106
An Efficient Approach to Detecting Phishing A Web
Using K-Means and Naïve-Bayes Algorithms
Ms. Kranti Wanawe
1, Ms. Supriya Awasare
2, Mrs. N. V. Puri
3Computer Department1, 2, 3, Universal College Of Engineering and Research, Pune1, 2, 3 Email: [email protected]1
Abstract-
Since last few years, Phishing is becoming one of the biggest network crime. Phishing is a current social engineering attack that results in online theft. Phishing is a form of identity theft in which a combination of social engineering and web site spoofing techniques are used to track a user into revealing confidential information with economic value. Over the past few years, we applied different methods for detecting phishing web using known as well as new features. In existing approach, Phishing sites are recognized by using blacklist-based approach. The disadvantage of this approach is that non-blacklisted phishing sites are not recognized. This paper presents an efficient approach for detection of phishing a web based on features of legitimate and phishing webs. In this paper, we proposed two algorithms that are K-Means and Naïve Bayes. Using these algorithms, we are checking blacklist for detection of phishing sites as well as their behavior also.Index Terms- Phishing; K-means; Naïve Bayes; Spoofing; Blacklist-based approach
.
1. INTRODUCTION
Now a days, there are so many people uses internet services, who are also known as ‘Netizens’. These internet services are convenient to all users and also beneficial as it saves money, time as well as efforts. Unfortunately, the usefulness of online services has been overshadowed by large-scale phishing attacks rised against internet users. Phishing is the identity theft in which attackers trying to access personal information and financial credentials of online consumers.
A typical phishing attack consists of four phases that are preparation, mass broadcast, mature and account hijack. Phishing is a form of identity theft that occurs when a malicious website impersonates a legitimate one in order to acquire sensitive information such as passwords, account details or credit card numbers. Phishing is a deception technique to gather confidential information by masquerading as a trustworthy person or business in an electronic communications
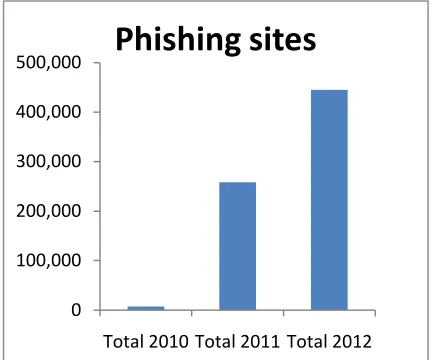
According to the antiphishing working group, there were 18480 unique websites. Unique phishing attacks and 9666 unique phishing sites reported in march 2006. The total no of phishing attacks launched in
2012 was 59% higher than 2011. It appears that phishing has been able to set another record year in attack volumes, with global losses from phishing estimated at $1.5 billion in 2012. This represents a 22% increase from 2011
0 100,000 200,000 300,000 400,000 500,000
Total 2010 Total 2011 Total 2012
[image:1.595.307.523.452.632.2]Phishing sites
Figure 1. Unique phishing sites for three years
107
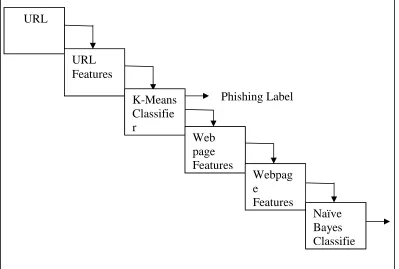
Figure 2: System Architecture for proposed system.
Figure 2 shows the system architecture. In this architecture, each block specifies particular procedure .These procedures are performed in the following steps:
Step 1. Extract URL identity of given web W and generate its features.
Step 2. Cluster W by K-Means classifier and return the result (+1, -1, 0).
// +1: Non-phishing, -1: Phishing, 0: Suspicious
Step 3. If result=+1 then output is Non-phishing label. If result= -1 then output is Phishing label. If result=0 then go to Step 4.
Step 4. If W doesn’t have a text input, then output is phishing web.
If W has a text input, then go to Step 5. Step 5. Extract the Webpage identity of W and
generate its features.
Step 6. Classify web W by Naïve Bayes classifier and output the phishing label.
