Abstract
MUSHI, MAGRETH JUBILATE. Factoring Human Workflow in Network Reliability Engineering. (Under the direction of Rudra Dutta.)
Network administration and management tasks play an integral role in Information Technology
(IT) since IT operations are critical and utilized across a diverse set of organizations. Therefore,
for this reason the reliability of networks is of crucial importance for ensuring effective business
processes in these organizations. While involvement of humans in network administration and
management is important, network administrators and engineers induce misconfigurations in the networks because of lack of required skills to perform the tasks, lack of enough human resources,
or presence of workflows that are complex to understand and execute. As it has been noted in the
literature, consistency and high level of skill are harder to achieve or maintain in small to large
workforces. This has been a significant challenge in maintaining reliability of enterprise networks
since human errors creep in during administration and management of network protocols and
services. Despite researchers’ agreement that the human factor becomes increasingly significant as
the IT system becomes more reliable, efforts to design reliability measures have remained largely
separate from considerations of the human component of IT systems. In view of this problem our
research is aimed at enhancing the reliability and security of network infrastructures by combating human-induced misconfigurations.
In this thesis we present our research on human-induced misconfigurations, categorize them and
understand the impact of various misconfigurations on network reliability, and design technological
measures to improve network reliability despite such human tendency to fallibility. We interviewed
and surveyed networking professionals to understand configuration workflows and sub-workflows
which are prone to misconfigurations, and conducted workflow monitoring experiments with
the same group. Based on the results of our study we used network modeling tools to model the
impact of misconfigurations on network reliability, and provided a proactive SDN-based solution
© Copyright 2016 by Magreth Jubilate Mushi
Factoring Human Workflow in Network Reliability Engineering
by
Magreth Jubilate Mushi
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Doctor of Philosophy
Computer Science
Raleigh, North Carolina
2016
APPROVED BY:
Laurie Williams Emerson Murphy-Hill
Chris Mayhorn Rudra Dutta
Dedication
To my husband,Rajabu Kitindi, whose endless love and support made it easy for me to complete this work,
Biography
Magreth Mushi is a Ph.D. candidate in the department of Computer Science at North Carolina State University. She was born in a small village in the Kilimanjaro region of Tanzania. Opportunities
in the village were limited, so her parents moved her and her four siblings to a nearby town when
Magreth was around 10 years old. Her mother worked as an accountant, and she was the inspiration
for Magreth to pursue a career in science and mathematics.
Following graduation from high school, Magreth worked for an IT company in Tanzania that
specialized in network design and installation, and it was here that she developed her interest
in computer networks. Magreth pursued this topic for her undergraduate studies, and in 2005
completed a BSc in Computer Science at the University of Dar es Salaam. She remained at the institution for her postgraduate studies, and was awarded an MSc in Computer Science in 2008.
Magreth then joined the Open University of Tanzania (OUT) as a Network Engineer and later she
became Associate Director of its Information Resources department.
Her PhD research focuses on designing secure and resilient network infrastructure, an area that
was motivated by her involvement with TERNET, a high-speed computer network connecting all
higher education and research institutions in Tanzania. Magreth helped to establish TERNET in
2007, and it enables access to the Internet, sharing of educational resources, common applications and services across the network. Since its inception TERNET network has presented a number of
challenges, and Magreth’s research aims to solve some of these challenges by enhancing the security
and reliability of the network infrastructure.
Over the course of her career and school, Magreth has been actively involved with different
ini-tiatives related to encouraging and retaining women in Science, Technology, Engineering, and
Tanzania to pair professional women with young professional women for the purpose of one-on-one
mentorship. As the secretary and later vice president for IEEE Women in Engineering Eastern North
Carolina Section since 2014, she has led many initiatives including a mentoring program where she
matches women industry professionals with female students in Eastern North Carolina in order to
provide role models to students, as well as giving them access to career opportunities. She has also
been a mentor for more than three years with More Active Girls in Computing (MAGIC) to provide one-on-one mentoring to middle and high school girls in USA. She is also an active member of
Women in Computer Science(WiCS) in the department. Apart from these initiatives, she has been a
committed volunteer in other areas and students organizations such as the NCSU international
orientation team, NCSU 4 the World organization, and habitat for humanity.
Following completion of her studies, Magreth plans to return to Tanzania to continue her work
with OUT and TERNET. She believes that network infrastructures such as TERNET have the ability
Acknowledgements
I would like to express the deepest appreciation to my advisor and committee chair, Dr. Rudra Dutta, for his expertise, understanding, generous guidance and encouragement throughout my research
at NC State University. Without his guidance and persistent help this dissertation would not have
been possible. In addition I would like to thank my committee members, Dr. Emerson Murphy-Hill,
Dr. Laurie Williams, and Dr. Chris Mayhorn for their insights and constructive criticism at various
points in my research.
I am deeply grateful to my husband Rajabu Kitindi, our daughters Zakia, Fahima, and Salma,
my parents Jubilate and Agnes Mushi and siblings Anna, Naomi, Daniel, James and their families
for encouraging me to pursue my dreams and supporting me all along the way. Along with them is my close friend Joyce Kalinga who was always there to support me in every matter. Those happy
faces and roaring cheers kept me going even when the graduate career got tough. Your value to me
only grows with age.
My graduate career would not have even started without the wonderful people who trusted my
abilities and submitted recommendations to different scholarship programs. My deep gratitude
goes to Prof. Tolly Mbwette, Dr. Honoratha Mushi, Dr. Jabiri Bakari, Dr. Rudra Dutta, and Dr.
Douglas Reeves for confidently recommending me to funding agents. You made it possible for me to secure full funding for my research every year. Your generosity taught me the true meaning of
scholarly support and I will not leave it here, I am determined to pay it forward.
I would like to extend my appreciation to NCSU Lead Network Architect, William Brockelsby, for
his understanding and continuous support throughout my research at NCSU. I also appreciate my
former and current laboratory colleagues: Trisha Biswas, Can Babaoglu, Rob Udechukwu, and Harsh
when it comes to my system testing. I am so grateful to you all. I also gratefully acknowledge the
support and generosity of our interviewees, survey respondents, and their organizations without
which the first part of our research could not have been completed.
