Scalable Big Data Privacy Preservation in
Cloud
Gawali Priyanka Shivaji1, Ms. Arti Mohanpurkar2
Student, Department of CSE, Dr. DYPSOET, Lohegaon Pune, Savitribai Phule Pune University, India.1 Prof, Department of CSE, Dr. DYPSOET, Lohegaon Pune, Savitribai Phule Pune University, India.2
ABSTRACT: Distributed computing is a standout amongst the most pre-predominant worldview in late patterns for registering and putting away purposes. Information security and protection of information is one of the significant worry in the distributed computing. Information anonymization has been broadly examined and generally embraced strategy for security saving in information distributed and sharing strategies. Information anonymization is forestalling appearing of touchy information for proprietor's information record to moderate unidentified Risk. The security of individual can be satisfactorily kept up while some total data is shared to information client for information examination and information mining. The proposed technique is summed up strategy information anonymization utilizing Map Reduce on cloud. Here we Two Phase Top Down specialization. In First stage, unique information set is divided into gathering of littler dataset and they are anonymized and middle of the road result is delivered. In second stage, middle of the road come about first is further Anonymized to accomplish constant information set. What's more, the information is displayed in summed up Form utilizing Generalized Approach. Discharging individual particular information in its most particular state represents a danger to individual security. This paper shows a down to earth and Productive calculation for deciding a dynamic form of information that veils touchy Standardizing association. The Classification of information is executed by Practicing or enumerating the level of data in a top-down way until a base protection necessity is traded off. This top-down specialization is viable and productive for taking care of both conclusive and consistent properties. Our technique misuses the situation that information as a rule contains excess structures for order. While speculation might evacuate few structures, different structures rise to offer assistance.
KEYWORDS: Data Anonymization; Top-Down Specialization; MapReduce; Privacy preservation.
I. INTRODUCTION
Anonymization of information can relieve protection and security concerns and consent to legitimate prerequisites. Anonymization is not immune countermeasures that trade off current anonymization systems can uncover ensured data in discharged datasets. After gets the individual information sets it applies the Anonymization. The anonymization implies cover up or evacuates the touchy field in information sets. At that point it gets the transitional result for the little information sets. The middle of the road results are utilized for the specialization process. Information anonymization calculation that changes over clear content information into a nonhuman intelligible and irreversible structure including yet not constrained to preimage safe hashes and encryption strategies in which the unscrambling key has been disposed of.
Two-Phase Top-Down Specialization (TPTDS) way to deal with behavior the calculation required in TDS in a very versatile and effective design. The two periods of the methodology depend on the two levels of parallelization provisioned by MapReduce on cloud. Fundamentally, MapReduce on cloud has two levels of parallelization, i.e., work level and errand level. Work level parallelization implies that numerous MapReduce employments can be executed at the same time to make full utilization of cloud framework assets. Joined with cloud, MapReduce turns out to be all the more intense and versatile as cloud can offer base assets on interest.
MapReduce System is coordinates by marshaling the conveyed servers, running the different errands in parallel, dealing with all interchanges and information exchanges between the different parts of the framework, accommodating excess and adaptation to non-critical failure, and general administration of the entire procedure. The model is motivated by the guide and decreases works generally utilized as a part of practical programming, despite the fact that their motivation in the MapReduce system is not the same as their unique structures. Besides, the key commitment of the MapReduce system are not the real guide and decrease capacities, but rather the adaptability and adaptation to internal failure accomplished for an assortment of utilizations by improving the execution motor once. MapReduce libraries have been composed in numerous programming dialects, with various levels of improvement. A prominent open source usage is Apache Hadoop. The name MapReduce initially alluded to the restrictive Google innovation and has following been sum up MapReduce is a structure for handling parallelizable issues crosswise over gigantic datasets utilizing an expansive number of PCs (hubs), by and large alluded to as a group (if all hubs are on the same nearby system and use comparable equipment) or a lattice (if the hubs are shared crosswise over topographically and authoritatively disseminated frameworks, and utilize more heterogeneous equipment).
