A Novel Survey Paper on Big Data Applications
Swathi reddy modugu & Dr. G. Vishnu Murthy
Post Graduate Student, Dept. of CSE Anurag Group Of Institutions Hyderabad, Telangana, India
[email protected]
professor &
HOD Dept. of CSE Anurag Group Of Institutions
[email protected]
ABSTRACTIn recent years, the net application and communication have seen lots of development and name within the field of data Technology. These web applications and communication square measure regularly generating the big size, totally different selection and with some real troublesome varied structure knowledge known as huge knowledge. As a consequence, we tend to square measure currently within the era of large automatic knowledge assortment, consistently getting several measurements, not knowing that one are relevant to the development of interest. as an example, E-commerce transactions embody activities like on-line shopping for, commerce or investment. therefore they generate the info that square measure high in dimensional and sophisticated in structure. the normal knowledge storage techniques aren't equal to store and analyses those immense volume of knowledge. several analysisers do their research in spatiality reduction of the massive knowledge for effective and higher analytics report and knowledge image. Hence, the aim of the survey paper is to supply the summary of the massive knowledge analytics, issues, challenges and numerous technologies connected with huge knowledge.
Keywords: huge knowledge, huge knowledge Analytics
I. INTRODUCTION
Today, system and folks uses the net with an exponential generation of huge size of knowledge. the scale of knowledge on the net is measured in Exabyte (EB) and Petabytes (PB). By 2025, the prediction is that the net can surpass the brain size of everybody living within the whole
world. This firm growth of knowledge is owing to advances in digital sensors, computations, communications, and storage that have created massive gatherings of knowledge. The name huge knowledge had been devised, by Roger Magoulas a investigator, to explain this singularity. Gartner Company explicit that, info or knowledge are the twenty first century oil. In last twenty five years, knowledge has mature massively in numerous fields with differing types. consistent with the applied mathematics report of International knowledge Corporation (IDC),
In the year 2011, the general knowledge volume created within the world was one.8ZB that was increased by nearly ninefold within next 5 years [1]. currently with the inclusion of promoting, smart city, the results of unwellness management and bar and business intelligence applications it may be effortlessly perceive that huge knowledge plays an important role all over within the universe [2]. With the rise in universal knowledge volume, the technology {of big|of large|of huge} knowledge and its analytical processes square measure usually wont to give the outline regarding massive datasets. Compared with alternative ancient datasets and its
processes, huge knowledge includes semi
difficult problems strict speedy resolutions. huge knowledge image method is another very important method that takes a crucial place in huge knowledge analytics issues. as a result of through knowledge image solely the ultimate report of knowledge analytics are envisioned.
Since the sphere of data Technology (IT) is up lots recently, this generates the info additional simply. as an example, for each minute roughly seventy two hours of video files square measure uploaded to YouTube by the individuals. This knowledge growth challenges the sphere with the most issues of gathering and desegregation immense volume {of knowledge|of knowledge|of information} from cosmopolitan data sources like social media applications.
Also the sudden growth of the cloud computing and web of Things (IoT) promote the
expansion of knowledge. Cloud computing
provides the quality for storing and accessing the enterprises knowledge for the massive knowledge assets. In IoT, sensors square measure wont to gather and transmit the knowledge to be hold on and processed within the cloud storage. Such knowledge sorts and size square measure exceeds the skills of the IT architectures and set-up of existing enterprises and its period demand and its computing capability. This increase in knowledge volume cause several problems in storing and retrieving the large heterogeneous datasets with the special hardware and code infrastructure.
As a result, this survey targets at providing a short review on the massive knowledge analytics. This literature survey any organized as given below: Chapter II explains the key ideas of massive knowledge analytics and its applications. Chapter III explains the technologies used to implement numerous applications. Chapter IV explains the analysis challenges, connected technologies. Chapter V depicts huge knowledge algorithms followed by conclusion and future enhancements.
