Performance Evaluation of Improved Web Search Algorithms
Full text
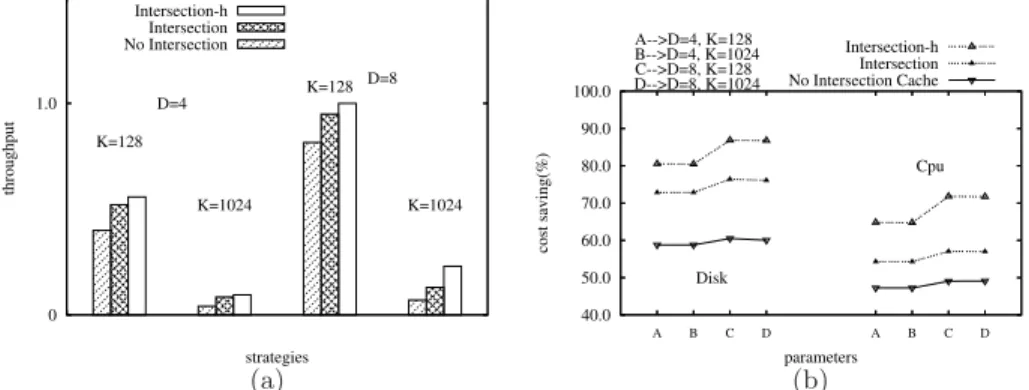
Figure
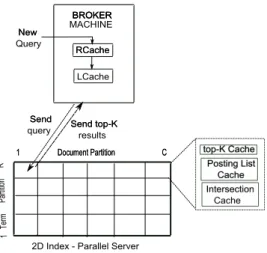
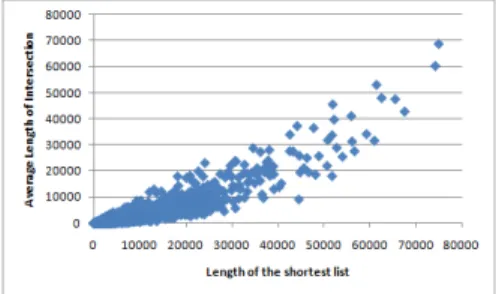
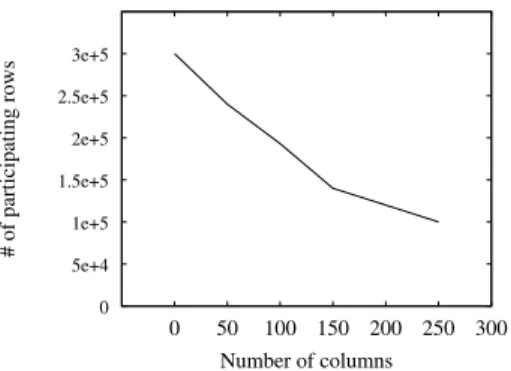
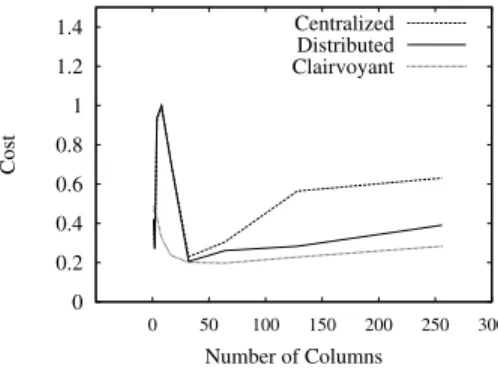
![Fig. 4. OR queries [Left] Normalized costs. [Right] Computation efficiency.](https://thumb-us.123doks.com/thumbv2/123dok_us/451822.2552472/12.918.223.718.282.455/fig-queries-left-normalized-costs-right-computation-efficiency.webp)
Related documents
Minors who do not have a valid driver’s license which allows them to operate a motorized vehicle in the state in which they reside will not be permitted to operate a motorized
4.1 The Select Committee is asked to consider the proposed development of the Customer Service Function, the recommended service delivery option and the investment required8. It
• Follow up with your employer each reporting period to ensure your hours are reported on a regular basis?. • Discuss your progress with
The corona radiata consists of one or more layers of follicular cells that surround the zona pellucida, the polar body, and the secondary oocyte.. The corona radiata is dispersed
Goldfish care Planning your aquarium 4-5 Aquarium 6-7 Equipment 8-11 Decorating the aquarium 12-15 Getting started 16-17 Adding fish to the aquarium 18-19 Choosing and
We obtain the rst fully polynomial randomized approximation scheme (FPRAS) for a broad class of multi-stage stochastic linear programming prob- lems with any constant number of
A policy in which all of the fixed assets of a firm are financed with long-term capital, but some of the firm’s permanent current assets are financed with short-term
When employees forget their password or forget to login/logout properly, helpdesk calls will increase to request password resets and front desk has to cover non-answered phone
