
UB(
Si,
h, δ)
−
LB(
Si,
h, δ)
|
<
1−82η.Consider a hypothesis h
∈
Hi withdi(
h,
h∗)
14. For any suchh, errDi,O(
h)
1−2η 4
+
η
=
1 4+
η 2, and so LB(
Si,
h, δ) >
1 4+
η 2−
1 8(
1−
2η
)
=
1 8+
3η4. On the other hand, errDi,O
(
h∗)
=
η
, and so UB(
Si,
h∗, δ) <
η
+
(
1 8
−
η 4)
=
1 8+
3η 4. Thus A2 eliminates allh∈
Hi withdi(
h,
h∗)
14. But this means that DisagreeD(
Hi
)
12DisagreeD(
Hi)
, thus terminating roundi. Finally notice that A2 makes O(
ln(
1δ
)
ln(
1))
calls to the oracle, whereδ
=
δ
N(,δ,H)(N(,δ,H)+1) and N
(
, δ,
H)
is an upper bound on the number of bound evaluations throughout the life of the algorithm. The number of bound evaluations required in roundiis O(
ln(
1/δ
))
, which implies that the number of bound evaluations throughout the life of the algorithm N(
, δ,
H)
should satisfy cln(
N(,δ,H)(Nδ(,δ,H)+1))
ln(
1)
N(
, δ,
H)
, for some constantc. Solving this inequality, completes the proof.2
4.2. Linear separators under the uniform distribution
A commonly analyzed case for which active learning is known to give exponential savings in the number of labeled examples is when the data is drawn uniformly from the unit sphere in
R
d, and the labels are consistent with a linear separator going through the origin. Note that even in this seemingly simple scenario, there exists anΩ(
1(
d+
log1δ))
lower bound on the PAC passive supervised learning sample complexity [30]. We will show that A2 provides exponential savings in this case even in the presence of arbitrary forms of noise.Let X
= {
x∈
R
d:x
=
1}
, the unit sphere inR
d. Assume that D is uniform over X, and let H be the class of linear separators through the origin. Anyh∈
His a homogeneous hyperplane represented by a unit vector w∈
X with the clas-sification ruleh(
x)
=
sign(
w·
x)
; for concreteness, leth(
0)
=
1. The distance between two hypothesesu and v in H with respect to a distribution D (i.e., the probability that they predict differently on a random example drawn from D) is given bydD(
u,
v)
=
arccos(πu·v). Finally, letθ (
u,
v)
=
arccos(
u·
v)
. ThusdD(
u,
v)
=
θ (uπ,v).Theorem 4.4.Let X , H , and D be as defined above, and let LB and UB be the VC bound. Then for any0
<
<
12,0<
η
<
16√d, andδ >
0, with probability1−
δ
, A2requires O d dlnd+
ln1δ
ln1calls to the labeling oracle, where
δ
=
N(,δ,H)(Nδ(,δ,H)+1)and N(
, δ,
H)
=
O ln1d2lnd
+
dlndln 1δ
.
Proof. Let w∗
∈
H be a hypothesis with the minimum error rateη
. Denote the region of uncertainty in round i by Ri. Thus Prx∼D[
x∈
Ri] =DisagreeD(
Hi)
. Fig. 4.1 schematically shows the region of uncertainty after the first iteration of thealgorithm.
Consider round i of A2. We prove that the round completes with high probability if a certain threshold on the number of labeled examples is reached. The round may complete with a smaller number of examples, but this is fine because the metric of progress DisagreeD
(
Hi)
must halve in order for the round to complete.Theorem A.1 says that it suffices to query the oracle on a set S of O
(
d2lnd+
dln1δ
)
examples fromith distribution Di to guarantee, with probability 1−
δ
, that for allw∈
Hi, errDi,O(
w)
−
errDi,O(
w)
<
1 2 1 8√
d−
η
ri,
whereriis a shorthand forDisagreeD
(
Hi)
. (By assumption,η
<
16√d and the loop guard guarantees thatDisagreeD
(
Hi)
. Thus the precision above is at least 1
32√d.)
4 This implies that UB
(
S,
w, δ
)
−
errDi,O
(
w) <
1 8√d−
η ri,
and errDi,O(
w)
−
LB(
S,
w, δ
) <
1 8√d−
ηri
.
Consider any w∈
Hi with dDi(
w,
w∗
)
1
4√d. For any such w, errDi,O
(
w)
dDi(
w,
w∗)
−
errDi,O
(
w∗)
1 4√d−
η ri, since errDi,O(
w ∗)
η ri. Therefore LB
(
S,
w, δ
) >
1 4√
d−
η
ri−
1 8√
d+
η
ri=
1 8√
d.
