2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN: 978-1-60595-458-5
Usage of Text Sentiment Analysis Models and Methods
in the Sociological Studies
Evgeny KOTELNIKOV
1,*and Ekaterina MITIAGINA
21Vyatka State University, Institute of Mathematics and Information Systems, 610000, Russia, Kirov,
Lenin St., 111
2
Vyatka State University, Institute of Humanities and Social Sciences, 610000, Russia, Kirov, Lenin St., 111
*Corresponding author
Keywords: Text sentiment analysis, Sentiment lexicons, Sociological studies, Supervised learning, Unsupervised learning, Vector space model.
Abstract. Natural language processing has recently become very popular in the sociological studies
due to a wide expansion of social media such as social networks, blogs, forums, etc., as well as online polls. An important direction of this area is a text sentiment analysis, used to find out people’s opinions on various actual issues. The paper deals with two methods of sentiment analysis: known support vector machine (SVM) as supervised learning and proposed lexicon-based classifier as unsupervised learning. The proposed classifier is domain-independent, does not require training data, and uses ready-made sentiment lexicons. The lexicon-based classifier is shown to exceed the SVM for small text collections. The article provides analysis of errors and offers the ways to increase classifier’s quality.
Introduction
The recent wide spread of Web 2.0 in the Internet made available huge text information arrays, which are of some interest for the sociological studies. These arrays are of interest for the sociological studies. The main source of such information is the social media – the technologies allowing users to create social networks by means of uniting of their profiles and groups, to generate and to share various content [1]. The social media platforms are social networks, blogs, forums, online newspapers, mobile apps and other services that help people communicate with each other. The user interaction may be implemented in various forms – message dialog, exchange of news and comments, rating of media content. It is important that the results of such interaction are often open and available for analysis. Another significant electronic source of information for sociologists are online polls.
In sociology the user text messages can be analyzed to study political favors, opinions about famous people and organizations, attitude towards the products of commercial companies [2]. The computer automation of such studies is needed due to the large information volume. Automatic opinion research is possible on the basis of the models and methods of text sentiment analysis or opinion mining [3]. The opinion mining allows one to recognize the sentiment expressed in the text – positive, negative, neutral or conflict.
There are two main approaches to the sentiment analysis: supervised machine learning and unsupervised methods [4, 5]. In the first approach the sentiment classifier is built based on pre-labelled text collection. Many algorithms of such classifier building are known: support vector machine, random forest, neural networks, decision trees, etc. [6, 7]. In the second approach labelled collection is not needed; the sentiment of text is determined based on other information, e.g., the sentiment lexicons [8].
described. The following section is devoted to the results and discussion of experiments. The last section consists of the conclusions and the ways of future work.
Models and Methods
Supervised Learning
In the supervised machine learning the classifier C is built [6]:
C: t S, (1) where t – a text representation model, S – a set of sentiment categories.
The classifier C is based on the training collection of text models
t1,,tn
, labelled by categories from the set S.In the paper a vector space model with TF-IDF weighting (Term Frequency – Inverse Document Frequency) is used as the text representation model [9, 10]. In this model the text is represented as a fixed-length vector, each element of which is the weight of a single word (feature):
i1, , im
,i w w
t
(2)
, 1 log
j ij
ij
N N f
w
(3)
where wij – the weight of jth word in ith text, fij – the frequency of jth word in ith text, N – the total
number of texts, Nj – a number of texts, containing jth word.
In order to build the supervised classifier, the support vector machine (SVM) as one of the most powerful machine learning methods is chosen [11, 12]. In the linearly separable case of binary classification problem this method finds an optimal separating hyperplane in m-dimensional feature space. This hyperplane is located in the middle of the distance between the closest objects of both classes (support vectors). The computation of the optimal hyperplane parameters is reduced to the finding of saddle point of the Lagrangian function:
i i i
i i
is th b
h b
h
L ,
2 1 ,
, 2
(4)
where h – normal vector of separating hyperplane, b – free term, – Lagrange multipliers vector,
S
si – sentiment categories, ti – support vectors.
In practice the objects are usually not linearly separable. In this case the regularization parameter C
is used in the SVM, and scalar product tih is replaced by nonlinear kernel function K
ti,h [13]. The most widespread kernels are:linear: K
ti h tih
, ;
polynomial: K
ti,h tih1
p;radial basis function (RBF): K
ti,h exp
tih2
.A generalization of the SVM to multiclass problem (|S| > 2) is based on the one-versus-the-rest approach [7]. At this approach |S| classifiers are built, each of which separates the objects of “its” class from others.
Sentiment Lexicon
– a number of positive words in the text t, neg – a number of negative words in the text t, d – difference threshold. Then for the classification of text t the following rules can be proposed:
if pos – neg >= d, then t has the positive sentiment;
if neg – pos >= d, then t has the negative sentiment;
if pos = 0 и neg = 0, then t has the neutral sentiment;
otherwise t has the conflict sentiment.
In addition, negations and the past tense should be taken into account [8]:
if before the sentiment word the negation or verb denoting a termination of action (“not”, “no”, “nothing”, “to lose”, “to stop”, “to cease”, etc.) is encountered at a distance of no more than r1 words, then sentiment of such word is inverted: “I don’t like”, “it ceased to be comfortable”;
if before the sentiment word the verb “to be” in the past tense is encountered at a distance of no more than r2 words, then sentiment of such word is inverted: “it was better earlier”.
The sentiment lexicon was taken from a study [14] (universal, n=3). This lexicon contains 1047 positive and 2210 negative words.
Data and Preprocessing
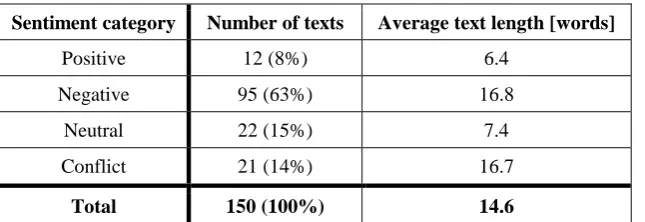
[image:3.595.140.463.447.558.2]To study the applicability of the sentiment analysis models and methods in the sociological studies some experiments with the results of the students’ online poll were carried out. In 2016 Vyatka State University and Vyatka State University of Humanities were reorganized in the form of union in a single university. In October-November 2016 the online poll of students from both universities was conducted to examine their opinions about the union. As a result, a text collection was formed which contained 150 students’ answers to a free-answer question: “Express your attitude to the uniting of the universities”. This collection was labelled with four sentiment categories: positive, negative, neutral and conflict. The characteristics of the collection are given in Table 1.
Table 1. Characteristics of text collection.
Sentiment category Number of texts Average text length [words]
Positive 12 (8%) 6.4
Negative 95 (63%) 16.8
Neutral 22 (15%) 7.4
Conflict 21 (14%) 16.7
Total 150 (100%) 14.6
All words were reduced to their normal form with the help of the morphological analyzer Mystem [15]. Thus a dictionary of the collection was formed. It consists of 703 words.
Experiments
Evaluation Metrics
To evaluate the quality of the classifiers’ results the standard sentiment analysis quality metrics were used: Accuracy (A), Precision (P), Recall (R), F1-measure (F1) [6]. Let us denote: TP – a number of texts correctly classified as belonging to the category s (true positive), FP – a number of texts incorrectly classified as belonging to the category s (false positive), FN – a number of texts incorrectly classified as not belonging to the category s (false negative), TN – a number of texts correctly classified as not belonging to the category s (true negative). Then the quality metrics with respect to category s are defined as follows:
TN FN FP TP
TN TP A
,
FP TP
TP P
,
FN TP
TP R
,
R P
PR F
2
To compute the final values, the metrics are averaged over all |S| categories (macro-averaging) [10]:
S
S
i i
av
1 P P ,
S R R
S
i i
av
1 ,
S F F
S
i i
av
1 1
1 . (6)
In the paper the F1-measure is selected as a primary metric owing to the strong imbalance of text collection (see Table 1). This metric takes into account metrics for all categories equally, regardless of the number of objects in them.
Cross-Validation and Parameter Selection
Due to the small size of text collection, the experiments were conducted with 5-fold cross-validation procedure [6, 7]. In this procedure all labelled data are randomly divided into 5 equal sized subsets. Then, at each step, one subset is used as a test set, and the classifier is trained on the basis of the remaining subsets. As a result, we have 5 metric values that are averaged to obtain the final score.
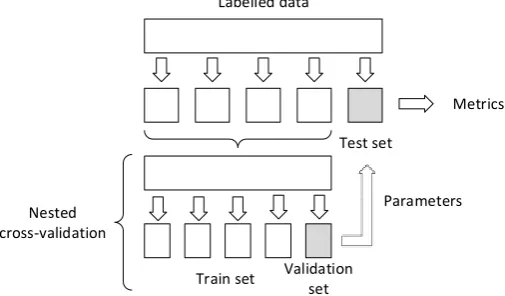
Both classifiers under consideration have several parameters. The SVM has regularization parameter C, type of the kernel and kernel parameters. The lexicon-based classifier has difference threshold d and distances r1 and r2. The tuning of classifier’s parameters on the same data on which the classifier is evaluated may lead to an overfitting and overstated scores [16]. Therefore, in our work we use a nested cross-validation. In this procedure the splitting of data into training and validation sets is used for the parameters tuning on each step (Figure 1).
Test set
Validation set Train set
Labelled data
Parameters Metrics
[image:4.595.172.425.375.523.2]Nested cross-validation
Figure 1. Nested cross-validation. One iteration of outer cross-validation (up) and one iteration of inner cross-validation (down) are shown.
As a result of the described procedure of the parameters tuning the following values were selected:
SVM-classifier: linear kernel, C = 10;
lexicon-based classifier: d = 1, r1 = r2 = 2.
Results and Discussion
The software implementation of the models and methods was made in Python 3 with the use of machine learning library scikit-learn [17].
In the experimental study the results presented in Table 2 (averaged values for 5 subsets) were obtained.
Table 2. Experimental results [%].
Classifier Accuracy Precision Recall F1-measure
SVM 71.43 54.14 43.13 43.90
Lexicon-based 71.06 57.32 67.24 58.20
As a baseline the simple classifier was used which classified all objects to the highest category (negative).
Table 2 shows that despite the minimal lag in Accuracy the lexicon-based classifier substantially exceeds the SVM in F1-measure due to Recall. At that both classifiers overcome the baseline. Let us analyze the classifiers’ quality by categories (Table 3, LB – lexicon-based classifier).
Table 3. The categories results [%].
Category
Precision Recall F1-measure
SVM LB SVM LB SVM LB
Positive 40.00 55.00 16.67 100.00 23.33 70.24
Negative 71.55 84.53 96.84 78.95 82.22 81.50
Neutral 75.00 53.10 49.00 76.00 55.38 62.03
Conflict 30.00 36.67 10.00 14.00 14.67 19.05
Average 54.14 57.32 43.13 67.24 43.90 58.20
Table 3 shows that the lag of the SVM on Recall come from the positive category. This category being the smallest in size, the supervised classifier has not enough data to learn with high quality. We should also note that the conflict category has been the most challenging for both classifiers. It is connected with the objective difficulties of recognition: for this category a human agreement degree is the lowest as a rule.
Error Analysis
After analyzing error examples for lexicon-based classifier, the following main types of errors can be identified (in brackets the percentage of a given type of errors is shown):
the lack of sentiment phrases in the sentiment lexicon (50%): “vechnaja begotnja” (“a hurried life”), “tjazheloe raspisanie” (“a difficult schedule”), “stalo bol'she rashodov” (“higher expenses”), “stipendii ponizili” (“lower scholarships”), “tratit' bol'she vremeni” (“to spend more time”);
an overall opinion belongs to one sentiment category but the text contains also an opinion of other category (17%): “horosho stalo lish' tem kto okazalsja na vershine sluzhebnoj lestnicy” (“it worked out very well only for those who found themselves at the top of the career ladder”), “mnogie otdely i uchebnye auditorii pereehali, chto vyzyvaet nebol'shie neudobstva” (“many departments and classrooms got relocated, which causes slight inconveniences”)
the subjunctive mood (13%): “hochetsja stabil'nosti, jasnosti i spokojno douchit'sja” (“I want stability, clarity and graduate without much fuss”), “luchshe by ostavili kak est'” (“it would be better to keep it the way it is”);
an improper account of negations (9%): “luchshe ne stalo” (“It did not become better”), “polozhitel'noj storony ja ne vizhu” (“I don’t see the positive side of it”);
typos (7%): “smiralas'”, “nepriemlimo”;
comparative (2%): “skoree otricatel'no, chem polozhitel'no” (“rather negative than positive”);
the sentiment in past tense (2%): “iz komfortnyh korpusov pary perenesli v uzhasnye zdanija” (“the lessons are transferred from comfortable buildings to terrible ones”).
