Image Data Classification using Hadoop
Based on Semi Supervise Algorithm
Dr. Pratik Gite1, Aditya Acharya2, Udit Gupta3 Assistant Professor (IES IPS, Indore)1
Student (IES IPS, Indore), 191 MIG, Meghdoot Nagar, Mandsaur, (MP), India2 Student (IES IPS, Indore), 5/1 Holani Sadan, Mahesh Nagar, Indore, (MP), India3
Abstract: In this paper, an technique is presented for
storing and dispensation bulky satellite images by using the Hadoop MapReduce framework and HDFS(Hadoop distributed file system)by incorporate Remote Sensing image processing tools into MapReduce The huge volume of visual data in current years and their require for efficient and efficient processing arouse the exploit of distributed image processing frameworks in image processing area. So that up to the imminent years, numerous algorithms which have been bring in in the field of image processing and pattern recognition should believe the necessities for macro image processing in order to be salutation by the outside world. This paper provides an indication of distributed processing method and the programming models. . To proposed image data classification with hadoop based on semi supervise SVM learning algorithm. The experiment consequence illustrate that the proposed system can attain a enhanced consequence even dealing with big data volume
Keywords: big data, Hadoop, yet another resource
negotiator (YARN), parallel processing, remote sensing (RS).
I. INTRODUCTION
MapReduce [1] has materialized as the nearly all significant programming model for large-scale distributed data processing. The current years using Hadoop open source framework. Hadoop and its processing model are recently formed and like several other innovative technologies might have its own issues, such as need of acquaintance of the mainstream of IT society with it, lack of sufficient specialist forces, and unnecessary defects and problems appropriate to its novelty. though, this processing style that use MapReduce model and distributed file system, will be amongst the nearly all helpful tools for image processing and pattern recognition in the coming years appropriate to its faithfulness with cloud computing structures. To
proposed technique for image data classification using semi supervise learning algorithm based on (Support vector machine) SVM. An Image Recognition System is use to automatically categorize or substantiate a person or an object from a digital image One of the ways to do this is by compare chosen image features from the database. This use for retrieving the subsequent images from the database base on their feature of images which consequent the image itself. The retrieval of the image is base on the content of an image and it is additional resourceful than the text based which is called content based image retrieval that are used for a a variety of application like vision technique of computer .
conventionally, investigate of the images are with text, tags or keywords or annotation allocate to the image while store into the databases. Where as if the image which is accumulating in the database are not exclusively or specially tag or wrongly illustrate then it’s unsatisfactory, arduous and enormously time overwhelming job for searching the exacting image in the huge set of databases. For receiving most precise result Image Recognition Systems are used which search and retrieve the query images from the huge databases based on the image content which is resulting from image itself by with image processing techniques.
To store such immense amount of data as a substitute of with an effortless Client Server architecture it’ll be enhanced to use architecture where in the data demonstrate the property of logical independence. A scheme where in the data has to be distributed on a huge number of workstations so that it might reduce the load of analysis on a single machine.
lot around us at every times. each digital process system, mobile devices ,sensors and transmit it. Big data is inward from manifold sources at an disturbing velocity, quantity and diversity. To extract significant value from big data, you require optimal processing power, analytics capability and skills. To utilize semi supervise learning algorithm based on support vector machine. To classified the data label and unlabeled . receiving the accrue data set subsequent to training testing.
Spatial Big Data Spatial big data refers to data or in sequence that bring up and illustrate geographic features and restrictions of objects [4]. Spatial big data is accumulate into databases as organize and topology for satellite objects such as ocean, lake, plants etc. Spatial data [5] can be as well called as geospatial data, spatial information or geographic information. This type of data is usually process and manipulate by GIS. Spatial data can be categorize into three types: raster data, vector data and network data [6]. Section 2 explains related work in image processing with HDFS and MapReduce over Hadoop framework. Section 3 describe anticipated two phase extended system semi supervise SVM learning algorithm and usage of APIs. Section 4 describe experimental consequences, and Section 5 present the conclusions and future work.