The attackers of phishing websites convince consumers by developing different types of engineering solutions such as threatening to stop
consumer or consumer’s account if they don’t update their account details related to their account or for any other reasons to attract the customers by visiting their phishing websites.
We are proposing two algorithms for detecting phishing websites using existing as well as new features. We are proposing some features that can help to discover phishing attacks with limited prior knowledge about the algorithms which we are going to use for detection of phishing attacks. Our approach is to detecting phishing websites not to prevent access to the phishing websites. This paper provides an efficient approach to detecting phishing a websites with the help of URL features and Machine-Learning algorithms.
This paper is classified as follows:
In section 2 we provide related work to the existing system. In section 3 we are presenting modules and data used. In section 4 we enhance future scope of our approach and conclusion remarks.
URL
URL
Features
K-Means
Classifie
r
Web
page
Features
Webpag
e
Features
108
3. RELATED WORK
There are large number of anti-phishing approaches developed till now. Those are generally classified into five main types:
(1) Email-based approach (2) Black-list-based approach (3) Visual-clue-based approach (4) Website-feature-based approach (5) Information-flow-based approach
(1) Email-based approach
The approaches in this category eliminate the problem of phishing at the email level by preventing the phishing emails from reaching the victims. For this purpose, these approaches use the filters. Thus, these are somewhat related to the anti-spam research. If the Bayesian filters are regularly trained, then they are more effective in also intercepting the phishing emails. Main drawback of email-based approach is that their efficiency depends on the regular training. And though these anti-spam solutions are more effective, they are not perfect and some of phishing emails may reach potential victims. Yahoo and Microsoft also have defined the email authentication protocol file sender ID.
(2) Black-list-based approach
Blacklist of phishing domains are the basis of most popular and widely deployed anti-phishing techniques. Google safe browsing[F. Schneider, et al 2007] uses the blacklists of the phishing URLs to detect the phishing sites. Drawback of this approach is that the phishing site those are non-blacklisted are not detected. On the other hand[Net Craft, 2007], the NetCraft tool bar calculates the phishing probability of a visited site. It does this by trying to find out how old the registered domain is. Company maintains the database of sites which is used by this approach. These approaches are effective according to how quality of the lists are maintained.
(3) Visual-clue-based approach
One solution is proposed by Dhamija et al. which uses the dynamic security skin on the browser of users. This technique allows remote server to give its identity for proving that this is easy for humans to verify but difficult for phishers to spoof. Drawback of this approach is that it needs the user’s effort. The user must be aware of the phishing attacks and check actively that the visited site is spoofed or not.
(4) Website-feature-based approach
Website-feature based solution is spoofGuard in phishing literatures. It is phishing symptoms in web pages. Similarly internet explorer 7 has also simple anti-phishng functionality where browser analyzes the HTML structure of web pages to determine whether that certain page is phishing or not. In this approach, analyze and compare legitimate and phishing web pages for defining matrices that can be useful for detection of phishing pages. Classify a web page as phishing page if its visual similarity value is above predefined threshold value.
(5) Information-flow-based approach
AntiPhish uses different approaches for showing the track of how sensitive information is being submitted. If it detects that sensitive information is being entered on phishing websites, then warning is generated and pending operation is canceled. Drawback of AntiPhish is that it requires user interaction for specifying which sensitive information should be captured and monitored.
4. MODULES
We are proposing main two modules for detection of phishing webpages. The purpose of using these modules is to directly extract data and features from URL. The modules used in our approach are described below:
(1) Features Extraction
Feature extraction plays vital role for efficient detection of phishing web. In this module, URL features and Website features are described.
• URL features:
Extracting URL with trained model is lightweight operation as compared to downloading whole webpage and using its contents for extracting purpose. There exist number of URL features that allow for detection of phishing sites. This module shows the complete count of URL features after extracting, then that count of URL features is the input data to K-Means algorithm for clustering. The URL features are as follows:
• IP address:
Server’s identity is achieved through the use of an IP address. A trust website usually has domain name for its verification and phishing sites normally use some unauthenticated Zombie system to host that particular sites. For avoiding from domain registration or user checking, the IP address is a way used to hide from all identification and verification.
