Optimal Client-Server Assignment for
Internet Distributed Systems
Mosiur Rahaman, Abdul Aziz
Assistant Professor, Computer Science & Engineering, Royal Institute of Technology and Science, JNTU,
Hyderabad, India
Student, Dept. of C.S.E, Royal Institute of Technology and Science, JNTU, Hyderabad, India
ABSTRACT: Internet is a network of several distributed systems that consists of clients and servers communicating
with each other directly or indirectly. In order to improve the performance of such a system, client-server assignment plays an important role. Achieving optimal client-server assignment in internet distributed systems is a great challenge. It is dependent on various factors and can be achieved by various means. Our approach is mainly dependent on two important factors, 1) Total communication load and 2) Load balancing of the servers. In our approach we propose an algorithm that is based on Semi definite programming, to obtain an approximately optimal solution for the client-server assignment problem. We will show the efficiency of our approach by the simulation experiments compared with the existing client-server assignment.
KEYWORDS: Distributed Systems, Client-Server Systems, Graph Clustering, Load Balancing, Communication
Overhead, Optimization.
I. INTRODUCTION
In this paper, An Internet distributed system consists of a number of nodes (e.g., computers) that are linked together in ways that allow them to share resources and computation. An ideal distributed system is completely decentralized, and that every node is given equal responsibility and no node is more computational or resource powerful than any other. However, for many real-world applications, such a system often has a low performance due to a significant cost of coordinating the nodes in a completely distributed manner. In practice, a typical distributed system consists of a mix of servers and clients. The servers are more computational and resource powerful than the clients. We propose a heuristic via relaxed convex optimization for finding the approximate solution. Our simulation results indicate that the proposed algorithm produces superior performance than other heuristics, including the popular Normalized Cuts algorithm.
II. EMERGING APPLICATIONS
III. MODEL FOR COMMUNICATION
We model the load incurred on a server for sending and receiving messages. We call the load incurred by communication the communication load. This model will be important for the precise formulation of the client-server assignment problem.
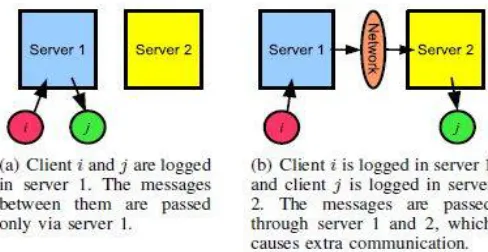
We begin with an example shown in Fig. . The IMS of Interest operates according to the following rules:
a) If client i and j are logged in the same server and exchange messages each other, then their messages are processed only through the server (Fig.1. (a)).
b) If client i and j are logged in different servers (i is in server 1, j is in server 2) and suppose i sends a message to j, then server 1 forwards the message to server 2 and server 2 sends it to j (Fig. (b)). This causes an extra communication overhead compared to case a), because it generates an additional message passing between servers 1 and 2.
We assume that all messages are encrypted and the server load by communication is proportional to the amount of messages sent from and received by the server. Specifically,
Fig.1. Example of client assignment to servers
TABLE MESSAGE PROCESSING SUMMARY IN FIG.1.
• If both clients i and j are logged in server 1, server 1 receives the messages from i and sends them to j. • If client i is logged in server 1 and j is in server 2, server 1 receives the messages from i and sends them to server 2, then server 2 receives them and sends to j.
IV. CLIENT-SERVER ASSIGNMENT
A. CLUSTERING ALGORITHMS
To a certain extent, the client server assignment problem can be viewed as an instance of the clustering problem. Specifically, the clients and their communication patterns can be represented as a graph whose vertices denote the clients, an edge between two vertices denote a communication between two corresponding clients. The weight of an edge between two vertices represents how frequent the two clients communicate with each other.
