Big Data Adoption – An Iterative
Approach to Harness the Power
of Big Data
The emergence of every new technology brings its own
share of Wow! and Aha! factors. While these factors add
value to the technology development process, they can
also lead to benefits and limitations of the technology
remaining unevaluated before adoption. If these factors are
not examined properly, they can subsequently derail the
entire program and send it back to the drawing board.
While Big Data appears to be a technology-driven
movement, its strategic importance requires special focus
and attention during its adoption, because
n
Technology to support Big Data is evolving rapidly and
will take some time to mature.
n
Effective utilization of Big Data requires a change in
mindset regarding the way it is used. While other
technologies help solve problems like streamlining the
inventory management process or providing an online
system that enables the order shipment tracking on
realtime basis, Big Data helps find the problems that
require attention; for example, the combination of
factors that causes defects in the manufacturing process,
or the factors contributing to the sales differential
between two stores.
n
While the three Vs (i.e., Volume, Velocity and Variety) have
been regularly used to define Big Data, the use of
technologies that support Big Data are not confined only
to the way the three Vs are defined. Their usage has a
much broader scope when correctly analyzed from the
organization’s perspective.
Much like other evolving technologies, it may be useful to
first conduct small-scale projects in Big Data, for a better
understanding of the technology and the business areas
that may benefit from it. While these projects (more like
proofs-of-concept) are good as a starting point, the
mainstream adoption of Big Data requires a structured
framework. This is because the solution space in this area
comprises not only large, isolated and varied data sets, but
also a rapidly evolving technology landscape. Trying to get
all the requirements defined at one go and selecting the
technology of choice at the outset can potentially derail the
entire program and leave the organization with a dead
investment.
The paper addresses this need by presenting a systematic
and focused approach to be followed while adopting Big
Data.
About the Authors
Ajay Parashar
With a Master’s degree in Business Administration and a
Bachelor’s degree in Industrial and Production Engineering, Ajay Parashar is a Solution Architect and the Big Data Lead for the TCS HiTech Industry Solution Unit’s Domain group. During the last year, Ajay has been involved in business development projects around Big Data, and has overall experience of 12 years in Database Administration, Project and Program Management and Delivery Management.
Table of Contents
1
Introduction
5
2
Adoption Framework
5
Data Discovery
7
Analytics Discovery
7
Tools and Technology Discovery
8
Infrastructure Discovery
9
Implementation
10
Introduction
Adoption Framework
Big Data, the new buzz word in the IT space, has captured the imagination of many organizations, making its way to the strategy desk in the relatively short time it has been in existence. The web space, the
analysts and anybody-who-matters are talking about the immense benefits that the harnessing of Big Data can bring to an organization or to society at large, by tapping into information that has so far lain hidden. With rewards in billions of dollars, Big Data is a highly attractive investment.
While there are benefits to be gained, like using market buzz to reduce the time taken to change product features or the product mix, enabling targeted promotion and prompting shorter analysis cycle time, the picture around Big Data adoption is still fuzzy—as is usually the case with any new emerging technology. Conceptually, Big Data is defined by the size of data, but is this classification alone sufficient to answer the questions that most organizations ask? For instance, questions like:
n What data is to be analyzed? n Which technology is to be used?
n What is the quantum of investment to be made?
n What should be the enterprise adoption approach towards Big Data?
Answers to these questions are not easy to come by, if we rely on the established system development approach as prescribed by the Waterfall and Agile models. The very premise of these models—having a set of requirements — does not exist in the case of Big Data. Some may argue that the requirement is to harness Big Data, which is not entirely wrong; however, this is similar to starting a project with the stated requirement of poverty eradication— a requirement too broad and sweeping to be easily fulfilled. It is important to start with a clean slate while approaching the idea of Big Data, continuously building on it without discarding anything created in the process.