109
Here many dot appearance is checked in URL. Phishing web uses fake domain name to construct legitimate look of the URL with the help of extra dots put in URL. So the verification of dots in URL is being performed at this stage.
• No. of suspicious URL:
When ‘@’ or ‘_’ these suscipious characters are present in URL that URL is Suspicious URL. This URL is used to detect phishing web. When phishing web try to access the victims, then URL is checked, if the URL is suspicious then that site is phishing site.
• No. of slashes in URL:
Generally, the URL should not contains more number of slashes. If URL contains more than five slashes then that URL will be a phishing URL.
• K-means Algorithm:
K-means is one of the simplest unsupervised learning algorithms that solve the well known clustering problem. In statistics and data mining, k-means clustering is a method of cluster analysis which aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean. It is similar to the expectation-maximization algorithm for mixtures of Gaussians in that they both attempt to find the centers of natural clusters in the data as well as in the iterative refinement approach employed by both algorithms. Description:
Given a set of observations (x1, x2, …, xn), where each observation is a d-dimensional real vector, k-means clustering aims to partition the n observations into k sets (k ≤ n) S = {S 1 , S 2 , …, S k } so as to minimize the within-cluster sum of squares (WCSS):
(1) where µi is the mean of points in Si.
The algorithm is represented by following steps: Step 1: Place K points into the space represented by
the objects that are being clustered. These points represent initial group centroids. Step 2: Assign each object to the group that has the
closest centroid.
Step 3: When all objects have been assigned, recalculate the positions of the K centroids. Step 4: Repeat Steps 2 and 3 until the centroids no
longer move. This produces a separation of
the objects into groups from which the metric to be minimized can be calculated.
In our approach, after applying K-Means algorithm on URL’s features, predictor predicts three states. Predictor is used to show the prediction states. It is behavioural response to phishing risk. It results three states i.e. ‘yes’,’ no’,’ may be’.
• Yes is the prediction which is for phishing.
• No is for legitimate web.
• May be is for suspicious webs.
Figure 3: Working of K-Means
At the result ‘may be’, naive bayes algorithm will be applied on complete website to detect phishing.
• Website Features:
Given suspicious web W and its identity terms would determine the feature value of that webpage. First the whole suspicious webpage is downloaded then we are extracting the feature of that webpage. After that webpage is parsed into Document Object Model(DOM) tree. DOM is cross-platform and language independent convention for representing and interacting with objects in HTML, XHTML, XML documents. It allows programs and scripts to dynamically access and update the documents including its contents, structure and style. After parsing, feature vector generated would passed to Naïve Bayes Classifier to detect whether webpage is phishing or legitimate. The website features are discussed below-
• Forms:
If any webpage contains any HTML text entry form asking for confidential data from users such as password and credit card number. Most Phishing sites contains such forms for acquiring personal information from users. Then this is risky for victims.
K-Means Classifier
Predictor
Naïve Bayes Classifier
110
So check whole webpage and forms for avoiding such risk, so that criminals not getting personal information they want.
• Nil Anchors:
A nil anchor is an anchor that doesn’t point anywhere. It is just like NULL value. If a webpage has more nil anchor, then that webpage becomes more suspicious. Foreign Anchors:
The anchor which contains the link which is present on another page. This anchor tag contains href attribute. This attribute has value is on URL to which the page is linked with domain name in URL of pages are not similar in foreign anchors in webpage, but too many foreign anchors increase the daught on suspicious web.
• Foreign Requests:
As like foreign anchor, when there are many foreign requests present in webpage then that web could be suspicious or less credible.
• Naïve Bayes algorithm:
The Naïve Bayes Classifier technique is particularly suited when the dimensionality of the inputs is high. Despite its simplicity, Naive Bayes can often outperform more sophisticated classification methods. Naïve Bayes model identifies the characteristics of patients with heart disease. It shows the probability of each input attribute for the predictable state.
Why preferred Naive bayes algorithm:
Naive Bayes or Bayes’ Rule is the basis for many machine-learning and data mining methods. The rule (algorithm) is used to create models with predictive capabilities. It provides new ways of exploring and understanding data. It is used when data is high and we want efficient output compared to other methods.
• Bayes Rule:
A conditional probability is the likelihood of some conclusion, F, given some evidence/observation, E, where a dependence relationship exists between F and E.
This probability is denoted as P(F |E) where P(E/F)=[P(E/F)P(F)] /[P(E)]
• NB Classifier:
The website features are used to encrypt web’s URLs as HD feature vectors. Naïve Bayes classifier is one of the high detection approach for learning classification of text documents. Given a set of classified training samples, an application can learn from these samples, so as to predict the class of an unmet samples.
The features (a1, a2, a3, a4) which are present in URL are independent from each other. Every feature ai(1<=i<=4) text binary value showing whether the particular property comes in URL. The probability is calculated that the given web belongs to a class m(m1: Non-phishing and m2: Phishing) as follows:
P(m1/A)= (P(m1)*P(A/mi))/P(A)
Where all of P(A) are constant meanwhile P(ai|m1) and P(mi) can be easily calculated from training. The proportional to P(m1|A), P(m2|A) is calculated and the results are as follows:
P(m1|A)P(m2|A) > b (b>1), Non-phishing Web.
P(m2|A)P(m1|A) > b , Phishing Web.
Figure 4:Working Naive-Bayes
5. FUTURE SCOPE
As a future work, we plan to use different efficient algorithms to compare accurate rates. We also plan to adjust existing and known features extraction methods and use more relevant features that produces better result. After applying both algorithms if web’s legality is still suspicious, then we can apply fast and high detection algorithms. And we will plan for implementing anti-phishing tools for different environments.
No
Yes
Website
Features
DOM Tree
DFS
Parsing
Naïve
Bayes
Classifier
111
6. CONCLUSION
Phishing is becoming major crime in the network. In this project, an efficient approach is proposed to identifying the potential phishing target of a given web. Every web claims a webpage identity, either legal or illigals. If a web claims a fake identity, abnormality may exist in a network space; therefore our approach could detect and differentiate between a legitimate and a phishing web. Our approach first extracts the URL features and then test whether the page is phishing or not using K-Means algorithm. When the web’s legality is still suspicious, then categorize its webpage features and test whether the page is phishing or not using Navie Bayes algorithm.
ACKNOWLEDGEMENTS
This work was supported by Universal College of Engineering and Research, pune under grants Prof. N.V.Puri and Prof. A.D.Londhe for building grant is greatfully acknowledged.
REFERENCES
[1] Angelo P. E. Rosiello , Engin Kirda‡, Christopher Kruegel‡, and Fabrizio Ferrandi
Politecnico di Milano
[email protected],[email protected] ‡Secure Systems Lab, Technical University Vienna {ek,chris}@seclab.tuwien.ac.at A Layout-Similarity-Based Approach for Detecting Phishing Pages.
[2] F. Schneider, N. Provos, R. Moll, M. Chew, and B. Rakowski. Phishing Protection Design Doc-
umentation. http://wiki.mozilla.org/Phishing_ Protection:_Design_Documentation, 2007. [3] Gartner Press Release. Gartner Says Number of
Phishing E-Mails Sent to U.S. Adults eearly Doubles in Just Two Years . http://www.gartner.com/it/ page.jsp?id=498245, 2006.
[4] Google Inc, Google safe browsing for Firefox, http://www.google.com/tools/firefox/
safebrowsing/
[5] Journal of Computational Information Systems 9: 14 (2013) 5553–5560 Available at http://www.Jofcis.com Xiaoqing GU, Hongyuan WANG , Tongguang NI, An E cient Approach to Detecting Phishing Web.
[6] Microsoft. Sender ID Home Page. http://www. microsoft.com/mscorp/safety/technologies/ senderid/default.ms%px, 2007.
[7] NetCraft. Netcraft anti-phishing tool bar. http:// toolbar.netcraft.com, 2007.
[8] PhishtankInc, phishing dateset, http://www.phishtank.com/.
[9] R. Dhamija and J. D. Tygar. The battle against phish- ing: Dynamic security skins. In Proceedings of the 2005 symposium on Usable privacy and security, New York, NY, pages 77– 88. ACM Press, 2005.