HTML Web Content Extraction Using
Paragraph Tags
Howard J. Carey, III, Milos Manic
Department of Computer Science Virginia Commonwealth UniversityRichmond, VA USA [email protected], [email protected]
Abstract— With the ever expanding use of the internet to disseminate information across the world, gathering useful information from the multitude of web page styles continues to be a difficult problem. The use of computers as a tool to scrape the desired content from a web page has been around for several decades. Many methods exist to extract desired content from web pages, such as Document Object Model (DOM) trees, text density, tag ratios, visual strategies, and fuzzy algorithms. Due to the multitude of different website styles and designs, however, finding a single method to work in every case is a very difficult problem. This paper presents a novel method, Paragraph Extractor (ParEx),of clustering HTML paragraph tags and local parent headers to identify the main content within a news article. On websites that use paragraph tags to store their main news article, ParEx shows better performance than the Boilerpipe algorithm with higher F1 scores of 97.33% to 88.53%.
Keywords—HTML, content extraction, Document Object Model, tag-ratios, tag density.
I. INTRODUCTION
The Internet is an ever growing source of information for the modern age. With billions of users and countless billions of web pages, the amount of data available to a single human being is simply staggering. Attempting to process all of this information is a monumental task. Vast amounts of information that may be important to various entities are provided in web based news articles. Modern day news websites are updated multiple times a day making more data constantly available. These web based articles offer a good source for information because of the relatively free availability, ease of access, large amount of information, and ease of automation. To analyze news articles from a paper source, the articles would first have to be read into a computer, making the process of extracting the information within much more cumbersome and time consuming. Due to the massive amount of news articles available, there is simply too much data for a human to manually determine which of this information is relevant. Thus, automating the extraction of the primary article is necessary to allow further data analysis on any information within a web page.
To help analyze the content of web pages, researchers have been developing methods to extract the desired information from a web page. A modern web page now a days consists of
numerous links, advertisements, and various navigation information. This extra information may not be relevant to the main content of the web page, and can be ignored in many cases. This additional information, such as ads, can also lead to misleading or incorrect information being extracted. Thus, determining the relevant main content of a web page among the extra information is a difficult problem.
Numerous attempts have been made in the past two decades to filter the main content of a web page. Therefore, this paper presents Paragraph Extractor (ParEx), a novel method used to identify the main text content within an article on a website while filtering out as much irrelevant information as possible. ParEx relies upon using HTML paragraph tags, denoted by p in HTML, combined with clustering and entity relationships to extract the main content of an article. It was shown that ParEx had very high recall and precision scores on a set of test sites that use p tags to store their main article content and have little to no user comment section.
This rest of this paper is organized in the following format: Section II examines related works in the field. Section III details the design methodology of ParEx. Section IV discusses the evaluation metrics used to test the method. Section V describes the experimental results of ParEx. And finally, section VI summarizes the findings of this paper.
II. RELATED WORKS
Early attempts at content extraction mostly had some sort of human interaction required to identify the important features of a website, such as [1],[9],[10]. While these methods could be accurate, they were not easily scalable to bulk data collection. Other early methods employed various natural language processing methods [7] to help identify relationships between zones of a web page, or utilized HTML tags to identify various regions within the text [14]. Kushmerick developed a method to solely identify the advertisements in a page, and remove them [11].
Many methods attempt to utilize the Document Object Model (DOM) to extract formatted HTML data from websites [3, [4]. DOM provides “a platform and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure and style of
documents.” [13]. In [2], Gongquing et al. utilized a DOM tree to help determine a text-to-tag path ratio, while in [20] Mantratzis et al. developed an algorithm that recursively searches through a DOM tree to find which HTML tags contained a high density of hyperlinks.
Layouts can be common throughout web pages in the forms of templates. Detection of these templates and the removal of the similar content that occurs between multiple web pages can leave the differing content between them, which can be the main article itself, as found by Bar-Yossef et al. in [22]. Chen et al. in [15] explored a method of combining layout grouping and word indexing to detect the template. In [16] and [23], Kao et al. developed an algorithm that utilized the entropy of feature, links, and content of a website to help identify template sections. And Yi et al. in [17] proposed a method to classify and cluster web content using a style tree to help compare between website structures to determine the template used. Kohlschütter [30] developed a method, Boilerpipe, to detect shallow text features in templates to help detect the boilerplate (any section of website which is not considered main content) using the number of words and link density of a website.
