Study of Some Distance Measures for Language and Encoding
Identification
Anil Kumar Singh
Language Technologies Research Centre International Institute of Information Technology
Hyderabad, India [email protected]
Abstract
To determine how close two language models (e.g., n-grams models) are, we can use several distance measures. If we can represent the models as distributions, then the similarity is basically the simi-larity of distributions. And a number of measures are based on information theo-retic approach. In this paper we present some experiments on using such similar-ity measures for an old Natural Language Processing (NLP) problem. One of the measures considered is perhaps a novel one, which we have called mutual cross entropy. Other measures are either well known or based on well known measures, but the results obtained with them vis-a-vis one-another might help in gaining an insight into how similarity measures work in practice.
The first step in processing a text is to identify the language and encoding of its contents. This is a practical problem since for many languages, there are no uni-versally followed text encoding standards. The method we have used in this paper for language and encoding identification uses pruned character n-grams, alone as well augmented with wordn-grams. This method seems to give results comparable to other methods.
1 Introduction
Many kinds of models in NLP can be seen as dis-tributions of a variable. For various NLP prob-lems, we need to calculate the similarity of such models or distributions. One common example of
this is the n-grams model. We might have sev-eral reference data sets and then we may want to find out which of those matches most closely with a test data set. The problem of language and en-coding identification can be represented in these terms. One of the most important questions then is which similarity measure to use. We can expect that the performance obtained with the similarity measure will vary with the specific problem and the kind of model used or some other problem spe-cific details. Still, it will be useful to explore how these measures relate to each other.
The measures we are going to focus on in this paper are all very simple ones and they all try to find the similarity of two models or distributions in a (more or less) information theoretic way, except theout of rank measure proposed by Cavnar and Trenkle (Cavnar and Trenkle, 1994).
This work had started simply as an effort to build a language and encoding identification tool specifically for South Asian languages. During the course of this work, we experimented with various similarity measures and some of the results we ob-tained were at least a bit surprising. One of the measures we used was something we have called mutual cross entropy and its performance for the current problem was better than other measures.
Before the content of a Web page or of any kind of text can be processed for computation, its lan-guage and encoding has to be known. In many cases this language-encoding is not known before-hand and has to be determined automatically. For languages like Hindi, there is no standard encod-ing followed by everyone. There are many well known web sites using their own proprietary en-coding. This is one of the biggest problems in ac-tually using the Web as a multilingual corpus and for enabling a crawler to search the text in
guages like Hindi. This means that the content in these languages, limited as it is, is invisible not just to people (which could be just due to lack of display support or unavailability of fonts for a par-ticular encoding) but even to crawlers.
The problem of language identification is sim-ilar to some other problems in different fields and the techniques used for one such problem have been found to be effective for other prob-lems too. Some of these probprob-lems are text cate-gorization (Cavnar and Trenkle, 1994), cryptanal-ysis (Beesley, 1988) and even species identifi-cation (Dunning, 1994) from genetic sequences. This means that if something works for one of these problems, it is likely to work for these other problems.
It should be noted here that the identifica-tion problem here is that of identifying both lan-guage and encoding. This is because (especially for South Asian languages) the same encoding can be used for more than one languages (ISCII for all Indian languages which use Brahmi-origin scripts) and one language can have many encod-ings (ISCII, Unicode, ISFOC, typewriter, pho-netic, and many other proprietary encodings for Hindi).
In this paper we describe a method based mainly on character n-grams for identifying the language-encoding pair of a text. The method requires some training text for each language-encoding, but this text need not have the same con-tent. A few pages (2500-10000 words) of text in a particular language-encoding is enough. A pruned character basedn-grams model is created for each language-encoding. A similar model is created for the test data too and is compared to the training models. The best match is found using a similar-ity measure. A few (5-15) words of test data seems to be enough for identification in most cases.
The method has been evaluated using various similarity measures and for different test sizes. We also consider two cases, one in which the pruned character n-grams model is used alone, and the other in which it is augmented with a wordn-gram model.
