Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2806
Secure and Efficient method for Hidden Objects Crawling in
Web Search Interface by KNN Queries
O.Siva Ramakrishna , V.S.Ramakrishna,
P G Student, Dept. Of CSE.,B.V.C Engineering College ,Odalarevu , Amalapuram,
Associate Professor Of CSE, B.V.C Engineering College ,Odalarevu , Amalapuram,
Abstract: Through Many sites we are discovering Location Based Services (LBS) that give a best k Nearest Neighbors objects (e.g., most limited eateries) for a given query location. This paper manages the data about finding the issue of slithering (searching) all articles proficiently from a LBS site, it gives the public kNN web search interface. Precisely, we create 2D and higher-dimensional spaces by utilizing slithering algorithm, separately, and exhibit that our algorithms overhead by a component of the quantity of measurements and the quantity of crept objects, regardless of the fundamental circulations of the articles. We likewise grow the creeping algorithms to control the situations where clear reinforcement data about the fundamental information dissemination, e.g., the general public thickness of a region which is frequently emphatically related with the thickness of LBS objects, is accessible.
Keywords: Information and Communications Technology, Location based Searching technique, LBS server, kNN queries, crawling objects.
1. INTRODUCTION
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2807 with wage levels nitty gritty in Census, et
cetera. Our objective in this paper is to engage the crawling of a LBS database by issuing couple of request through its transparently open kNN web look for interface, with the goal that a brief span later a data inspector can simply view the crawled data as a separated database and play out whatever examination tasks liked.
Here "crawling" is widely described, i.e., it can insinuate the extraction of all things from the database, or simply those articles that satisfy certain assurance conditions, because of the fact that such conditions can be "experienced" to the kNN interface. For example, if the target here is to crawl Google Maps, at that point the objective may be to crawl each Vietnamese restaurant in Washington, DC. One can see that this condition can be successfully experienced to Google Maps by keeping request territories to be from Washington, DC, and deciding "Vietnamese diners" as the chase keyword1. Note that the key particular test for crawling through a kNN interface is to confine the amount of inquiries issued to the LBS advantage. The essential is realized by limitations constrained by most LBS organizations on the amount of inquiries allowed from an IP address or a customer account (if there ought to be an event of an API organization, for instance, Google Maps) for a given day and age (e.g., one day). For example, Twitter compels the request rate at 180 inquiries for each 15 minute. Clearly, no computation can accomplish the endeavor without issuing in any occasion n=k questions, where n is yield appraise (i.e., the amount of
crawled things), because every request returns at most k of the n objects. Everything considered, we will without a doubt have a yield sensitive figuring, which regardless should have an inquiry cost as close n=k as could be permitted.
This is an unavoidable ancient rarity of the space partitioning methodology taken by the two systems - one utilizing Quad Tree whiles the other utilizing Constrained Delaunay Triangulation. In any case, as we should appear in the trial comes about, it might prompt genuine productivity issues while running the algorithms by and by, particularly when the space estimate is huge yet the coveted items are few and congregated in little groups. Another issue shared by both existing procedures is that they just work on 2D spaces, yet not higher dimensional spaces that uncover a KNN interface.
1.1 Hidden Data
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2808 inquiries to slither all focuses when the
shrouded focuses are in skewed circulation.
1.2 Data Crawling
Slithering algorithms with outside Source: The Two-D creeping algorithm is performed subsequent to apportioning the TwoD space utilizing outer Source. This is a standout amongst the most slithering (searching) algorithms this paper proposed in TwoD space. The DCDT slithering algorithm: This algorithm was proposed in work. To our source, this slithering algorithm is the progressed for kNN based databases in 2-D space. The compelled Delaunay triangulation method is executed by creators, parcels the revealed districts into triangles, and after that the new query is gone up against the Center of the hardest triangle. Their algorithm recursively rehashed this procedure until the point that no revealed triangles are cleared out. We can discover the quantifiability of the algorithms with various size of the databases.