Finally, I am thankful to The Fulbright Foreign Student Program, Google Inc, and
Schlum-berger Foundation Faculty For The Future Program for providing financial and intellectual support throughout my graduate career. Without your support it would not have been possible to pursue
Table of Contents
List of Tables. . . ix
List of Figures. . . x
Chapter 1 INTRODUCTION . . . 1
Chapter 2 BACKGROUND. . . 5
2.1 Network Administration and Management . . . 5
2.1.1 Traditional Enterprise Network . . . 6
2.1.2 Software Defined Network . . . 10
2.2 Computer-based Platforms Used in Our Research . . . 13
2.2.1 Cisco Virtual Internet Routing Lab(VIRL) . . . 13
2.2.2 Network Simulator-3 (NS-3) . . . 16
2.2.3 OpenDayLight(ODL) Controller . . . 21
Chapter 3 OUR CONTRIBUTION AND RELATED WORK . . . 22
3.1 Motivation . . . 22
3.2 Our Contribution . . . 23
3.3 Related Work . . . 24
3.3.1 Human Processes and Systems Reliability . . . 24
3.3.2 Engineering Solutions . . . 25
Chapter 4 METHODOLOGY . . . 28
4.1 Network Administration and Management . . . 29
4.2 Network modeling . . . 36
4.3 Proactive Solution . . . 38
Chapter 5 HUMAN FACTOR IN ENTERPRISE NETWORK. . . 39
5.1 Discoveries from Interviews . . . 40
5.1.1 Misconfigurations and Technical Challenges Discoveries . . . 40
5.1.2 Administration and Management Best Practices Discoveries . . . 48
5.1.3 Academic Qualifications Discoveries . . . 51
5.1.4 Organization and Work Environment Discoveries . . . 53
5.1.5 On-the-job Training Discoveries . . . 56
5.1.6 Interviewees’ Tasks Discoveries . . . 57
5.2 Discoveries from Survey . . . 59
5.2.1 Misconfigurations and Technical Challenges Discoveries . . . 59
5.2.2 Administration and Management Best Practices Discoveries . . . 62
5.2.3 Academic Qualifications Discoveries . . . 62
5.2.4 Organization and Work Environment Discoveries . . . 64
5.2.5 On-the-job Training Discoveries . . . 66
5.4 Insights Regarding Categories of Misconfigurations . . . 77
5.5 Insights Regarding Causes of Misconfigurations . . . 80
5.6 Summary . . . 82
Chapter 6 NETWORK MODELLING. . . 84
6.1 Conjectures on Network Impact . . . 84
6.2 Experimental Design and Results . . . 86
6.2.1 End-to-end Delay . . . 87
6.2.2 Node Throughput . . . 90
6.2.3 Packet Delivery Ratio . . . 92
6.2.4 Summary . . . 94
Chapter 7 PROACTIVE NETWORK CONFIGURATION ANALYSIS . . . 97
7.1 Requirements . . . 98
7.2 Design . . . 100
7.2.1 SanityChecker Architecture . . . 104
7.2.2 SanityChecker Modules . . . 105
7.3 Implementation . . . 107
7.3.1 Sample Scenario 1 . . . 109
7.3.2 Sample Scenario 2 . . . 111
7.3.3 Implementation Challenges . . . 113
7.4 Tests and Evaluation . . . 114
7.4.1 Functional Testing . . . 114
7.4.2 Non-Functional Testing . . . 115
Chapter 8 CONCLUSION AND FUTURE WORK . . . .122
BIBLIOGRAPHY . . . .124
APPENDICES . . . .129
Appendix A INTERVIEW SCRIPT . . . 130
Appendix B ONLINE SURVEY . . . 134
Appendix C NETWORK ENGINEERING WORKFLOWS . . . 149
C.1 Cisco Inc. IOS . . . 149
C.2 Extreme Networks Inc. OS . . . 165
Appendix D NETWORK ENGINEERING TUTORIAL . . . 179
Appendix E VIRL LAB INSTRUCTIONS . . . 198
List of Tables
Table 5.1 Organization size versus network support staff - USA . . . 56
Table 5.2 Organization Size versus Network Support Staff - Tanzania . . . 65
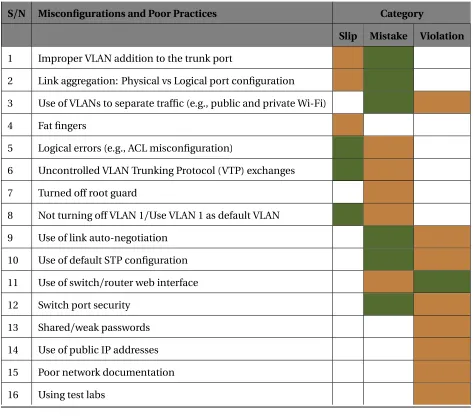
Table 5.3 Misconfigurations and poor practices by category . . . 79
Table 6.1 Misconfigurations and poor practices by Impact . . . 95
Table 7.1 Functional and Non-Functional Requirements . . . 99
List of Figures
Figure 2.1 The High-level SDN Architecture . . . 11
Figure 2.2 Screenshot of VIRL GUI Design perspective . . . 14
Figure 2.3 Screenshot of VIRL GUI Simulation perspective . . . 15
Figure 2.4 VIRL Workflow . . . 16
Figure 2.5 Basic simulation flow chart . . . 18
Figure 2.6 NetAnim: NS-3 simulation animator . . . 19
Figure 2.7 Tracemetrics: Trace analyzer for NS-3 . . . 20
Figure 4.1 General Approach. . . 29
Figure 4.2 Iterative approach followed in the first part of our research. . . 33
Figure 4.3 Topology used in the Study. . . 36
Figure 4.4 Topology used for experiments. . . 37
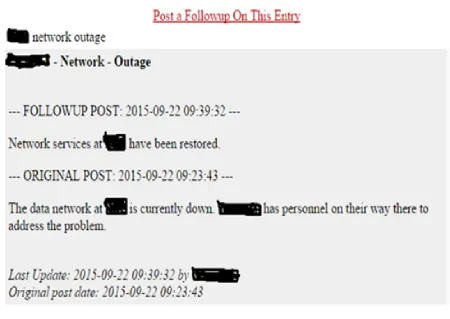
Figure 5.1 An example of poor postmortem documentation . . . 50
Figure 5.2 Interviewees’ academic qualifications . . . 52
Figure 5.3 Human classes in the operation of computer network . . . 55
Figure 5.4 Interviewees’ occasional and routine tasks . . . 58
Figure 5.5 Basic passwords configuration . . . 61
Figure 5.6 Survey respondents’ academic qualifications . . . 63
Figure 5.7 On-the-job training availability . . . 66
Figure 5.8 Example of best practices in networking. . . 69
Figure 5.9 Improper use of prompts (pre-assessment). . . 71
Figure 5.10 Inconsistence use of prompts (post-assessment). . . 72
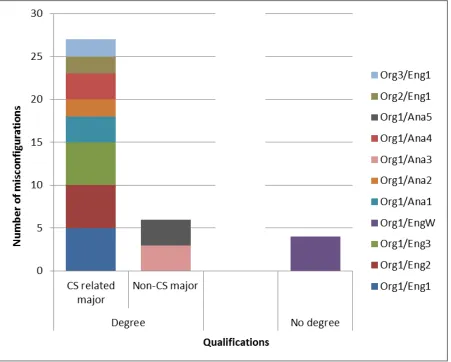
Figure 5.11 Number of common misconfigurations vs educational level by individual interviewees. . . 74
Figure 5.12 Rejected Mistyping. . . 76
Figure 6.1 Delay due to link failure. . . 88
Figure 6.2 Node 6 streams. . . 89
Figure 6.3 Node 7 streams. . . 90
Figure 6.4 Broken link per-node throughput. . . 91
Figure 6.5 Broken node per-node throughput. . . 92
Figure 6.6 Packet delivery ratio. . . 93
Figure 6.7 Network congestion-Reno TCP variant. . . 94
Figure 6.8 Misconfigurations and poor practices by Impact . . . 96
Figure 7.1 SanityChecker design approach. . . 100
Figure 7.2 SanityChecker Top Level Diagram. . . 101
Figure 7.3 SanityChecker Flowchart. . . 103
Figure 7.4 SanityChecker Modules. . . 105
Figure 7.5 Development Setup. . . 108
Figure 7.7 Example of a right port adding configuration. . . 111
Figure 7.8 Example of a configuration with negative consequence. . . 112
Figure 7.9 Example of a configuration with positive consequence. . . 113
Figure 7.10 Network usage data without SanityChecker. . . 116
Figure 7.11 Network usage data with SanityChecker. . . 117
Figure 7.12 CPU usage data without SanityChecker. . . 118
Figure 7.13 CPU usage data with SanityChecker. . . 119
Figure 7.14 Memory usage data without SanityChecker. . . 120
Chapter 1
INTRODUCTION
Computer and communication networks form part of the critical infrastructure of society and have
grown increasingly sophisticated and complex. Even the numbers of devices, such as routers, have
increased by many orders of magnitude[35]. Due to the increase in Internet usage[36], reliability and
security have become of paramount consideration for this large, complex and critically important
system. Much work in research and development has gone into ensuring that the technology for such networks is reliable and secure. In the earliest days of the Internet, such networks were administered
manually[35], and every detail was configured by human network administrators and managers,
typically experts who were closely related to the development of the protocols they administered. As
such networks have become larger and more complex, the process of administering and managing
them has also become more challenging. Due to simple considerations of scale, completely manual
configuration and administration have become increasingly impractical. The job of configuration
has progressively shifted toward the use of automated protocols[27]. For example, routing tables
were configured manually in the earliest days of Internet, but during the last few decades they have become the domain of automated protocols, such as Routing Information Protocol (RIP) and
Open Shortest Path First (OSPF). However, such protocols do not completely eliminate the need
configured by hand, routing protocols themselves must be manually configured. Thus the effect is
to trade one sort of configuration task for another, which is now more scalable for the network, but is in fact more complex for the human administrator or manager.
