Available at http://www.ijcsonline.com/
XLARGE: an efficient XML Compressor for simple, large and repetitive
document
Debashish Roy
School of Education Technology Jadavpur University
India
Abstract
In Last few years XML has became standard of data interchange in most of the applications over the web. Most of the Enterprise level application, Middleware software adopted XML as their standard medium for data interchange. So in these days of Internet and web technology popularity of XML is huge. The power of XML lies in its self describing abilities. This same ability makes XML verbose thus introducing significant amount of redundancy that adds no particular value. Increased size of XML documents create burden on application and network bandwidth. So there is a clear requirement for good and effective data compression algorithm for XML. Traditional ZIP utility like GZIP compressed the XML data in a non readable format means we can't query those data until it's decompressed. So in this paper I had developed an efficient XML compression utility named as XLARGE. XLARGE has shown a significant amount of improvement in compression ratio over GZip.
Keywords: XML, Data Compression, Web Technology.
I. INTRODUCTION
In the last few years, XML has become the standard for communicating among heterogeneous systems. XML is used to standardize information exchange in a variety of fields ranging from business reporting (XBRL) to sports SportsML). The power of XML lies in its self describing abilities. This same ability makes XML verbose thus introducing significant amount of redundancy that adds no particular value. In addition, the increased size affects both query processing and data exchange. XML files require a lot more storage space and network bandwidth. Therefore, it is particularly important to explore effective compression techniques that will help reduce the usage of these resources yet not compromise on speed and flexibility. [10]
Extensible Markup Language (XML;
www.w3c.org/XML/) is the widespread format for structured documents and data on the Web. With the vision of the semantic Web becoming a reality, communication of information on the machine level will ultimately be carried out through XML. As the level of XML traffic grows so will the demand for compression techniques which take into account the XML structure to increase the compression ratio. With the proliferation of mobile devices, such as palmtop computers, as a means of communication in recent years, it is reasonable to expect that in the foreseeable future, a massive amount of XML data will be generated and exchanged between applications in order to perform dynamic computations over the Web. However, XML is by nature verbose, since terseness in XML markup is not considered a pressing issue from the design perspective. In practice, XML documents are usually large in size as they often contain much redundant data, such as repeated tags.
The size problem hinders the adoption of XML, since it substantially increases the costs of data processing, data
storage, and data exchanges over the Web. There are a number of XML compression techniques available today which were developed, and tested over the last few years. gZip is the most widely used commercial compressor available. Since XML is represented as a text file, an obvious choice for a compression tool would be a general-purpose compression tool such as gZip. gZip was developed by Jean-loup Gailly and Mark Adler and uses a combination of the LZ77 algorithm and Huffman coding.
II. LITERATURE REVIEW
The eXtensible Markup Language (XML) has been acknowledged to be one of the most useful and important technologies that has emerged as a result of the immense popularity of HTML and the World Wide Web. Due to the simplicity of its basic concepts and underlying theories, XML has been used in solving numerous problems such as providing neutral data representation between completely different architectures, bridging the gap between software systems with minimal effort and storing large volumes of semi-structured data [2].
minimizing the main memory requirements of processing and querying XML documents.[2]
The major text compressor algorithms are Gzip , Bzip2 , WinZip , PKZIP and MPEG-7(BiM).Also there are a number of XML compression techniques available today which were developed, and tested over the last few years namely XMill, XGrind, Xpress, and XComp.
A. GZIP
This general-purpose compression utility is relatively very popular and is used in many commercial implementations. gZip has its own pros and cons. The benefits of using such a tool would be:
• This tool is widely available in both open-source and commercial implementations
• gZip provides better compression rate (40-50%) and freedom from patented algorithms
• Using gZip requires no knowledge of the document-structure.
• gZip is built into http and web-servers as a standard feature. However, the main disadvantage with using gZip to compress XML files is:
• Compression of elements/attributes may be limited due to the long-range dependencies between elements and between attributes. (Duplication is not necessarily local) .This means that generic compression algorithms are limited because they do not leverage document semantics.
Gzip[3] is based on the DEFLATE algorithm, which is a combination of LZ77 and Huffman coding. DEFLATE was intended as a replacement for LZW and other patent encumbered data compression algorithms, which, at the time, limited the usability of compress and other popular archivers.