2 Previous Work
Language identification was one of the first natural language processing (NLP) problems for which a statistical approach was used.
Ingle (Ingle, 1976) used a list of short words
in various languages and matched the words in the test data with this list. Such methods based on lists of words or letters (unique strings) were meant for human translators and couldn’t be used directly for automatic language identification. They ignored the text encoding, since they assumed printed text. Even if adapted for automatic identification, they were not very effective or scalable.
However, the earliest approaches used for au-tomatic language identification were based on the above idea and could be called ‘translator ap-proaches’. Newman (Newman, 1987), among oth-ers, used lists of lettoth-ers, especially accented letters for various languages and identification was done by matching the letters in the test data to these lists.
Beesley’s (Beesley, 1988) automatic language identifier for online texts was based on mathemat-ical language models developed for breaking ci-phers. These models basically had characteristic letter sequences and frequencies (‘orthographical features’) for each language, making them similar ton-grams models. The insights on which they are based, as Beesley points out, have been known at least since the time of Ibn ad-Duraihim who lived in the 14th century. Beesley’s method needed 6-64 K of training data and 10-12 words of test data. It treats language and encoding pair as one entity.
Cavnar also mentions that top 300 or son-grams are almost always highly correlated with the lan-guage, while the lower rankedn-grams give more specific indication about the text, namely the topic. The distance measure used by Cavnar is called ‘out-of-rank’ measure and it sums up the differ-ences in rankings of then-grams found in the test data as compared to the training data. This is among the measures we have tested.
The language model used by Combrinck and Botha (Combrinck and Botha, 1994) is also based on bigram or trigram frequencies (they call them ‘transition vectors’). They select the most dis-tinctive transition vectors by using as measure the ratio of the maximum percentage of occurrences to the total percentage of occurrences of a transi-tion vector. These distinctive vectors then form the model.
Dunning (Dunning, 1994) also used ann-grams based method where the model selected is the one which is most likely to have generated the test string. Giguet (Giguet, 1995b; Giguet, 1995a) re-lied upon grammatically correct words instead of the most common words. He also used the knowl-edge about the alphabet and the word morphology viasyllabation. Giguet tried this method for tag-ging sentences in a document with the language name, i.e., dealing with multilingual documents.
Another method (Stephen, 1993) was based on ‘common words’ which are characteristic of each language. This methods assumes unique words for each language. One major problem with this method was that the test string might not contain any unique words.
Cavnar’s method, combined with some heuris-tics, was used by Kikui (Kikui, 1996) to identify languages as well as encodings for a multilingual text. He relied on known mappings between guages and encodings and treated East Asian lan-guages differently from West European lanlan-guages. Kranig (Muthusamy et al., 1994) and (Simon, 2005) have reviewed and evaluated some of the well known language identification methods. Mar-tins and Silva (MarMar-tins and Silva, 2005) describe a method similar to Cavnar’s but which uses a dif-ferent similarity measure proposed by Jiang and Conrath (Jiang and Conrath, 1997). Some heuris-tics are also employed.
Poutsma’s (Poutsma, 2001) method is based on Monte Carlo sampling ofn-grams from the begin-ning of the document instead of building a
com-plete model of the whole document. Sibun and Reynar (Sibun and Reynar, 1996) use mutual in-formation statistics or relative entropy, also called Kullback-Leibler distance for language identifica-tion. Souter et al.(Souter et al., 1994) compared unique character string, common word and ’tri-graph’ based approaches and found the last to be the best.
Compression based approaches have also been used for language identification. One example of such an approach is called Prediction by Partial Matching (PPM) proposed by Teahan (Teahan and Harper, 2001). This approach uses cross entropy of the test data with a language model and predicts a character given the context.
3 Pruned CharacterN-grams
Like in Cavnar’s method, we used prunedn-grams models of the reference or training as well as test data. For each language-encoding pair, some training data is provided. A character based n -gram model is prepared from this data. N-grams of all orders are combined and ranked according to frequency. A certain number of them (say 1000) with highest frequencies are retained and the rest are dropped. This gives us the pruned charac-ter n-grams model, which is used for language-encoding identification.
