Transport Protein Classification through Structured
Prediction and Multiple Kernel Learning
Hongyu Su
Helsinki Institute for Information Technology Department of Computer Science
Aalto University, Finland [email protected]
Giorgio Valentini Anacleto Lab
Department of Computer Science University of Milan, Italy [email protected]
Sandor Szedmak
Helsinki Institute for Information Technology Department of Computer Science
Aalto University, Finland [email protected]
Juho Rousu
Helsinki Institute for Information Technology Department of Computer Science
Aalto University, Finland [email protected]
1
Introduction
Membrane transport systems comprise roughly 10% of all proteins in a cell and play a critical role in many biological processes [1]. Improving and expanding their classification is an important goal that can affect studies involving comparative and functional genomics, probing molecular mechanisms of diseases and metabolic processes, and searching new therapeutic targets and pharmacologically relevant transport proteins. In this context, a relevant classification problem is represented by the characterization of transport proteins according to the TC (Transporter Classification) data base (TCDB). Indeed by exploiting this hierarchical taxonomy that includes thousands of families and subfamilies of transporters we implicitly predict the mode of action of the transport activity, the energy coupling mechanism used for the transport, the phylogenetic grouping of the proteins and their substrate specificity [2].
The computational methods proposed so far in literature significantly contributed to enlighten the critical roles played by transporters in the living cells and in several diseases, but suffer of several drawbacks that limit their effectiveness in proteome-wide studies [3]. In particular, most of the proposed computational approaches have been applied to specific categories of transporters (e.g. only to a small subset of the transporter families, or limited to only the most general classes or subclasses of the TCDB), or to specific organisms, and we lack of computational analyses extended to the overall TCDB taxonomy and involving transporters belonging to large sets of organisms. Most methods used only part of the available features that could be helpful to predict transport proteins, but other features could be added in an integrated prediction system to significantly improve performance [3]. Moreover, to our knowledge no methods exploited the hierarchical nature of the TC taxonomy, thus loosing relevant a priori information about the hierarchical relationships between classes.
In this work we introduce an integrative machine learning based approach that tries to consider all the above issues. To this end we propose a novel structured-output method able to explicitly consider the hierarchical relationships between TCDB categories. The proposed classifier exploits state-of-the-art Multiple Kernel Learning (MKL) strategies to integrate a very large set of features extracted from up-to-date databases and it is conceived to be applied virtually to any organism for the TCDB-wide and proteome-wide prediction of the categories of transporters.
2
Methods
We consider a supervised learning setting with an arbitrary input spaceX and an output spaceY consisting of the set ofℓdimensional multilabel vectorsy = (y1,· · ·, yℓ), yi ∈ {+1,−1}whose components are called microlabels. In transporter protein classification problem, xis a protein sequence andyis a vector of all possible function classes. We assume a collection ofpinput feature maps{φk(x)}
p
k=1in which thekth feature mapφk(x) ∈ Rdk transforms an input x ∈ X into a feature space ofdk dimension. The task is to estimate a functionf : X → Y computing the best multilabelyfor an inputx.
2.1 Multiple kernel learning
We assumepinput kernels{K1,· · ·, Kp}composed frompdifferent input feature maps and an
ideal target kernel computed by Ky = Y Y′ where the rows ofY are formed of the multilabel
vectors. We assume that all kernels are centered in the corresponding feature space. As input features generated from transporter protein sequences are heterogeneous, a uniform combination of corresponding kernel matrices will be suboptimal. Therefore, we conside the following two advanced multiple kernel learning (MKL) approaches.