Gzip is not to be confused with the ZIP archive format, which also uses DEFLATE. The ZIP format can hold collections of files without an external archiver, but is less compact than compressed tarballs holding the same data, because it compresses files individually and cannot take advantage of redundancy between files (solid compression)[3].
B. XMill
XMill is a new tool for compressing XML data efficiently. It is based on a regrouping strategy that leverages the effect of highly-efficient compression techniques in compressors such as gzip. XMill groups XML text strings with respect to their meaning and exploits similarities between those text strings for compression. Hence, XMill typically achieves much better compression rates than conventional compressors such as gzip.[4]
Prior to the main compression process, a pre-compression phase is introduced in XMill before the data is compressed by Gzip. There are two special objectives in the pre compression phase in order to optimize XML compression:
to separate the document structural information from data, and
to group data items with related semantics in the same \container".[5]
The main disadvantages of XMill are as follows [6]: Compressed output of XMill is not queryable. To be
queried, the document has to be decompressed.
If the size of the input document is less than 20KB, XMill will not exhibit any significant advantage over gzip.
III. PROBLEM STATEMENTS AND OBJECTIVE
While XML is widely used on the Internet for a wide variety of tasks, including configuration files, protocols, and web services, XML is a very verbose syntax. Simple messages can be quite large, considering how little information is actually conveyed. So there is a huge demand for an efficient XML compression techniques exist. Several XML compression tools have been proposed in the literature of the recent years. Using XML compressing techniques can have many advantages such as: reducing the network bandwidth required for transmitting the XML data, reducing the disk space required for storing the original documents and minimizing the main memory requirements for representing the XML documents.
So there is a clear need for an efficient XML compression algorithm exists. Our objective is to develop an efficient XML compression algorithm for simple, large and repetitive documents.
For our experiment we will primarily consider XML file which is having simple 2 level structures. We will not consider any deeply nested XML structure. Also we will not take xml namespace, namespace prefix and attribute into our consideration. We will mainly target to improve the compression ratio for large and repetitive XML files.
IV. PROPOSED DESIGN
Our present work will mainly emphasize on designing an xml compression and decompression module which will work effectively in case of simple, large and repetitive
A. Compression Algorithm
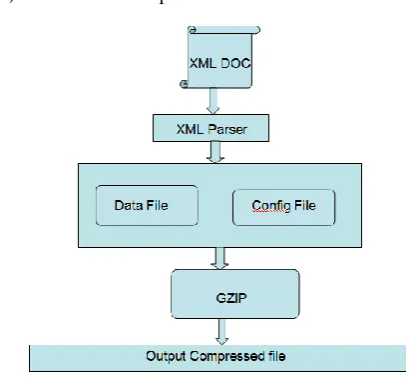
1) Read the XML file via DOM Parser. 2) Separate the Data and tag from the file.
3) Compressor Module will Create 2 Files from the source Xml.(One Data file and Config File)
Data file: data File will contain the data. Every data will be separated via some Separator.
4) Apply Standard Text compression algorithm gzip on Data file and Config File.
5) Transmit the compress file.
Fig 1: Flowchart of the compression Algorithm
Example:
Suppose we are going to implement our compression algorithm on the below xml file
Fig 2: Sample Source XML file
So using XML parser we will create two separate files (one data file and another is config file) from the above source xml file.
So our data file will contain all the data with some field separator.
Fig 3: Sample output data file
And our config file is another XML file which contains the necessary configuration data that will be used by decompression module to correctly recreate the xml file.
Fig 4: sample output config File
Configuration file XML tag name
XML tag “D” indicate XML Document Name. XML tag “R” indicates XML Record set Name. XML tag “F” indicate XML Document field Names.
B. Decompression Algorithm:
1) Read the transmitted compressed file.
2) Decompress the data using Standard Text compression algorithm gzip.
3) Retrieve the data file and config file
4) Decompress module will reconstruct the XML file using the data file and config file.
V. RESULTS AND INTERPRETATIONS A. Data Sets
For Experimental evaluation purpose we have created one XML data set containing total 17 XML files. The documents are selected to cover a wide range of sizes.
B. Testing environments
C. Examined compressors
In our study we examine mainly GZIP compression technique and our proposed methods.
D. Performance metrics
I measured and compare the performance of the XML compression tools using the following metrics:
Compression Ratio: represents the ratio between the sizes of compressed and uncompressed XML documents as given by:
Compression Ratio = (Compressed Size)/(Uncompressed Size).