Much research tends to build on the work from previous researchers. In [5], Gottron provided a comparison between many of the content extraction algorithms at the time, and modified the document slope curve algorithm from [18]. The modified document slope curve proved the best within his test group. In [18], Pinto et al. expanded on the work of Body Text Extraction from [14] by utilizing a document slope curve to identify content vs. non-content pages in hopes of determining whether a web page had content worth extracting or not. Debnath et al. proposed the algorithms ContentExtractor [21] and FeatureExtractor [22], that compared similarity between blocks across multiple web pages and classified sections as content with respect to a user defined desired feature set.
In [19], Spousta et al. developed a cleaning algorithm that involved regular expression analysis and numerous heuristics involving sentence structure. Their results performed poorly on web pages with poor formatting or numerous images and links. Gottron [24] utilized a content code blurring technique to identify the main content of an article. The method involved applying a content code ratio to different areas of the web page and analyzing the amount of text in the different regions.
Many recent works have taken newer approaches, but still tend to build on the works of previous research. In [12], Bu et al. proposed a method to analyze the main article using fuzzy association rules (FAR). They encoded the min., mean, and max values of all items and features for a web page into a fuzzy set and achieved decent, but quick, results. Song et al., in [6] and Sun et al. [8], expanded on the tag path ratios by looking at text density within a line and taking into account the number of all hyperlink characters in a subtree compared to all hyperlink tags in a subtree. Peters et al. [25] combine elements of Kohlschutter’s boilerplate detection methods, [30], and Weninger’s CETR methods, [3] and [4], into a single machine learning algorithm. Their combined methodology showed improvements over using just a single algorithm, however had trouble with websites that used little CSS for formatting.
Nethra et al. [26] created a hybrid approach using feature extraction and decision tree classification. They used C4.5 decision tree and Naïve Bayes classifiers to determine which features were important in determining main content. In [27], Bhardwaj et al. proposed an approach of combining the word to leaf ratio (WLR) and the link attributes of nodes. Their WLR was defined as the ratio between the number of words in a node to the number of leaves in the subtree of said node. In [28], Gondse et al. proposed a method of extracting content from unstructured text. Using a web crawler combined with user input to decide what to look for, the crawler analyzes the DOM tree of various sites to find potential main content sections. Qureshi et al. [29] created a hybrid model utilizing a DOM tree to determine the average text size and link density of each node.
No algorithm has managed to achieve 100% accuracy in extracting all relevant text from websites so far. With the ever changing style and design of modern web pages, different approaches are continually needed to keep up with the changes. Some algorithms may work on certain websites but not others. There is much work left to be done in the of website content extraction.
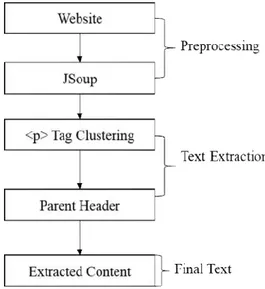
III. PAREX WEB PAGE CONTENT EXTRACTION METHOD The steps involved in ParEx are shown in Figure 1. The
Preprocessing step starts with the original website’s HTML being extracted and parsed via JSoup [32]. The Text Extraction section locates and extracts the main content within the website. The Final Text is then analyzed using techniques elaborated on in section IV.
A. Preprocessing
The HTML code was downloaded directly from each website and parsed using the JSoup API [32] to allow easy filtering of HTML data. In this way, HTML tags were pulled out, processed and extracted from the original HTML code. JSoup also simplified the process of locating tags and parent
tags, allowing for quicker testing of the method. B. p Tag Clustering
The presented ParEx method combines a number of methods used in previous papers into a single, simple, heuristic extraction algorithm. The initial idea stems from the work of Weninger et al., [3], [4], and Sun et al., [8], using a text-to-tag ratio value. Weninger et al. showed that the main content of a site generally contains significantly more text than HTML tags. A ratio of the number of non-HTML tag characters to HTML tag characters was, with higher ratios being much more likely to contain the main content of an HTML document. A down side of this method is it will grab any large block of text, which can sometimes include comments sections on many websites. The method to calculate the text to tag ratio in this experiment is as follows:
tagCount textCount
tagRatio
Where the textCount variable is the number of non-tag characters contained in the line and tagCount is the number of HTML tags contained in the line. The tagRatio variable uses the number of characters in the line instead of the number of words to prevent any biases from articles that use fewer, but longer, words, or vice versa. The character count gives a definitive length of the line without concern to the length of the individual words.