II. HUGE DATA-AN SUMMARY
A. Big Data
Big knowledge more and more edges each analysis and industrial areas like health care, finance service and industrial recommendation [1]. The social scientist says, knowledge have become a brand new stuff of business. Economic input is sort of love capital and labor. Nowadays, the info to be analyzed square measure dynamic and big in volume, conjointly they're the cluster of various knowledge sorts. These knowledge come back from totally different knowledge sources like Whatsapp, Twitter, Facebook, YouTube, Mobile phones GPS signals and additional. Hence, the massive knowledge has the distinctive options like heterogeneous, unstructured, semi structured, unity, high dimensional. According to industrial knowledge analyst Doug Laney defines the massive knowledge is articulated within the year 2000’s because the 3 V’s [3]:
1) Volume (Data in Rest): Organizations collect knowledge from a range of knowledge sources, together with industrial transactions, social media knowledge {and information|and knowledge|and knowledge} from sensors or machine-to-machine data.
2) rate (Data in Motion): knowledge streams are available at unmatched speed and may be allotted with in associate acceptable manner. totally different quite IoT sensors, RFID tags and sensible metering square measure driving the requirement to affect knowledge flows in real time.
3) selection (Data in several Forms): knowledge comes in several sorts of formats like structured, numeric knowledge in ancient databases to unstructured text documents, email, video, audio, stock and money transactions.
4) Variability (Data in Highlight): Inconsistency of the info set will hamper processes to handle and manage it.
5) truthfulness (Data in Doubt): Refers to the messiness or trait of the info. the standard of captured knowledge will vary greatly, touching correct analysis.
All major IT firms, together with EMC, Microsoft, Google, Amazon, and Facebook, etc. have already got started their huge knowledge comes. To extract info or knowledge from huge knowledge, optimum process power, analytics capabilities and skills square measure required [5]. So, dealing the massive knowledge effectively needs generating the worth against the amount, selection and truthfulness of massive knowledge [7].
B. huge knowledge Analytics Operations
To develop the information discovery in databases (KDD) additional clear, Fayyad and his colleagues finished that the KDD method as shown in Fig one that has choice, preprocessing, transformation, data processing, and interpretation. With the on top of operations, it'll be capable to create a whole knowledge analytics system that is grouping {the data|the info|the info} then realize information from the info and visualize the information to the user.
Fundamentally, processing is seen because the grouping, processing, and management {of data|of
knowledge|of info} for manufacturing new
information for finish users [8]. Karmasphere presently splits huge knowledge analysis into four steps: Acquisition, Assembly, Analyze and Action. Thus, these steps square measure mentioned because the four A’s.
1) Acquisition:
Big knowledge design has got to get high speed knowledge from a unique quite knowledge sources and it has to affect totally different access management protocols. it's wherever a filter might be recognized to store solely knowledge that might
be useful or raw knowledge with a lesser degree of uncertainty [9]. In some applications, the conditions of generation of knowledge square measure vital, thus it may be fascinating for any analysis to capture these information and store them with the corresponding knowledge.
2) Assembly:
At now the design has got to affect numerous knowledge formats and should be able to take apart them and extract the particular info like named entities, relation between them, etc [9]. conjointly this can be the purpose wherever knowledge ought to be clean, place in a very estimable mode, structured or semi-structured, integrated and hold on within the right location. Thus, a form of Extract, Transform, and Load had to be done. Successful cleaning in huge knowledge design isn't entirely bonded. in reality the amount, velocity, variety, and variability of massive knowledge might preclude North American nation from taking the time to cleanse it all totally.
3) Analyze:
Here we tend to have running queries, modeling, and building algorithms to seek out new insights. Mining needs integrated, cleaned, trustworthy knowledge. At the similar time, data processing may also be wont to facilitate enhance the standard and trait of the info, perceive its linguistics, and supply intelligent querying functions [9].
4) Action:
Valuable choices square measure got to be competently interpreting the results from analysis. Consequently it's terribly vital for the user to perceive and verify outputs [9]. Further, origin of the info ought to be provided to assist the user to grasp he obtains.
5) Privacy:
will cause several issues at the analysis of knowledge, at the creation {of knowledge of information} [10] as a result of if we wish to mixture knowledge or to associate it we tend to may ought to access personal data and privacy may also cause inconsistencies at the eliminating of info. To add up handling huge knowledge implies having associate infrastructure linear scalable , able to handle high turnout multi-formatted knowledge, machine recoverable , fault tolerant, with a better degree of similarity and a distributed processing
C. huge knowledge Analytics Infrastructure
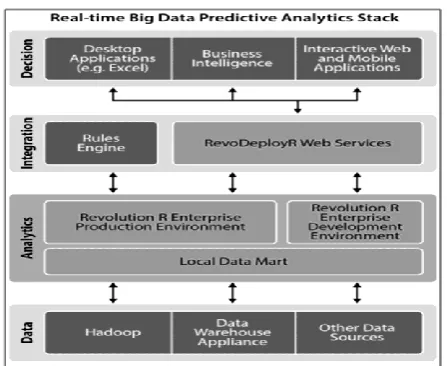
The following Fig one shows totally different layers happens in the big knowledge analytics.
