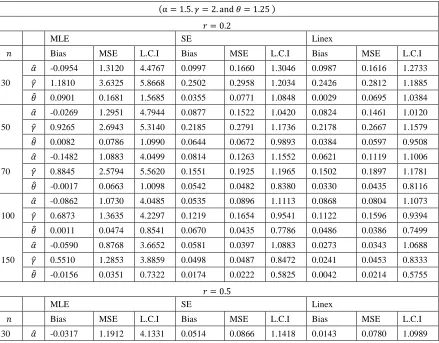
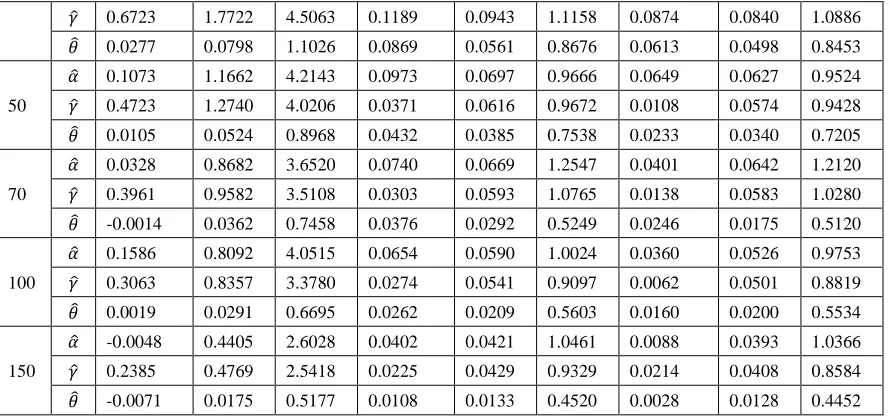
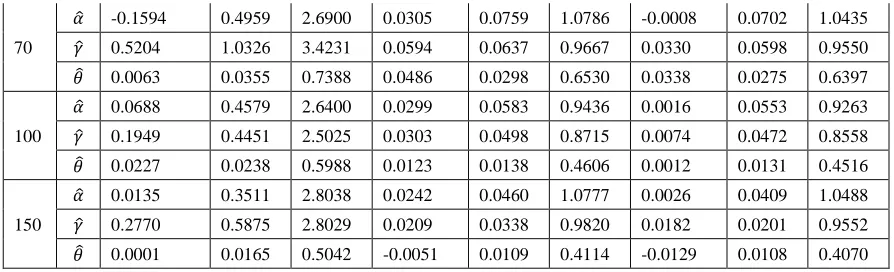
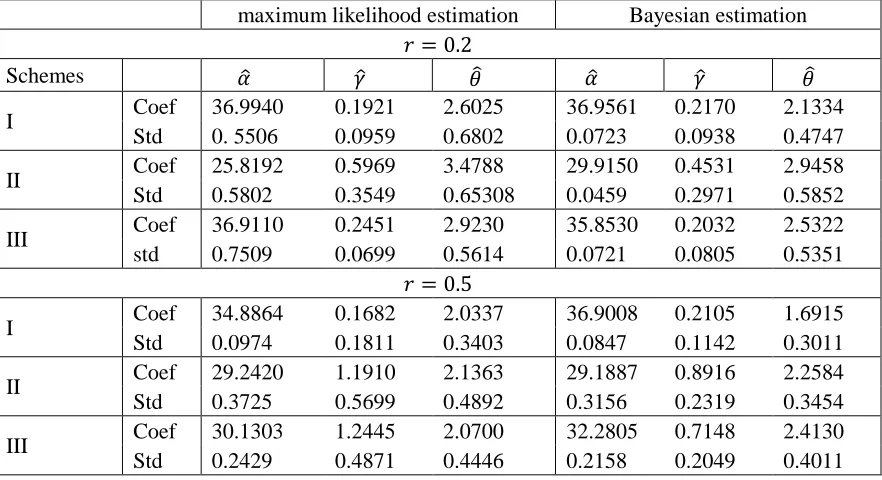
Bayesian and Maximum Likelihood Estimation for the Weibull Generalized Exponential Distribution Parameters Using Progressive Censoring Schemes
16
0
0
Full text
Figure
+5
Related documents