1.3 Location Based Services
Location Based Services (LBS), e.g., WeChat, Four Square, and so on., began offering electronic search systems that take after a kNN query interface. In particular, for a client indicated query location q, these sites bringing from the items in its backend information to the best k closest neighbor to q and return back to these k articles to the client through the web interface. In this paper, we think about the issue of creeping the LBS through the limited kNN search interface. Albeit shrouded focuses for the most part exist in 2-D space, there are a few applications with
focuses in higher dimensional spaces. We expand the 2-D creeping algorithm to the general m-D space, and give the m-D slithering algorithm with hypothetical upper bound examination. This paper tends to the issue of slithering all articles productively from a LBS site, through the public kNN web search interface it gives. In particular, we create creeping algorithm for 2D and higher dimensional spaces, separately, and exhibit through hypothetical investigation that the overhead of our algorithms can be limited by a component of the quantity of measurements and the quantity of crept objects, paying little respect to the hidden disseminations of the articles.
1.4 KNN Queries
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2809 administration, for example, Google Maps) for
a given era (e.g., one day).
2. LITERATURE SURVEY
The crawler engines of today can't accomplish most by far of the information contained in the Web. A phenomenal measure of huge information is "concealed" behind the request kinds of online databases, and additionally is capably made by developments, for instance, JavaScript. This piece of the web is by and large known as the Deep Web or the Hidden Web. We have produced DeepBot, a model hid web crawler prepared to get to such substance. DeepBot gets as data a course of action of room definitions, each one depicting a specific data gathering undertaking and normally perceives and makes sense of how to execute inquiries on the structures apropos to them. In this paper we depict the strategies used for building DeepBot and report the test happens got when testing it with a couple of bona fide data gathering endeavors.
We show a system called DEQUE (Deep WEbQUerySystEm) for showing and scrutinizing the significant Web. We propose a data show for addressing and securing HTML outlines, and a web shape request lingo called DEQUEL for recuperating data from the significant Web and securing them in the design favorable for additional taking care of. Our system can address shapes (single and consecutive) with data regards from relations and from result pages (delayed consequences of addressing web outlines). We show a novel approach in exhibiting of persistent structures and present the possibility of the super shape.
A model system has been executed on a SUN workstation working under Solaris 2.7 using Perl variation 5.005_2 and using MySQL (adaptation 3.23.49) DBMS as the data stockpiling.
Significant web creep is stressed with the issue of surfacing covered substance behind interest interfaces on the Web. While some significant destinations keep up report arranged artistic substance (e.g., Wikipedia, PubMed, Twitter, et cetera.), which has for the most part been the convergence of the significant web composing, we watch that a gigantic piece of significant locales, including all online shopping districts, priest sorted out components instead of substance records. Disregarding the way that crawling such substance organized substance is unquestionably significant for a combination of purposes, existing crawling strategies streamlined for document arranged substance are not most suitable for component arranged areas. In this work, we portray a model structure we have produced that has some mastery in crawling component orchestrated significant destinations. We propose methodology exclusively fitted to deal with indispensable subproblems including question period, release page filtering and URL deduplication in the specific setting of substance arranged significant destinations. These methods are likely surveyed and had all the earmarks of being practical.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2810 ensure the individual subtle elements of the
client locations. It ensures client uniqueness inside fundamental versatile administrations.
This spotlights on following viewpoints: User ought to be control the entrance to location data at various levels of granularity and with various levels of client control, client needs to portray the bunch of element that are permitted to get to its location data LBS bolster location security control by the client. It bolsters client control and adaptability. It gives Instant Messaging administration to server and customers [3].
Weijia Jia and Ke presented an anonymous affirmation convention in view of anonymous intermediary for remote frameworks. Meandering client dislikes to distinguish their own particular data to other client; they need to shield their data while pondering from home system to outside system [4].
Controlling individual client location under untrusted server may cause the protection issue for the client in remote sensor arrange. Hence Chi-Yin Chow, Mohamed F. Mokbel, and Tian presents a saving protection client location controlling framework to give better security to the client. Chi-Yin Coweta proposes a two in organize algorithm, which are data and quality-mindful algorithms used to ensure the location data of the client [5].
An extra type of web search, known as online briefest way search, is in vogue because of advance in geo situating. All things considered, existing storing approaches are unsuccessful for briefest way inquiries. This is a direct result of various essential contrasts
between web search comes about and briefest way comes about, in commonplace to query coordinating, store point covering, and query cost distinction. Spurred by this, they distinguish a few properties that are basic to the accomplishment of viable Caching for briefest way search.
3. PROPOSED SYSTEM
We create creeping algorithm for 2D and higher dimensional spaces, separately, and show through hypothetical examination that the overhead of our algorithms can be limited by an element of the quantity of measurements and the quantity of slithered objects, paying little respect to the fundamental conveyances of the items.
Then we build up our OPTIMAL-1D-CRAWL algorithm for databases in 1-D spaces which can maintain a strategic distance from the previously mentioned issue.
Finally, we give the hypothetical investigation of the proposed algorithm. Above hypothesis demonstrates that the proposed creeping algorithm can perform with cost straightly identified with the quantity of purposes of the database if the point thickness in the area changes not all that much.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2811 We clarified the subtle elements of
these datasets individually as takes after, This algorithm is the best in class of creeping (searching) algorithm for kNN based databases in Two-D space. Constrained Delaunay triangulation this strategy is actualized by creators in their work to dependably parcel the revealed locales into triangles, at that point issued the new query on the focal point of the greatest triangle.
OPTIMAL-1D-CRAWL Algorithm:
The detail of this OPTIMAL-1DCRAWL algorithm is exhibited in Algorithm 1. This algorithm focuses on the midpoints of revealed areas while the already portrayed covering algorithm focuses on the limits of revealed districts - simply this unpretentious distinction prompts on a very basic level diverse query intricacy comes about.
Algorithm 1: OPTIMAL-1D-CRAWL Algorithm
DBSCAN for grids clustering:
This paper presented another algorithm GRPDBSCAN (Grid-based DBSCAN
Algorithm with Referential Parameters). GRPDBSCAN, which accumulate the matrix segment system and various thickness in light of the grouping algorithm, enhanced its effectiveness. Then again, the Eps and Minpts parameters of the DBSCAN algorithm were they auto-produced, more target.
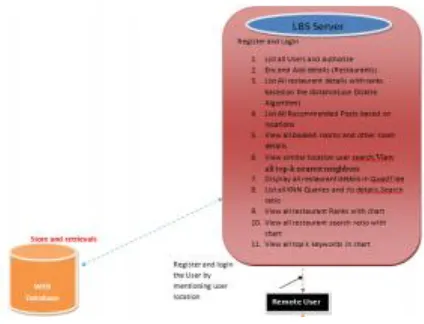
Figure 1: Architecture Diagram
Objective of the project:
Our goal in this task is to empower the creeping of a LBS database by issuing few questions through its publicly accessible kNN(Crawling Nearest Neighbor) web search strategy, with the goal that subsequently an information searchers can just regard the searched information as a disconnected database and play out whatever symptomatic activities it wanted. Here "creeping" (searching)is for the most part characterized, i.e., it can allude to the extraction of all articles from the database ,or just those items that fulfill certain choice conditions, inasmuch as such conditions can be "went through" to the kNN interface.
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2812 Usage manages the instruments utilized for
front end plan and strategies utilized for back end associations. Obscuration is the apparatus on which the web application is created. Alternate apparatuses utilized are MySQL and JDK. We are utilizing the programming dialects HTML and Java. The programming systems utilized are Angular JS and Bootstrap.
AngularJS (regularly alluded to as "Angular.js") is a JavaScript-based open-source front-end web application structure basically kept up through Google and by a network of people and partnerships to address a significant number of the difficulties experienced in creating single-page applications. The Angular JS system gives more essential perusing the HTML page, which has inserted into it extra custom label properties. Bootstrap is a free and open-source front-end web structure for outlining sites and web applications. It contains HTML-and CSSbased configuration formats for shapes, catches and so forth and other interface parts, and in addition discretionary JavaScript augmentations. Not at all like most web systems, it worries about its front-end advancement as it were.
The tables are made once in MySQL summon provoke. Association between front end to backend is finished by Hibernate. Rest is open source Java Framework. It's essential component is mapping from Java classes to database tables.
