Annotating the functional chunks in Chinese sentences
Qiang Zhou*, Elliott Franco Drabek*, Fuji Ren
* State Key Laboratory of Intelligent Technology and Systems Dept. of Computer Science and Technology,
Tsinghua University, Beijing 100084, P. R. China [email protected], [email protected]
Dept. of Information Science and Intelligent Systems Faculty of Engineering, The University of Tokushima
2-1 Minamijosanjima, Tokushima 770-8506, Japan [email protected]
Abstract
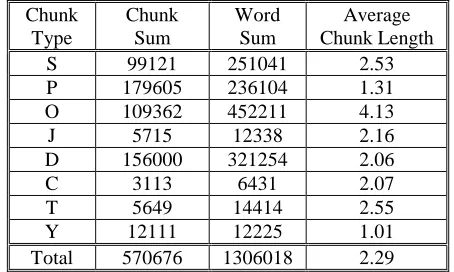
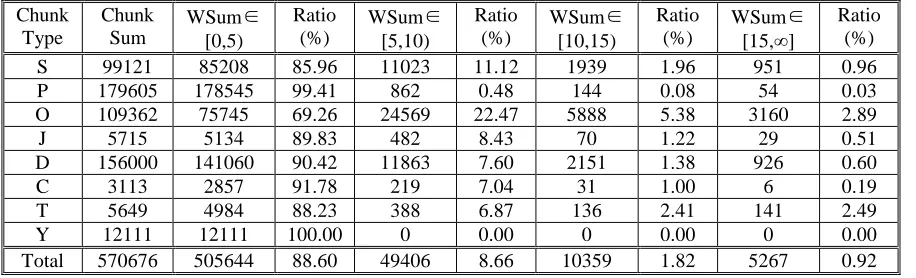
The paper proposed a new syntactic annotation scheme --- functional chunk, which tried to represent information about grammatical relations between sentence-level predicates and their arguments. Under this scheme, we built a Chinese chunk bank with about two million Chinese characters, and developed some learned models for automatically annotating fresh text with functional chunks. We also proposed a two-stages approach to build Chinese tree bank on the top of chunk bank, and gave some experimental results of chunk-based syntactic parser to show the advantage of functional chunk for parsing performance increase. All these work lays good foundations for further research project to build a large scale Chinese tree bank.
1 Elliott F. Drabek has been a Ph.D. candidate in John Hopkins University since Sept. 2001.
1. Introduction
Corpus annotation is a good way to acquire the knowledge of language performance in real texts. How to represent that knowledge in the most informative and efficient way is its fundamental question. There are two extremes among the syntactic annotating schemes now. The simplest way is to assign the words with part-of-speech tags, i.e. categories designed to reflect the syntactic behavior of words. Two typical examples are Brown and LOB corpus in English. This is a good start, and many efficient algorithms have been proposed to automatically assign the correct POS tags with very high precision and recall. But intuition and plentiful experiments tell us that this is not enough, and the idiosyncrasies of individual words and their syntactic relations must be considered. The most complex way is to tag the complete syntactic trees in sentences. A typical example is Penn tree bank (Marcus et al., 1993). Although they can give detailed syntactic information descriptions of the real text sentences, the cost to build a large-scale tree bank is very expansive.
In the resent years, many researchers have devoted to design some better annotation schemes with suitable trade-off between annotation cost and description capability. Abney’s chunk parsing scheme is a good example among them. He defined a chunk essentially as the continuous set of words belonging to a single s-projection, or the domain of a single semantic head. (Abney, 1991). Based on this scheme, CONLL’2000 shared chunk task built an unified training and test set for partial parsing in English (Sang and Buchholz, 2000). The text of the corpus was taken from the Wall Street Journal portion of the Penn Treebank, and the chunks were extracted automatically from the original syntax trees, using straightforward heuristic rules. The quantity of the chunk annotated text amounts to approximately three
hundred thousand words, with an average chunk length of two words. Many automatic partial parsers proposed in the conference showed good parsing performance. But it’s still very difficult to grasp the overall structure of a sentence only based on these chunk information.