Fig 1: huge knowledge Analytics Implementation Layers
The implementation Layers ar as follows [12]:
1) knowledge Layer This layer has RDBMS based mostly structureddata, Semi-structured and unstructured based mostly knowledge. NoSQL knowledgebases ar wont to store the unstructured data. for example, MongoDB and prophetess ar the NoSQL databases. Streaming knowledge from the online world, social media domain, knowledge from IoT sensors and operational systems ar the examples to unstructured and semi-structured knowledge. software system tools like HBase, Hive, HBase, Spark and Storm are sitting at this
layer. Hadoop and Map scale back conjointly support this layer.
2) Analytics Layer Analytics layer has the setting to implement the dynamic knowledge analytics and deploy the $64000 time values. it's building models developing setting and modify the native knowledge in regular interval. This conjointly improves the performance of the analytical engine.
3) Integration Layer This layer integrates the finish user applications and analytical engine. This includes sometimes a rules engine associate degreed an API for dynamic knowledge analytics.
4) call Layer This layer is wherever the top product hits the market. It includes applications of user like mobile app, desktop applications, interactive net applications and business intelligence software system. this can be the layer wherever individuals act with the system.
Each and each layer delineate on top of is related to totally different sets of finish users in real time and allows a vital section of real time knowledge analytics implementation.
D. huge knowledge Applications
Fig 2: huge knowledge Application Areas
1) Fraud Recognition and Control:
Business operations face several varieties of fraudulent claims or group action process. therefore fraud recognition and management is most reverberating huge knowledge application [15]. In most cases, fraud is discovered long when the actual fact, at that purpose the loss has been done and every one that is left is to attenuate the hurt and regulate policies to stop it from happening once more. huge knowledge platforms that may verify, analyze, claims and transactions in real time, characteristic giant scale patterns across thus several transactions or detective work inconsistent behavior from associate degree individual user, will modification the fraud detection game.
2) center Analytics:
Now we tend to address the client connected huge knowledge application examples, during which center knowledge analytics ar specifically powerful application. the present means of method during a customer's center is commonly an excellent measuring instrument and influencer of market sentiment, however while not a giant knowledge resolution, a lot of of the notice that a center will offer are
ignored or discovered too late. huge knowledge solutions will help ascertain revenant issues or client and employees behavior patterns on the fly not solely by creating intellect of your time or quality resolution metrics, however conjointly by capturing and process decision content itself.
3) Log Analytic in IT:
IT departments and consultancies are generates a large quantity of logs and trace knowledge. while not a giant knowledge resolution, vast volume of the information might go unexamined. All organizations naturally don't have
the supply or men to agitate through all that info by hand, not to mention in real time. With a giant knowledge resolution, but each logs and trace knowledge is also place to higher use. among this list of massive knowledge application examples, IT log analytics is the foremost for the most part applicable. Any organization with an oversized IT department can get help from the ability to quickly determine large-scale patterns to assist in identification and preventing issues within the field. within the same means, any organization with an oversized IT department can intensify the capability to establish progressive performance improvement opportunities.
4) Social Media Analysis:
Of the customer-facing huge knowledge application examples might discuss, analysis of social media activity is one in every of the foremost necessary. everybody and their mothers ar on social media of late, whether or not they like company pages on Facebook or tweeting complaints concerning product on Twitter. A huge knowledge resolution engineered to turn out and investigates social media activity, like IBM's Cognos client Insights, a reality resolution running on IBM's huge Insights huge knowledge platform, might build the sense of the chatter. Social media knowledge will offer real time insights into however the market is responding to product and campaigns. With those insights, corporations will regulate their rating, promotion, and campaign placement on the fly for optimum results.
5) Finance Analysis
Big knowledge analytics are often wont to analyze the money standing and prediction in enterprises. For Example, the tool is analyzing the vital stock market moves and supports in creating international money prediction and choices. albeit this can be not a fool-proof method, it's positively advancement within the field.