II. RELATED WORK
Image processing and computer vision
algorithms can be functional as multiple self-determining responsibilities on huge scale data sets concurrently in parallel on a distributed system to accomplish higher throughputs
Yang Hu et al[1] have developed a steady, scalable, quick processing, and uncertainty in g system based on Hadoop to put back our initial MySQL RDBMS design. to bring in a frequent research analytics and
data lifecycle situation for energy (Energy
CRADLE), with the distributed computing platform Hadoop and its database tool, HBase, to resolve the obtainable data management and dispensation metrics.
Swapnil Arsh et al[2] In this work obtainable an technique to parallely development an image row-wise column-row-wise. In the procedure pragmatic the modify in dispensation time with a modify in the allocated per mapper task. The split is critical in order to entirely utilize the power of parallel processing. Splitting should be complete in a way, such that the entirety work is regularly divided and as well the lessening in time taken to process the image by every mapper should additional than recompense
the boost in time outstanding to the conception of additional instances of the mapper
Abdulrahman Alhamali et al[3] present in feature the architecture of our hardware prototype. to as well report investigational performance and energy
measurements when distributing subterranean
learning difficulty neural networks for training across a Hadoop cluster of computational nodes, where every node is increased with FPGA hurrying
hardware for dispensation the the majority
performance-critical tasks in the CNN algorithm
Michael R. Evans et al[4]To benefit from on these novel datasets, intrinsic confront that come with spatial big data require to be address. For example, lots of spatial operations are iterative by nature, incredible that parallelization has not hitherto been intelligent to handle totally. By increasing cyber-infrastructure, can tie together the power of these enormous spatial datasets. Novel form of analytics with simpler models and richer neighborhoods will facilitate solutions in a diversity of disciplines.
Almeer, M. H et al[5] obtainable a casing study for implement parallel processing of remote sensing images in TIF format by with the Hadoop
MapReduce framework. The experimental
consequences have exposed that the typical image
processing algorithms can be successfully
parallelized with satisfactory run times when useful to remote sensing images.
. Hadoop [6]an open source framework for address huge scale data analytics with HDFS and MapReduce programming models. In adding to Hadoop, there are a number of other frameworks like Twister [7] for iterative computing of stream text analytics, and Phoenix [8] used for map and reduce function for distributed data concentrated Message Passing Interface (MPI) variety of application.
III. RESEARCH METHODOLOGY
To strength focus on images processing for huge scale database and still for big scale satellite images get from social media like face book, Amazon etc.
This paper presents an technique based
stronger their strength using Based On Semi Supervise Algorithm using support vector machine (SVM). accepted data analysis technique like Map Reduce offer a lot of features like the generation of a
programming model and its connected
implementation in organize to development and produce huge datasets to with semi –supervised laerning algoritham image data clasified labeled and unlabeled data set paerfom the taining using SVM and perform the testing
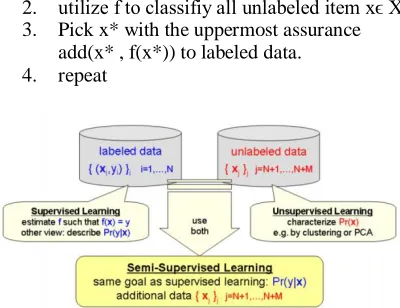
Using together labeled and unlabled data to construct enhanced classifiers (than using labeled data alone )
Notation
Imput x , label y
Classifier f: x-->y
Labeled data(Xl , Yl)={(x1 ,y1)…..(xl,yl)}
Unlabeled data Xu= (xl+1….xn)
Usually= n>>l
Algorithm
1. Pick SVM image data categorization
method. Train a classifier f from (Xl , Yl)
2. utilize f to classifiy all unlabeled item xϵ Xu
3. Pick x* with the uppermost assurance
add(x* , f(x*)) to labeled data.
