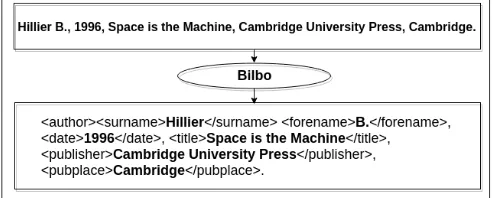
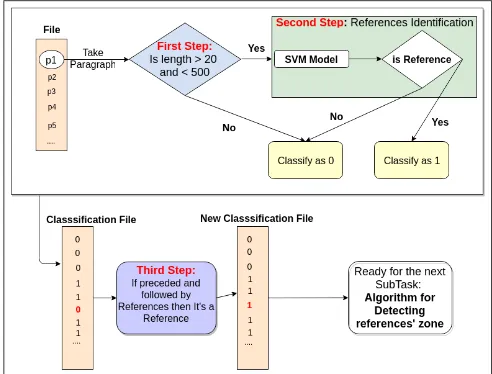
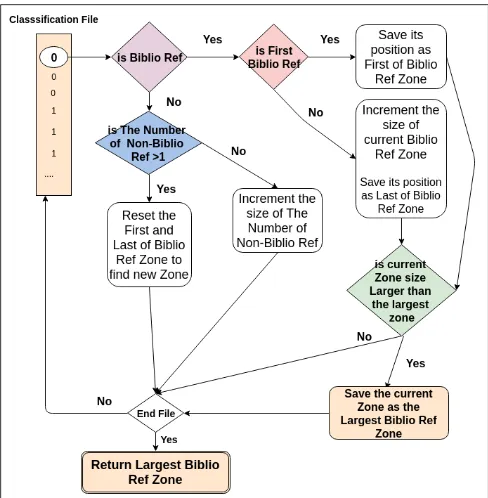
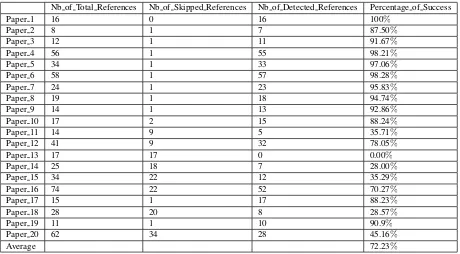
Bilbo Val: Automatic Identification of Bibliographical Zone in Papers
Full text
Figure
Related documents
There is evidence that the market factor in the CAPM can explain the time-series variation in returns on both the industry portfolios and the 25 size/BM portfolios, and the size
Abstract This paper describes the implementation of a factorial survey within the SOEP-Pretest of 2008 and investigates (1) respondents’ comments about the vi- gnettes,
This scheme assigns repair resources to failed nodes with the highest number of physical links prior to failure, i.e., node degree in Gs = ( Vs , Es ) , see Figure 5.. Similarly,
The inclusion criteria of the study were diagnosed type 2 diabetic patients of ≥01 year duration, already on metformin therapy, of 35-60 years of age, both gender
The paper goes on to describe the Intercloud security considerations and proposes a new Intercloud Trust Model, Identity and Access Management, Encryption and
The Urban Poverty Reduction Project, the first major project providing housing, credit, services and infrastructure to the poor through the NGOs, could not be started since 1996
disability, it’s better to wait until the individual describes his/her situation to you, rather than to make your own assumptions. Many types of disabilities have similar
The physical process of star formation in distant galaxies and through much of cosmic history must be reasonably the same as it is presently in the nearest molecular