In agriculture, biotechnology centers use sensing element knowledge to boost crop potency. It will take a look at the crops and simulates to live the plants reaction to numerous conditions. Its setting
endlessly adjusts to changes within the
characteristics of assorted knowledge together with water level, temperature, growth, output, and cistron sequencing of every and each plant in the testing setting referred to as workplace.
HUGE KNOWLEDGE ANALYSIS
ALGORITHMS
Data mining algorithms and its techniques for knowledge analysis ar enjoying very important role within the huge knowledge analytics in terms of the spatial property reduction, procedure value, memory demand and management and accurateness of the top results. This section provides a quick discussion from the attitude of research and search algorithms [28] to elucidate its importance.
A. clump Algorithm:
One of the foremost common clump tools is CloudVista that is employed in cloud computing to implement the clump method in parallel. BIRCH and alternative clump ways ar utilized in CloudVista to point out that may be handle terribly giant scale knowledge. GPU is another clump tool [22] that is employed to enhance the performance and safety of a clump algorithmic rule.
B. Classification algorithms:
Like clump algorithmic rule for huge knowledge mining, the set up and implementation of classification algorithmic rule learned under
consideration the {input knowledge|input
file|computer file} that ar gathered by the data sources and they can be managed by a heterogeneous set of learners.
C. Frequent Pattern Mining:
Most of the time, data processing researchers on frequent pattern mining ar focusing on handling huge volume of knowledgeset at the terribly
starting as a result of some initial approaches of them tried to look at the information from the group action data {of large|of vast|of enormous} enterprises and searching malls.
D. C4.5:
This tool builds a classifier within the type of decision tree. A classifier may be a tool in data processing that takes a gaggle {of knowledge|of knowledge|of information} that specifies the items wish to categoryify and place efforts to predict that class the new data belongs and the way it belongs to. call tree learning creates more or less the same as a flow chart to classify new knowledge.
E. K-Means:
K-means algorithmic rule creates k teams from a set of knowledge or objects in order that the members of a gaggle ar additional similar. It’s a preferred knowledge clump and analysis technique.
F. Apriori:
The Apriori algorithmic rule learns association rules and is enforced to a information containing a very sizable amount of transactions and its knowledge. Association rule learning is {one of|one among|one during all|one amongst|one in every of} the information mining technique for learning correlations and association among variables in a information.
G. Expectation-Maximization (EM):
This algorithmic rule is typically used as a clustering algorithmic rule for data discovery in mining. In statistics, the EM algorithmic rule iterates and optimizes the probability of seeing
experimental knowledge till estimating the
parameters or values of a applied mathematics model with not experiment variables.
H. PageRank:
some object connected among a network of knowledge objects. This algorithmic rule processes a sort of network analysis trying to explore the associations among objects and rank them.
I. AdaBoost:
Adaboost algorithmic rule constructs a classifier. It is a categoryifier that brings {the knowledge|the info|the information} and tries to predict that class a brand new data part belongs to. The aim of this algorithmic rule is to create a gaggle of weak learners and integrate them to form one sturdy learner.
VI. CONCLUSION
In this literature survey, huge knowledge and its various ideas includes huge knowledge analytics, huge knowledge analytics techniques, knowledge image and massive knowledge analysis algorithmic rule have been studied. conjointly this survey provides summary of the doable opportunities of
massive knowledge analysis setting. {they
ar|they're} as follows i) The planning ways are wont to handle the computation resources of the cloud based mostly platform and to create it to complete the task of knowledge analysis as quick as doable. ii) the opposite problems like {the knowledge|the info|the information} privacy and data security that go together with the work of knowledge analysis ar transmitted inquiry topics that contain instruction to safely store and manipulate the information, the way to make sure the knowledge communication is protected, and the way to ban somebody from looking for the data
concerning America. several issues {of
knowledge|of knowledge|of information} security and knowledge privacy ar primarily constant as those of the normal knowledge analysis albeit we tend to ar getting into the huge data age. Thus, protective the knowledge is the inevitable construct also will seem within the analysis of massive knowledge analytics.iii) The economical ways ar wont to decrease the comparison, sampling,
computation time of input and a kind of reduction ways that ar enjoying a vital role in huge knowledge analyst
REFERENCES
1.Shuhui Jiang, Xueming Qian, Tao Mei, Yun Fu, Personalized Travel Sequence recommendation on Multisource Big Social Media, 2016, IEEE Transactions on Big Data,Vol.2, Issue:1
2. Vallabh Dhoot, Shubham Gawande, Pooja Kanawade and Akanksha Lekhwani, Efficient Dimensionality Reduction for Big Data Using
Clustering Technique, Imperial Journal of
Interdisciplinary Research (IJIR), Vol-2, Issue-5, 2016, ISSN: 2454-1362
3. Gantz J, Reinsel D, Extracting value from chaos.IDC iView, 2011, pp 1–12
4. Cheikh Kacfah Emani, Nadine Cullot,
Christophe Nicolle, Understandable Big Data: A survey, Mobile New Applications 2014, 171-209
5. Mayer-Schonberger V, Cukier K, Big data: a revolution that will transform how we live, work, and think. Boston: Houghton Mifflin Harcourt; 2013.