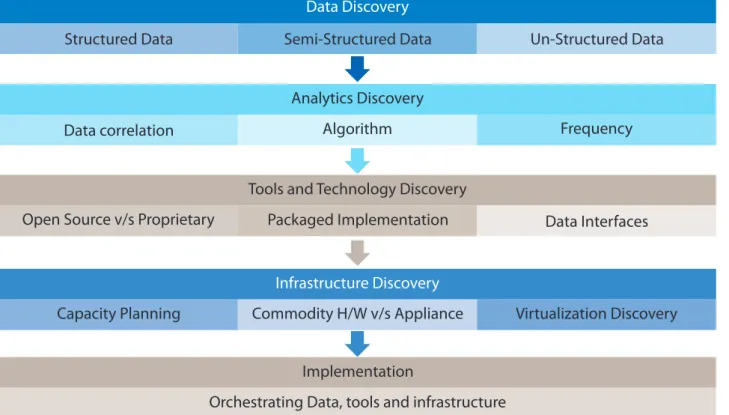
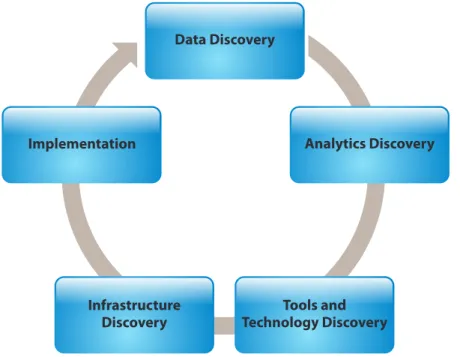
A key factor in the success of any new program is the way it is approached from the inception phase itself. Any Big Data program that requires the integration of data with strategic planning is going to be critical and will carry heavy penalties in case of failure. The right framework to enable the adoption of Big Data analytics within the organization must be adopted. The critical components of this framework include:
n Data discovery n Analytics discovery
n Tools and technology discovery\ n Infrastructure discovery
Unlike a conventional analytics solution that starts with a problem statement and then finds different data sources to address the problem, Big Data analytics must be studied from a completely different perspective. For instance, the problem an organization is trying to solve is unknown, because had it been known, the relevant solution or answer would already have been in place and we would not be looking at Big Data for a solution. For example, ‘understanding consumer sentiments’ is as good a problem
statement as someone asking for the count of galaxies in the universe!
The value of Big Data analytics lies in bringing together different data sources in a cost-efficient manner and providing an environment that enables questioning the integrated data set. Coming back to the imagined question on consumer sentiments, Big Data helps not just in understanding the sentiments but also to develop a deeper understanding of the factors causing a particular sentiment – that is, the
business problem to be solved.
Data Discovery
Structured Data Semi-Structured Data Un-Structured Data
Analytics Discovery
Data correlation Algorithm Frequency
Tools and Technology Discovery
Open Source v/s Proprietary Packaged Implementation Data Interfaces
Infrastructure Discovery
Capacity Planning Commodity H/W v/s Appliance Virtualization Discovery
Implementation
Orchestrating Data, tools and infrastructure
Data Discovery
Analytics Discovery
For any organization looking to Big Data for a solution, the first and most important step is to define the visible sources of data. Enterprise data warehouses, Online Transaction Processing (OLTP) systems, the Customer Relationship Management (CRM) system, the Enterprise Resource Planning (ERP) platform etc. are the usual sources of data. However, the selection should not be limited to these alone. There may be other data sources that are very operational in nature and may not be seen as important from the Business Intelligence perspective. These include salespersons’ daily logs (if there are any), machine
operators’ logs or manual logs maintained by security persons. Bringing them on a common platform and integrating them with other data sources may reveal information that was hitherto unknown. For
example, integrating sales and CRM data with web application logs may help understand the decision matrix followed by a customer before making the purchase decision.
Data discovery is the most crucial part of the entire exercise, as it defines the subsequent solution design and development. Creating a Big Data environment is an ever-evolving process, with the addition and integration of each new data source further strengthening the existing analytics operations and bringing to light new problem areas to be researched.