Centered Kernel Alignment (ALIGN). This approach computes a weighted combination of in-put kernels [4] KALIGN =
∑p
k=1αkKkc the corresponding weights, αk, are computed by αk = ⟨Kc,Kc
y⟩F ||Kc||
F||Kyc||F
, where⟨·,·⟩F denotes the Frobenius product and|| · ||Fis the Frobenius norm. Two-StageMKL(ALIGNF). This approach improvesALIGNby assuming the correlation between input kernels.ALIGNFcomputes a convex combination of input kernels [4]KALIGNF =
∑p k=1βkK
c k, where kernel weightsβk are learned such that the alignment between the combined kernel and the target kernel is maximized
max β ⟨KcALIGNF, Kyc⟩F ||KALIGNF||FKycF , s.t. p ∑ k=1 β2k= 1, βk≥0,∀k.
Uniform Kernel Combinationis used as the baseline. This approach computes an ‘average’ kernel from input kernel matrices
KUNIF = 1 p p ∑ k=1 Kkc,
which is equivalent to concatenating original feature vectors. 2.2 Hierarchical multilabel classification approaches
The transport classification (TC) is a four-level hierarchical system defined on transporter protein function classes. In particular, the system is a rooted tree in which nodes correspond classes and directed edges correspond to relationship between classes and subclasses.
We use two different multilabel classification approaches to predict the hierarchy.
Hierarchical Structured Output Prediction (SOP) . The first method is based on the hierarchical structured output prediction framework of [5, 6] that models the hierarchy as an associative Markov networkG= (E, V)where nodes corresponds to microlabels (classes). There is an edge(i, j)∈E
if two microlabelsyiandyjare connected in the underlying classification hierarchy.
The proposed model (SOP) is based on embedding the input and output into a joint feature space and learning in that space a linear score functionF(w,x,y) =⟨w, ϕϕϕ(x,y)⟩given by the inner product of parametersw and the joint featureϕϕϕ(x,y). The joint feature mapϕϕϕ(x,y)is composed by the tensor product of the input feature mapφφφ(x)and the output feature mapψψψ(y). The tensor prodct will then consist all pairs of input and output featuresϕϕϕi,j(x,y) =φφφi(x)ψψψj(y).
The output feature map will encode the multilabelyaccording to the structure of the networkG
defined by
ψ(y) = (ψe,ue(y))e,ue = (1{ye=ue})e,ue, e∈E, ue={+1,−1}
where1{·}is the indicator function. In other words, for each edgeeand edge labelue, we define the featureψe,ue(y)to be 1 if edge labelyeisuein the networkG(and 0 otherwise).
The feature weight parameterswof the score function are learnt by optimizing the following regu-larized structured output learning problem
min w,ξi 1 2||w|| 2 2+C m ∑ i=1 ξi (1) s.t. ⟨w, ϕϕϕ(xi,yi)⟩ − max y∈Y/yi ⟨w, ϕϕϕ(xi,y)⟩ ≥ℓ(yi,y)−ξk, ξi≥0,∀i∈ {1, . . . , m},
where|| · ||2denotes theL2norm, andℓ(y,yi)is the loss function defined on two multilabels. The impact of the constraints of the above optimization problem is to push the score of inputxiwith correct multilabelyiabove the scores of all competing multilabelsy∈ Y/yi. The slack parameters
ξiis used to relax the constraints so that a feasible solution can always be found. Cis the margin slack parameter that controls the amount of regularization in the model. The objective minimizes the L2-norm of the weights and the slacks allocated to the training data which is equivalent to
maximizing the margin subject to allowing some data to be outliers.
The search space appears to be exponential in the number of microlabels|Y| = 2ℓ. However, we observe that a valid functional annotation is always a simple path from the root to a leave in the transport classification (TC) system. Therefore, we are able to substantially reduce the search space to a set of valid annotations which is linear in the number of leaves inG. The exponential reduction of the search space dramatically improves the training time and the performance of the model. To allow the use of kernels for high dimensional feature spaces, we use marginalized dual representation [7, 5] of (1) combined with conditional gradient descent algorithm.
Max-margin regression (MMR). To find the most suitable type of kernels the exponentially large search space is a real bottleneck. To alleviate that problem we can apply a compressed approach provided by the Maximum Margin Regression (MMR) whose primal formulation is given as
minw,ξi 1 2||w|| 2 2+C m ∑ i=1 ξi s.t. ⟨ψ(yi),wϕ(xi)⟩ ≥1−ξi, ξi≥0,∀i∈ {1, . . . , m}.