Fig.2. Example of Normalized Cuts
The goal of many clustering algorithms is to cluster the clients into a fixed number of groups so that a certain objective, e.g., the ratio of inter-communication among groups to intra-communication within a group, is minimized. Therefore, we briefly discuss a few approaches to the clustering problem. The most related clustering algorithm to our
problem is the (NC) that partitions an undirected graph into two disjoint partitions so that
= ,
, , +
,
, ,,
is minimized, where , is the sum of the weights of all edges that connect the vertices in group i and j (see Fig.2).The
less the amount of inter-group communication and the more balanced the volumes of the groups (volume = the sum of
the weights of all edges in the group), the less we have. In this sense, is very similar to our objective. NC
utilizes the Eigen values of the adjacency matrix and solves efficiently. The NC is especially suitable for segmenting an image, and is also widely used in bioinformatics and machine learning communities.
In order to solve efficiently, NC uses Eigen values of adjacency matrix. But NC tends to cause imbalance in the
volumes of the groups by isolating the vertices that do not have strong connection to others. Balanced clustering algorithms for power law graphs are examined. Author concludes that combining multiple trials of a randomized flow-based rounding methods and solving a semi definite program yields effective results. In it is shown that the optimal client server assignment for pre-specified requirements on total communication load and load balancing is NP-hard. A heuristic algorithm based on relaxed convex optimization is used for finding the approximate solution to the client server assignment problem.
B. DISTRIBUTED INTERACTIVE APPLICATIONS (DIAS)
DIAs is networked systems that allow multiple participants at different locations to interact with each other. Wide spread of client locations in large-scale DIAs often requires geographical distribution of servers to meet the latency requirements of the applications. In the distributed server architecture, client assignment to servers directly affects the network latency involved in the interactions between clients. Focuses on client assignment problem for enhancing the interactivity performance of DIAs. In this paper, the problem is formulated as a combinational optimization problem on graphs and proved to be NP-complete of assigning clients to appropriate servers. Three heuristic algorithms are proposed, namely, nearest assignment, Greedy assignment, Distributed greedy assignment and are compared and evaluated using real Internet latency data is an improved version of and the results show that the proposed algorithms, nearest Assignment algorithm, Modify Assignment and Distributed modify assignment, are efficient and effective in reducing the interaction time between clients. However, both and consider the client assignment in DIAs and do not consider the load on the server and other factors.
C. LOAD-DISTANCE BALANCING PROBLEM (LDB)
load on the server in client-server assignment. The problem is defined as Load-distance balancing (LDB) problem. This paper targets 2 flavors of LDB. In the first flavor, the objective is to minimize the maximum incurred delay using an approximation algorithm and an optimal algorithm. In the second flavor, the objective is to minimize the average incurred delay, which the paper mentions it as NP-hard and provides a 2-approximation algorithm and exact algorithm. However to the best of our knowledge there is no clustering algorithm that is designed as a Semi-definite programming problem to achieve our goal: Load balancing on servers and minimizing the communication load between servers, for client-server assignment.
Algorithm for load balancing:
a. Maintain a matrix ∗ which stores the rate of data exchanged between clients. Rows and columns represent the
clients in system.
b. Maintain a matrix ∗ denoting which client is using which servers for communication.1 denotes client using the
server and 0 denotes not using the server.
c. Maintain matrix ∗ storing total load on server due to client.
d. Calculate total load on all the servers’ i.e.
e. Calculate approximate average load that should be given to each server i.e. ⁄ .
f. Calculate the load balance factor for each server i.e.
∫ ( + )≤ ,
g. Split the number of servers in two groups with m = [M/2] and M-m = [M/2] servers in each group.
h. First perform intra-server load balance by comparing load balance factor ‘ ’ of each server then perform
inter-server load balance by comparing load balance factor of inter-server from one group and inter-servers from other group. A threshold needs to be setup in order to avoid congestion of requests from the clients. This can be achieved with the help DOS (Denial of Service) attack.