6. Chen H, Chiang RHL, Storey VC. Business intelligence and analytics: from big data to big impact. MIS Quart.2012; 36(4):1165–88.
7. Kitchin R. The real-time city? Big data and smart urbanism. Geo J. 2014, 79(1), pp: 1–14.
8. Katrina Sin and Loganathan Muthu,
Applications of big data in education data mining and learning analytics – A literature Review, ICTACT Journal on soft computing special issue on soft computing models for big data, July 2015, Vol:05, Iss: 04, pp: 1035-1049
9. Cheikh Kacfah Emani, Nadine Cullot,
10. K. Krishnan, Data warehousing in the age of big data, in: The Morgan Kaufmann Series on Business Intelligence, Elsevier Science, 2013.
11. H.V. Jagadish, D. Agarwal, P.Bernstein, Challenges and Opportunities in Big Data, The Community Research Association, 2015
12. K. Davis, D. Patterson, “Ethics of Big Data: Balancing Risk and innovation”, O’Reilly Media, 2012.
13. K. Krishnan, Data warehousing in the age of big data, in the Morgan Kaufmano series on Business Intelligence, Elsevier Science, 2013.
14. Mike Barlow, Real-Time Big Data Analytics: Emerging Architecture, ISBN: 978-1-449-36421-2, 2013
15.
http://www.techrepublic.com/blog/big-data-analytics/10- emerging-technologies-for-big-data
16. http://hortonworks.com/apache/hbase
17.
http://www.slideshare.net/infoDiagram/big-datacloudappsvisualiconpptinfodiagramtoolbox
18.
https://blog.profitbricks.com/39-data-visualization-tools-forbig-data
19.
https://www.knime.org/files/knimeseventechniques datadimre duction.pdf
20. Seung-Hee Bae, Jong Youl Choi, Judy Qiu, Dimension Reduction and Visualization of Large
High-dimensional Data via Interpolation,
HPDC,2010 Chicago
21. Cheng-Long Ma , Xu-Feng Shang , Yu-Bo Yuan, International conference on machine learning and cybernetics, 2012, vol:4
22. Jun Yan, Benyu Zhang, Ning Liu Shuicheng Yan , Effective and efficient dimensionality reduction for large scale and streaming data preprocessing, IEEE Transactions on Knowledge and data engineering, 2016, Vol:18, issue:3
23. Yetial Fan, Bon song, Yuan Ling, wei wu, A Novel Dimensionality reduction algorithm based on laplace matrix for microbiome data analysis, IEEE International Conference on Bioinformatics and Biomedicine, 2015, pp:49-54
24. Alhussein Fawzi, Bei chen, Pascal Frossard, Mathieu sinn, Structured Dimensionality reduction for additive model regression, IEEE Transactions on knowledge and data engineering, 2016, vol: 28, No:6, pp: 1589-1601.
25. Aswani Kumar, Srinivas.S. A note on the effect
of term weighting on selecting intrinsic
dimensionality of data, Cybernetics and
Information Technologies, 2009, Vol. 9, No. 1, pp: 5-12.
26. J. MacQueen, some methods for classification and analysis of multivariate observations, Proc. 5th Berkeley Symposium. Math. Statist. Probab., Berkeley, CA, 1967, pp. 281–297
27. Xu H, Li z. Guo S, Chen K,Cloudyvista, Interactive and Economical Value Cluster Analysis data in the Cloud, Proc VLDB Endowment. 2012; 5(12):1886–89.