In theMMRthe input and output objects are separated, and the multilabel vectors are handled as complete entities by ignoring the potential interactions between the microlabels, [8]. This approach allows to scan the possible kernels at the cost of a simple SVM type binary classification problem.
3
Data and Experiments
Data. We collect 12546 protein sequences from Transporter Protein Classification Database (TCDB) [2]. After removing duplications,12515unique protein sequences are remained. We anno-tate each protein with3145function classes extracted from the classification hierarchy. The structure of the hierarchy is also collected and used as the underlying Markov network.
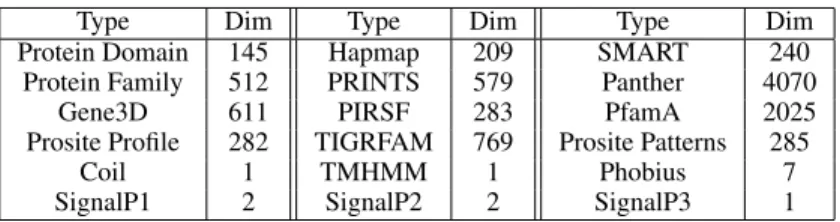
For each protein sequence, we also generate sequence similarity features by aligning the sequence against the whole TCDB database with BLAST. In addition, we generate18different features with InterProScan [9]. The statistics of the features are illustrated in Table 1.
Type Dim Type Dim Type Dim
Protein Domain 145 Hapmap 209 SMART 240
Protein Family 512 PRINTS 579 Panther 4070
Gene3D 611 PIRSF 283 PfamA 2025
Prosite Profile 282 TIGRFAM 769 Prosite Patterns 285
Coil 1 TMHMM 1 Phobius 7
SignalP1 2 SignalP2 2 SignalP3 1
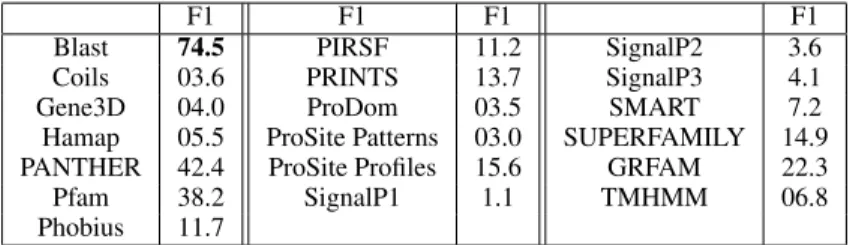
F1 F1 F1 F1
Blast 74.5 PIRSF 11.2 SignalP2 3.6
Coils 03.6 PRINTS 13.7 SignalP3 4.1
Gene3D 04.0 ProDom 03.5 SMART 7.2
Hamap 05.5 ProSite Patterns 03.0 SUPERFAMILY 14.9 PANTHER 42.4 ProSite Profiles 15.6 GRFAM 22.3
Pfam 38.2 SignalP1 1.1 TMHMM 06.8
Phobius 11.7
Table 2: Microlabel F1 obtained by SVM on individual features.
F1 0/1
Linear Gaussian Linear Gaussian
SVM MMR SOP MMR SOP MMR SOP MMR SOP
UNIF 68.3 35.1 71.7 79.9 79.9 06.9 55.1 64.1 64.3
ALIGN 74.6 33.9 76.9 83.0 82.8 05.9 58.4 68.3 68.6
ALIGNF 79.2 50.1 80.0 85.4 85.2 21.0 62.9 72.7 72.8 Table 3: Prediction performance of models.