II. NEED OF PROPOSED SYSTEM
The nearby recoding anonymization for enormous information in cloud has been explored from the points of view of ability of safeguarding closeness protection breaks, adaptability and time-productivity. We have proposed a vicinity security model. A progression of creative MapReduce occupations have been produced and composed to direct information parallel calculation. Broad investigations on true information sets have shown that our methodology essentially enhances the ability of protecting vicinity assaults, the versatility and the time-effectiveness of nearby recoding anonymization over existing methodologies.Today is the period of Google. The thing which is obscure for us, we Google it. What's more, in portions of seconds we get the quantity of connections thus. This would be the better case for the preparing of Big Data. This Big Data is not any distinctive thing than out customary term information. Simply huge is a catchphrase utilized with the information to distinguish the gathered datasets because of their huge size and unpredictability? We can't oversee them with our present approaches or information mining programming devices. Among every one of these tweets, the exceptional remarks that created the most discourses really uncovered the general population intrigues. Such online talks give another intends to sense the general population intrigues and produce criticism continuously, and are for the most part engaging contrasted with nonspecific media, for example, radio or TV. This sample exhibits the ascent of Big Data applications. The information accumulation has become enormously and is past the capacity of normally utilized programming instruments to catch, oversee, and prepare inside of a middle of the road time. we examine the issues of existing methodologies for neighborhood recoding anonymization from the viewpoints of vicinity security and adaptability regarding the investigations above, accomplishing the nearby recoding plan under closeness mindful protection models is still a testing issue. To our best information, no past work concentrates on this issue. Persuaded by this test, we propose a vicinity mindful grouping approach for neighborhood recoding anonymization.
III. RELATED WORK
correspondences. The arrangement, exhibits an even level of administration, accessible to every single ensnared entitie, that understands a security network, inside of which key trust is kept up. Here it utilizes the endorsement base approval to give the security in cloud environment. The general execution of the security issues are low contrast and existing methodologies.
In the work [2] Author said another strategy, called "work load mindful anonymization procedures and grouping and relapse" Protecting individual security is an essential issue in smaller scale information dissemination and distributed. Anonymization calculations normally mean to fulfill certain protection definitions with negligible effect on the nature of the subsequent information. While a significant part of the past writing has measured quality through straightforward one-size-fits-all measures and contend that quality is best judged concerning the workload for which the information will at last be utilized. This article gives a suite of anonymization calculations that join an objective class of workloads, comprising of one or more information mining errands and in addition determination predicates. A broad observational assessment demonstrates this methodology is frequently more compelling than past procedures. Moreover consider the issue of versatility. The article depicts two expansions that permit scaling the anonymization calculations to datasets much bigger than fundamental memory. The primary expansion depends on thoughts from versatile choice trees, and the second depends on examining. A careful execution assessment demonstrates that these systems are suitable by and by. Here it utilizes the declaration base approval to give the security in cloud environment. The general execution of the security issues are low contrast and existing methodologies. Here are utilizing the work load mindful anonymization systems and characterization and relapse. It additionally neglects to handles the extensive measure of the information sets.
In the work [3] Author said another method, called "disseminate anonymization and brought together anonymization" Sharing human services information has turned into an essential necessity in social insurance framework administration; in any case, improper sharing and use of medicinal services information could debilitate patients' protection. In this article, it thinks about the security worries of sharing patient data between the Hong Kong Red Cross Blood Transfusion Service (BTS) and people in general doctor's facilities. It sum up their data and security necessities to the issues of brought together anonymization and appropriated anonymization, and recognize the significant difficulties that make customary information anonymization strategies not relevant. Moreover propose another protection model called LKC-security to beat the difficulties and present two anonymization calculations to accomplish LKC-protection in both the concentrated and the appropriated situations. Probes genuine information show that the anonymization calculations can adequately hold the fundamental data in unknown information for information investigation and is adaptable for anonymizing expansive datasets. Treatment of the extensive scale information sets is exceptionally troublesome. Here it utilizing the disperse anonymization and brought together anonymization to gives the protection on cloud. Treatment of the substantial scale information sets is extremely troublesome.