The paper proposed a new syntactic annotation scheme --- functional chunk, which tried to represent information about grammatical relations between sentence-level predicates and their arguments. Among this scheme, each sentence can be exhaustively partitioned into a series of non-nested, non-overlapping units, labeled with functional tags, such as subject, object, predicate, complement and so on, while any structural relations within these chunks are left implicit. Compared with Abney’s chunk, the novelty of functional chunk appears in the definition of what constitutes a chunk. Abney’s chunks are defined strictly from the bottom up; a unit qualifies as a chunk based on its internal make-up, regardless of any changes in the larger context, and its category is primarily determined by the category of its head word. By contrast, the functional chunks are defined strictly from the top down; a unit qualifies as a chunk based on its position in the larger context, regardless of its internal make-up, and its category is primarily determined by the grammatical relation between it and the predicate. This top-down characteristic gives more detailed information to grasp the overall structure of a sentence than Abney’s chunk.
1) Word-split and part-of-speech tagged sentences (STSent);
2) Word-split, part-of-speech tagged and functional chunk annotated sentences (CHSent);
This is a close test. All the knowledge based used by the parser were automatically extracted from THTree, including:
1) Probabilistic Context-Free Grammar rules, which can be used for overall disambiguation;
2) Structure Preference Relation rules (Zhou and Ren, 2001), which can be used for local context disambiguation;
Table 7 Experimental results of parser with different input
Input Labelled Precision
Labelled Recall
Crossing Brackets
STSent 76.7% 78.5% 3.04
CHSent 89.5% 89.2% 1.17
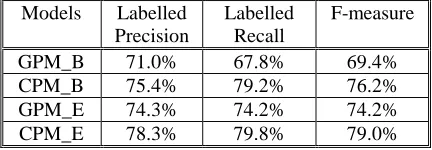
The experimental results in Table 7 shows that functional chunk information bring in great improvement in parsing performance: the labeled precision an recall of the syntactic parser increase about 13%, and the average number of crossing brackets in a sentence is reduced from 3.04 to 1.17. Therefore, the workload for manual proofreading will be greatly reduced.
6. Conclusions and Future Work
The construction of a large-scale linguistically annotated corpus is a long-term and arduous work, where suitable human-machine collaboration is inevitable and retains a central role.The paper proposed a new syntactic annotation scheme --- functional chunk, representing information about grammatical relations between sentence-level predicates and their arguments. We made a tentative step to find suitable trade-off between annotation cost and description capability. Under this scheme, we built a Chinese chunk bank with about two million Chinese characters through manual annotation and proofreading, and developed some learned models for automatically annotating fresh text with functional chunks. Based on the top-down characteristic of functional chunk scheme, We proposed a two-stages approach to build Chinese tree bank on the top of chunk bank, and gave some experimental results of chunk-based syntactic parser to show the advantage of functional chunk for parsing performance increase. The
small-size treebank building experiment on the Chinese text with about 200,000 words have shown the feasibility of this method.
In the future, we plan to give impetus to the above research work in the following directions:
1) Automatically annotate (manually proofread if possible) the constituent type (NP, VP, etc.) and head word information for each functional chunk, and build a new version of chunk bank.
2) Extract useful lexical collocations from new chunk bank and apply them in the partial parsing models to improve parsing performance.
3) Build a 1,000,000 words Chinese treebank annotated with syntactic constituent and function information on the top of current chunk bank.
7. Acknowledgements
This work was supported by the Chinese National Science Foundation (Grant No. 69903007) and National 973 Foundation (Grant No. 1998030507). We would like to thank Prof. Changning Huang for his original idea in functional chunk annotation, Dr. Weidong Zhan and Dr. Haibo Ren for their good suggests to perfect the chunk annotation stylebook, all the corpus builders for their hard works in annotating the chunk bank, and the anonymous reviewers for their insightful comments and suggestions.
8. References
Abney, S. 1991. Parsing by chunks. In Principle-Based
Parsing, Kluwer Academic Publishers,.
Alsina. A. 1996. The Role of Argument Structure in Grammar:
Evidence from Romance. CSLI Lecture Notes No. 62, CSLI
Publications: Stanford, California, USA.
