PROBABILITY SPACES IN DATABASES
WITH UNCERTAINTY
Abdallah Alashqur Faculty of Information Technology Applied Science University, Amman Jordan
Abstract
Traditional databases store deterministic data in which there is no room for uncertainty. Uncertain or probabilistic data cannot be represented or stored in these databases. On the other hand, many modern applications require the need to capture and store data with uncertainty. In response to recent demand for the ability to manage and store this type of data, researchers have started exploring techniques to handle probabilistic data in relational databases. Research in this area has focused on aspects of probabilistic data management including: (1) coming up with ways to represent and model uncertain data, (2) querying uncertain data, (3) handling aggregation functions in databases with probabilistic data, and (4) indexing and storage techniques for probabilistic data. In this paper we focus on the first area, which is the representation and modeling of probabilistic data. We show how probability associated with data can be represented in three different probability spaces, namely, attribute probability space, record probability space, and database state probability space.
Keywords: Probabilistic databases; probability theory; uncertainty; advanced database applications.
1. Introduction
Recently there has been increasing interest within the database research community in coming up with powerful ways to handle imprecise and uncertain data. This has been motivated by the growth in the number of modern applications that demand such capability. Examples of applications that need to support imprecise and uncertain data include the following.
Sensor data: Sensors in a factory or in the medical field are just examples of the areas where sensors are being used in current days. Sensor data can sometimes be imprecise due to inherent limitations in the environment or in the sensor equipment. For example two sensors that are not far from each other my report temperature as 25 degrees and 28 degrees respectively. It is possible that one of the two sensors is faulty and needs calibration or replacement.
Information Extraction: When extracting information from text files or from the web in order to load it to a relational database, the person performing the extraction may have a degree of uncertainty regarding some pieces of data. For example, a customer name is recorded as A. Khalid in one location and as Ahmed Khalid in another location. Do the two occurrences of the name refer to the same individual or to two different individuals? When inserting such data in a relational database, we need to be able to capture such uncertainty.
Other applications: In addition to the above examples which lead to uncertainty in the data as an undesirable side effect, there are other applications in which uncertainty is considered a first class citizen because of the nature of these applications. Examples of such applications may include:
A database that stores weather predictions for different parts of the world has to be able to store a lot of uncertain and probable weather forecasted information.
A robot’s perception of the surrounding environment, which is stored in the robot’s knowledge base, is normally associated with a degree of imprecision.
A medical database that stores information about diseases and symptoms has to represent the degree of certainty (or probability) that exists between these diseases and their symptoms.
A marketing database of customers may need to represent the uncertainty associated with each customer in terms of likelihood that the customer may purchase certain merchandise or the likelihood that the customer will pay regularly if financing the merchandise.
In this paper we present a new approach for viewing and presenting probability in databases with uncertainty. In our approach, probability can be considered at three levels of granularity. We demonstrate these three levels with examples and introduce the definitions of the probability space pertaining to each of these three levels. The remainder of this paper is organized as follows. In Section 2 we describe related work in the area of probabilistic databases. Also in section 2 we briefly summarize a variety of research prototype systems that have been described in the literature. In Section 3 we demonstrate several techniques for capturing probability in the database at various granularity levels. In addition we introduce the definition of three different probability spaces that can exist in a probabilistic database. Conclusions are presented in Section 4.
2. Related Work
Traditionally, imprecise data in relational databases have been limited to the handling of null values. A null is used in a field that has an unknown or inapplicable data. Different types of null values with different semantics have been described in [1], which we summarize here. The first type is when the attribute is valid but the value is unknown. An example of that is an Apartment_No attribute as part of the address of an employee. The value is valid but could be left null because the employee did not provide that value.
