Chapter 6 Quantum Computing Based Software Testing Strategy
(QCSTS)
6.1 Introduction
Software testing is a dual purpose process that reveals defects and is used to evaluate quality attributes of the software, such as reliability, security, usability, and correctness. The critical problem in software testing is its time complexity. In this chapter a new concept of software testing strategy, based on quantum computing, has been explored to show how software testing time complexity can be reduced by the application of quantum computing based algorithms, in common, and Grover’s algorithm, in particular. The significance of said algorithm is to minimize not only time but also cost. Another added benefit of the algorithm is that the complexity is much less than other searching algorithms in use.
As described in [52] the quantum computer is very suitable for handling problem that is hard to be dealt with by conventional computers because of the need for one by one solution. To remedy this problem, the said algorithm is proposed for solving the issue of database inquires. As per discussion [49, 52], it is expected that the said quantum computer would be marketed in the next five years. Some progress in this direction has already been made.
As described in [25, 35, 46], 50% of the total system development time is spent in testing and costs accordingly. To resolve this problem some algorithms, tools or techniques to reduce the testing time and cost are required. The main problem of time taken may occur when the database is large and unsorted. As the tester executes test suites, the output message may show errors on a particular record. It becomes very difficult to reach the
particular record due to prolonged time and efforts required for correct record insertion because of a large sized database.
To overcome the problems of time and cost, we studied several search algorithms and finally decided Grover’s Algorithm to minimize both time and cost. The reason is that the complexity of the said algorithm is much lesser than other search algorithms.
6.2 Quantum Algorithm Based Software Testing
A possible software testing technique is to verify that the system should satisfy its state equation y = f(x) for all possible values of x-input(s) i.e. for all possible states of input(s), the actual states of y-output(s) should be the same as the desired ones. The desired outputs can be stored in a look-up table along with their corresponding inputs. Finding an error state in such a scenario is just like searching a record in an unsorted database. This can then be achieved effectively using the quantum algorithm namely, “Grover’s algorithm”.
The purpose of Grover’s Algorithm is described as searching unsorted databases with N entries using quantum computing in O(N1/2) time and using O(LogN) storage space, which makes it the fastest possible algorithm for searching an unsorted database as described in [10, 20, 36, 40]. This is because of the fact that searching an unsorted database in classical computing, requires at least a linear search, which is O(N) in time. Grover’s algorithm is obviously very useful and efficient when database (or N) is very large, just as in the case of complex software testing. Like many quantum computers’ algorithms, Grover’s algorithm is probabilistic in the sense that it gives the correct
answer with high probability. Repeating the algorithm can decrease the probability of failure.
The algorithm is based on quantum computing whereas Quantum Computers are expected in the world market in the near future as described in [36, 49]. By application of this algorithm it is expected that the testing time will be reduced considerably. Our existing digital computers are not capable to execute this algorithm because digital computers are based on 0 & 1 logic but quantum computers are based on qubits [0, . . . , 1]. The qubit is a system that belongs to closed interval [0, 1]. It takes the values |0>and
|1>, where notation ‘|>’ is called Dirac notation, and is a combination of intermediate
values of 0 and 1.
An important concept that is extensively used in Grover’s algorithm is that of
“Hadamard matrix”, which is a square matrix whose entries are either +1 or −1 and
whose rows are mutually orthogonal. This means that every two different rows in a
Hadamard matrix represent two perpendicular vectors. This matrix is directly used as an
error correcting code and to generate random numbers [9, 16, 18]
Grover’s algorithm is well organized, highly formal and unambiguous for “inverting a function”. This is because the algorithm is based on backtracking from output to input as we can always come up with a function y=f (x) that produces a particular value of y if x matches a desired entry in a database.
6.3 Application of Grover’s Algorithm for Software Testing
In order to express how the Grover’s algorithm contributes in software testing, we have automated the steps of the algorithm in an application program. The program takes “m”
as input, which is the value of required number of bits, necessary to hold N records and can be expressed as ⎡log2 N⎤. It then automatically generates the 2mx2m Hadamard
matrix (shown with/without the normalization factor) as well as the matrix of inversion
about average transformation (shown with/without the normalization factor).
The pseudo code for the important function of Hadamard matrix generation along with
the pseudo code for the application of Grover’s algorithm is given below:
6.3.1 Pseudo code for Hadamard Matrix Generation:
function HM(m, matrix, x, y) if(m=0)
matrix[x,y]:=1; else
for(i:=0; i<2m; i:=i+2m-1)
for(j:=0; j<2m; j:=j+2m-1)
if(i=j&&i=2m-1)
HM(m-1,matrix,x+i,y+j);
//negate the following portion of the matrix
matrix[x+i:2m-1-1,y+j:2m-1-1):=- matrix[x+i:2m-1-1,y+j:2m-1-1); else HM(m-1,matrix,x+i,y+j); end if end for end for end if end function
6.3.2 Pseudo code for Application of Grover’s Algorithm:
input m;
had_mat:=Define a matrix of dimensions 2m x 2m; HM(m,had_mat,0,0);
//Normalise the Hadamard matrix had_mat_norm:=had_mat/(2m/2);
A:=Define a matrix of dimensions 2m x 2m for inversion about average transformation; //Step1 of Grover’s algorithm
Qureg:= Define a matrix of dimensions 2m x 1; Qureg[0,0]:=1;
display(Qureg);
//Step2 of Grover's algorithm Qureg:=multiply(HMn,Qureg); display(Qureg);
//Step3 of Grover's algorithm
Random subroutine:=new Random(); rnum:=subroutine.Next(0,2m); do if(Qureg[rnum,0]>=0) Qureg[rnum,0]:=-Qureg[rnum,0]; end if display(Qureg);
//Step4 of Grover's algorithm Qureg:=multiply(A,Qureg);
display(Qureg);
until(desired probability not achieved); end do-until
Then, it applies the Grover’s algorithm step-by-step and displays the state of the Q-register after each step.