IV. IMPLEMENTATION STRATEGIES
Calculations address the versatility issue, we propose a two-stage bunching approach comprising of the t-progenitors grouping (like k-means [22]) and closeness mindful agglomerative bunching calculations. The main stage parts unique information set into t segments that contain comparable information records as far as semi identifiers. In the second stage, information segments are privately recoded by the nearness mindful agglomerative bunching calculation in parallel. We plan the calculations with MapReduce to increase high versatility by performing information parallel calculation over numerous figuring hubs in cloud. We assess our methodology by leading broad examinations on true information sets. Test results exhibit that our methodology can safeguard the nearness security generously, and can fundamentally enhance the versatility and the time-effectiveness of nearby recoding anonymization over existing methodologies.
V. MATHEMATICAL MODELING
Set Theory Analysis
1. Let ‘S’ be the unlabeled data pattern.
2. Identify the input as S= {mI,τ, k}
Where mI =unlabeled data patterns τ = threshold value
k = subspace cluster size
3. Identify the output as X S = {mI, τ}
X = {X | ‘X’ is output dataset containing number of cluster J.}
4. Identify the processes as P. S= {mI, τ}
P= {S(k), H(k), SP(L), E(L)}
Where S(k) = Subspace clustering process H(k)= Hierarchical clustering process SP(L)= Split process
E(L)= Ensemble clustering process
5. Identify failure cases as F’ S= {mI, τ, X, P, F’}
Failure occurs when –
System failure
6. Identify success case (terminating case) as e S= {mI, τ, X, P, F’, e}
Success is defined as-
Generated cluster = C
VI. EXISTING SYSTEM
The size of information in numerous cloud applications increments colossally as per the Big Data pattern, consequently making it a test for regularly utilized programming instruments to catch, oversee and process such huge scale information inside of a decent passed time. Subsequently is test for existing anonymization ways to deal with accomplish protection conservation on security touchy huge scale information sets because of their deficiency of adaptability. A present the adaptable two-stage top-down specialization way to deal with Anonymized extensive scale information sets utilizing the MapReduce structure on cloud.
VII. PROPOSED SYSTEM
A present the adaptable two-stage top-down specialization way to deal with Anonymized vast scale information sets utilizing the MapReduce system on cloud. In both periods of methodology is purposely plan a gathering of imaginative MapReduce employments to solidly finish the specialization calculation in an exceptionally versatile manner. Test assessment results exhibit that with this methodology. The versatility and proficiency of top-down specialization can be enhanced fundamentally over existing methodologies.
Approaches for taking care of the issue and effectiveness issues-
of the MapReduce structure are not the genuine guide and lessen capacities, but rather the extensibility and adaptation to internal failure picked up for an assortment of utilizations by streamlining the execution motor once. A solitary strung execution of MapReduce will normally not be quicker than a customary usage. At the point when the improved circulated mix operation (which decreases system correspondence cost) and adaptation to internal failure elements of the MapReduce structure become an integral factor, is the utilization of this model advantageous. MapReduce libraries have been composed in different programming dialects, with isolated levels of streamlining.
VIII. EXPECTED RESULTS
To get to extensive information set in cloud applications. The blends of two-stage TDS, information anonymization and encryption are utilized as a part of effective approach to handle adaptability. We break down the versatility issue of existing framework approaches when taking care of huge scale information sets on cloud. The brought together methodologies misuses the information structure TIPS so the primary objective is enhance the versatility and effectiveness by indexing mysterious information records and holding factual data.