4 The assumption in the theorem statement can be weakened toη<
Fig. 4.1.The region of uncertainty after the first iteration (schematic).
On the other hand, we have UB
(
S,
w∗, δ
) <
ηri
+
1 8√d−
η ri=
1 8√d, so A 2eliminates w in step(
∗∗
)
. Thus roundieliminates all hypothesesw∈
HiwithdDi(
w,
w∗)
1
4√d. Since all hypotheses inHiagree on everyx
∈
/
Ri, dDi(
w,
w∗)
=
1 ri dD(
w,
w∗)
=
θ (
w,
w∗)
π
ri.
Thus round i eliminates all hypotheses w
∈
Hi withθ (
w,
w∗)
4πr√id. But since 2θ/
π
sinθ
, forθ
∈
(
0,
π2]
, it certainly eliminates all wwith sinθ (
w,
w∗)
ri2√d.
Consider anyx
∈
Ri+1 and the value|
w∗·
x| =
cosθ (
w∗,
x)
. There must exist a hypothesis w∈
Hi+1 that disagrees with w∗ onx; otherwisexwould not be inRi+1. But then cosθ (
w∗,
x)
cos(
π2−
θ (
w,
w∗))
=
sinθ (
w,
w∗) <
ri2√d, where the last inequality is due to the fact thatA2 eliminates allwwith sin
θ (
w,
w∗)
ri
2√d. Thus anyx
∈
Ri+1must satisfy|
w∗
·
x|
<
ri2√d. Using the fact thatPr
[
A|
B] =
PrPr[[A BB]]PrPr[[AB]] for any AandB,Prx∼Di
[
x∈
Ri+1]
Prx∼Di|
w·
x|
ri 2√
d Prx∼D[|
w·
x|
ri 2√d]
Prx∼D[
x∈
Ri] ri 2ri=
1 2,
where the third inequality follows from Lemma A.2. ThusDisagreeD(
Hi+1)
12DisagreeD
(
Hi)
, as desired.In order to finish the argument, it suffices to notice that since every round cuts DisagreeD
(
Hi)
at least in half, thetotal number of rounds is bounded by log1. Notice also that A2 makes O
(
d2lnd+
dlnδ1)
ln(
1)
calls to the oracle, whereδ
=
N(,δ,H)(Nδ(,δ,H)+1) andN(
, δ,
H)
is an upper bound on the number of bound evaluations throughout the life of the algorithm. The number of bound evaluations required in round i is O(
d2lnd+
dln1δ
)
. This implies that the number of bound evaluations throughout the life of the algorithmN(
, δ,
H)
should satisfyc(
d2lnd+
dln(
N(,δ,H)(N(,δ,H)+1)δ
))
ln(
1
)
N(
, δ,
H)
for some constantc. Solving this inequality, completes the proof.2
Note.For comparison, the query complexity of the Perceptron-based active learner of [23] is O
(
dln1δ(
lndδ+
ln ln1))
, for the sameH,X, andD, but only for the realizable case whenη
=
0. Similar bounds are obtained in [5] both in the realizable case and for a specific form of noise related to the Tsybakov small noise condition. The cleanest and simplest argument that exponential improvement is in principle possible in the realizable case for the sameH, X, andD appears in [21]. Our work provides the first justification of why one can hope to achieve similarly strong guarantees in the much harder agnostic case, when the noise rate is sufficiently small with respect to the desired error.5. Conclusions, discussion and open questions
This paper presents A2, the first active learning algorithm that finds an
-optimal hypothesis in any hypothesis class, when the distribution has arbitrary forms of noise. The algorithm relies only upon the assumption that the samples are drawni.i.d.from a fixed (unknown) distribution, and it does not need to know the error rate of the best classifier in the class in advance. We analyze A2 for several settings considered before in the realizable case, showing that A2 achieves an exponential improvement over the usual sample complexity of supervised learning in these settings. We also provide a guarantee that A2never requires substantially more labeled examples than passive learning.
5.1. Subsequent work
Following the initial publication of A2, Hanneke has further analyzed the A2 algorithm [25], deriving a general upper bound on the number of label requests made by A2. This bound is expressed in terms of particular quantity called the disagreement coefficient, which roughly quantifies how quickly the region of disagreement can grow as a function of the radius of the version space. For concreteness the bound is included in Appendix B.
In addition, Dasgupta, Hsu, and Monteleoni [22] introduce and analyze a new agnostic active learning algorithm. While similar to A2, this algorithm simplifies the maintenance of the region of uncertainty with a reduction to supervised learning, keeping track of the version space implicitly via label constraints.