Figure 1: Application prompt to give new value or quit the application.
Figure 2: Application prompt to enter value of m (database items) and to
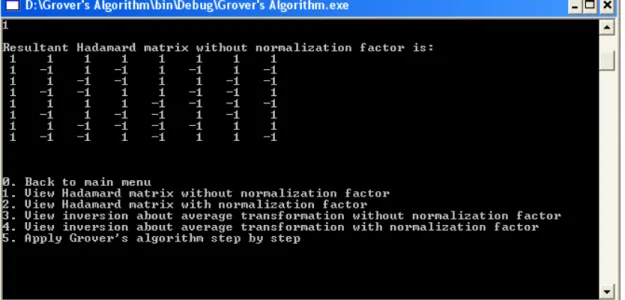
Figure 3: Consider m=3 i.e. the database has N=8 records
Figure 4: Displays a Hadamard Matrix of order 8x8 without normalization factor.
Where, “Hadamard matrix” is a square matrix whose entries are either +1 or −1 and
whose rows are mutually orthogonal”. This means that every two different rows in a Hadamard matrix represent two perpendicular vectors. This matrix is directly used as an error correcting code. The Hadamard matrix can also be used to generate random numbers.
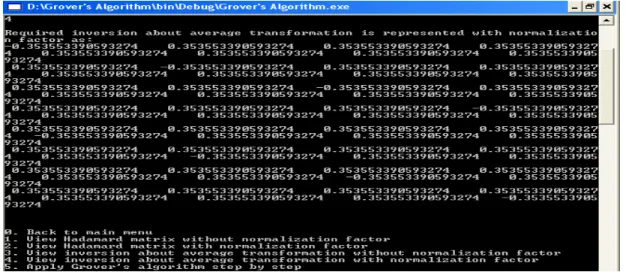
Figure 5: shows Hadamard matrix after multiplying the normalization factor which is
1/23/2
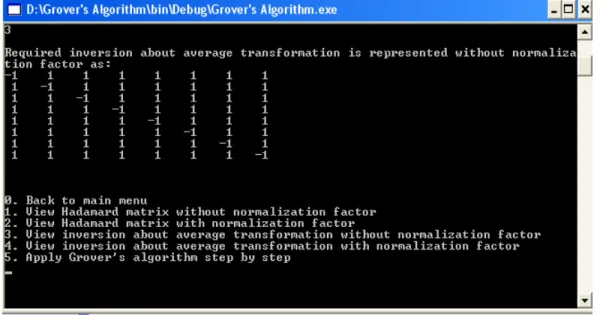
Figure 6: Displays an inversion about average, is represented by a matrix without
normalization factor. This inversion operator is meant to rotate the phase of a given search record.
Figure 7: Shows inversion about average with normalization factor
Then the Grover’s algorithm was applied step-by-step and the results were as follow: After step-1 of Grover’s algorithm, Qureg is:
1 0 0 0 0 0 0 0
After step-2 of Grover’s algorithm, Qureg is: 0.353553390593274
0.353553390593274 0.353553390593274 0.353553390593274
0.353553390593274 0.353553390593274 0.353553390593274 0.353553390593274
After step-3 of Grover’s algorithm, Qureg is: 0.353553390593274 0.353553390593274 0.353553390593274 0.353553390593274 0.353553390593274 -0.353553390593274 0.353553390593274 0.353553390593274
After step-4 of Grover’s algorithm, Qureg is: 0.5 0.5 0.5 0.5 0.5 1 0.5 0.5
In the last step of Grover’s algorithm, the 6th row gets the probability “1”, identifying itself to be the desired mark state.
The important point to note here is that the complexity statistics of this application program would clearly contradict the desired complexity of Grover’s algorithm that is O (N1/2). This is because of the fact that the algorithm is dependent on a quantum subroutine that marks a unique state, satisfying the condition C (S v) =1, in unit time. Obviously no reason can be assigned to this contradiction because of the current usage of a classical computer. This contradiction shall be defeated when the quantum subroutine becomes operational.
Since the working procedure of the quantum subroutine is something in a black box for
the Grover’s algorithm, therefore, the application program takes assistance of a random-number generator that marks any record randomly whenever required. However, even this random marking of the record requires a traversing of the database and the worst-case complexity of even this traversal is O (N).
Therefore, this useful program (especially for large values of m) is only for application purposes. For achieving the same complexity and optimization as that of the Grover’s algorithm, we would have to wait for the quantum subroutine to become operational and its incurrence.
As per discussion above, it is possible that this time complexity can be achieved by applying a fast searching mathematical algorithm known as Grover’s Algorithm for unsorted database which is O(N1/2). If quantum subroutine is available (which is expected in the near future), this time complexity will be at least 100 times faster than any other
possible algorithm for searching an unsorted data base (If N is very large). For example, if the number of database items is N=10000 and the error occurred at N=9998, then this algorithm technique will search the required error item in maximum of 100 iterations. In comparison to this algorithm, any other possible algorithm requires a traversing of the database and the worst traversal is of O (N).
6.4 Conclusions and Future Enhancement
The complexity and time-consuming task of identification and correction of errors in software-testing phase can easily be transformed into a scenario of searching a record in a database. It is very much expected that the application of quantum-computing, based on the quantum algorithm, can accomplish more accurately and unambiguously and in much lesser time the database testing phase successfully. The novelty of the said algorithm is the provision of the facility of reducing the time-complexity by a factor of O (N1/2). As and when the Quantum computing becomes operational in the market it is very much hoped that the said strategy shall play a vital role to reduce time factor.