At the same time, according to the USA Bureau of Labor statistics, the job of network
administra-tion is now quite common and is projected to grow 8% between 2014 to 2024[52]. Large, medium
and even small organizations of widely different types business, education, governance, societal
-now own devices to connect to the Internet, and to their own internal networks. These organizations
must hire network administrators to manage these devices. Unfortunately this phenomenon has
the potential to defeat the very goal of reliability that complex protocols are designed to achieve. A
simple example will make this clear. We consider the very broadly deployed Spanning Tree Protocol
(STP) designed to remove the requirement for network administrators to precisely maintain spe-cific tree-constrained connectivity between bridges and to provide reliability through redundant
bridges that self-activate without requiring manual intervention by administrators. However, this
goal is often subverted by challenges in the human process of configuring and maintaining the
protocol. Our study showed that since STP default configuration works well in a small network,
most administrators tend to use the defaults without being aware that as the network grow and
technology advances, default configurations tend to cause problems. The 802.1D specification
recommends a maximum network diameter of 7 hops, which is derived from a series of calculations
based on various timers being tuned to their default values. Though these values can be tuned to
allow for a network larger than 7, this can introduce more complicated risks in the network and is not practically done by administrators as we observed in the interviews discussed in Chapter 5. The
case of CareGroup network outage[25]is a notable example in this regard where the network was
flooded by application data as a result of Spanning Tree Algorithm (STA) failure due to exceeding
the allowable network diameter.
With the emerging paradigm of Software Defined Networking (SDN) the job of the network
common workflows like Virtual LAN (VLAN) configuration. Such an evolution promises increased
efficiency and correctness in configuring or reconfiguring networks, and the possibility of abstracting workflows commonly prone to human errors into automated processes that will not make such
errors. On the other hand, any vulnerability inherent in a set of scripts, running automatically
on demand, can magnify the risk of such mistakes since they may execute many hundreds of
times before any reaction at a human time scale is possible. For this reason, complete workflow
automation, although yet in its infancy, is highly worthy of research attention as we strive toward
gradual staged automation (i.e., automation that will be carried out in a stepwise manner, beginning
from very basic to more advanced workflows).
The response of the research community to the human error problem in device configuration
has been largely directed at detecting and correcting misconfigurations statically, after they have been introduced into the configuration files. This is done either by checking against known good
configuration practices, as is done by Router Configuration Checker (RCC)[20], or by data mining
configuration files, as in MINERALS[33]. Though to some extent such approaches are useful, they
are in fact “treatments” rather than “preventions.”
In this thesis, we address the challenge of architecting such “prevention” strategies. Since this
area has not been explored to any significant degree in literature, we start from first principles. We
first seek to gain an understanding of the tasks network administrators must perform, and insight
into what misconfigurations happen, and why. To this end, we use various methodologies,
includ-ing structured and unstructured interviews, online surveys, and follow-up discussions. We then investigate the relative impact of various misconfigurations on network reliability, by using network
simulation tools. Finally, we advance an approach, using the Software Defined Networking paradigm,
for automatic just-in-time detection and prevention of mistakes in network administrators and
managers performing configuration tasks.
The rest of the thesis is organized as follows: In Chapter 2 we provide background of different
method-ology and results. In Chapter 3 we present our problem statement and motivation as well as review
related research in the area of network reliability and human processes and available solutions. In Chapter 4 we provide the details of the research methodology used in our study. In Chapter 5 we
present our study and report the findings as well as discuss their implications in network reliability.
In Chapter 6 we discuss the modeling process and findings, while in Chapter 7 we describe the
design, implementation, and evaluation of our proactive solution. Finally, we conclude and discuss
Chapter 2
BACKGROUND
To lay the groundwork to understand our research findings, in this chapter we present the
back-ground of network administration and management in two major networking paradigms: the
traditional networking paradigm, which has been in existence since invention of the Internet, and
Software Defined Networking paradigm, which came in existence in recent years. In both these
paradigms we will examine the architecture, protocols, and services that are the main components that differentiate the administration and management of these networking approaches. We are also
going to give a brief background for each of the computer-based platform we used to assist in our
research.
2.1
Network Administration and Management
At this point it is worth pointing out that our main focus in this thesis is in the enterprise
net-work, which accounts for the majority of practical networks. Therefore, protocols and services for
other networks such as Internet Service Provider (ISP)or Telecommunication networks will not be
discussed. Definitions of these types of networks can be found in common networking texts. In
adminis-trators and engineers in the traditional network. In Section 2.1.2 we give a brief background of SDN
and its architecture, as well as its implication for network administration and management. The administration and management tasks in SDN paradigm are not yet formalized like in the traditional
network, that is why we do not discuss them separate as we did in Section 2.1.1. From the separation
of the control and the data planes, it is expected that the administration and management tasks will
also be separated depending on the task to be performed.
2.1.1 Traditional Enterprise Network
In this section we will introduce the basic protocols and services that make up the traditional
enterprise network. The workflows and tasks performed by network support staff are mainly
admin-istration and management of these protocols and services. These are important aspects of the entire
enterprise network and if they are misconfigured the network will suffer reliability and security
issues such as: (i) Traffic will not flow through the network; (ii) Traffic will be lost or misdirected to
unintended location; (iii) Traffic will be misused to caused Denial of Service (DoS)in the network;
(iv) Nothing will appear to be broken but benign misconfigurations will be present in the network
and may cause future problems. Here we will give brief information about what the protocol/service is, and why is it important in the network. More details including their possible vulnerabilities in
the network are discussed in Appendix C.
2.1.1.1 Administration
As part of their job, network support staff issue specific commands to configure these protocols and services in the networking devices, but before configuring these protocols and services, it is
necessary to configure the foundation where they will run. This is why device base configuration is
very important. In most cases, a new device will need basic configurations which involve giving
the device a name, passwords (vty,console,enable), IP address(es) and default gateways, set up
where necessary. It also involves setting other optional work environment parameters such as
auto messages, idle timer, domain-lookup, and aliases. Thereafter, the protocols and services can be configured. Commands associated with base configuration as well as configuration for these
protocols and services are given in Appendix D.