As an attempt to increase the performance, we also tried to augment the pruned charactern-grams model with a wordn-gram model.
4 Distance Measures
Some of the measures we have experimented with have already been mentioned in the section on pre-vious work. The measures considered in this work range from something as simple as log probabil-ity difference to the one based on Jiang and Con-rath (Jiang and ConCon-rath, 1997) measure.
Assuming that we have two models or distribu-tionsPandQover a variableX, the measures (sim) are defined as below (pand q being probabilities andrandsbeing ranks in modelsPandQ:
1. Log probability difference:
sim=X
x
(log p(x)−log q(x)) (1)
2. Absolute log probability difference:
sim=X
x
3. Cross entropy:
sim=X
x
(p(x)∗log q(x)) (3)
4. RE measure (based on relative entropy or Kullback-Leibler distance – see note below):
sim=X
x
p(x) log p(x)
log q(x) (4)
5. JC measure (based on Jiang and Conrath’s measure) (Jiang and Conrath, 1997):
sim=A−B (5)
where,
A= 2∗
X
x
(log p(x) +log q(x)) (6)
and,
B =X
x
log p(x) +X
x
log q(x) (7)
6. Out of rank measure (Cavnar and Trenkle, 1994):
sim=X
x
abs(r(x)−s(x)) (8)
7. MRE measure (based on mutual or symmet-ric relative entropy, the original definition of KL-distance given by Kullback and Leibler):
sim=X
x
p(x)log p(x) log q(x)+
X
x
q(x)log q(x) log p(x)
(9) 8. Mutual (or symmetric) cross entropy:
sim=X
x
(p(x)∗log q(x)+q(x)∗log p(x)) (10) As can be noticed, all these measures, in a way, seem to be information theoretic in nature. How-ever, our focus in this work is more on the pre-senting empirical evidence rather than discussing mathematical foundation of these measures. The latter will of course be interesting to look into.
NOTE:
We had initiallly experimented with relative en-tropy or KL-distance as defined below (instead of the RE measure mentioned above):
sim=X
x
p(x)log p(x)
q(x) (11)
Another measure we tried was DL measure (based on Dekang Lin’s measure, on which the JC measure is based):
sim= A
B (12)
whereAandB are as given above.
The results for the latter measure were not very good (below 50% in all cases) and the RE mea-sure defined above performed better than relative entropy. These results have not been reported in this paper.
5 Mutual Cross Entropy
Cross entropy is a well known distance measure used for various problems. Mutual cross entropy can be seen as bidirectional or symmetric cross en-tropy. It is defined simply as the sum of the cross entropies of two distributions with each other.
Our motivation for using ‘mutual’ cross entropy was that many similarity measures like cross en-tropy and relative enen-tropy measure how similar one distribution is to the other. This will not neces-sary mean the same thing as measuring how sim-ilar two distributions are to each other. Mutual information measures this bidirectional similarity, but it needs joint probabilities, which means that it can only be applied to measure similarity of terms within one distribution. Relative entropy or Kullback-Leibler measure is applicable, but as the results show, it doesn’t work as well as expected.
Note that some authors treat relative entropy and mutual information interchangeably. They are very similar in nature except that one is applicable for one variable in two distributions and the other for two variables in one distribution.
Our guess was that symmetric measures may give better results as both the models give some in-formation about each other. This seems to be sup-ported by the results for cross entropy, but (asym-metric) cross entropy and RE measures also gave good results.
6 The Algorithm
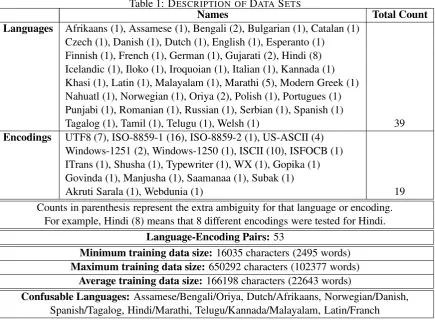
Table 1: DESCRIPTION OF DATASETS
Names Total Count
Languages Afrikaans (1), Assamese (1), Bengali (2), Bulgarian (1), Catalan (1) Czech (1), Danish (1), Dutch (1), English (1), Esperanto (1)
Finnish (1), French (1), German (1), Gujarati (2), Hindi (8) Icelandic (1), Iloko (1), Iroquoian (1), Italian (1), Kannada (1) Khasi (1), Latin (1), Malayalam (1), Marathi (5), Modern Greek (1) Nahuatl (1), Norwegian (1), Oriya (2), Polish (1), Portugues (1) Punjabi (1), Romanian (1), Russian (1), Serbian (1), Spanish (1)
Tagalog (1), Tamil (1), Telugu (1), Welsh (1) 39 Encodings UTF8 (7), ISO-8859-1 (16), ISO-8859-2 (1), US-ASCII (4)
Windows-1251 (2), Windows-1250 (1), ISCII (10), ISFOCB (1) ITrans (1), Shusha (1), Typewriter (1), WX (1), Gopika (1) Govinda (1), Manjusha (1), Saamanaa (1), Subak (1)
Akruti Sarala (1), Webdunia (1) 19
Counts in parenthesis represent the extra ambiguity for that language or encoding. For example, Hindi (8) means that 8 different encodings were tested for Hindi.
Language-Encoding Pairs: 53
Minimum training data size:16035 characters (2495 words) Maximum training data size: 650292 characters (102377 words)
Average training data size:166198 characters (22643 words)
Confusable Languages: Assamese/Bengali/Oriya, Dutch/Afrikaans, Norwegian/Danish, Spanish/Tagalog, Hindi/Marathi, Telugu/Kannada/Malayalam, Latin/Franch
Table 2: NUMBER OFTESTSETS
Size Number
100 22083
200 10819
500 4091
1000 1867
2000 1524
All test data 840
or customized for best performance. Perhaps they can even be learned by using some approach as the EM algorithm.
1. Train the system by preparing character based and word based (optional) n-grams from the training data.
2. Combine n-grams of all orders (Ocfor char-acters andOw for words).
3. Sort them by rank.
4. Prune by selecting only the top Nc charac-ter n-grams and Nw word n-grams for each language-encoding pair.
5. For the given test data or string, calculate the charactern-gram based score simcwith every model for which the system has been trained.
6. Select the t most likely language-encoding
pairs (training models) based on this charac-ter basedn-gram score.
7. For each of thetbest training models,
calcu-late the score with the test model. The score is calculated as:
score=simc+a∗simw (13)
wherecandwrepresent character based and word based n-grams, respectively. Anda is the weight given to the word basedn-grams. In our experiment, this weight was 1 for the case when word n-grams were considered and 0 when they were not.
8. Select the most likely language-encoding pair out of the t ambiguous pairs, based on the
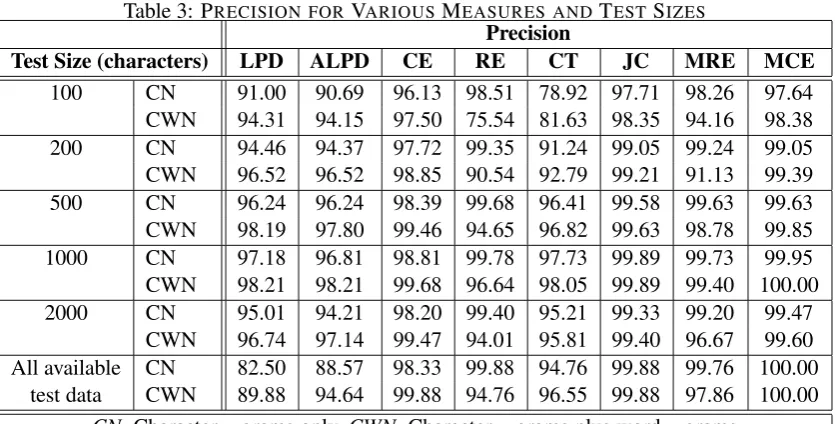
[image:5.595.108.250.419.531.2]Table 3: PRECISION FORVARIOUSMEASURES ANDTEST SIZES
Precision
Test Size (characters) LPD ALPD CE RE CT JC MRE MCE 100 CN 91.00 90.69 96.13 98.51 78.92 97.71 98.26 97.64 CWN 94.31 94.15 97.50 75.54 81.63 98.35 94.16 98.38 200 CN 94.46 94.37 97.72 99.35 91.24 99.05 99.24 99.05 CWN 96.52 96.52 98.85 90.54 92.79 99.21 91.13 99.39 500 CN 96.24 96.24 98.39 99.68 96.41 99.58 99.63 99.63 CWN 98.19 97.80 99.46 94.65 96.82 99.63 98.78 99.85 1000 CN 97.18 96.81 98.81 99.78 97.73 99.89 99.73 99.95 CWN 98.21 98.21 99.68 96.64 98.05 99.89 99.40 100.00 2000 CN 95.01 94.21 98.20 99.40 95.21 99.33 99.20 99.47
CWN 96.74 97.14 99.47 94.01 95.81 99.40 96.67 99.60 All available CN 82.50 88.57 98.33 99.88 94.76 99.88 99.76 100.00
test data CWN 89.88 94.64 99.88 94.76 96.55 99.88 97.86 100.00 CN:Charactern-grams only,CWN:Charactern-grams plus wordn-grams
To summarize, the parameters in the above method are:
1. Character basedn-gram modelsPcandQc 2. Word basedn-gram modelsPwandQw 3. OrdersOcandOwofn-grams models 4. Number of retained topn-gramsNcandNw
(pruning ranks for character based and word basedn-grams, respectively)
5. Number t of character based models to be
disambiguated by word based models 6. Weightaof word based models
Parameters 3 to 6 can be used to tune the per-formace of the identification system. The results reported in this paper used the following values of these parameters:
1. Oc= 4 2. Ow = 3 3. Nc= 1000 4. Nw = 500 5. t= 5
6. a= 1
There is, of course, the type of similarity score, which can also be used to tune the performance. Since MCEgave the best overall performance in our experiments, we have selected it as the default score type.
7 Implementation
The language and encoding tool has been imple-mented as a small API in Java. This API uses an-other API to prepare pruned character and word n-grams which was developed as part of another project. A graphical user interface (GUI) has also been implemented for identifying the languages and encodings of texts, files, or batches of files. The GUI also allows a user to easily train the tool for a new language-encoding pair. The tool will be modified to work in client-server mode for docu-ments from the Internet.
From implementation point of view, there are some issues which can significantly affect the per-formance of the system:
1. Whether the data should be read as text or as a binary file.
2. The assumed encoding used for reading the text, both for training and testing. For ex-ample, if we read UTF8 data as ISO-8859-1, there will be errors.
3. Whether the tranining models should be read every time they are needed or be kept in memory.
To take care of these issues, we adopted the fol-lowing policy:
1. For preparing character based models, we read the data as binary files and the charac-ters are read as bytes and stored as numbers. For word based models, the data is read as text and the encoding is assumed to be UTF8. This can cause errors, but it seems to be the best (easy) option as we don’t know the ac-tual encoding. A slightly more difficult op-tion to implement would be to use charac-ter based models to guess the encoding and then build word based models using that as the assumed encoding. The problem with this method will be that no programming environ-ment supports all possible encodings. Note that since we are reading the text as bytes rather than characters for preparing ‘charac-ter basedn-grams’, technically we should say that we are using byte based n-grams mod-els, but since we have not tested on multi-byte encodings, a byte in our experiments was al-most always a character, except when the en-coding was UTF8 and the byte represented some meta-data like the script code. So, for practical purposes, we can say that we are us-ing character basedn-grams.
2. Since after pruning, the size of the models (character as well as word) is of the order of 50K, we can afford to keep the training mod-els in memory rather than reading them every time we have to identify the language and en-coding of some data. This option is naturally faster. However, for some applications where language and encoding identification is to be done rarely or where there is a memory con-straint, the other option can be used.
3. It seems to be better to store the training mod-els in binary format since we don’t know the actual encoding and the assumed encoding for storing may be wrong. We tried both options and the results were worse when we stored the models as text.
Our identification tool provides customizability with respect to all the parameters mentioned in this and the previous section.
8 Evaluation
Evaluation was performed for all the measures listed earlier. These are repeated here with a code
for easy reference in table-3.
• LPD: Log probability difference
• ALPD: Absolute log probability difference
• CE: Cross entropy
• RE: RE measure based on relative entropy
• JC: JC measure (based on Jiang and Con-rath’s measure)
• CT: Cavnar and Trenkle’sout of rank mea-sure
• MRE: MRE measure based on mutual (sym-metric) relative entropy
• MCE: Mutual (symmetric) cross entropy We tested on six different sizes in terms of char-acters, namely 100, 200, 500, 1000, 2000, and all the available test data (which was not equal for various language-encoding pairs). The number of language-encoding pairs was 53 and the minimum number of test data sets was 840 when we used all available test data. In other cases, the number was naturally larger as the test files were split in fragments (see table-2).
The languages considered ranged from Es-peranto and Modern Greek to Hindi and Telugu. For Indian languages, especially Hindi, several en-codings were tested. Some of the pairs had UTF8 as the encoding, but the information from UTF8 byte format was not explicitly used for identifi-cation. The number of languages tested was 39 and number encodings was 19. Total number of language-encoding pairs was 53 (see table-1).
The test and training data for about half of the pairs was collected from web pages (such as Gutenberg). For Indian languages, most (but not all) data was from what is known as the CIIL cor-pus.
We didn’t test on various training data sizes. The size of the training data ranged from 2495 to 102377 words, with more on the lower side than on the higher.
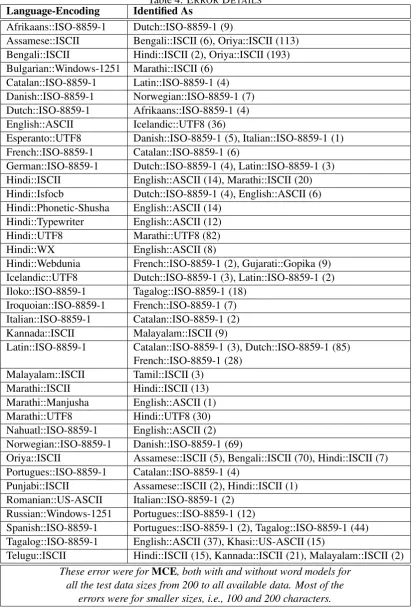
Table 4: ERRORDETAILS
Language-Encoding Identified As
Afrikaans::ISO-8859-1 Dutch::ISO-8859-1 (9)
Assamese::ISCII Bengali::ISCII (6), Oriya::ISCII (113) Bengali::ISCII Hindi::ISCII (2), Oriya::ISCII (193) Bulgarian::Windows-1251 Marathi::ISCII (6)
Catalan::ISO-8859-1 Latin::ISO-8859-1 (4) Danish::ISO-8859-1 Norwegian::ISO-8859-1 (7) Dutch::ISO-8859-1 Afrikaans::ISO-8859-1 (4) English::ASCII Icelandic::UTF8 (36)
Esperanto::UTF8 Danish::ISO-8859-1 (5), Italian::ISO-8859-1 (1) French::ISO-8859-1 Catalan::ISO-8859-1 (6)
German::ISO-8859-1 Dutch::ISO-8859-1 (4), Latin::ISO-8859-1 (3) Hindi::ISCII English::ASCII (14), Marathi::ISCII (20) Hindi::Isfocb Dutch::ISO-8859-1 (4), English::ASCII (6) Hindi::Phonetic-Shusha English::ASCII (14)
Hindi::Typewriter English::ASCII (12) Hindi::UTF8 Marathi::UTF8 (82) Hindi::WX English::ASCII (8)
Hindi::Webdunia French::ISO-8859-1 (2), Gujarati::Gopika (9) Icelandic::UTF8 Dutch::ISO-8859-1 (3), Latin::ISO-8859-1 (2) Iloko::ISO-8859-1 Tagalog::ISO-8859-1 (18)
Iroquoian::ISO-8859-1 French::ISO-8859-1 (7) Italian::ISO-8859-1 Catalan::ISO-8859-1 (2) Kannada::ISCII Malayalam::ISCII (9)
Latin::ISO-8859-1 Catalan::ISO-8859-1 (3), Dutch::ISO-8859-1 (85) French::ISO-8859-1 (28)
Malayalam::ISCII Tamil::ISCII (3) Marathi::ISCII Hindi::ISCII (13) Marathi::Manjusha English::ASCII (1) Marathi::UTF8 Hindi::UTF8 (30) Nahuatl::ISO-8859-1 English::ASCII (2) Norwegian::ISO-8859-1 Danish::ISO-8859-1 (69)
Oriya::ISCII Assamese::ISCII (5), Bengali::ISCII (70), Hindi::ISCII (7) Portugues::ISO-8859-1 Catalan::ISO-8859-1 (4)
Punjabi::ISCII Assamese::ISCII (2), Hindi::ISCII (1) Romanian::US-ASCII Italian::ISO-8859-1 (2)
Russian::Windows-1251 Portugues::ISO-8859-1 (12)
Spanish::ISO-8859-1 Portugues::ISO-8859-1 (2), Tagalog::ISO-8859-1 (44) Tagalog::ISO-8859-1 English::ASCII (37), Khasi::US-ASCII (15)
Telugu::ISCII Hindi::ISCII (15), Kannada::ISCII (21), Malayalam::ISCII (2) These error were forMCE, both with and without word models for
9 Results
The results are presented in table-3. As can be seen almost the measures gave at least moderately good results. The best results on the whole were obtained with mutual cross entropy. The JC mea-sure gave almost equally good results. Even a sim-ple measure like log probability difference gave surprisingly good results.
It can also be observed from table-3 that the size of the test data is an important factor in perfor-mance. More test data gives better results. But this does not always happen, which too is surprising. It means some other factors also come into play. One of these factors seem to whether the train-ing data for different models is of equal size or not. Another factor seems to be noise in the data. This seems to affect some measures more than the others. For example,LPDgave the worst perfor-mance when all the available test data was used. For smaller data sets, noise is likely to get isolated in some data sets, and therefore is less likely to affect the results.
Using word n-grams to augment character n -grams improved the performance in most of the cases, but for measures like JC, RE, MRE and MCE, there wasn’t much scope for improvement. In fact, for smaller sizes (100 and 200 charac-ters), word models actually reduced the perfor-mance for these better measures. This means ei-ther that word models are not very good for better measures, or we have not used them in the best possible way, even though intuitively they seem to offer scope for improvement when character based models don’t perform perfectly.
10 Issues and Enhancements
Although the method works very well even on lit-tle test and training data, there are still some is-sues and possible enhancements. One major issue is that Web pages quite often contain text in more than one encoding. An ideal language-encoding identification tool should be able to mark which parts of the page are in which language-encoding.
Another possible enhancement is that in the case of Web pages, we can also take into account the language and encoding specified in the Web page (HTML). Although it may not be correct for non-standard encodings, it might still be useful for differentiating between very close encodings like
ASCII and ISO-8859-1 which might seem identi-cal to our tool.
If the text happens to be in Unicode, then it might be possible to identify at least the encod-ing (the same encodencod-ing might be used for more than one languages, e.g., Devanagari for Hindi, Sanskrit and Marathi) without using a statistical method. This might be used for validating the re-sult from the statistical method.
Since every method, even the best one, has some limitations, it is obvious that for practical applications we will have to combine several ap-proaches in such a way that as much of the avail-able information is used as possible and the var-ious approaches complement each other. What is left out by one approach should be taken care of by some other approach. There will be some issues in combining various approaches like the order in which they have to used, their respective priorities and their interaction (one doesn’t nullify the gains from another).
It will be interesting to apply the same method or its variations on text categorization or topic identification and other related problems. The dis-tance measures can also be tried for other prob-lems.
11 Conclusion
We have presented the results about some dis-tance measures which can be applied to NLP prob-lems. We also described a method for automati-cally identifying the language and encoding of a text using several measures including one called ‘mutual cross entropy’. All these measures are ap-plied on character based pruned n-grams models created from the training and the test data. There is one such model for each of the known language-encoding pairs. The character based models may be augmented with word based models, which in-creases the performance for not so good measures, but doesn’t seem to have much effect for better measures. Our method gives good performance on a few words of test data and a few pages of training data for each language-encoding pair. Out of the measures considered, mutual cross entropy gave the best results, but RE,MRE and JCmeasures also performed almost equally well.
12 Acknowledgement
Technologies Research Centre, International Insti-tute of Information Technology, Hyderabad, India for helping in preparing the data for some of the language-encoding pairs. The comments of re-viewers also helped in improving the paper.
References
Gary Adams and Philip Resnik. 1997. A language identification application built on the Java client-server platform. In Jill Burstein and Claudia Lea-cock, editors,From Research to Commercial Appli-cations: Making NLP Work in Practice, pages 43– 47. Association for Computational Linguistics. K. Beesley. 1988. Language identifier: A computer
program for automatic natural-language identifica-tion on on-line text.
William B. Cavnar and John M. Trenkle. 1994. N-gram-based text categorization. InProceedings of SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval, pages 161–175, Las Vegas, US.
H. Combrinck and E. Botha. 1994. Automatic lan-guage identification: Performance vs. complexity. In Proceedings of the Sixth Annual South Africa Workshop on Pattern Recognition.
Ted Dunning. 1994. Statistical identification of lan-guage. Technical Report CRL MCCS-94-273, Com-puting Research Lab, New Mexico State University, March.
E. Giguet. 1995a. Categorization according to lan-guage: A step toward combining linguistic knowl-edge and statistic learning.
Emmanuel Giguet. 1995b. Multilingual sentence cate-gorisation according to language. InProceedings of the European Chapter of the Association for Compu-tational Linguistics, SIGDAT Workshop, From Text to Tags: Issues in Multilingual Language Analysis, Dublin, Ireland.
Norman C. Ingle. 1976. A language identification ta-ble. InThe Incorporated Linguist, 15(4).
Jay J. Jiang and David W. Conrath. 1997. Semantic similarity based on corpus statistics and lexical tax-onomy.
G. Kikui. 1996. Identifying the coding system and language of on-line documents on the internet. In
COLING, pages 652–657.
Bruno Martins and Mario J. Silva. 2005. Language identification in web pages. InProceedings of ACM-SAC-DE, the Document Engeneering Track of the 20th ACM Symposium on Applied Computing.
Y. K. Muthusamy, E. Barnard, and R. A. Cole. 1994. Reviewing automatic language identification. In
IEEE Signal Processing Magazine.
Patricia Newman. 1987. Foreign language identifica-tion - first step in the translaidentifica-tion process. In Pro-ceedings of the 28th Annual Conference of the Amer-ican Translators Association., pages 509–516. Arjen Poutsma. 2001. Applying monte carlo
tech-niques to language identification. InProceedings of CLIN.
P. Sibun and J. C. Reynar. 1996. Language identifi-cation: Examining the issues. InIn Proceedings of SDAIR-96, the 5th Symposium on Document Analy-sis and Information Retrieval., pages 125–135. Kranig Simon. 2005. Evaluation of language
identifi-cation methods. InBA Thesis. Universitt Tbingens. C. Souter, G. Churcher, J. Hayes, J. Hughes, and
S. Johnson. 1994. Natural language identification using corpus-based models. InHermes Journal of Linguistics., pages 183–203.
Johnson Stephen. 1993. Solving the problem of lan-guage recognition. InTechnical Report. School of Computer Studies, University of Leeds.