By utilizing the above ideas we executed web application through three stages:
Stage 1: Development of Web Application utilizing html, css and Java.
Stage 2: Creating tables in MySQL charge line incite.
Stage 3: Hosting the Application in cloud and Running in program.
Usage is the fundamental phase of the undertaking when the hypothetical plan is transformed out into a working framework. In this way it can be thought to be the most troublesome stage in accomplishing a fruitful new framework and it ought to be work with certainty and successful. This new framework is providing for client. The execution arrange includes cautious arranging, testing of the current framework and it's limitations on usage, outlining of techniques to accomplish changing and assessment of changeover strategies.
5. CONCLUSION
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2813 spatial space. In the general situation when the
constrained area of the things is erratic, it can be pre-distributed a course of action of square shapes (3D squares) before using the frameworks proposed in this paper.
REFERENCES
[1] L. Barbosa and J. Freire, “Siphoning hidden-web data throughkeyword-based interfaces,” in SBBD, 2004, pp. 309– 321.
[2] A. Ntoulas, P. Pzerfos, and J. Cho, “Downloading textualhidden web content through keyword queries,” in Digital Libraries, 2005. JCDL’05. Proceedings of the 5th ACM/IEEE-CSJoint Conference on. IEEE, 2005, pp. 100– 109.
[3] K. Vieira, L. Barbosa, J. Freire, and A. Silva, “Siphon++: a hidden-web crawler for keyword-based interfaces,” in Proceedings of the 17th ACM conference on Information and knowledge management. ACM, 2008, pp. 1361–1362.
[4] L. Jiang, Z. Wu, Q. Feng, J. Liu, and Q. Zheng, “Efficient deepweb crawling using reinforcement learning,” in Advances in Knowledge Discovery and Data Mining. Springer, 2010, pp. 428–439.
[5] S. Raghavan and H. Garcia-Molina, “Crawling the hidden web,” in VLDB 2001, Proceedings of 27th International Conference on Very Large Data Bases, September 11-14, 2001,Roma, Italy, 2001, pp. 129–138.
[Online]. Available:
http://www.vldb.org/conf/2001/P129.pdf
[6] S. W. Liddle, D. W. Embley, D. T. Scott, and S. H.Yau, “Extracting data behind web forms,” in Conceptual Modeling - ER 2002, 21st International Conference on Conceptual Modeling, Tampere, Finland, October 7-11, 2002, Proceedings,2002, pp. 402–413. [Online]. Available: http://dx.doi.org/10. 1007/978-3-540-45275-135
[7] P. Wu, J. Wen, H. Liu, and W. Ma, “Query selection techniques for efficient crawling of structured web sources,” in Proceedings of the 22nd International Conference on Data Engineering, ICDE2006, 3-8 April 2006,
Atlanta, GA, USA,
2006,p.47.[Online].Available:http://dx.doi.org /10.1109/ICDE. 2006.124
[8]Mcdonalds, “Mcdonalds page, http://www.mcdonalds.com/,”
[Accessed:Aug.6,2014]. [Online]. Available: nurlfhttp://www. mcdonalds.com/us/en/ restaurant locator. htmlg
[9] S. Byers, J. Freire, and C. T. Silva, “Efficient acquisition of webdata through restricted query interfaces,” in Poster Proceedingsof the Tenth International World Wide Web Conference, WWW 10, Hong Kong, China, May 1-5, 2001, 2001.[Online].Available:http://www10.org/cdr om/posters/105 1.pdf
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 2814
[11]G. E. Glasses,
“Greateyeglassespage,http://www.greateyegla sses.com/shop/search.php,” [Accessed: Jan. 20, 2014]. [Online]. Available: nurlfhttp://www.greateyeglasses.com
/shop/search.phpg
[12]Yahoo,“Yahoolocalpage,
https://local.yahoo.com/,”[Acces sed: Dec. 2012]. [Online]. Available: nurlfhttps://local. yahoo.com/g
About Authors:
O.Siva Ramakrishna is current pursuing
M.Tech in CSE. dept., B.V.C Engineering
College, Odalarevu, Amalapuram,
E.G.DT-533 210, AP.