Identifying data sets and putting them together is one part of the Big Data adoption roadmap. The real challenge is to mine the data for information of business importance. The foundation of this process is derived from the existing business intelligence dashboards and reports. You must identify the vital dashboards and start asking the Big Data repository questions in order to obtain insights into the ‘what’ and ‘why’ part of the dashboards.
For example, examine the regional sales data, and try to dig for information that first addresses the ‘what’ of the sales difference; as a next step, understand the ‘why’ part of the difference. This is an evolutionary process that moves from vanilla dashboard reporting to complex decision-support predictive analytics, while strengthening attribute identification and establishing correlations between them.
The analytics discovery process will:
n Create an elaborate analytics landscape touching upon the critical business functions that play an
important role in the top-line and bottom-line of the organization,
n Establish the relationship between different data sources; this will help understand the effect of their
mutual interaction, and
n Create analytics modeling that meshes with the organization’s goals and objectives, evolving
Tools and Technology Discovery
Having started with the identification of the data set and defining the analytics requirements from the data set, the next step is choosing the right mix of technology and tools. This is crucial for the success of any Big Data program, for the following reasons:
a) No two business problems are the same; each requires a different treatment. For example, the analysis of structured data might be more efficient and less complex in a fine-tuned Relational Database Management System (RDBMS) driven setup as compared to a setup driven by NoSQL databases or open source community-provided parallel processing engines such as Apache Hadoop.
b) Each identified data set may need to be handled differently, especially during the initial stages, in order to clear the noise and make it presentable to the analytics engine.
c) The core technology driving Big Data analytics (such as Apache Hadoop) and other analytic eco-system tools are still evolving.
In the current technology landscape that addresses the analytics requirements of Big Data, there are multiple products, solutions or frameworks. Names such as Hadoop, MapReduce, R, Mahout, SAS, Flume, Lucene etc. are frequently referred to in discussions about Big Data. However, all these components address specific areas: for example, Lucene is associated with search functions, Mahout with machine learning to automate routine system decision-making and Hadoop with parallel processing of large amounts of data. Picking a tool is, therefore, dependent on the outcome of the earlier two steps, i.e., Data Discovery and Analytics Discovery.
For example, the technology requirements for analyzing web log data on a real-time basis are completely different from what is required to analyze unstructured data to access the sentiments of customers. There is no single technology solution that fits all analytics’ requirements. Investing upfront in one technology or a tool might not be conducive to evolving a robust Big Data analytics platform. A focused and detailed evaluation of tools and technologies is required, based on the outcome of the earlier two phases.
Another point to consider during technology evaluation is whether to opt for a packaged solution from an established OEM, or a custom-built solution from open source products. While most of the
technologies driving the Big Data movement have their origin in the open source community, these technologies are being rapidly adopted by established OEMs such as EMC, IBM, Teradata and Oracle. These are also being bundled in the form of Big Data appliances. The guiding pillars in this decision making process should be the velocity of the Big Data adoption program, the maturity of the analytics model, the business value realization and the appetite for capital expenditure.
Infrastructure Discovery
With organizations today reeling under the operational overheads of maintaining multiple data centers, identifying and defining infrastructural requirements for a Big Data eco-system is important, to avoid the addition of further complexity to the IT landscape and additional capital and operational expenses. The infrastructural decisions to be taken can be grouped into three distinct categories:
a) Server Hardware: The decision on server hardware is dependent on the following factors: a. Data characteristics including its source, privacy and security aspects
b. Nature of the analytics operations, i.e., regular analysis to support areas such as risk assessment of a customer for insurance policy issuance, in-store product placement decision-making, sentiment analysis from social channels, periodic analysis to support strategic decision-making such as customer segmentation while finalizing the product launch program, new branch/store opening decision-making etc.