For all metrics: the lower the metric value, the better the compressor.
Improvement Percentage Over GZip(IPOG):
Improvement Percentage Over GZip(IPOG)=( CRG-CRO)/ CRG
Where
CRG= Compression ration using GZIP and
CRO=Compression ratio using our proposed method
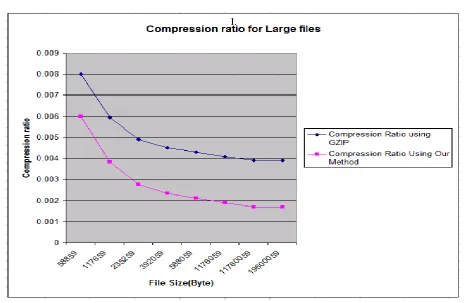
Fig 5: Compression Ratio and Improvement percentage for large files
I.
Fig 6: A graph for GZIP Vs XLARGE method performance for large files
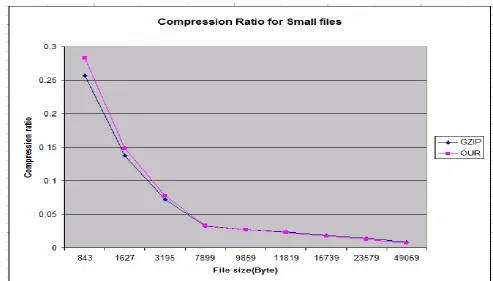
Fig 8: A graph for GZIP Vs my method performance for small files
II. CONCLUSIONS AND FUTURE SCOPE A. Conclusion
In this paper i introduced a novel method for XML compression which provides more than 50% improvement in the compression ratio in compare to standard compressor like GZIP. It can be concluded that specific application types determine the choice of the compressor. In a local distributed system, where the size of XML documents that need to be transferred will usually be small , our method is not advantageous . In such a case, it would be best to use a general-purpose compressor such as GZip or WinZip.
There is also a possible thought that since bandwidth is very cheap now a day so there is really no need for compression. However, with the advent of wireless devices such as phones, PDAs etc, bandwidth is at a premium. Therefore, compressing data to transmit to such devices becomes essential.
So our Compression method is very effective in case simple, large and repetitive data files.
B. Future Scope
Our proposed method is very effective and shown great improvement in compression ratio but it has some limitation in terms of wide applicability. So there is a huge opportunity of future work.
(1) Our Concept can be implemented for wide range of XML files and evaluate the performance (with support for attribute, namespace prefix, XML namespace, deep nested structure).
(2) Work on the Query module to support query on the compressed data.
(3) Implement SOA (Web service based) based approach on the Compression/Decompression module.
REFERENCES
[1] C.J. Augeri, B.E. Mullins, L.C. Baird, D.A. Bulutoglu, and R.O. Baldwin. An Analysis of XML Compression Efficiency. In Proceedings of the 2007 Workshop on Experimental Computer Science (ExpCS '07), 2007. Additional information about the study, including links to the XML corpus used in the paper, is available at http://www.chris-augeri.com/docs/xml_compress.htm.
[2] Sherif Sakr. XML compression techniques: A survey and comparison.Journal of Computer and System Sciences 75 (2009) 303–322. Additional information about the study, including links to the XML corpus used in the paper, is available at http://www.cs.panam.edu/~artem/main/teaching/csci6370spring201 1/papers/XML%20compression%20techniques%20A%20survey%2 0and%20comparison.pdf
[3] http://en.wikipedia.org/wiki/Gzip
[4] Xmill: An Efficient Compressor for XML, http://www.liefke.com/hartmut/xmill/xmill.html
[5] Wilfred Ng Lam, Wai Yeung ,James Cheng. Comparative Analysis of XML CompressionTechnologies. paper is available at http://www.cs.ust.hk/~wilfred/paper/wwwj05.pdf
[6] Pankaj M. Tolani, Jayant R. Haritsa.XGRIND: A Query-friendly XML Compressor. paper is available at http://reference.kfupm.edu.sa/content/x/g/xgrind__a_query_friendly _xml_compressor__87177.pdf
[7] D. Huffman, “A Method for Construction of Minimum-Redundancy Codes”, Proc. of IRE, September 1952.
[8] J. McHugh, et al. “Indexing Semi-structured Data”,Technical Report, Computer Science Dept., Stanford University, January 1998.
[9] http://www.ebi.ac.uk