Baker, C.F., Fillmore, C.J., and Lowe, J.B. 1998. The Berkeley FrameNet project. In Proceedings of the COLING-ACL’98,
Montreal, Canada, 86-90.
Drabek, E.F. 2001. Use of Machine Learning Techniques for
Partial Parsing of Chinese. Master thesis, Dept. of Computer
Science, Tsinghua University.
Fillmore, C. J. 1982. Frame semantics. In Linguistics in the
Morning Calm, Hanshin Publishing Co., Seoul, South Korea.
111-137.
Fillmore, C.J., Wooters, C., and Baker, C.F. 2001. Building a Large Lexical Databank Which Provides Deep Semantics. In
Proceedings of the Pacific Asian Conference on Language, Information and Computation. Hong Kong.
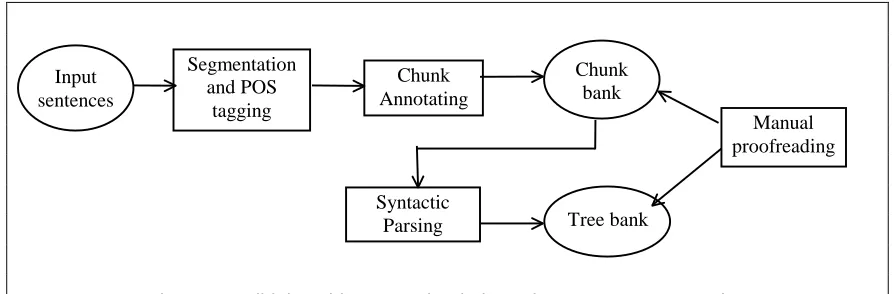
Figure 1 Build the Chinese treebank through two-stages processing Input
sentences
Segmentation and POS
tagging
Chunk Annotating
Syntactic Parsing
Manual proofreading
Tree bank Chunk
Garside, R., Leech, G., and McEnery, A. (eds.) 1997. Corpus
Annotation: Linguistic Information from Computer Text Corpora. Longman, London, England
Kaplan, R. and Bresnan, J. 1982. Lexical-Functional Grammar: A Formal System of Representation, In Joan Bresnan (ed.)
The Mental Representation of Grammatical Relations. MIT
Press, Cambridge, Mass. 173-281.
Marcus, M.P., Marcinkiewicz, M.A. and Santorini, B. 1993. Building a Large Annotated Corpus of English: The Penn Treebank. Computational Linguistics, 19(2), 313-330
Marcus, M., Kim, G., Marcinkiewicz, M.A. et al. 1994. The Penn treebank: annotating predicate argument structure. In Proceedings of ACL’94 post.
Quinlan, J.R. 1993. C4.5: Programs for Machine
Learning, Morgan Kaufmann, San Mateo, CA.
Sang T.K. and Buchholz, S. 2000, Introduction to CoNLL-200 shared task: chunking. In Proceedings of
CoNLL-2000 and LLL, Lisbon, Portugal. 127-132.
Skut, W., Krenn, B., Brants, T., and Uszkoreit, H. 1997. An Annotation Scheme for Free Word Order Language. In Proceedings of the Fifth Conference on Applied
Natural Language Processing(ANLP-97), Washington,
DC, USA.
Yu, S.W., Zhu, X.F., Wang, H., Zhang Y.Y. 1998. The
Grammatical Knowledge base of Contemporary Chinese --- A Complete Specification. Tsinghua
University Press,
Zhou, Q. 1997. A Statistics-Based Chinese Parser. In Proc.
of the Fifth Workshop on Very Large Corpora, 4-15.
Bejing, China.
Zhou Q. 2000. The stylebook for Chinese functional chunk
annotation. Technique report, Dept. of Computer
Science, Tsinghua University.
Zhou, Q. and Ren, F.. 2000. Acquisition and applications of structure preference relations in Chinese. Natural
Language Engineering 6(2): 163-181.
Zhou, Q. and Sun, M.S. 1999. Build a Chinese Treebank as the test suite for Chinese parser. In Proceedings of
the Workshop MAL'99 (Multi-lingual information Processing and Asian Language Processing), Beijing,