c. Existing data center capacity, maturity of the server virtualization program and openness to cloud environment
b) Storage Infrastructure: Dealing with large quantities of data utilized mainly in a read-only manner will require closer examination of the storage solution chosen to support the Big Data platform. The choice between Network Attached Storage (NAS), Storage Area Network (SAN), Redundant Array of Independent Disks (RAID) or On-server storage requires one to scrutinize the benefits of each and compare them against the performance impact. By its very nature, the core technology driving Big Data relies on parallel processing of data spread across multiple machines. The reduction in I/O bottlenecks as a result of local processing (each server processing data stored within it) plays a very important role in ensuring the promised performance benefits are delivered. Our earlier paper titled “Scale-out Storage Systems” provides insights about storage infrastructure decision-making.
c) Networking Setup: A Big Data analytics environment will involve analytics computation on large quantities of data spread across multiple systems and accessed in a random manner. The decision to have a separate network for the Big Data environment instead of leveraging the existing enterprise-wide network should be weighed against the business risk associated with enterprise application performance degradation due to network bandwidth utilization by Big Data analytics operations.
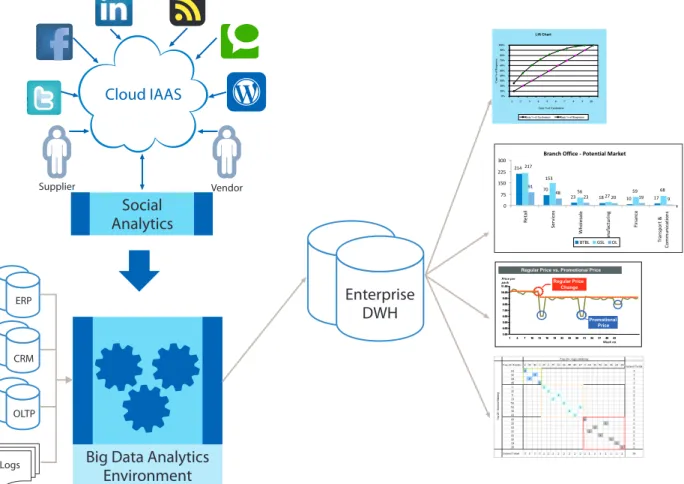
A key point to consider and evaluate here is whether to utilize Infrastructure as a Service provided by cloud vendors such as AWS and Microsoft Azure. A cloud-based environment may be ideal to analyze social data generated from Facebook, Twitter and weblogs, integrating the resultant analytics with the inhouse Big Data environment data elements coming from systems such as ERP and CRM. However, this must be analyzed as per the analytics operations surrounding social data and the level of expected correlation with in-house data elements.
The Big Data analytics adoption program is an iterative program, with each iteration addressing a specific
Implementation
Lift Chart 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 1 2 3 4 5 6 7 8 9 10 Cum % of Customers Cum % of ResponseCum % of Customers Cum % of Response
Branch Office - Potential Market
214 70 10 17 59 68 91 48 23 18 20 19 9 23 217 153 27 56 0 75 150 225 300 R etail Services Wholesale Manuf acturing Finance Tr ansport & Communications BTBL GSL OL Cloud IAAS Social Analytics
Big Data Analytics Environment ERP CRM OLTP Logs Enterprise DWH Supplier Vendor
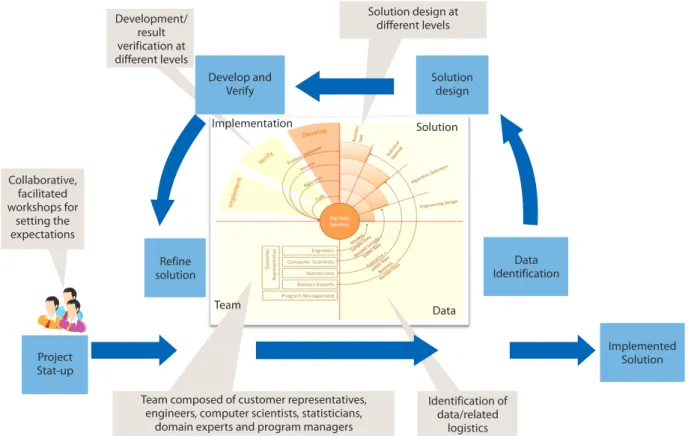
The iterative nature of the solution implementation helps in a number of ways and is strongly recommended for any Big Data adoption program.
n Big Data programs usually begin with a clean slate approach, where the outcome is not known and is
difficult to define.
n The selection of the analytics model and tools/techniques is based on certain assumptions made by
examining the identified data elements. Once implemented, the outcome of result interpretation may shed new light on these assumptions and require corrective action.
n The need to analyze and integrate newer data elements and data sources will change over a period of
time, according to the strategic direction of the business. Having an iterative approach allows for this seamless integration.