V. APPROXIMATE METHODS VIA RELAXED CONVEX OPTIMIZATION
Since our problem is NP-hard, in this section we present an approximation method via relaxed convex optimization.
The main idea of our approach is to solve the special case with the number of servers = 2via relaxed convex
optimization. Specifically, we will approximate both the objective and the solution domain with convex functions and a
convex set, respectively. Next, we show how to apply this result to the general case for > 2. The main idea is to
split the servers into two groups sequentially. For each group of servers, we then recursively solve the problem
for = 2. Empirical results show that this method approximates the optimal solution very well.
A. TWO-SERVER SOLUTION
In this paper we focus on total communication load and load balancing in client server assignment. Our goal is to achieve client assignment minimizing the overall load and load balance of servers. In this section we consider client
assignment in a system with 2 servers, Server A ( ) and Server B( ). Load issue is solved using semidefinite
programming. This solution is extended to case of multiple servers.
Xi variable is used to denote the server to which client is assigned to. Formula 1 defines ,
= 1
−1 ℎ (1)
Let , denote the date rate of communication from client to client . Communication load will be , between clients
and if they are assigned to the same server. Communication load will be doubled if clients and are assigned to two
different servers. Formula for total communication load is as given below.
=∑ ∑ , +∑ ∑ ∗ , (2)
Note that , = 0.
Load balance of the servers is the load difference between the two servers and . is use to denote the load
balance of servers. If two communicating clients are assigned to two different servers, they increase the communication
load on both servers equally resulting in no impact on load balance. In figure 1, clients and are assigned to two
different servers. When has to communicate with , sends message to which is forwarded to . Receives
and does not change. From this observation it is clear that to calculate the load balance of a server we need to
calculate only cost of communications between those clients which are assigned to that server. We denote load on
as and load on as . and includes load of communications between clients assigned to only and
respectively.We can express load on each server and based on formula 1 as follows:
=∑, ∗ , +∑, ∗ , (3)
=∑, ∗ , +∑, ∗ , (4)
Hence the load difference between Server A and Server B can be expressed as
= | − |.
D can also be expressed as,
= ∑, ∗ , (5)
D, load balance cannot be added directly to our objective function as this makes our objective function non-quadratic.
Non-quadratic functions are hard to solve hence we modify our load balance. New load balance is denoted by| −
| or = ( − ) .Minimizing results in a minimized value of D, load balance. To explain our
objective function better, we express D in other two equivalent formulas:
= |∑ ∗ | (6)
=∑ ∗ , + , (7)
We obtain,
=∑ +∑ ∗( ) (8)
Since
∗ = 1.
Our goal is to minimize both total load and the load balance among the servers. Objective function is expressed as,
:∝ + (1−∝)
: = 1, ∈ . 1≤ ≤ (9)
Our objective function of (9) is a strict quadratic formula along with the constraints, as it is clear from formulas (2) and
(8) that and consists of monomials of either degree 0 (constants) or degree 2.We define two new
parameters, , and C, which are obtained by denoting and by (2) and (8) in the objective function of (9).
, =− ∝ , + (1−∝) (10)
= ∝ ∑ , + (1−∝)∑ (11)
Objective function of (9) can be expressed as:
:∑ , + (12)
We translate our original problem to a Vector problem. To solve (12) based on constraints of (9), we relax the n integer
variables to n vector variables in and substitute each term with degree 2 to the inner product of two vector variables.
According to [8] a vector program is a program with all the variables as vectors within , say 1 … , and objective
functions and all constraints are linear functions of inner products . , 1 ≤ ≤ . Thus we have our original
problem transferred into the following vector program:
:∑ , . +
: . = 1, ∈
∈ , ∈ (13)
For any feasible solution of (9) if we assign a vector form feasible solution for (13) is obtained. Vector
programming is equivalent to Semi definite programming [?]. For a matrix ∈ let , denote the( , ) the entry in
matrix. Trace of A, denoted by ( ) is defined as the sum of its diagonal entries.