5.2. Open questions
A common feature of the selective sampling algorithm [18], A2, and others [22] is that they are all non-aggressive in their choice of query points. Even points on which there is a small amount of uncertainty are queried, rather than pursuing the maximally uncertain point. In recent work Balcan, Broder and Zhang [5] have shown that more aggressive strategies can generally lead to better bounds. However the analysis in [5] was specific to the realizable case, or done for a very specific type of noise. It is an open question to design aggressive agnostic active learning algorithms.
A more general open question is what conditions are sufficient and necessary for active learning to succeed in the agnos-tic case. What is the right quantity that can characterize the sample complexity of agnosagnos-tic active learning? As mentioned already, some progress in this direction has been recently made in [25] and [22]; however, those results characterize non-aggressive agnostic active learning. Deriving and analyzing the optimal agnostic active learning strategy is still an open question.
Much of the existing literature on active learning has been focused on binary classification; it would be interesting to analyze active learning for other loss functions. The key ingredient allowing recursion in the proof of correctness is a loss that is unvarying with respect to substantial variation over the hypothesis space. Many losses such as squared error loss do not have this property, so achieving substantial speedups, if that is possible, requires new insights. For other losses with this property (such as hinge loss or clipped squared loss), generalizations of A2 appear straightforward.
Acknowledgments
Maria-Florina has been supported in part by the NSF grant CCF-0514922, by an IBM Graduate Fellowship, and by a Google Research Grant. Part of this work was done while she was visiting IBM T.J. Watson Research Center in Hawthorne, NY, and Toyota Technological Institute at Chicago.
Appendix A. Standard results
The following standard Sample Complexity bound is in [3].
Theorem A.1.Suppose that H is a set of functions from X to
{−
1,
1}
with finite VC-dimension VH1. Let D be an arbitrary, but fixed probability distribution over X× {−
1,
1}
. For any,
δ >
0, if a sample is drawn from D of sizem
(
, δ,
VH)
=
642 2VHln 12
+
ln 4δ
,
then with probability at least1
−
δ
,|
err(
h)
−
err(
h)
|
for all h
∈
H .Section 4.2 uses the following a classic lemma about the uniform distribution. For a proof see, for example, [5,23]. Lemma A.2. For any fixed unit vector w and any0
<
γ
1,γ
4Prx|
w·
x|
√
γ
dγ
,
where x is drawn uniformly from the unit sphere. Appendix B. Subsequent guarantees forA2
This section describes the disagreement coefficient [25] and the guarantees it provides for the A2 algorithm. We begin with a few additional definitions, in the notation of Section 2.
Definition 2.Thedisagreement rate
Δ(
V)
of a set V⊆
His defined asΔ(
V)
=
Prx∼DDefinition 3.Forh
∈
H,r>
0, letB(
h,
r)
= {
h∈
H: d(
h,
h)
r}
and define thedisagreement rate at radius r asΔ
r=
suph∈H
Δ
B(
h,
r)
.
Thedisagreement coefficientis the infimum value of
θ >
0 such that∀
r>
η
+
,
Δ
rθ
r.
Theorem B.1.(See [25].) If
θ
is the disagreement coefficient for H , then with probability at least1−
δ
, given the inputsand
δ
, A2 outputs an-optimal hypothesis h. Moreover, the number of label requests made by A2is at most:
˜
Oθ
2η
22
+
1 VHln 1+
ln 1δ
ln1,
where VH
1is the VC-dimension of H . References[1] D. Angluin, Queries and concept learning, Mach. Learn. 2 (1998) 319–342. [2] D. Angluin, Queries revisited, Theoret. Comput. Sci. 313 (2) (2004) 175–194.
[3] M. Anthony, P. Bartlett, Neural Network Learning: Theoretical Foundations, Cambridge University Press, 1999.
[4] M.-F. Balcan, A. Blum, A PAC-style model for learning from labeled and unlabeled data, in: Proceedings of the 18th Annual Conference on Computational Learning Theory (COLT), 2005.
[5] M.-F. Balcan, A. Broder, T. Zhang, Margin based active learning, in: Proceedings of the 20th Annual Conference on Computational Learning Theory (COLT), 2007.
[6] M.-F. Balcan, E. Even-Dar, S. Hanneke, M. Kearns, Y. Mansour, J. Wortman, Asymptotic active learning, in: Workshop on Principles of Learning Design Problem, in Conjunction with the 21st Annual Conference on Neural Information Processing Systems (NIPS), 2007.
[7] M.-F. Balcan, S. Hanneke, J. Wortman, The true sample complexity of active learning, in: Proceedings of the 21st Annual Conference on Computational Learning Theory (COLT), 2008.
[8] E. Baum, K. Lang, Query learning can work poorly when a human oracle is used, in: Proceedings of the IEEE International Joint Conference on Neural Networks, 1993.
[9] A. Blum, S. Chawla, Learning from labeled and unlabeled data using graph mincuts, in: Proceedings of the 18th International Conference on Machine Learning (ICML), 2001.
[10] A. Blum, T. Mitchell, Combining labeled and unlabeled data with co-training, in: The 11th Annual Conference on Computational Learning Theory (COLT), 1998.
[11] A. Blumer, A. Ehrenfeucht, D. Haussler, M. Warmuth, Occam’s razor, Inform. Process. Lett. 24 (1987) 377–380.
[12] O. Bousquet, S. Boucheron, G. Lugosi, Theory of classification: A survey of recent advances, ESAIM Probab. Stat. 9 (2005) 323–375.
[13] N.H. Bshouty, N. Eiron, Learning monotone dnf from a teacher that almost does not answer membership queries, J. Mach. Learn. Res. 3 (2002) 49–57. [14] M. Burnashev, K. Zigangirov, An interval estimation problem for controlled observations, Probl. Inf. Transm. 10 (1974) 223–231.
[15] R. Castro, R. Nowak, Minimax bounds for active learning, in: Proceedings of the 20th Annual Conference on Computational Learning Theory (COLT), 2007.
[16] R. Castro, R. Willett, R. Nowak, Faster rates in regression via active learning, Adv. Neural Inform. Process. Systems 18 (2006). [17] O. Chapelle, B. Schölkopf, A. Zien, Semi-Supervised Learning, MIT Press, 2006.
[18] D. Cohn, L. Atlas, R. Ladner, Improving generalization with active learning, in: Proceedings of the 15th International Conference on Machine Learning (ICML), 1994, pp. 201–221.
[19] J. Czyzowicz, D. Mundici, A. Pelc, Ulam’s searching game with lies, J. Combin. Theory Ser. A 52 (1989) 62–76. [20] S. Dasgupta, Analysis of a greedy active learning strategy, Adv. Neural Inform. Process. Systems 17 (2004). [21] S. Dasgupta, Coarse sample complexity bounds for active learning, Adv. Neural Inform. Process. Systems 18 (2005).
[22] S. Dasgupta, D.J. Hsu, C. Monteleoni, A general agnostic active learning algorithm, Adv. Neural Inform. Process. Systems 20 (2007).
[23] S. Dasgupta, A. Kalai, C. Monteleoni, Analysis of perceptron-based active learning, in: Proceedings of the 18th Annual Conference on Computational Learning Theory (COLT), 2005.
[24] Y. Freund, H.S. Seung, E. Shamir, N. Tishby, Selective sampling using the query by committee algorithm, Mach. Learn. 28 (2–3) (1997) 133–168. [25] S. Hanneke, A bound on the label complexity of agnostic active learning, in: Proceedings of the 24th Annual International Conference on Machine
Learning (ICML), 2007.
[26] J. Jackson, An efficient membership-query algorithm for learning dnf with respect to the uniform distribution, J. Comput. System Sci. 57 (3) (1995) 414–440.
[27] T. Joachims, Transductive inference for text classification using support vector machines, in: Proceedings of the 16th International Conference on Machine Learning (ICML), 1999, pp. 200–209.
[28] M. Kääriäinen, On active learning in the non-realizable case, in: Proceedings of 17th International Conference on Algorithmic Learning Theory (ALT), 2006.
[29] A. Levin, P. Viola, Y. Freund, Unsupervised improvement of visual detectors using co-training, in: Proceedings of the 9th International Conference on Computer Vision (ICCV), 2003.
[30] P.M. Long, On the sample complexity of PAC learning halfspaces against the uniform distribution, IEEE Trans. Neural Networks 6 (6) (1995) 1556–1559. [31] T. Mitchell, The discipline of machine learning, Technical Report CMU ML-06 108, 2006.
[32] K. Nigam, A. McCallum, S. Thrun, T.M. Mitchell, Text classification from labeled and unlabeled documents using EM, Mach. Learn. 39 (2/3) (2000) 103–134.
[33] S.B. Park, B.T. Zhang, Co-trained support vector machines for large scale unstructured document classification using unlabeled data and syntactic information, Inform. Process. Manag. 40 (3) (2004) 421–439.
[34] V. Vapnik, A. Chervonenkis, On the uniform convergence of relative frequencies of events to their probabilities, Theory Probab. Appl. 16 (2) (1971) 264–280.