4. repeat
Figure1:semi –supervised laerning algoritham
The primary step in the system entail create a list of accessible data sources that distinguish the nature of those data with reference to comprehensiveness, strength, reliability, timeliness, and accurateness. Through a observation to store a huge number of remote sensing image to utilize the Hadoop Distributed File System , HDFS [8] characterize the distributed file-system which assist in the storage of data on service machines and in as long as very high collective band width transversely the cluster.
included Remote sensing image are then prepared for processing, so that consistency among the input and consequences could be refied. Metadata is also retain for a future use by one more analyst who can reconstruct the consequences and make stronger their strength Semi-supervised SVM algorithm
The preparation of support vector machines
Two classes yϵ{+1,-1}
Labeled data (Xl , Yl)
A kernel K
The replicate hilbert kernel space HK
SVM discover a function f(x)=h(x)+b with hϵ
HK Classify x by sign(f(x))
Algorithm: semi-supervised
Input: kernel K , weights ƛ1,ƛ2 , (Xl , Yl) , Xu
Solve the optimization problem for f(x)=h(x)+b , hϵ
HK
SVM‖ℎ‖2∑ =1(1 − ( )) +ƛ1+ ƛ2∑ = +11 − | ( )|)
Classify a innovative test position x by sign(f(x))
To proposed system architecture using machine learning algorithm data analysis technique like Map Reduce present a assortment of features like the establishment of a programming model and its associated implementation in organize to process and create large datasets. MapReduce has two most important tasks the JobTracker, reserve management and job scheduling monitor and they work into divide daemons. The Resource Manager has two most important parts:
Scheduler and request Manager. The Scheduler is accountable for allocate resources to the a variety of running applications subject to recognizable
constraint of capacity, queue. The objective of this phase is to separate into part the image datasets into numerous logical splits, and then allocate these split to matching nodes to read and procedure the data in parallel. Then every compute node receives the allocate splits, the contribution remote sensing images will be chosen to practical number of Map tasks allowing for data district and workload opposite then call the equivalent functions present by OTB (The Orfeo ToolBox )library to procedure the
referred images. consequently The Reduce
assignment will accumulate every the status reports establishment the Map task. subsequent to having effectively absolute these tasks and To test the probability of our technique to realize Semi supervise learning algoritham in regulate to compare the two consequences of remote sensing image classification. To prefer SVM for the reason that is a accepted data mining algorithm. As a concluding step many option are specified to visualize the consequences
IV.RESULT ANALYSIS
Our training and testing environment is collected of 5 PC computer(Intel i5, 16GB Memory, 2TB HDD, Ubuntu 16.0 64 bit Linux systems, Hadoop 2.6 and Java SE 7), the primary computer worked as NameNode whereas the responsibility of others is DataNode. every of them are associated by 1 gigabit switch. The remote sensing images use for the experiment are get from the satellite, They are consisted of 100 image files, every of which has 6366 5840 pixels declaration , 5 bands and its size is about to 60MB.In arrange to validate the efficiency of our scheme, every the image data more randomly alienated into 5 groups. Then we decide the classification tool in the OTB which describe in the subsequent phase of processing (a map algorithm) to be appropriate a categorization to one of the input image files (Fig.2) and to evaluate the consequences with a semi supervise learning algorithm to the identical input file. Illustrate a evaluation of the classification accuracy amongst the proposed approaches and the semi supervise learning algorithm Based on SVM. As we be able to note, the overall accuracy is amplified from 82.50% for the semi supervise learning algorithm Based on SVM to 90.94% for our technique, acquire complete benefit of the integrated configuration possessions, and it create enhanced consequences than the traditional semi supervise learning. So our proposed approach application will be valuable in future to the subsequent sectors: 1. Meteorological disaster -
Violent, unexpected and unhelpful modify to the environment connected to, formed by, or distressing the earth's atmosphere, particularly the weather-forming process. 2. Military navigation - learning of traverse during untried ground by base or in a land vehicle. 3. Key end corresponding among two images competition the key points next to a database of that get from training images by pronouncement the adjacent neighbor a key summit with minimum Euclidean distance. 4. Monitoring approximately the
sphere to extract discriminative information
concerning regions of the world for which GIS data is not obtainable. 5. Feature vector generation and its learning is extremely important characteristic in machine learning.
