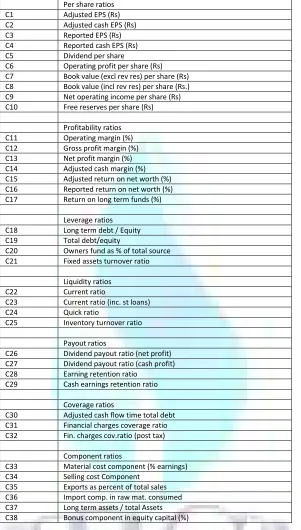
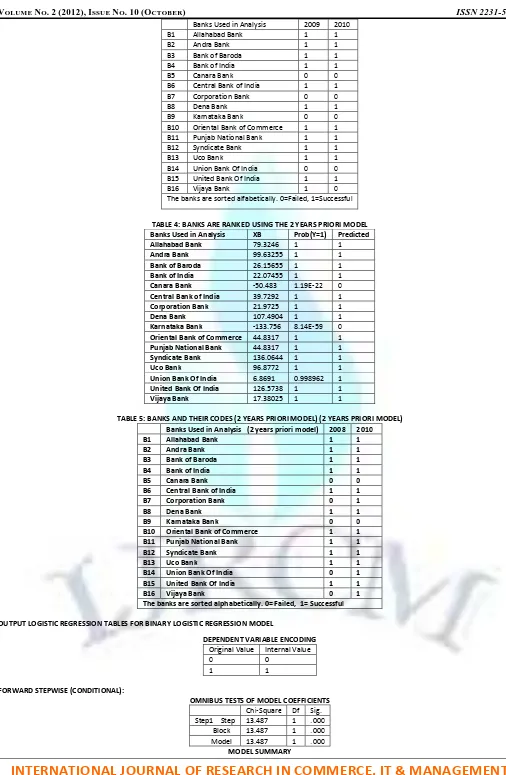
LOGISTIC REGRESSION MODEL FOR PREDICTION OF BANKRUPTCY
15
0
0
Full text
Figure
Related documents