Virtual Local Area Networks (VLANs):This is the logical grouping of network end devices. Vlan
are considered a level of security within the organization where traffic is separated depending on
group factors like location, work functions, data sensitivity, etc.
Spanning Tree Protocol:This is a network protocol that ensures a loop-free network topology
in a network with redundant links. It was originally standardized as IEEE 802.1D, and subsequent
versions were published later as IEEE 802.1w - Rapid Spanning Tree Protocol (RSTP), IEEE 802.1s
- Multiple Spanning Tree Protocol (MSTP), and various vendor specific versions such as Cisco’s Per-Vlan STP (PVSTP) and PVSTP+.
WAN connection protocols: These are protocols that allow communication outside the
en-terprise network either to the Internet or to another enen-terprise network. Though there are many
available options for protocols to run over a WAN connection, the notable ones are Point-to-point
(PPP), High-Level Data Link Control(HDLC) and Frame Relay.
Internet Protocol Virtual Private Network:IP VPN is a connection allowing sites to communicate
using their private IP addresses over a secure tunnel through the Internet. The main protocol used is
IPsec, which is a suite of other protocols used for negotiation (Authentication Header(AH),
Encapsu-lating Security Payload(ESP)), encryption (Data Encryption Standard (3DES), Advanced Encryption Standard (AES)), authentication (Message Digest algorithm 5 (MD5), Secure Hash Algorithm 1
(SHA-1)), and protection (Diffie-Hellman (DH), DH2) over the VPN tunnel.
Multiprotocol Label Switching VPN:MPLS VPN is by far the more commonly deployed
tech-nology today for WAN connection. “MPLS” and “VPN” are two different techtech-nology types. MPLS
is a standard-based technology used to speed up the delivery of network packets over multiple
A VPN uses shared public telecom infrastructure such as the Internet to provide secure access to
remote offices and users in a cheaper way than an owned or leased line. With those definitions understood, an MPLS VPN is a VPN that is built on top of an MPLS network (usually from a service
provider) to deliver connectivity between enterprise office locations.
Network Address Translation (NAT):NAT is a very popular and effective means of conserving
public IP addresses and enhancing security where devices inside the network use private IP addresses
for internal communication and share one or more public IP address(es) to communicate with
other devices in the Internet. The configuration of NAT routers requires a good understanding of
Access Control List (ACL) configuration.
Authentication, Authorization, and Accounting (AAA):The AAA framework allows verification
of the identity of, grant access to, and track the actions of users managing network devices. These devices support Remote Access Dial-In User Service (RADIUS) or Terminal Access Controller Access
Control device Plus (TACACS+) protocols. Based on the user ID and password combination provided
by the user, the device performs local authentication or authorization using the local database or
remote authentication or authorization using one or more AAA servers. A pre-shared secret key
provides security for communication between the device and AAA servers[11].
Access Control Lists (ACLs): ACLs have several uses but the most common uses are access
control, NAT, Quality of Service (QoS), and route filtering. Access lists are used to implement firewall
functions in the router by restricting/permitting access to network resources and are configured
one per interface per direction (in or out).
Routing Protocols: There are two categories of routing protocols:Interior Gateway Routing
Protocols (IGRP)that enable routing within Autonomous Systems (ASes) and Exterior Gateway
Routing Protocols (EGRP) such as BGP that enable routing across ASes. For the purpose of our
research we are more concerned with IGRP such as OSPF, RIP, and Enhanced Interior Gateway
Routing Protocol (EIGRP).
addresses to the devices in the network. The IP addresses are leased for a certain period of time
defined by the network administrator. In configuring DHCP, administrators are supposed to define an address (or a pool of addresses) to be used and also configure the DHCP servers and clients to
allow dynamic allocation of addresses.
Wireless Fidelity (WiFi):WiFi refers to the IEEE standard 802.11x which allows computers,
smart-phones, or other devices to connect to the Internet or communicate with one another “wirelessly”
within a particular area. Most wireless controllers and APs have Graphical User Interface (GUI) that
administrators use to select different parameters which in-turn allow for auto-discovery of wireless
devices.
2.1.1.2 Management
Network management involves activities, methods, procedures, and tools that pertain to
manag-ing the operation, administration, maintenance, and provisionmanag-ing of networked systems. Data
for network management is collected through several mechanisms including agents installed on
infrastructure, synthetic monitoring that simulates transactions, logs of activity, sniffers and real
user monitoring. Below is the brief description of the most common protocols, services, and tools that are used in network management.
Simple Network Management Protocol (SNMP):This protocol was formally defined in RFC
1157 as SNMPV1, and then revised to SNMPV2 and SNMPV3. One of its most common uses is
remote management of networked devices. The SNMP-managed network typically consists of three
components; managed devices, agents, and one or more management systems (with manager,
Management Info Base, and management protocol).
Network management tools, systems, and applications:These are the tools used by network
administrators to monitor and manage networks. They can perform general-purpose tasks, such
category also includes diagnosis and network statistics gathering tools such as protocol analyzers
used to analyze data packets in all layers of OSI model.
Web-based network management: This means the use of web technology to access network
devices information. The web environment makes it easier to access information remotely in
network management systems. Tools like Multi Router Traffic Grapher (MRTG) is based on web
technology and used as a performance tool to gather network statistics. It uses SNMP to send
requests with two object identifiers (OIDs) to a managed device. More about MRTG and other like
tools can be found at http://www.mrtg.com/.
2.1.2 Software Defined Network
In the traditional networks discussed above, networking devices have both control and data plane
coupled within the same device. The control plane provides information used to build a forwarding
table. The data plane consults the forwarding table to make decision on where to send frames or
packets entering the device. In contrast to this paradigm SDN is a new way of deploying network
infrastructure which separates the control plane and the data plane within the network, allowing
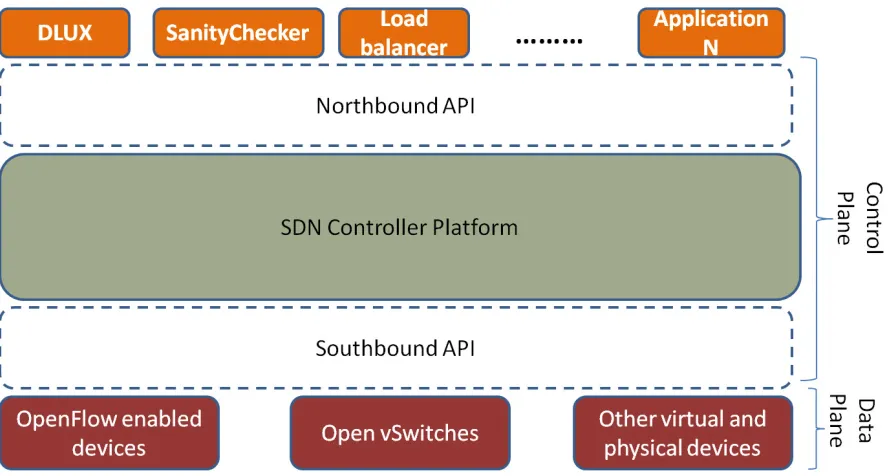
the intelligence and state of the network to be managed centrally while abstracting the complexity of the underlying physical network. The high-level SDN architecture in Figure 2.1 depicts its major
Figure 2.1The High-level SDN Architecture
2.1.2.1 The control plane
This is where most of the network intelligence is performed. The controllers are used to control how
the network performs, such as computing the routes and installing the routes into switch forwarding tables. The control plane consists of three main parts:
Controller:This is the strategic control point in the SDN network relaying information to the
switches/routers ’below’ (via southbound APIs) and the applications and business logic ’above’
(via northbound APIs). An SDN Controller platform typically contains a collection of “pluggable”
modules that can perform different network tasks. Some of the basic tasks includes inventorying
what devices are within the network and the capabilities of each, gathering network statistics, etc.