A second type of null is called marked null. This is used to indicate that two nulls used in two different fields actually refer to the same unknown value. In the example above, if the same marked null is used in the Apartment_No field in two different records, this means that the two employees are living in the same apartment, even though the apartment number is currently unknown. Marked nulls were introduced in [2]
A third type of null is when a value is missing not because it is unknown but because it is not applicable. An example of this is when the Apartment_No field value is left null because the employee lives in a house and not in an apartment. In this case all components of the address exist (street_no, city, etc.) but there is no valid Apartmet_No.
In recent years, many new applications started needing richer representation techniques to be able to capture not only null values but also probabilistic values. Due to such demand, the area of probabilistic databases has become an active area of research.
3. Probability Spaces
The granularity of imprecise data in a relational database can be at the level of an attribute, where an attribute value in a record can actually be a set of probable values instead of just a single deterministic value. Also uncertainty can be at the level of an entire record, where the existence of the record itself is not certain. The third possibility is uncertainty at the level of the entire database.
To demonstrate the various probability spaces that may exist in a probabilistic database, we use the example shown in Table 1. This table shows a Patient table that exhibits both types of imprecision/uncertainty. In addition to the patient’s name, the table stores some vital signs of patients who are presently in the intensive care unit (ICU) in a hospital. The vital signs that the table stores are Temperature and Pulse-Rate (P_rate).
In this table, we use a star “*” to denote uncertain records. The “*” next to record r4 reflects the fact that this record may or may not exist in the database (e.g., it is unsure if the patient has been discharged from the ICU). On the other hand, we use a square bracket to enclose a set of probable values for an attribute. For example, the temperature of patient Huda can be either 38 or 39. Similarly, Andy’s pulse rate can be either 75 or 85.
Table1. Example Probabilistic Database
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda [38,39] 85
r3 Andy 39 [75,85]
r4 Samir 37 70 *
In the remainder of this section we first extend the notion of database state as defined for deterministic databases in order to cover the case of probabilistic databases. Then we introduce three different probability spaces that can exist in databases with uncertainty.
3.1 Database states in probabilistic databases
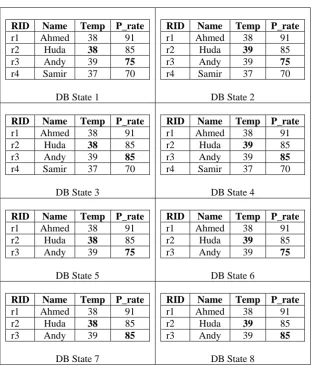
Data that exist in the database at a particular moment in time is referred to, in database terminology, as database state. In deterministic databases (databases that have no uncertain or imprecise data) there can be exactly one database state at any particular moment in time. In databases with imprecise data, there can be multiple possible database states at any particular moment in time. The number of these possible database states depends on how many pieces of uncertain data there exist in the database. Table 2 shows all possible states corresponding to the data represented in Table 1. Since there are two possible values for each of Huda’s temperature and Andy’s pulse rate and there are two possibilities for record r4 (i.e., that record may or may not exist in the database), the total number of possible states is 2 × 2 × 2 = 8, which are the eight states shown in Table 2. Note that the fact that there are these different possible states at any moment of time does not mean that all these possible states are physically stored in the database. The representation shown in Table 2 is a conceptual representation. Optimized storage techniques are needed to avoid consuming a huge storage space when storing probabilistic data.
3.2 Attribute probability space
In the example shown in Table 1, the alternative values are assumed to have equal probabilities by default. For example, Huda’s temperature has a 0.5 probability of being 38 and a 0.5 probability of being 39. Similarly record r4 has a 0.5 probability of existing in the database and 0.5 probability of not existing.
In some situations where the probability is not necessarily equally distributed, explicit probability values need to be assigned. Table 3 shows the same data as in Table 1, but with explicit probabilities assigned to attribute values, where each value is followed by a colon then its probability. For example, Andy’s PULSE_RATE has a 0.6 probability of being 75 and a 0.4 probability of being 85. Formally, we can state these probability assignments as follows.