Typically, the main HTML content is placed in paragraph tags, denoted by p , and having a high text-to-tag ratio. However, advertisements can contain a massive amount of characters while only containing a few HTML tags, which can fool the algorithm in the form of a high text-to-tag ratio. To filter out these cases from the main content, a clustered version of the regular tagRatios (1) is used in the ParEx to find regions of high text-to-tag ratios as opposed to simple one-liners. The clustered text-to-tag ratio uses a sliding window technique to assign an average text-to-tag ratio from the line in question, and the two lines before and after it. This gives each line of HTML two ratios, an absolute text-to-tag ratio which determines the text-to-tag ratio of the individual line, and a relative tag ratio which determines the average text-to-tag ratio of the sliding window cluster.
Figure 2 shows an example of the clustered text-to-tag ratio. The second column of numbers represents the absolute text-to-tag ratio for each line. Line 3 will be assigned a clustered ratio that is the average of lines 1-5, 31.8. Line 4 will
be assigned a clustered ratio that is the average of lines 2-6, 32.8. This process is repeated for all lines in the raw HTML, before any other formatting is done. This clustering helps filter out one line advertisements or extraneous information that have high to-tag ratios while favoring clusters of high text-to-tag ratios.
C. Parent Header
The novelty in this paper recognizes that most (all for the websites tested) websites group their entire main article under one parent header together, either under p tags or li tags. Essentially, this means if a single line of the main content can be identified, the entire section can be extracted by finding the parent header tag of the single line. Once every line has a relative tag ratio, the p tags with the highest relative tag ratio is extracted.
The highest relative tag ratio will help to find the single sentence that is most likely to contain the main article text within it. This extracted line’s parent header is taken to be the master header for the web page. All p tags under this master header are then extracted and considered to be the primary article text within the web page. Examples of this procedure are shown in Figures 3 and 4 and discussed below.
In Figure 3, there are three p tags. If line 3 has the greatest relative text-to-tag ratio, it is extracted as the most likely to contain the main content. The parent of line 3 is found as local . Then, all p tags under local are extracted and considered to be the main content. While main is the most senior parent in the tree, only the immediate parent is chosen when determining the parent of the relative p tag. Selecting a more senior parent generally selects more information than the desired content. Also in this case, no tags under next would be chosen.
Lists in HTML are often used to list out various talking points within an article, however these are not generally formatted into p tags, but into list tags, denoted by li . If any li tags are found within the master header, then their text contents are added to the extracted article text as well.
In Figure 4, if the p tag on line 3 was chosen as the main content containing line, then all p tags under the local
Figure 2: Example showing the clustered text-to-tag ratio.
tag would be extracted. However, information within the list tags, li , would also be extracted, as the algorithm recognizes any p as well as li tags under the chosen master parent tag.
Once the final list of p and li tags are extracted, the text of these tags is compared to the original, annotated data that was extracted using methods discussed in section A. The techniques used to evaluate the effectiveness of the algorithm are discussed in the next section of the paper.
IV. EVALUATION METRICS
Three metrics are used to evaluate the performance of the ParEx, precision, recall, and F1 score. These are standard evaluation techniques used to determine how accurate an extracted block of text is compared to what it is supposed to be. Precision (P) is a ratio between the size of the intersection of the extracted text and the actual text, over the size of the extracted text. Precision gives a measurement of how relevant the extracted words are to the actual desired content text and is expressed as:
S
S
S
E A E P where SE is the extracted text from the algorithm and SA is the actual article text.
Recall (R) is a ratio between the size of the intersection of the extracted text and the actual text, over the size of the actual text. Recall gives a measurement of how much of the relevant data was accurately extracted and is expressed as:
S
S
S
A A E R where SE is the extracted text from the algorithm and SA is the actual article text that serves as the base line comparison for accuracy.
The F1 (F) score is a combination of precision and recall, allowing for a single number to represent the accuracy of the algorithm. It is expressed as:
R
P
R
P
F
2
where P is the precision and R is the recall.
These metrics analyze the words extracted from each algorithm and compare them to the words in the article itself. If the words extracted from the algorithm closely match the actual words in the article, the F1 score will be higher. Using these three scoring methods allows for a numerical comparison between various algorithms. F1 score is important because looking purely at either precision or recall can be misleading. Having a high precision but low recall value means nearly all of the extracted data was accurate, however it does not tell any information on how much relevant information is missing. Having a high recall but low precision value means nearly all of the data that should have been extracted was, but it does not tell any information on how much extra, non-relevant data was also extracted. Thus, the F1 score is useful as it allows a combination of both precision and recall to determine a balance between the two.