Experimental setup. We perform experiments to evaluate the performances of different kernels, multiple kernel learning approaches, and machine learning models. We compute linear kernels over
19input feature maps and apply threeMKLapproaches to combine input kernels including: uniform kernel combination (UNIF),ALIGN, andALIGNF. In addition, a Gaussian kernel is composed over the kernels computed fromMKL. We train a collection of SVMs, one for each microlabel. On the other hand,MMRandSOPare both multilabel learners. Kernel parameter and margin slack parame-ters of the learning models are tuned using cross-validation. The measures of performance include
F1 scores computed by pooling all microlabel predictions, and multilabel accuracy computed by
requiring the whole annotation vector to be predicted correctly. The results are from 5-fold cross validation.
Results. Table 2 reports the predictive potential of different individual features in conjunction of SVM. We can notice that Blast provides the best microlabel F1 with 74.5%, with Pfam and Panther the next best features. Most of the features have poor F1 scores when used individually.
We compare the prediction performance ofSVM,MMR, andSOP in Table 3. First, we notice that multiple kernel learning withALIGNFleads to the best performance. On SVM, it is the onlyMKL
methods that beats using Blast feature as the single input feature. The most accurate models overall are obtained with ALIGNFusing the Gaussian kernel over the learned mixture and either of the multilabel learning methodsSOPorMMR. Between the two multilabel methods, we notice thatSOP
is very competitive in all setups, with both linear and Gaussian kernel and with all three methods of combining kernels. With Gaussian kernelMMRclosely matches the performance ofSOP.
In absolute terms, the best prediction accuracies of85.4%multilabel F1 score and72.8% multil-abel accuracy are remarkably good, and show that transport functions can be well predicted from sequence derived features to a fine-grained detail.
4
Conclusions
We have presented here a study on predicting transport protein functions as encoded by the Transport Classification Database (TCDB). According to our knowledge, this is the first time prediction of the whole hierarchy has been attempted. Our experiments show that combining state-of-the-art sequence-derived features, multiple kernel learning and structured output learning make detailed functional classification viable.
References
[1] Zachary Chiang, Ake Vastermark, Marco Punta, Penelope Coggill, Jain Mistry, Robert Finn, and Milton Saier. The complexity, challenges and benefits of comparing two transporter classi-fication systems in tcdb and pfam.Briefings in Bioinformatics, 2015.
[2] Milton H. Saier, Vamsee S. Reddy, Dorjee G. Tamang, and Ake Vastermark. The transporter classification database.Nucleic Acids Research, 42(D1):D251–D258, 2014.
[3] M. Michael Gromiha and Yu-Yen Ou. Bioinformatics approaches for functional annotation of membrane proteins.Briefings in Bioinformatics, 15(2):155–168, 2014.
[4] Corinna Cortes, Mehryar Mohri, and Afshin Rostamizadeh. Algorithms for learning kernels based on centered alignment.The Journal of Machine Learning Research, 13(1):795–828, 2012. [5] J. Rousu, C. Saunders, S. Szedmak, and J. Shawe-Taylor. Kernel-based learning of hierarchical multilabel classification models. The Journal of Machine Learning Research, 7:1601–1626, 2006.
[6] Katja Astikainen, Liisa Holm, Esa Pitk¨anen, Sandor Szedmak, and Juho Rousu. Towards struc-tured output prediction of enzyme function. InBMC proceedings, volume 2, page S2. BioMed Central Ltd, 2008.
[7] Ben Taskar, Carlos Guestrin, and Daphne Koller. Max-margin markov networks. In S. Thrun, L.K. Saul, and B. Sch¨olkopf, editors,Advances in Neural Information Processing Systems 16, pages 25–32. MIT Press, 2004.
[8] Hanchen Xiong, Sandor Szedmak, and Justus Piater. Scalable, accurate image annotation with joint svms and output kernels.Neurocomputing, 169:205–214, 2015.
[9] Philip Jones, David Binns, Hsin-Yu Chang, Matthew Fraser, Weizhong Li, Craig McAnulla, Hamish McWilliam, John Maslen, Alex Mitchell, Gift Nuka, et al. Interproscan 5: genome-scale protein function classification.Bioinformatics, 30(9):1236–1240, 2014.