At present moment two of the most well-known protocols used by SDN controllers to
communi-cate with the switches/routers is OpenFlow and OVSDB. Others protocols that could be used by a
Southbound API:This API provide a means for the controllers to communicates and control the
SDN data plane. The most known and standardized protocol in the Southbound API is OpenFlow which communicate with the switch over a secure channel to update the flow table entries in the
switch. The switch is then responsible for packet lookup and performs a defined action for match
in a flow table entry; if there is no match the packet is sent to the controller.
Northbound API:This is the interface that allows application and orchestration systems to
program the network at higher level of abstraction. This API enables network programmers to
write more complex applications such as firewalls and load balancers that communicate with the
controller to perform these sophisticated functions.
2.1.2.2 The data plane
The data plane of the network is basically the forwarding devices that perform an action (or series
of actions) on packets based on the match of information available in the forwarding table of the
device. In SDN the content of the table is computed and installed by the controller, then devices in
the data plane use that information to forward user traffic. If information for traffic is not available
in the table the device sends the traffic to the controller. The data plane can also be programmable in order to allow flexibility and extensibility either by using software data plane (e.g., Click), or by
programming the hardware.
2.1.2.3 SDN Implication for Network Administration and Management
In the current context from our research point of view it is important to note that, while the implica-tions of the ODL approach for the data plane is obvious, ODL (or a similar unifying approach) has
significant implications for network management and administration as well. First of all, the locale
of the administration job moves from the network device (datapath) to the controller(s), and instead
of being a CLI job it is now a scripting or programming job. Secondly, many administrative tasks will
to telling the switch where to find the controller. It is easily conceivable that this will in fact, in time,
become an automated discovery protocol and will be factory-installed. The network management job in turn will have a single logical point of application at the controller or federated controllers.
New management tasks involved with controller federation and source-code management for
con-troller applications will come into being. It is in such a world, which we believe will emerge in
the near future, that we will be able to design automated workflow or workflow fragments with
confidence that they will be of general usefulness and not restricted to highly specific combinations
of equipment. This provides the timely impetus to our research vision.
2.2
Computer-based Platforms Used in Our Research
In our approach to study and design mitigation solution for misconfiguration problem we used
three computational environments: Cisco Virtual Internet Routing Lab(VIRL), Network
Simulator-3, and Opendaylight controller (ODL). VIRL was used for understanding network administration
workflows and which points in the workflows suffer misconfiguration problem. NS-3 was used to
model the enterprise network and measure the impact of misconfigurations to network reliability.
ODL was used as a SDN platform to implement our proactive solution to misconfiguration. In this section we will go through a brief background for each in order to provide context to understand
the methodology presented in Chapter 4 and the results presented in Chapter 5 , 6, and 7.
2.2.1 Cisco Virtual Internet Routing Lab(VIRL)
We used VIRL to run workflow monitoring experiments with network administrators and engineers in order to gain in-depth understanding of workflows that are prone to misconfigurations. VIRL is a
software platform for Cisco Modeling Labs and its primary purpose is to test network designs prior
to deployment in a production environment. VIRL is designed to provide students and network
XR, and NX-OS in an easy-to-use GUI as seen in the screenshot in Figure 2.2 below. The OS are
acronyms for specific Cisco software tradename[12].
Figure 2.2Screenshot of VIRL GUI Design perspective
VIRL platform uses VM Maestro[14]as the interface to interact with VIRL server. VM Maestro
is the client-side application that is used to build topologies, generate configurations and
visual-izations, and manage simulations that execute on the VIRL host or virtual machine. There are two
main VIRL perspectives (Design and Simulation). In a “Design” perspective, users build network
op-erating system. In this environment users can also choose to use AutoNetKit (used to auto-generate
configurations for the nodes in the topology). In the “Simulation” perspective the user executes the design. From this perspective users can also SSH/Telnet to the device to enter configurations via
Command Line Interface (CLI). For the purpose of our study we used the CLI method.
Figure 2.3Screenshot of VIRL GUI Simulation perspective
Figure 2.4 below shows VIRL workflow when the user runs a simulation. First the configurations
entered via VM Maestro interface are converted between different OS-types and platforms. Topology
represented in XML. The Service Topology Director orchestrates the creation of VIRL virtual nodes
and inter-node links based on the XML-based topology definition and configurations based on VM Maestro.
VM Maestro
Service Topology Director (Create nodes & networks Topology graph, view, and
configurations
VMs/Switches
Figure 2.4VIRL Workflow
2.2.2 Network Simulator-3 (NS-3)
We used NS-3 in a controlled environment to model the impact of mis-configurations on network
graphical representation of the simulated data.
1. NS-3is a discrete-event network simulator for Internet systems. It enables development of simulation models that are sufficiently realistic to be interconnected with the real network.
NS-3 also supports a real-time scheduler that facilitates a number of “simulation - in-the-loop”
use cases as well as real applications that can be used to test the models. NS-3 simulator was
used to build the topology and run simulations for different network configuration scenarios. Figure 2.5 below shows a basic flow of activities during the simulation. We wrote a C++
function that schedules events to occur at specific simulation times or after the previous event.
The simulation time moves in discrete jumps from event to event. A simulation scheduler in
NS-3 orders the events execution which is then run by Simulation::Run() and stops at specific
time or when the events end. At the end of simulation, NS-3 produces two files. The xml file
with events and schedule to be used as input to NetAnim and a trace file to be used as input
Simulation time Start End Configuration time Get&Execute event Are there more events ? Is simulati on time over? No No Yes Yes Create nodes Create channels Connect nodes Configure nodes (IS, IPV4 Install apps
Tear down time Un-configure nodes Disconnect nodes Release resources
Figure 2.5Basic simulation flow chart
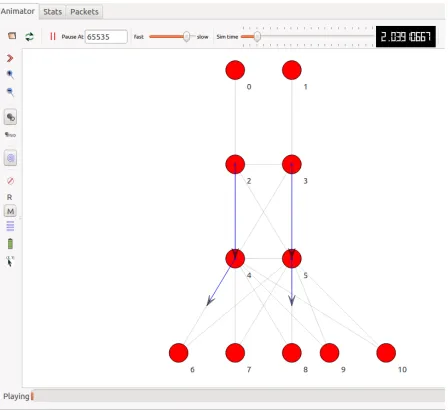
2. NetAnimwas used for animating NS-3 simulation. It is a stand-alone program which uses the custom trace files generated by the animation interface to graphically display the simulation.