ParEx was tested against manually extracted data from each website. This allowed the results to be verified against a known dataset. The precision, recall, and F1 score were obtained by using the set of words that appeared in the manually extracted text and comparing against the set of words extracted by the tested algorithms. No importance was given to the order in which certain words appeared.
V. EXPERIMENTAL RESULTS
The hypothesis being tested was whether or not the ParEx method would be a more effective extraction algorithm than Boilerpipe on websites which used p tags to store their main content and had little to no user comment sections. To test this hypothesis, 15 websites were selected which exhibited these characteristics and 15 websites which did not exhibit these characteristics were selected.
The websites selected were mostly local news based websites, such as FOX, CBS, NBC, NPR, etc., with a subject focus on critical infrastructure events in local areas. All 30 of the articles selected were from different websites. The wide variety of websites allowed both methods to be tested on as diverse a set of sites as possible. The use of news article sites as opposed to other sites, such as blogs, forums, or shopping sites, is because news sites tend to have a single primary article of discussion per site. To acquire HTML data form these sites, it was simply downloaded from the website directly. To compare the algorithm’s extracted text with the actual website main content text, the main content needed to be extracted and annotated. The annotation was done manually, by a human. The final decision about what was considered relevant to the main article within the website was up to the annotator. Figure 4: li tag extraction example.
This method of manual content extraction for comparison has some inherent error risk involved. Different people may consider different parts of an article as main content. For instance, the title and header of the article may be viewed as main content or not. The author information at the bottom of an article may or may not be viewed as main content by different people. For the purposes of this paper, only the main news article content was considered, leaving off any author information, contact information, titles, or author notes. With this in mind, a certain amount of error is to be expected even with accurate algorithm results.
The accuracy of ParEx was compared against the accuracy of the Boilerpipe tool, developed by Kohlschutter [30]. Boilerpipe is a fully developed tool that is publically available and provides numerous methods of content extraction via an easy to use API [31] allowing easy testing and performs well on a broad range of website types.
Table I shows ParEx performed better than Boilerpipe in all metrics for websites that exhibited the required characteristics. Table II shows Boilerpipe performed much better than ParEx on websites that did not exhibit the required characteristics. These results support the original assumption, for websites that use p tags to store their main content and have limited to no user comment sections ParEx will have a higher performance.
Examining the differences of each method between both tables I and II shows that while ParEx may be more accurate on sites that exhibit the required characteristics, Boilerpipe is a more generalizable method. ParEx claims an F1 score of 97.33% on the first data set, while only a 33.73% on the second. Boilerpipe, however, achieves F1 scores of 88.53% on the first set, and 82.53% on the second. Boilerpipe does not work as well on sets that exhibit the characteristics required for ParEx, but it performs more consistently on multiple types of websites.
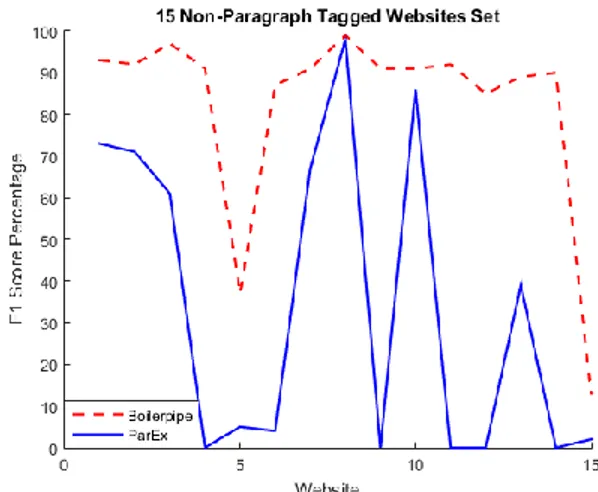
Figure 5 emphasizes the performance of ParEx over Boilerpipe. ParEx performed as good as or better for every website tested. Figure 6 demonstrates Boilerpipe’s resiliency over the non-paragraph tagged websites. Note that Figure 6 is scaled from 60%-100% on the y-axis. While dipping to ~40% and ~10% on two of the websites, its performance on the majority of the test sites is relatively consistent with that of the first set of test sites in Figure 5. Figure 6 also shows that, while ParEx performs poorly on most of the chosen sites, it still manages to perform quite well on a couple of the websites. As expected, it was found that many of the websites where ParEx performed poorly was because the website did not use p tags to store their main content. This led to a score of 0 (see Figure 6), as the text-to-tag ratio only examines p tags for text, and since there were no p tags, there was no text. Also to be expected, on many of the sites in Table II, the ParEx’s relative text-to-tag ratio had selected a comment section on the website. If there was no overlap in words used in the comment section with the actual article, the resulting score was 0%. If there was some minimal amount of overlap in words, it led to a very low result. Thus the two identified primary requirements of a website to work well with ParEx are: 1) it requires websites to use paragraph tags to store then main article TABLE I:SCORE COMPARISON BETWEEN BOTH METHODS ON
THE SET OF <P> TAGGED SITES.