Given two matrices , ∈ trace of is given by, ( ) =∑ ∑ , , Let U be a symmetric and positive
semidefinite matrix and W be a matrix with all diagonal entries as 0 and other entries as , defined in (10). We obtain
the equivalent semidefinite programming as follows:
: ( )
: , = 1, 1≤ ≤ ,
By solving (14) we obtain a solution matrix . Then by using Cholesky Factorization we compute a matrix =
( 1, 2, … . ) that satisfies = in ( )time. V is set of all vectors in solution of relaxed vector
programming in (13). To obtain the final solution of our original problem, we have to round the n
vectors( 1 2… ) ( 1 2 … ). This rounding method is similar to the procedure of solving MAX-CUT problem:
randomly chose a uniformly distributed vector r in n-dimensional unit sphere, then for . ≥ 0, then , the rounded
result of , is set to 1, else is set to -1.
B. GENERAL SOLUTION
Thus far, we have described the basic idea of our relaxed convex optimization approach for the two-server scenario.
We can achieve the nearly optimal client-server assignment for servers by splitting servers into two groups and
recursively splitting within each group as shown in Fig. . How to split M servers is the central question. If is even, then it makes sense to split servers into two equal groups with servers in each group. In the ideal case, optimizing the load balance between these two groups will result in individual servers in these two groups having identical server loads. On the other hand, when making the number of servers in these groups is not same, optimizing the objectives will result in two groups having total identical server loads. However, since the two groups have different number of servers, a server within a group with fewer servers will likely to have a higher load than a server in the group with more
servers. This reduces the load balance. Therefore, when is not even, it is necessary to modify the objective at each
step, depending on how splitting is done, so as to maintain the similar load at individual servers. Intuitively, the
modified objective should reflect the number of servers in each group. When splitting servers into two groups
consisting of and − servers in each group, the load balance metrics in () and () should be replaced by:
=
( ) {
( )
− }2,
= ′ + ′ ′ ,
′ = ( )− / ( )…
′ = / ( )…..
Due to lack of space, the justification for this claim is omitted. The full justification can be found in []. We would like to mention that the modified load balance metrics allocate a higher load to groups with more servers, and is intuitively plausible. Importantly, both metrics in Claim 4.1 are convex functions; therefore we can employ the Algorithm 1 embedded in the Algorithm 2 below for finding an approximate solution.
Algorithm 2
1) Split the number of servers into two groups with m = and − = servers in each group.
2) Run Algorithm 1 with modified load balance metrics stated in Claim 4.1.
3) Repeat steps 1 and 2 for each of the two groups, until the number of servers in each group equal to 1.
C. TIME COMPLEXITY
Our algorithms run the convex optimization and quantization for N clients and repeat it for depth degrees.
Suppose the convex optimization routine takes ( ), then the overall time complexity is ( +
( ) ). ( )Depends on the optimization algorithm but takes at least ( ). As a result, the time complexity of
our algorithms is at least ( ), which is considerably expensive.Though standard calculation of eigenvectors
takes O ( ) in the Normalized Cuts, it reduces the time complexity to ( ) by 1) utilizing sparse graphs.
2) Calculating only the top of few eigenvectors.
3) Lowering the precision. Our algorithms have much room for improvement, and speeding up remains as our future work.
VI. SIMULATION RESULTS
In this section, the algorithm names are abbreviated as follows:
BCO-D: The binary splitting via relaxed convex optimization based on (28) BCO-E: The binary splitting via relaxed convex optimization based on (29) NC: The Normalized Cuts
Random: We assign the clients to each server at random. We used = 0.5 for (28) (29).