From probability theory, the sum of the probabilities of the set of attribute values should be one. In other words,
P(r3.Pulse_Rate = 75) + P(r3.Pule_Rate = 85) = 1.
Table 2. The Eight Probable DB States Corresponding to Table 1
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda 38 85
r3 Andy 39 75
r4 Samir 37 70
DB State 1
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda 39 85
r3 Andy 39 75
r4 Samir 37 70
DB State 2
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda 38 85
r3 Andy 39 85
r4 Samir 37 70
DB State 3
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda 39 85
r3 Andy 39 85
r4 Samir 37 70
DB State 4
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda 38 85
r3 Andy 39 75
DB State 5
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda 39 85
r3 Andy 39 75
DB State 6
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda 38 85
r3 Andy 39 85
DB State 7
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda 39 85
r3 Andy 39 85
DB State 8
In probability theory, the set of all possible simple events representing the outcomes of a repeatable experiment is called sample space. Borrowing from probability theory, we refer to the set of possible attribute values of a given attribute in given record and their probabilities as the attribute probability space (APS).
Table 3. Probabilistic Data with Assigned Probabilities
RID Name Temp P_rate
r1 Ahmed 38 91
r2 Huda [38:0.3,39:0.7] 85
r3 Andy 39 [75:0.6,85:0.4]
r4 Samir 37 70 0.8
3.3 Record Probability Space
Similarly, explicit probabilities can be assigned to represent the uncertainty associated with the existence of records. As shown in Table 3, instead of a “*” to indicate that the existence of record r4 is not certain, a probability of 0.8 is used to indicate that the probability that r4 exists is 80%. We refer to this probability as record existential probability. Formally, we can state this as follows.
Where P(r4) denotes the existential probability of record r4. The probability that a record exists and the probability that it does not exist should add up to one. Therefore,
P(r4) + P(¬r4) = 1
Where P(¬r4) denotes the probability that record r4 does not exist in the database. We can compute P(¬r4) by rearranging the above equation to obtain:
P(¬r4) = 1 – P(r4) = 1- 0.8 = 0.2
We refer to the set of different record possibilities of a given record along with their probabilities as record probability space (RPS). Therefore the RPS of record r4 consists of the set {P(r4) = 0.8, P(¬r4)= 0.2}.
3.4 State probability space
Similar to the attribute probability space and record probability space, we can define state probability space
(SPS). A state probability space represents the set of possible database states and their probabilities. For
example, Table 2 shows the state probability space corresponding to Table 1 (where equal probabilities of the alternatives are assumed).
The some of the probabilities of these different states should be exactly one as represented by the following equation.
1
Where n is the number of different states and Pi is the probability of state i. Since the eight states shown in Table 2 have equal probabilities, we can conclude that the probability of each state is
Pi = (1/8) = 0.125
In summary, in our representation of uncertain data we have introduced the definition of three different probability spaces. These, as ordered based on granularity of data from smaller to larger, are:
Attribute probability space (APS) that pertains to the set of possible values of an attribute along with their probabilities.
Record portability space (RPS) that pertains to the different possible instances of a record along with their existential probabilities.
State probability space (SPS) which represents the different possible states and their probabilities for the entire database.
4. Conclusions
In this paper we have described the need to represent and model probabilistic data in relational databases. Many new applications demand such capability. Examples of these applications are: data integration, sensor data, information extraction from text and legacy databases. In addition to these applications, several applications require to handle probabilistic data by nature of the application and not just as an undesirable side effect. For example, medical databases that store symptoms and diseases need to capture the probability associating a symptom with each of the potential diseases that exhibit that symptom. Due to this need, the area of probabilistic databases has emerged as a very active and important area of research.
Acknowledgement
The author is grateful to the Applied Science Private University, Amman, Jordan, for the partial financial support granted to this research project (Grant No. DRGS-2012-2013-29).