We did this for visual purposes to help us see the actual traffic flow through the links as seen
in Figure 2.6 below. NetAnim takes as input the trace data in xml file generated during NS-3
Figure 2.6NetAnim: NS-3 simulation animator
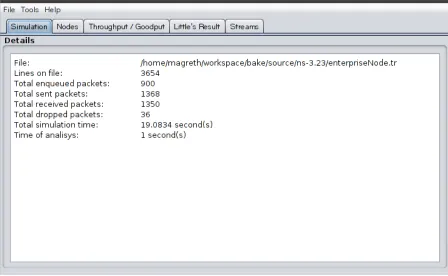
3. Tracemetricswas used to perform analysis of the trace file produced by NS-3 simulations and calculate useful metrics for research and performance measurement (e.g., packet drops,
throughput, etc.). As seen in Figure 2.7 below, the simulation tab shows the general details
trace file, packet counters, simulation time and analysis time. The nodes tab has a list of
nodes in the simulation that includes node number in the simulation, packets sent and received, throughput, goodput, etc. The Throughput/Goodput tab makes it easy to compare
the throughput and goodput between the nodes in the simulation. The Little’s results table
analyzes three main things: the Little’s validation, the average size of the queue (E[N]) and
the average time spent by each packet in the node (E[W]). This information is very useful to
detect points of overload in the network. The Lambda column in this tab shows the average
number of packets sent by the node each second. The Streams tab presents the results related
with data streams like TCP or UDP.
2.2.3 OpenDayLight(ODL) Controller
Apart from all other available controller platforms we will specifically give a brief information about
ODL in this section because this is the platform we used in the implementation of our proactive
solution to be discussed in Chapter 7.
In order to realize SDN goals the OpenDayLight consortium[42]introduced the ODL controller.
This is an attempt to standardize the controller application language (or controller programming
API) for a broad set of SDNs, all based on the separation of policy and mechanism (i.e., the
controller-based approach). So far the ODL controller has evolved through four major releases (i.e., Neutron,
Helium, Lithium, and Beryllium). Though the earlier versions of ODL did not follow the model
driven approach, the controller has adapted this approach starting with the Helium release. The Model Driven Service Abstraction Layer (MD-SAL) provides the abstractions to support multiple
southbound protocols via plugins. The application oriented extensible northbound architecture
provides a set of Northbound APIs via RESTful web services (for loosely coupled applications) and
Open Service Gateway Initiative (OSGi) services (for co-located applications). The OSGi framework
upon which the Controller platform is built on is responsible for the modular and extensible nature
of the controller and also provides the versioning and life-cycle management for OSGi modules and
Chapter 3
OUR CONTRIBUTION AND RELATED
WORK
While involvement of humans in network administration and management is important, network administrators and engineers induce misconfigurations in the networks because of lack of required
skills to perform the tasks, lack of enough human resources, or presence of workflows that are
complex to understand and execute. As it has been noted in the literature review in Section 3.3,
consistency and high level of skill is harder to achieve or maintain in small to large workforces. This
has been a significant challenge in maintaining reliability of enterprise networks since human errors
creep in during administration and management of network protocols and services.
3.1
Motivation
Since the 1980’s, there have been several research efforts geared toward reduction and elimination
of network misconfigurations. Earlier research and tools[20] [54]were developed for traditional
networks. These tools are based on a reactive engineering approach of post-scanning configuration
occur and then at a later stage they reactively scan the network configuration files to find the errors,
which must then be corrected by an administrator. According to current studies[30] [2], these reactive approaches have not proven successful in combating misconfigurations.
In view of the above challenges and considering the scientific approach discussed in the newly
emerging area of Science of Security (SoS) [29], we were motivated to follow this approach to
study the problem and design a proactive solution that leverages the power and promises of SDN
infrastructure to intercept and check switch configurations submitted by a network administrator
through the controller.
3.2
Our Contribution
As indicated in several studies mentioned in Section 3.3 below, misconfigurations in network devices
have been a major source of vulnerabilities in the network. Currently available solutions for this
problem are based on post scanning the configuration files to determine misconfigurations which are
then fixed manually by the administrator. Though this is the current practice, it is a treatment rather
than prevention at best. It seems more logical to prevent the misconfigurations from happening
(or minimize the chance of them happening) and therefore enhance reliability and security while saving the time it takes to develop post scanning solutions and manually correcting the mistakes. We
believe it is crucial to follow a systematic approach in order to completely understand the problem
space and propose a sustainable solution. Therefore, our contribution presented in this section is
geared towards this approach.
Our contribution in this field of research is to answer the following overarching questions:
1. What are the typical workflows in network administration and management?
2. What are the common misconfigurations and technical challenges in network administration
3. What is the impact of misconfigurations and technical challenges on network reliability?
4. Can a proactive automated solution be beneficial in combating misconfigurations?
In understanding the typical workflows in network administration and management we did a
comprehensive literature survey as well as taking standard professional examinations which gave us
hands on experience in working with network devices. This gave us the expertise necessary to
pro-ceed with the following stages; the most relevant part was presented as background in Chapter 2. In
understanding the common misconfigurations and technical challenges in network administration
and management we conducted unstructured and semi-structured interviews, an online survey,
and workflow monitoring experiments with network architects, engineers, and administrators. The
outcome is presented in Chapter 5. We then modeled the enterprise network in order to understand the impact of misconfigurations in the overall reliability and security of networked systems and
the results of our modeling are presented in Chapter 6. Finally in Chapter 7 we present the design,
implementation, and testing of the proactive solution that checks incoming configurations for the
possibility of human errors.
3.3
Related Work
3.3.1 Human Processes and Systems Reliability
Reason[45]once said, “Human fallibility, like gravity, weather and terrain is just another foreseeable
hazard; therefore, we cannot change the human condition, but we can change the conditions under
which people work.” Despite this fact, numerous studies[40] [22] [34] [9]shows it is undeniable that
human input plays a critical role in any computing system. However, the involvement of humans in
complex computing introduces serious reliability and security issues[22] [34] [9].
networking field is no exception. In recent and past years we have seen several human-related major
network failures. In 2004, Border Gateway Protocol (BGP) misconfiguration in network AS9121 (TTnet - the largest Internet Service Provider (ISP) in Turkey) resulted in the propagation of 100K+
routes, leading to misdirected/lost traffic for tens of thousands of networks and network downtime
of more than 10 hours[3]. The same problem occurred with AS7007[39]and AS3561[19]incidents.
Due to events like these, several researchers have studied the contribution of human processes to
network reliability and security. Some of these studies (discussed below) have shown that
human-introduced network device misconfigurations are common and can have significant adverse impacts
on the operations of a network. Misconfigurations can compromise the reliability and security of
an entire network by causing global disruption to Internet connectivity and availability of resources,
as shown by Wool’s study of firewall configuration errors[53]. Wool found that the complexity of rule sets that are too difficult for administrators to manage effectively was one of the major
contributing factors to misconfigurations. Feamster et al.[20]and Mahajan et al.[38], on the other
hand, studied the misconfiguration of the routers that speak BGP and found that the major causes
of misconfigurations are inadvertent errors by network administrators, poor understanding of
configuration semantics, and sometimes router initialization bugs. Mahajan proposed to reduce
administrative mistakes by making self-configured systems with minimal maintenance and minimal
human interaction.
3.3.2 Engineering Solutions
While the researchers above studied the contribution of human processes in network security and
reliability, other researchers have proposed solutions to the problem and focused on tools to further
automate network administration and management. Buchmann[7]described general concepts of
network management and provided a prototype implementation of network management system software to facilitate easier administration of large, heterogeneous networks. Colwill et al.[15]
joint-vendor approaches to ensure consistency across different providers. However, such approaches are
necessarily based on very general concepts. Some of the tools developed involve RCC[20]for static analysis of configuration files to find faults in BGP configurations. Other tools like FIREMAN[54]and
AT&T configuration checker[21]also were recommended. Due to limitations of these static tools,
other researchers developed MINERALS[33], a tool based on data mining techniques. MINERALS
applies association rules mining to the configuration files of routers across an administrative domain
to discover local, network-specific policies. Deviations from these local policies are considered
potential misconfigurations. Other tools, such as EDGE[8], follow the same approach to help
minimize misconfigurations in the networking devices.