The framework or the adoption approach calls for a continuous improvement exercise carried out in an iterative manner, with each iteration critically examining the achievements of the past iteration and weighing them against the business benefits extracted from the exercise. New data sources added during an iteration can potentially render an earlier developed analytics model useless. Without refinement, an analytics model will tend to lose its significance in the long run.
Development/ result verification at different levels Solution design at different levels Collaborative, facilitated workshops for setting the expectations
Team composed of customer representatives, engineers, computer scientists, statisticians,
domain experts and program managers
Identification of data/related logistics Develop and Verify Solution design Data Identification Implemented Solution Project Stat-up Refine solution Implementation Solution Team Data
Conclusion
In conclusion, a Big Data adoption program should be viewed as a holistic program that is driven iteratively over a period of time by critically examining the assumptions made in earlier iterations, and weighing the business benefits derived from the results as well as the level of maturity/stability achieved with respect to broader business strategic objectives. The different phases, i.e., data discovery, analytics discovery, tools and technology discovery, infrastructure discovery and implementation, when carried out on a continuous basis, will help establish a robust Big Data analytics environment that supports the strategic decision-making process by augmenting it with data-centric analysis and predictions.
References
• “Big Data: The next frontier for innovation, competition, and productivity”, McKinsey Global Institute, May 2011, accessed Feb 11, 2012 http://www.mckinsey.com/insights/mgi/research/technology_and_innovation/big_data_the_next_frontier_for_innovation
• “Big Data and Advanced Analytics: Success Stories From the Front Lines”, Forbes, Dec 2012, accessed Feb 11, 2012,
http://www.forbes.com/sites/mckinsey/2012/12/03/big-data-Tools and Technology Discovery Infrastructure Discovery Analytics Discovery Implementation Data Discovery
vices M 03 13 I I I
All content / information present here is the exclusive property of Tata Consultancy Services Limited (TCS). The content / information contained here is
IT Services
Business Solutions Outsourcing
Contact
For feedback on this article and more information, please contact us at:
About TCS HiTech Industry Solution Unit
TCS' HiTech industry Solutions Unit provides optimal, customized, and comprehensive solutions across varied High Tech industry segments: Computer Platform and Services Companies, Software Firms, Electronics and Semiconductor Companies, and Professional Services Firms (Legal, HR, Tax & Accounting and Consulting & Advisory/Analyst firms). Building on its vast experience in engineering, business process transformation, innovation and IT solutions, TCS offers a comprehensive portfolio of services that maximize growth, manage risk, and reduce costs. The TCS HiTech Industry Solution Unit partners with High Tech enterprises to provide end-to-end solutions which help realize operational excellence, innovation and greater profitability.
For more information, visit us at http://www.tcs.com/industries/high_tech
About Tata Consultancy Services (TCS)
www.tcs.com
Tata Consultancy Services is an IT services, consulting and business solutions organization that delivers real results to global business, ensuring a level of certainty no other firm can match. TCS offers a consulting-led, integrated portfolio of IT and IT-enabled infrastructure, engineering
TM
and assurance services. This is delivered through its unique Global Network Delivery Model , recognized as the benchmark of excellence in software development. A part of the Tata Group, India’s largest industrial conglomerate, TCS has a global footprint and is listed on the National Stock Exchange and Bombay Stock Exchange in India.
For more information, visit us at
Subscribe to TCS White Papers
TCS.com RSS: http://www.tcs.com/rss_feeds/Pages/feed.aspx?f=w Feedburner: http://feeds2.feedburner.com/tcswhitepapers