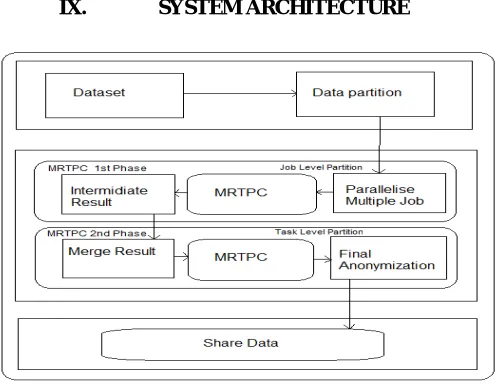
IX. SYSTEM ARCHITECTURE
Fig. System Architecture
Explanation-
MapReduce execution can be enhanced by upgrading the use of spaces from two essential points of view. To start with, the spaces can be named unmoving openings (no running assignments) and occupied openings (with running tasks).The execution and opening utilizat particle of a Hadoop bunch can be upgraded with the accompanying regulated procedures.
1. In the event that an opening is unmoving, then DynamicMR will first endeavor to enhance the space usage with DHSA system. It will assess in view of various limitations such as reasonableness, burden adjust and choose whether to dispense the unmoving opening to the undertaking or not.
2. On the off chance that the allotment is genuine, DynamicMR will assist streamline the execution by enhancing the productivity of opening use with SEPB. It takes a shot at top of Hadoop theoretical scheduler to check whether to apportion the accessible unmoving openings to the pending undertakings or to the theoretical errands.
XI. CONCLUSION
Right now, security in big information is a testing research issue. On the off chance that Integration of MapReduce, a machine for protection saving, is intended for the breaking down of information would give better security. In the current framework adaptability and time-effectiveness have been finished with nearby recording anonymization and did not address worldwide recording anonymization. This audit work gives thought Local recording anonymization in cloud situations for safeguarding information security over BigData utilizing MapReduce. Utilizing the two stage top down way to deal with give capacity to handles the high measure of the huge information sets. What's more, here it gives the protection by successful anonymization approaches.
REFERENCES
[1]. S. Chaudhuri, “What Next?: A Half-Dozen Data Management Research Goals for Big Data and the Cloud,” in Proc. 31stSymp.Principles of
Database Systems (PODS'12), pp. 1-4, 2012.
[3]. L. Wang, J. Zhan, W. Shi and Y. Liang, “In Cloud, Can Scientific Communities Benefit from the Economies of Scale?,” IEEE Trans. Parallel Distrib. Syst., vol. 23, no. 2, pp.296-303, 2012.
[4]. H. Takabi, J.B.D. Joshi and G. Ahn, “Security and Privacy Callenges in Cloud Computing Environments,” IEEE Securityand Privacy, vol. 8, no. 6, pp. 24-31, 2010.
[5] B. C. M. Fung, K. Wang, R. Chen, and P. S. Yu, “Privacy-preserving data publishing: A survey of recent developments,” ACM Comput. Survey, vol. 42, no. 4, pp. 1–53, 2010.
[6] J. Xu, W. Wang, J. Pei, X. Wang, B. Shi, and A. W. C. Fu, “Utilitybased anonymization using local recoding,” in Proc. 12th ACM SIGKDD Int. Conf. Knowl. Discovery Data, 2006, pp. 785–790.
[7] J. Li, R. C.-W. Wong, A. W.-C. Fu, and J. Pei, “Anonymization by local recoding in data with attribute hierarchical taxonomies,” IEEE Trans. Knowl. Data Eng., vol. 20, no. 9, pp. 1181–1194, Sep. 2008.
[8] J.-W. Byun, A. Kamra, E. Bertino, and N. Li, “Efficient K-anonymization using clustering techniques,” in Proc. 12th Int. Conf. Database Syst. Adv. Appl., 2007, pp. 188–200.
[9] R. C.-W. Wong, J. Li, A. W.-C. Fu, and K. Wang, “(a, k)-anonymity: An enhanced k-anonymity model for privacy preserving data publishing,” in Proc. 12th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2006, pp. 754–759.