IV. CONCLUSIONS AND FUTURE
WORK
Image processing applications covenant with processing of pixels in comparable, for which Hadoop and MapReduce can be successfully used to get superior throughputs. though numerous of the algorithms in Image Processing and additional scientific computing, necessitate use of neighborhood data, for which the obtainable technique of data association and processing are not appropriate. We presented an extensive HDFS and MapReduce interface, called Semi-supervised SVM algorithm, for image processing application. Semi-supervised SVM algorithm present extended library of HDFS and MapReduce to development the single large scale images with high level of concept over writing and reading the images. We plan to implement the bi-directional opening as well in the proposed system, which would be the prerequisite for huge scale canvas images. In future effort propose MapReduce APIs could be comprehensive for a lot of more Image giving out and Computer vision modules. It is also proposed to enlarge the similar to multiple image formats in the inhabitant format itself.
Acknowledgments:
REFERENCE
[1] Yang Hu, Member, IEEE, Venkat Yashwanth Gunapati, Pei Zhao, Devin Gordon, Nicholas R.Wheeler,,” A Nonrelational Data Warehouse for the Analysis of Field and Laboratory Data From Multiple Heterogeneous Photovoltaic Test Sites” IEEE JOURNAL OF PHOTOVOLTAICS, VOL. 7, NO. 1, JANUARY 2017
[2] Swapnil Arsh , Abhishek Bhatt†, Praveen Kumar,” Distributed Image Processing Using Hadoop and HIPI” 2016 Intl. Conference on Advances in Computing, Communications and Informatics (ICACCI), Sept. 21-24, 2016, Jaipur, India.
Morcel, Mazen Ezzeddine, Omar Hamdan, Haitham Akkary, and Hazem Hajj ,” FPGA-
Accelerated Hadoop Cluster for Deep Learning Computation” 2015 IEEE 15th International Conference on Data Mining Workshops.
[4] Michael R. Evans, Dev Oliver,XunZhou, and Shashi Shekhar Spatial Big Data: Case Studies on Volume, Velocity, and Variety , in Big Data: Techniques and Technologies in Geoinformatics ,isbn 978-1-46-6586512, CRC Press, 2014.
[5] Almeer, M. H., Cloud hadoop map reduce for remote sensing image analysis,Journal of Emerging Trends in Computing and Information Sciences 3(4): 637-644 ,2012.
[6] K.Bakshi, Considerations for Big Data: Architecture and Approach Aerospace Conference-Big Sky, MT, 3-10 March 2012. [3] K. Michael, and K. W. Miller, Big Data: New opportunities and New Challenges, IEEE Computer, 46 (6) (2013): 22-24.
[7] The Apache Hadoop Project, http://hadoop.apache.org [5] J. Kelly, Big Data: Hadoop, Business Analytics and Beyond, Wikibon
Whitepaper,27thAugust2012, http://wikibon.org/wiki/v/Big Data: Hadoop, Business Analytics and Beyond.
[8]Y.Huetal.,“ComparisonofmulticrystallinesiliconP Vmodules’performanceunderaugmentedsolarirradiati on,”MRSProc.,vol.1493,pp.3–9, 2013.
[9] M. A. Hossain et al., “Microinverter thermal performance in the realworld: Measurements and modeling,” PloS One, vol. 10, no. 7, 2015, Art. no. e0131279.
[10]
RCoreTeam,R:ALanguageandEnvironmentforStatisti
calComputing. Vienna, Austria: R Found. Statist. Comput., 2016. [Online]. Available: https://www.R-
project.org/.
[11] J. S. Fada et al., “Democratizing an electroluminescence imaging apparatus and analytics project for widespread data acquisition in photovoltaic materials,” Rev. Sci. Instrum., vol. 87, no. 8, 2016, Art. no. 085109.
[12] M. Adhikari et al., “NoSQL databases,” in
Handbook of Research on Securing Cloud-Based Databases with Biometric Applications. Hershey, PA, USA: IGI Global, 2014, p. 109.
[13] M. ˇ S´uri et al., “SolarGIS: Solar data and online applications for PV planning and performance assessment,” in Proc. 26th Eur. Photovoltaics Sol.
Energy Conf., 2011, pp. 3930–3934.
[14]A.Woyteetal.,“Monitoringofphotovoltaicsystems: