Speech Recognition Using a Stochastic Language Model Integrating Local and Global Constraints
6
0
0
Full text
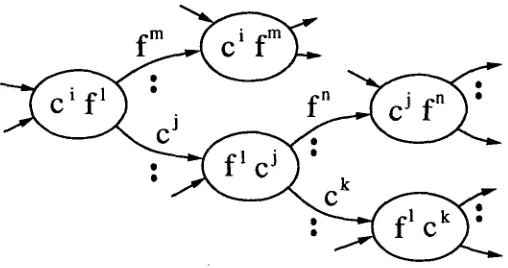
Figure



Related documents
Segmenting Speech Without a Lexicon The Roles of Phonotactics and Speech Source S E G M E N T I N G S P E E C H W I T H O U T A L E X I C O N T H E R O L E S O F P H O N O T A C T I C S A
A DISCRETE MODEL OF DEGREE CONCEPT IN NATURAL LANGUAGE A D I S C R E T E M O D E L O F D E G R E E C O N C E P T I N N A T U R A L L A N G U A G E S h i n i c h i r o K A M E I a n d K a
LINGUISTICS AND AUTOMATED LANGUAGE PROCESSING L I N G U I S T I C S A N D A U T O M A T E D L A N G U A G E P I ~ O C E S S I N G 1 0 1 T h i s p a p e r i s c o n c e r n e d w i t h n a
STATISTICAL LANGUAGE PROCESSING USING HIDDEN UNDERSTANDING MODELS S T A T I S T I C A L L A N G U A G E P R O C E S S I N G U S I N G H I D D E N U N D E R S T A N D I N G M O D E L S
A DYNAMICAL SYSTEM APPROACH TO CONTINUOUS SPEECH RECOGNITION A D Y N A M I C A L S Y S T E M A P P R O A C H T O C O N T I N U O U S S P E E C H R E C O G N I T I O N V Digalaki~f J
IMPROVED ACOUSTIC MODELING FOR CONTINUOUS SPEECH RECOGNITION I M P R O V E D ACOUSTIC M O D E L I N G FOR C O N T I N U O U S SPEECH R E C O G N I T I O N C H L e e , E GiachinP , L R R a
Recent Results from the ARM Continuous Speech Recognition Project R e c e n t R e s u l t s f r o m t h e A R M C o n t i n u o u s S p e e c h R e c o g n i t i o n P r o j e c t M a r t
A STACK DECODER FOR CONTINOUS SPEECH RECOGNITION A S T A C K D E C O D E R F O R C O N T I N O U S S P E E C H R E C O G N I T I O N 1 D e a n G S t u r t e v a n t D r a g o n Systems,