As a result of this analysis it is possible to propose the following ways of increasing the quality of lexicon-based classifier:
the replenishment of sentiment lexicon with the widespread sentiment phrases;
the using of the aspect-based sentiment analysis methods [18];
the using of the syntax analysis for proper account of the subjunctive mood, the negations, the comparative forms and the past tense;
Conclusion
Our research shows that the unsupervised lexicon-based classifier is more efficient than the supervised SVM in sentiment analysis of the small text collections. It exceeds the SVM in F1-measure by 15%.
Advantages of lexicon-based classifier are the following: 1) high quality of analysis on small datasets; 2) no need for training data; 3) domain independence; 4) it does not require time consuming training procedure.
The error analysis allows to propose the ways to increase the classifier’s quality. Another important direction is the using of the combination of the supervised and unsupervised classifiers [20]. For example, the texts, which received different labels of SVM and lexicon-based classifier, must be sent to an additional analysis procedure (perhaps, an expert assessment).
Thus, the sentiment analysis models and methods can be used for automatic text processing in the sociological research.
Acknowledgement
This work was carried out as a part of the project «Research and Development of Sentiment Lexicons for Text Sentiment Analysis» of the Government Order No. 34.2092.2017/ПЧ of the Ministry of Education and Science of the Russian Federation (2017-2019).
The authors would like to thank Alina Glushakova and Anastasia Zakharova for provided results of online poll.
References
[1]J.A. Obar, S. Wildman, Social media definition and the governance challenge: An introduction to the special issue, Telecommunications policy. 39(9) (2015) 745-750.
[2]L. Japec et al., Big data in survey research. AAPOR task force report, Public Opinion Quarterly. 79(4) (2015) 839-880.
[3]S.M. Mohammad, Sentiment analysis: detecting valence, emotions, and other affectual states from text, Emotion Measurement. (2015).
[4]B. Liu, Sentiment analysis and opinion mining, Synthesis Lectures on Human Language Technologies. 5(1) (2012).
[5]B. Pang, L. Lee, Opinion mining and sentiment analysis, Foundations and Trends® in Information Retrieval. 2 (2008).
[6]P. Flach, Machine Learning. The Art and Science of Algorithms that Make Sense of Data, Cambridge University Press (2012).
[7]C.M. Bishop Pattern Recognition and Machine Learning, Springer (2006).
[8]M. Taboada, J. Brooke, M. Tofiloski, K. Voll and M. Stede, Lexicon-based methods for sentiment analysis, Computational Linguistics. 37(2) (2011) 267-307.
[9]P. Turney, P. Pantel, From frequency to meaning: vector space models of semantics, Journal of Artificial Intelligence Research. 37 (2010) 141-188.
[10]C.D. Manning, P. Raghavan, H. Schütze, An Introduction to Information Retrieval, Cambridge University Press (2009).
[11]V.N. Vapnik, The Nature of Statistical Learning Theory, second ed., Springer (2000).
[13]N. Cristianini, J. Shawe-Taylor, An Introduction to Support Vector Machines and Other Kernel-based Learning Methods, Cambridge University Press (2000).
[14]E.V. Kotelnikov, N.A. Bushmeleva, E.V. Razova, T.A. Peskisheva and M.V. Pletneva, Manually created sentiment lexicons: research and development, Computational Linguistics and Intellectual Technologies. 15(22) (2016) 281-295.
[15]Mystem: morphological analyzer. URL: https://tech.yandex.ru/mystem/.
[16]G.C. Cawley, N.L.C. Talbot, On over-fitting in model selection and subsequent selection bias in performance evaluation, J. Mach. Learn. Res. 11 (2010) 2079-2107.
[17]F. Pedregosa et al., Scikit-learn: machine learning in Python, J. Mach. Learn. Res. 12 (2011) 2825-2830.
[18]L. Zhang, B. Liu, Aspect and entity extraction for opinion mining, in: W.W. Chu (Ed.), Data Mining and Knowledge Discovery for Big Data: Methodologies, Challenges, and Opportunities, Springer, 2014, pp. 1-40.
[19]C. Whitelaw, B. Hutchinson, G. Chung and G. Ellis, Using the Web for language independent spellchecking and autocorrection, Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing (EMNLP’2009). 890-899.