The main limitation in these previous approaches is that researchers did not employ systematic
scientific studies (e.g., studying the humans and environment behind minsconfigurations) to under-stand the root causes of the underlying misconfiguration problem. They also looked at the problem
beyond the smaller enterprise networks, ignoring the fact that human involvement starts at this
level. These enterprise networks are the foundation for the larger Internet. The proposed solutions
and tools are insufficient because they are more “treatment” than “prevention.” For example the
proposed static analysis tools are based on predefined best common practice rules known and
populated beforehand; deviation from these rules is considered misconfiguration. Logically, this
approach is ineffective since what is a considered misconfiguration in one network is not necessarily
a misconfiguration in a different network. Though the tools based on data mining techniques help
to solve this problem, they fall short of proactive means of addressing the misconfiguration problem, and instead they reactively scan the network after misconfigurations have occurred.
With the emergence and promises of SDN, some tools are being developed to enhance the
performance of the infrastructure. For the misconfiguration problem, Khurshid[30]developed
VeriFlow, an SDN based tool to verify incoming OpenFlow rules from the controller for possible
misconfigurations. FlowChecker[2]is another recent SDN plugin that verifies the incoming
look for misconfigurations introduced in the system by network administrators. To the best of our
knowledge there is no SDN-based tool for verifying human administrators’ configurations as they are submitted to the devices through the controller. Therefore, a proactive and effective approach
to deal with human errors is necessary to improve network security and reliability.
In our literature search we also found recent research work that are attempting to solve the
misconfiguration problem in network infrastructure but they fall short of the human aspect which
is very crucial in maintaining a reliable IT infrastructure. Recent work such as[6],[1],[26], and[49]
provide a few examples of the efforts to design network infrastructure reliability measures that
remain largely separate from considerations of the human component. Other research work have
examined the role of human and organizational factors in IT in general from a range of disciplinary
perspectives as well, for example, Applied Ergonomics[31], and Computers and Security[32]. While these research tracks have examined various facets of human and organizational factors in CS, none
has focused upon enterprise networks, which are the foundation for the larger Internet, and the
Chapter 4
METHODOLOGY
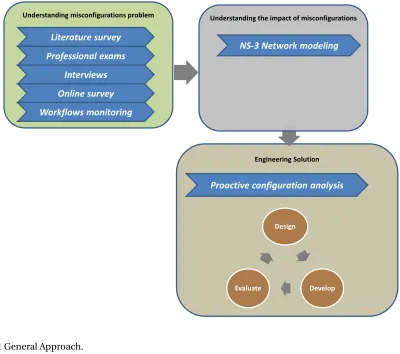
Figure 4.1 shows the general approach followed in our research. This approach was motivated by
the concepts advocated by the newly emerging area of Science of Security (SoS)[29]. We began by
studying the problem at hand and later proposed a solution based on the findings of our study. In
studying the problem we used several research tools: literature search, professional board
examina-tions, interviews, online survey, and experiments. The results of the first two tools are reported in Chapter 2 while the results of the rest of the tools are reported in Chapter 5. In order to understand
the impact of the problem in our field of study we modeled an enterprise network and subjected it to
the human errors we found in our study and reported the results in Chapter 6. Finally we used SDN
platform to design and implement the proactive solution to the human errors problem in enterprise
Engineering Solution Understanding misconfigurations problem
Design
Develop Evaluate
Understanding the impact of misconfigurations
Literature survey
Professional exams
Interviews
Online survey
Workflows monitoring
NS-3 Network modeling
Proactive configuration analysis
Figure 4.1General Approach.
4.1
Network Administration and Management
Because the impact of human processes in enterprise network administration and management is
not well studied, there are few pre-existing theories to tie to; therefore, it was important to develop
and follow a systematic approach, including some aspects of the Grounded Theory (GT) approach,
to conduct our research. The Grounded Theory approach means an approach to inductively
de-velop a theory by gathering a corpus of data such that the resulting theory fits that one dataset
We started understanding the problem by first understanding the network administration and
management job and its responsibilities. For such understanding we performed a detailed literature search followed by hands-on experience in practical networking exams (i.e., Cisco Certified Network
Associate). After understanding the job, we proceeded with interviews and an online survey study
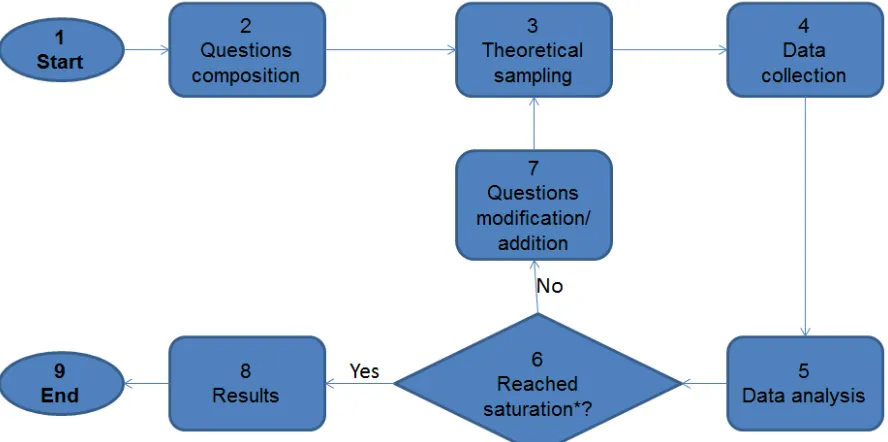
using an iterative approach depicted in Figure 4.2. Our study involved 4 phases: Phase I started at
stage 2 to 7, while subsequent phases began at stage 3 to 7. At the beginning of Phase I we composed
the questions that will guide our interview process. We selected our sample using a purposive
non-probability sampling method[37], then conducted the interviews and collected the data, which
we then analyzed. During data analysis we found out that there are some gaps in the data and we
needed to ask for more details to fill in the gaps (i.e., we had not reached saturation yet). Therefore,
we added additional questions to our question set and started Phase II of the research at stage 3. We initiated our study with a combination of unstructured and semi-structured expert interviews
to collect detailed information on network administration and management workflows, and then
we used this information for close examination of the configuration files of networking devices.
In the first two phases of our research, we gathered data from interviews with network architects,
engineers, and administrators. The data we gathered helped us develop an online survey that we
used to verify/falsify the conjectures we derived from the interviews.
In Phase I, we interviewed high-level network architects from three organizations, including two
academic institutions and a service provider. In this phase we aimed to understand the practical
aspects of network administration and management. Since each organization has only one network architect, our sample consisted of only three subjects. In Phase II, we conducted semi-structured
interviews with network engineers and administrators from three organizations (two organizations
were the same as in Phase I). In this phase we used the interview script in Appendix A to guide
the process and interviewed six network engineers and five network administrators across the
three organizations. This phase was very useful for understanding the details and challenges of
that we needed to obtain from a large variety of organizations in Phase III, which took the form of a
web-based survey in Appendix B. The final phase, Phase IV, involved follow-up discussions with our interviewees and survey respondents to mine additional details about some of the information they
had provided.