Method ParEx Boilerpipe
Metric Scores Standard
Deviation Scores Standard Deviation Precision 96.07% 3.53% 85.07% 8.44% Recall 98.73% 1.19% 94.00% 5.20% F1 Score 97.33% 2.04% 88.53% 7.02%
TABLE II:SCORE COMPARISON BETWEEN BOTH METHODS ON THE SET OF NON <P> TAGGED SITES.
Method ParEx Boilerpipe
Metric Scores Standard
Deviation Scores Standard Deviation Precision 40.33% 38.36% 77.53% 15.55% Recall 41.53% 40.84% 90.80% 10.88% F1 Score 33.73% 34.52% 82.53% 15.34%
Figure 5: Individual website results for the p tagged website set.
content, 2) the method is susceptible to comment sections, or other large blocks of text that may fool the clustering algorithm by selecting the wrong block of text as the main content.
VI. CONCLUSION
This paper presented a new method called ParEx to evaluate the content within a website and extract the main content text within. Building upon previous work with the text-to-tag ratio and clustering methods, the presented ParEx method focused only on the paragraph tags of each website, making the assumption that most websites will have their main article within a number of p tags. Two primary requirements were found to optimize the success of ParEx: 1) websites must use p tags to store their article content, 2) use websites that have limited or no user comment sections. The results showed that the ParEx method showed overall better performance than Boilerpipe on websites that exhibited these characteristics (with F1 scores of 97.33% vs. 88.53% for the Boilerpipe). This confirms the requirement for the ParEx approach.
Future work includes further improving the content extraction accuracy by improving the clustering algorithm and text-to-tag ratio metric to increase the likelihood that the algorithm will select the correct chunk of p tags to extract as the main content as opposed to a user comment section. Comparing the differences between a tag ratio that uses characters to one that uses words can also be explored.
ACKNOWLEDGMENT
The authors would like to thank support given by Mr. Ryan Hruska of the Idaho National Laboratory (INL) who helped make this effort a success.
REFERENCES
[1] S. Gupta, G. Kaiser, P. Grimm, M. Chiang, J. Starren, “Automating Content Extraction of HTML Documents,” in World Wide Web, vol. 8, no. 2, pp. 179-224, June 2005.
[2] G. Wu, L. Li, X. Hu, X. Wu, “Web news extraction via path ratios,” in
Proc ACM intl. conf. on information & knowledge management, pp. 2059-2068, 2013.
[3] T. Weninger, W.H. Hsu, "Text Extraction from the Web via Text-to-Tag Ratio," in Database and Expert Systems Application, pp.23-28, Sept. 2008.
[4] T. Weninger, W.H. Hsu, J. Han, “CETR: content extraction via tag ratios,” in Proc. Intl. conf. on World wide web, pp. 971-980, April 2010. [5] T. Gottron, "Evaluating content extraction on HTML documents," in Proc. Intl. conf. on Internet Technologies and Apps, pp. 123-132. 2007. [6] D. Song, F. Sun, L. Liao, "A hybrid approach for content extraction with
text density and visual importance of DOM nodes,"in Knowledge and Information Systems, vol. 42, no. 1, pp. 75-96, 2015.
[7] A.F.R. Rahman, H. Alam, R. Hartono, "Content extraction from html documents," in Intl. Workshop on Web Document Analysis, pp. 1-4, 2001.
[8] F. Sun, D. Song, L. Liao, “DOM based content extraction via text density,” in Proc. Intl. conference on Research and development in Information Retrieval, pp. 245-254, 2011.
[9] B. Adelberg, “NoDoSE—a tool for semi-automatically extracting structured and semistructured data from text documents,” in Proc. ACM Intl. conf. on Management of data, pp. 283-294, 1998.