A. EXAMPLES OF GRAPH CLUSTERING
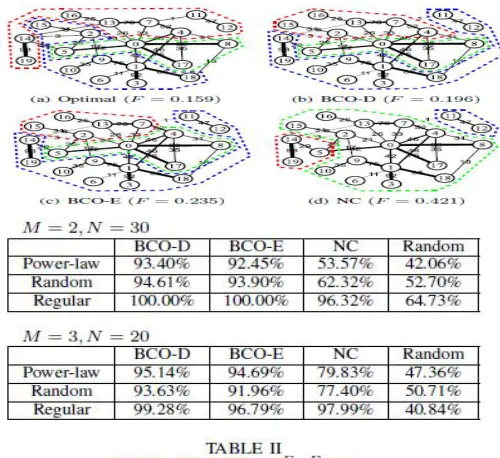
Fig. 5-6 shows our simulation results with small graphs. For the comparison, we added the results by the NC. We used a MATALB code [12] written by an author of [3] et al. for the NC algorithm. F is the metric in (17), and the smaller, the better client-server assignment we have. As shown in the figures, the NC tends to isolate small volumes of groups that do not have strong connection to others, while with our BCO methods, the volumes of the groups are well balanced, which appears as smaller F values.
B. OPTIMALITY
To verify how close the outputs by our algorithms are to the optimal solutions, we made the following examination:1)
For a each graph, we calculate Fs (17) exhaustively for all combinations of . Herein, we suppose the
Best (smallest) = and the worst (greatest) = .
2) For each graph, calculate F by each of the BCO-D, BCO-E, NC and a randomly generated , then calculate F’s
optimality . We also obtain each ’s ranking ( )out of outputs, and calculate its optimality1− .
The greater those values are the better optimality. 3) Do 1)-2) for:
• A hundred different graphs generated by Barabasi- Albert power-law graph generator algorithm.
• A hundred different graphs generated by our random graph generator. In our random graph generator, each vertex is allocated at most ten randomly selected neighbors.
• Regular graphs in which every node has the equal number of neighbors ( ) with an equal edge weight.
Note is even and vertex i is connected to + 1, . . . , + , − 1, . . . , − . We simulated for = 2, 4, . . . , −
2, that is, −1 different regular graphs for a given { , }.
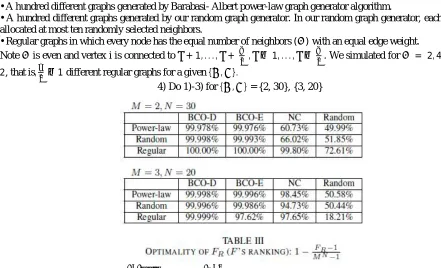
4) Do 1)-3) for { , } = {2, 30}, {3, 20}
Table II and III show average and 1−
Values respectively. Overall, the BCO-D method shows the best optimality in spite of the simple and cheap quantization technique (see Section IV-A). In fact, unlike the NC, the BCOs constantly output good values (close or
equal to ) regardless of the graph type. The simulation shows that the BCO-D is most suitable for solving our
problem.
On the other hand, the NC tends to isolate vertices that do not have strong connection to others. This is typically
observed in power-law graphs. As a result, though we have low (13) (the amount of inter-server communication),
(15) (the load balance metric) becomes high and we have worse than those of our algorithms.
C. EXPERIMENTS FOR LARGER POWER-LAW GRAPHS
As described in Section I-A, our algorithms should perform better than NC for power-law graphs. We simulated for a
hundred power-law graphs, in which each vertex is connected to up to a hundred neighbors, with = 4, 7, 10, N =
1000. In this setting, we cannot find the rankings for each algorithm as it requires an exhaustive search over all possible assignments which is infeasible for large . Instead, Table IV shows the
Average (17), (13), (15) values and where , are the maximum and minimum elements in (8)
i.e., the maximum and minimum communication load in servers respectively. As shown by Fl and
values, the BCO-D and BCO-E fairly balance the load, and at the same time maintain low total
communication load as seen in . Though the NC yields low , it does not balance the load, which appears as high
(bad and consequently. Also, the BCOs reduce the overall communication load (= 1 + )by 33-36%
VII. APPLICATIONS
Multi-Server Based Applications
Application servers are system software upon which web applications run. Application Servers consist of web server connectors, computer programming languages, runtime libraries, database connectors, and the administration code needed to deploy, configure, manage, and connect these components on a web host. An Multi Server application runs behind a web Server (e.g. Apache or Microsoft IIS) and (almost always) in front of an SQL database (e.g. Postgre SQL, MYSQL or Oracle). Web applications are computer code which run on top of application servers and are written in the language(s) the application server supports and call the runtime libraries and components the application server offers. There are many application servers and the choice impacts the cost, performance, reliability, scalability, and maintainability of a web application. Proprietary application servers provide system services in a well-defined but proprietary manner.