The interview script used for Phase II’s semi-structured interview and the online survey used
in Phase III were divided into four broad categories of information as indicated below. In all these
categories, to protect privacy, no identifying information was asked, and we made no attempt
to identify the participating organization or individuals by other means. The percentage within
brackets indicates the amount of questions included in each category.
• Demographic (5%): This category contained questions related to an individual network engineer/administrator’s educational background and experience in computer technology
related fields. It is important to understand these aspects and their impact on the overall
performance of an individual in the workplace.
• Organization (5%): This category contained questions related to the organization size in terms of number of employees supported by the network infrastructure, organization, type,
etc. The nature of the organization is another aspect that we suspected would have impact on
the overall performance of the administrator, which translates to reliability and security (or
insecurity) of the organization network infrastructure.
• Work environment (10%): This category was mainly concerned with the environment around the network engineer/administrator, such as the size of the network infrastructure in terms
of number of sites and network devices, and the size of the network infrastructure support
group. The end hosts were not included in this study because organizations have different
support groups (commonly referred to as a helpdesk) that provide support for end hosts. We
also asked about the tasks performed by engineers/administrators, on-the-job training, and
• Technical (80%): This final category formed the major part of the interview script. It con-tained questions related to network administration and management, ranging from initial configuration of the device to security configuration and day-to-day maintenance.
Due to the nature and sensitivity of our study, we followed a non-probability sampling method
where we chose the individuals in the sample based on formal and informal relationships existing
between our organization/ourselves and others. Many organizations perceive such studies as invasive to privacy, and therefore respondents are often sensitive about providing data, both on
their own behalf and on behalf of their organizations. Since we can collect data only from willing
participants, our respondent pool is necessarily self-selected. Participation was more likely to come
from organizations with a priori relationships with the researcher’s organization or researchers
themselves than from randomly chosen organizations. Despite this difficulty, we selected our
sample from both academic and industry organizations. We used both qualitative and quantitative
approaches to analyze our data depending on the nature of the question asked. For transcribing
and coding the interview we used Qualyzer[51].
The online survey was administered to 33 respondents in Tanzania. As with interviews, we chose organizations based on existing relationships, and because of limited resources we could not survey
more than one country. Phase I-II was done in the US only, Phase III in Tanzania only, and Phase IV in
both. Not all the results of one country can be generalized to another, but some feedback suggested
similar trends in both countries; for example, common misconfigurations appear to happen in both
countries. Of 33 respondents surveyed, 29 fully completed the survey while 4 partially completed
the survey. The respondents were network administrators from education and research institutions
who had gathered for a week training on “Campus Network Design and Management.” The survey
was developed and administered through the Qualtrics Survey Software[43]. The survey had the
Figure 4.2Iterative approach followed in the first part of our research.
After the interviews and online survey, we conducted workflow monitoring experiments using
Cisco VIRL (its background is given in Chapter 2. We designed the network engineering tutorial
and tasks in Appendix D and Appendix E respectively. The tasks document consisted of five major
tasks and between 3 to 10 sub-tasks for each task. The tutorial consisted of the same tasks, and in
addition, it included explanations and a sequence of commands to perform the tasks. We gave the
list of commands to participants and a reference guide because in real life, engineers/administrators
can browse the Internet to get the correct command if they know what they want and how to use
it. We assigned participants to two main groups (pre-assessment and post-assessment groups)
depending on when they participated and what working documents were given to them. We recruited participants from CSC 573 Fall 2015 class and from the industry engineers we interviewed
short questionnaire consisting of the following questions:
1. What is your project group (the groups used for in-class project)?
2. Have you worked with/configured network devices before?
3. For how long have you worked with network devices?
Question 1 was asked because before our research activity, the participants were divided into
eight project-groups for the purpose of their class projects; therefore, we decided to use the same
groups to conduct our research. We also wanted to understand the level of expertise of the
project-group members since tasks were going to be accomplished in project-project-groups. Throughout this
report we will use “project-group” to refer to these groups so they are not confused with our earlier two major groups (pre-assessment and post-assessment groups). Each project-group consisted
of four members. The second and third questions were asked because we wanted to understand
participant’s years of experience since many of them were working before joining college. From this
question we learned that the participants had varying years of experience in network administration,
and based on their feedback to these questions we grouped their experience in three categories (i.e.,
less than 1 year, 1-5 years, more than 5 years).
Samples for each of the two main groups were chosen randomly based on availability of
partici-pants and working document used. The pre-assessment group consisted of three project-groups
with a total of nine participants and was given network configuration tasks to accomplish in VIRL without any prior training. The post-assessment group consisted of eight project-groups with a
total of thirty participants and was given training based on the tutorial before they were given the
network configuration tasks. two members of the pre-assessment group were also involved in the
post-assessment group for post-assessment. In order to measure the impact of workload, the five
tasks were allocated 3 hours time to complete. 30 minutes was intended for each task, and the extra
time to complete the tasks was 2.5 hours. For the first group, participants were given access to the
VIRL platform in a shared server, a topology file which contains virtual networking devices with no configuration (Figure 4.3 below), and set of tasks to be accomplished on the given topology in order
to make the network functional. These tasks were drawn from the tutorial which includes necessary
tasks required to configure an enterprise network. For the second group, we first conducted brief
training to the participants using the tutorial. We aimed to teach different commands required
to accomplish network configuration tasks, the purpose of the commands, and best practices in
configuring enterprise networks. Participants were then given access to the VIRL platform in a
shared server, a topology file which contains virtual networking devices that do not contain any
configuration, and the same set of tasks to be accomplished on the given topology in order to make
the network functional.
Upon completion of each configuration tasks, students participants submitted the screen
cap-ture file that had recorded all the screen activities and the topology file containing all the
configu-rations. For industry engineers and administrators we set up a VCL image with VM Maestro and
recording software installed. These engineers/administrators made reservations for the image and
used it to perform the tasks while recording their desktop. As it was with the student, each task
was allocated 30 minutes. At the end of each activity they submitted their recording by saving it
anonymously in a public folder. We collected data from the captures by observing the different
Figure 4.3Topology used in the Study.
4.2
Network modeling
With NS-3 simulation, we designed and implemented the test bed as seen in Figure 4.4 below. The
design was influenced by a traditional hierarchical network design where we have ISP, gateway, core,
and distribution nodes with redundancy to help provide network reliability. We then conducted basic
controlled simulations to test the functionality of the test bed, as well as simulate misconfiguration
scenarios that affect network reliability. The results of these simulations are detailed in Chapter 6.
We installed Internet stack in each node and gave them IP addresses in order to be able to
communicate with each other node in the network. For testing purposes, we installed the client
I0 and I1). In order to simulate normal network traffic with redundancy and load balancing, D0 and
D1 were sending packets to I0 while D2,D3, and D4 were sending packets to I1 for a pre-defined amount of time.
4.3
Proactive Solution
The methodology followed to design and implement our proactive solution detailed in Chapter 7
is SDN based. The background of SDN and ODL controller is given in Chapter 2. We chose this
approach due to its ability to scale well in an enterprise network, easy automation process, and wide acceptance in our research field.
After we implemented our design we tested it against the functional and non-functional
require-ments provided in Section 7.1. In order to provide test environment for SanityChecker we created
a VCL Linux image with ODL controller and SanityChecker installed. The image also included
basic instructions and sample test cases to start performing SanityChecker tests. Test participants
reserved the image, performed the tests, and filled in the test cases template in Appendix F, which
was then returned to us. In testing the system, participants performed both positive (using valid
input) and negative (using invalid input) functional tests. We recruited 20 participants for functional