[10] L. Liu, C. Pu, W. Han. "XWRAP: An XML-enabled wrapper construction system for web information sources," in Proc. Intl. Conf. on Data Engineering, pp. 611-621, 2000.
[11] N. Kushmerick, "Learning to remove Internet advertisements," in Proc. Conf. on Autonomous Agents, pp. 175-181, 1999.
[12] Z. Bu, C. Zhang, Z. Xia, J. Wang, "An FAR-SW based approach for webpage information extraction,"Information Systems Frontiers, vol. 16, no. 5, pp. 771-785, February 2013.
[13] L. Wood, A. Le Hors, V. Apparao, S. Byrne, M. Champion, S. Isaacs, I. Jacobs et al., "Document object model (DOM) level 1 specification," in W3C Recommendation, 1998.
[14] A. Finn, N. Kushmerick, B. Smyth. "Fact or fiction: Content classification for digital libraries," in Joint DELOS-NSF Workshop on Personalisation and Recommender Systems in Digital Libraries, 2001. [15] L. Chen, S. Ye, X. Li, "Template detection for large scale search
engines," in Proc. ACM symposium on Applied Computing, pp. 1094-1098, 2006.
[16] H. Kao, S. Lin, J. Ho, M. Chen, "Mining web informative structures and contents based on entropy analysis,"in Trans. on Knowledge and Data Engineering, vol.16, no. 1,pp. 41-55, January 2004.
[17] L. Yi, B. Liu, X. Li, "Eliminating noisy information in web pages for data mining," in Proc. ACM intl. conf. on knowledge discovery and data mining, pp. 296-305, 2003.
[18] D. Pinto, M. Branstein, R. Coleman, W.B. Croft, M. King, W. Li, et. al., "QuASM: a system for question answering using semi-structured data," in Proc. ACM/IEEE-CS joint conference on Digital libraries, pp. 46-55, 2002.
[19] M. Spousta, M. Marek, P. Pecina, "Victor: the web-page cleaning tool," in 4th Web as Corpus Workshop (WAC4)-Can we beat Google, pp. 12-17, 2008.
[20] C. Mantratzis, M. Orgun, S. Cassidy, "Separating XHTML content from navigation clutter using DOM-structure block analysis," in Proc. ACM conf. on Hypertext and hypermedia, pp. 145-147, 2005.
[21] S. Debnath, P. Mitra, C. L. Giles, "Automatic extraction of informative blocks from webpages," in Proc. ACM symposium on Applied computing, pp. 1722-1726, 2005.
[22] S. Debnath, P. Mitra, C. L. Giles, "Identifying content blocks from web documents," in Foundations of Intelligent Systems, pp. 285-293, 2005. [23] S. Lin, J. Ho, "Discovering informative content blocks from Web
documents," in Proc. ACM SIGKDD intl. conf. on Knowledge discovery and data mining, pp. 588-593, 2002.
[24] T. Gottron, "Content code blurring: A new approach to content extraction," in Intl. Workshop on Database and Expert Systems Application, pp. 29-33, 2008.
[25] M.E. Peters, D. Lecocq, "Content extraction using diverse feature sets," in Proc. Intl. conf. on World Wide Web companion, pp. 89-90, 2013. [26] K. Nethra, J. Anitha, G. Thilagavathi, "Web Content Extraction Using
Hybrid Approach," in ICTACT Journal On Soft Computing,vol. 4, no. 02 (2014).
[27] A. Bhardwaj, V. Mangat, "A novel approach for content extraction from web pages," in Recent Advances in Engineering and Computational Sciences, pp. 1-4, 2014.
[28] P. Gondse, A. Raut, "Primary Content Extraction Based On DOM," in Intl. Journal of Research in Advent Technology, vol. 2, no. 4, pp. 208-210, April 2014.
[29] P. Qureshi, N. Memon, "Hybrid model of content extraction,"in Journal of Computer and System Sciences,vol. 78, no. 4, pp. 1248-1257, July 2012.
[30] C. Kohlschütter, P. Fankhauser, W. Nejdl, “Boilerplate detection using shallow text features,” in Proc. ACM intl. conf. on Web search and data mining, pp. 441-450, 2010.
[31] C. Kohlschütter. (2016, Jan.). boilerpipe [Online]. Available: https://code.google.com/p/boilerpipe/
[32] J. Hedley. (2016, Jan.). jsoup HTML parser [Online]. Available: http://jsoup.org