VIII. CONCLUSION
In this paper, we present a mathematical model and an algorithmic solution to the client-server assignment problem for optimizing the performance of a class of distributed systems over the Internet. We show that in general, finding the optimal client-server assignment for some prespecified requirements on total load and load balancing is NP-hard, and propose a heuristic via relaxed convex optimization for finding the approximate solution to the client server assignment problem.
REFERENCES
[1] [Online]. Available: http://xmpp.org/about/
[2] J. Dean and S. Ghemawat, “Map Reduce: simplified data processing on Large clusters,”Commun. ACM, vol. 51, pp. 107113,January2008.[Online].Available:http://doi.acm.org/10.1145/1327452.1327492
[3] J. Shi and J. Malik, “Normalized cuts and image segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 22, no. 8, pp. 888–905, 2000.
[4] Z. Wu and R. Leahy, “An optimal graph theoretic approach to data Clustering: theory and its application to image segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 15, No. 11, pp. 1101–1113, August 2002.
[5] K. Lang, “Fixing two weaknesses of the Spectral Method,” in Advances In Neural Information Processing Systems 18, 2006. [6] ——, “Finding good nearly balanced cuts in power law graphs,” Yahoo Research Labs, Tech. Rep., 2004.
[7] M. Kurucz, A. Benczur, K. Csalogany, and L. Lukacs, “Spectral clustering in telephone call graphs,” in Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 workshop on Web mining and social network analysis, ser. WebKDD/SNA-KDD ’07. New York, NY, USA: ACM, 2007, pp. 82– 91.
[8] J. C. S. Lui and M. F. Chan, “An efficient partitioning algorithm for distributed virtual environment systems,” IEEE Trans. Parallel Distrib. Syst., vol. 13, pp. 193–211, March 2002.
[9] P. Morillo, J. M. Orduna, M. Fernandez, and J. Duato, “Improving the performance of distributed virtual environment systems,” IEEE Transactions on Parallel and Distributed Systems, vol. 16, pp. 637–649, 2005.
[10] Y. Deng and R. W. H. Lau, “Heat diffusion based dynamic load balancing for distributed virtual environments,” in Proceedings of the 17th ACM Symposium on Virtual Reality Software and Technology, ser. VRST ’10. New York, NY, USA: ACM, 2010, pp. 203–210.
[11] H. Nishida, “Optimal client-server assignment for internet distributed system,” Oregon State University, Tech. Rep., 2011. [12]“Ncut.”[Online].Available:http://www.seas.upenn.edu/timothee/software/ncut/ncut.html
[13] S. Boyd and L. Vandenberg he, Convex Optimization. Cambridge University Press, March 2004.
[14] “A tutorial on integer programming,” The Operations Research Faculty of GSIA, 1997. [Online]. Available: http://mat.gsia.cmu.edu/orclass/integer/integer.html
[15] A. Y. Ng, M. I. Jordan, and Y. Weiss, “On spectral clustering: Analysis and an algorithm,” in ADVANCES IN NEURAL INFORMATION [16] J. Shi and J. Malik, “Normalized cuts and image segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 22,no. 8, pp. 888–905, 2000.