References
[1] T. Imielinski and W. Lipski (1984). “Incomplete information in relational databases”, Journal of ACM 31, 761–791.
[2] J. Widom (2005). “Trio: A System for Integrated Management of Data, Accuracy, and Lineage”. In: Proc. of Conf. on Innovative Data Systems Research (CIDR).
[3] N. N. Dalvi, C. R_e, and D. Suciu (2009). “Probabilistic databases: diamonds in the dirt”. Communication of the ACM, 52(7):86-94. [4] N. N. Dalvi, K. Schnaitter, and D. Suciu (2010). “Computing query probability with incidence algebras”. In PODS, pages 203-214. [5] R. Fink, D. Olteanu, and S. Rath (2011). “Providing Support for Full Relational Algebra in Probabilistic Databases”. In ICDE, pages
315-326.
[6] A. Jha, D. Olteanu, and D. Suciu (2010). “Bridging the Gap Between Intensional And Extensional Query Evaluation In Probabilistic Databases”. In EDBT, pages 323-334.
[7] C. Koch (2009) “On Query Algebras for Probabilistic Databases”. SIGMOD Rec., 37:78-85, March.
[8] J. Li, B. Saha, and A. Deshpande (2009) “A Unified Approach to Ranking in Probabilistic Databases”. PVLDB, 2(1):502-513. [9] P. Bosc and O. Pivert (2010). “Modeling and querying uncertain relational databases: A survey of approaches based on the possible
worlds semantics”, International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 18(5):565-603.
[10] L. Antova, C. Koch, and D. Olteanu ( 2007). “MayBMS: Managing Incomplete Information with Probabilistic World-Set Decompositions”. In: Proc. of Intl. Conf. on Data Engineering (ICDE).
[11] J. Boulos, N. Dalvi, B. Mandhani, S. Mathur, C. Re, and D. Suciu (2005) “MYSTIQ: a system for finding more answers by using probabilities”. In: Proc. of ACM SIGMOD Intl. Conf. on Management of Data.
[12] L. V. S. Lakshmanan, N. Leone, R. Ross, and V. Subrahmanian (1997). “ProbView: A Flexible Probabilistic Database System”. ACM Transactions on Database Systems (TODS), Vol. 22, No. 3, pp. 419–469.
[13] R. Cheng, S. Singh, and S. Prabhakar (2005). “U-DBMS: A Database System for Managing Constantly-Evolving Data” In: Proc. of Conf. on Very Large Data Bases (VLDB).
[14] R. Jampani, L. Perez, M. Wu, F. Xu, C. Jermaine, and P. J. Haas (2008). “MCDB: A Monte Carlo Approach to Managing Uncertain Data”. In: Proc. of ACM SIGMOD Intl. Conf. on Management of Data.
[15] D. Z. Wang, E. Michelakis, M. Garofalakis, and J. M. Hellerstein (2008 ). “BayesStore: Managing Large, Uncertain Data Repositories with Probabilistic Graphical Models”. In: Proc. of Conf. on Very Large Data Bases (VLDB).
[16] D. Olteanu, J. Huang, and C. Koch (2010). “Approximate Confidence Computation in Probabilistic Databases”. In ICDE, pages 145-156.
[17] C. Re and D. Suciu (2009). “The Trichotomy of HAVING Queries on a Probabilistic Database”. VLDB J., 18(5):1091-1116.
[18] S. Roy, V. Perduca, and V. Tannen (2011) “Faster Query Answering in Probabilistic Databases Using Read-Once Functions”. In ICDT, pages 232-243.
[19] P. Sen, A. Deshpande, and L. Getoor (2010). “Read-once Functions and Query Evaluation In Probabilistic Databases”. PVLDB, 3(1):1068-1079.
[20] M. A. Soliman, I. F. Ilyas, and S. Ben-David (2010). “Supporting Ranking Queries on Uncertain And Incomplete Data”. VLDB J., 19(4):477-501.