2018 International Conference on Information, Electronic and Communication Engineering (IECE 2018) ISBN: 978-1-60595-585-8
Design and Implementation of Parallelization of BLAST
Algorithm Based on Spark
Zhen-yu LIU, Jing GAO
*, Zhi-jun SHEN and Fang ZHAO
College of Computer and Information Engineering, Inner Mongolia Agricultural University, Hohhot Inner Mongolia 010018, China
*Corresponding author
Keywords: Spark, Parallel computing, Bioinformatics, Sequence alignment, Big data, Basic Local Alignment Search Tool (BLAST).
Abstract. BLAST (Basic Local Alignment Search Tool) is a local alignment algorithm, which has high accuracy and is used widely. It can reduce the running time of program while maintaining high precision, but it has performance bottleneck and low efficiency when comparing large gene data sets. Therefore, a distributed parallel method named Spark_BLAST based on Spark was proposed. The method uses Spark memory computation to identify and divide tasks, and realizes the distributed parallel computing of the BLAST algorithm. Finally, the method was implemented on the Spark cluster with 5 nodes. Comparing with single machine shows that the speedup of Spark cluster can reach about 4 without changing the accuracy of the comparison result. The method provides an efficient alignment method for bioinformatics.
Introduction
With the development of bioinformatics, gene sequence alignment has become an indispensable part in this field. BLAST [1, 2] (Basic Local Alignment Search Tool) is one of the most popular methods for gene sequence alignment. However, with the development of high-throughput sequencing technology, a large number of gene data produced. BLAST has performance bottlenecks and low efficiency in comparing large gene data sets.
Recently, many people have improved the blast algorithm. For example, the first way is the improvement of BLAST algorithm based on GPU: Vouzis at Carnegie Mellon University designed and implemented the GPU-BLAST [3] algorithm in 2011, which achieves a three-fold acceleration ratio compared with single-machine BLAST; In 2014, the G-BLASTN [4] was proposed by K Zhao and X Chu. It supports a pipeline mode that further improves the overall performance by up to 44% when handling a batch of queries as a whole. The second way is the BLAST algorithm based on distributed design and Implementation: Matsunaga and Tsugawa implemented the CloudBLAST [5] algorithm in 2009. And the algorithm integrates MapReduce with virtual machine and virtual network, realizes the parallel computation of BLAST2. In 2014, Ming MENG implemented an efficient and reliable parallel BLAST algorithm using MapReduce computing framework based on Hadoop cluster [6]. With the wide application of BLAST, RS Neumann, S Kumar et al. developed user-friendly programs to control the visualization and analysis of BLAST output results in 2014. It provides many conveniences for users without bioinformatics background [7]. In 2017, Marcelo Rodrigo de Castro and Catherine DOS Santos Tostems designed the SparkBLAST [8], and carried out protein comparison experiments on Google and Amazon clouds, showing that SparkBLAST is faster than Hadoop. In 2018, Grzegorz M Boratyn, Jean Thierry-Mieg designed and implemented Magic-BLAST [9], which can better identify introns and is suitable for aligning long-reading gene sequences. At the same time, the speed of comparison will be improved.
computing method of BLAST based on Apache Spark was proposed. Without changing the accuracy of BLAST algorithm, it provides an efficient and convenient gene alignment method.
BLAST Algorithm and Big Data Technology
BLAST+ [10] as one of the most widely used comparison software in NCBI [11], it composed of a number of comparison algorithms, including blastn, blastp, blastx and so on. And the core algorithm of them is BLAST algorithm. BLAST is made by the Altschulis in 1990. It is a local short segment matching algorithm. The BLAST algorithm consists of two parts, part one is Building index database, the second part is to search the seed sequence and extension.
With the development of big data, Hadoop [12] has become the mainstream big data technology. It can provide distributed computing framework MapReduce and HDFS (Hadoop distributed file system). HDFS has high reliability and high fault-tolerant. It supports TB, PB level data storage. Apache Spark [13, 14, 15] is a distributed memory computing framework, It developed by the University of California, Berkeley, AMPLab. Apache Spark can share memory data by cross-acyclic graphs and memory cache mechanism. On the other hand, it supports a variety of Resource Manager, including Hadoop YARN [16] and Apache Mesos [17]. It also supports different distributed file systems such as HDFS, Cassandra [18] and OpenStack Swift.
The Design of BLAST Parallelization Method
Here is a BLAST distributed parallel computing method based on Spark cluster was presented. The method consists of two parts, which are data preparation and Spark_BLAST distributed parallel computing.
Prepare Data
When running BLAST, two input files are required: the first one is database file, It is used to building index database; the second file is a sequence alignment file, which containing a lot of sequences of nucleic acid or protein sequences.
In the experiment, the Spark cluster is made up of 1 NameNode nodes and 4 DataNode nodes. Firstly, the reference genome database should be established on the local file system of all the notes. And it is necessary to upload sequence alignment files to the HDFS distributed file system for parallel computing.
Spark_BLAST Distributed Parallel Computing
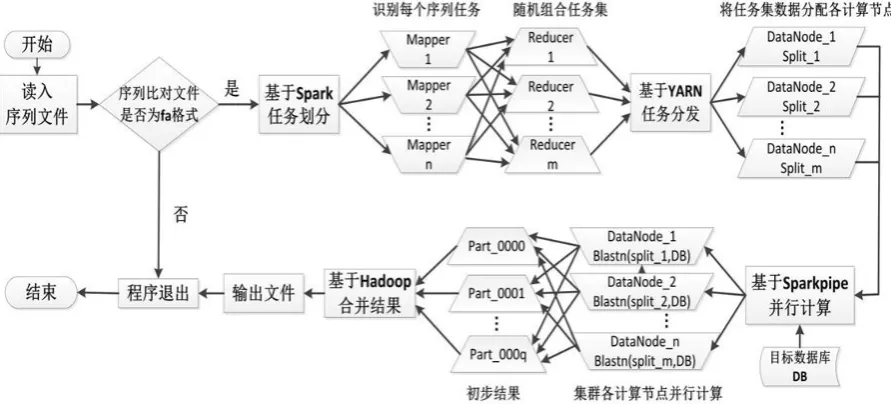
Figure 1. The flow chart of Spark_BLAST distributed parallel computing.
(1)Data partitioning stage, uploading the sequence file to HDFS through the client terminal and it will become a shared data source for each computing node. Before performing data BLAST alignment, the programming needs to start the driver of Spark application. In this experiment, the driver of Spark is programmed by Scala language.
(2)The task allocation phase, YARN was selected for resource allocation and tasking distribution. The Spark cluster will start the YARN resource manager according to the running mode specified by users, it will distribute the subtask partitioned into each DataNode nodes for further parallel computation.
(3)Parallel computing phase, according to the execution command submitted by client, Spark calls Pipeline mechanism to execute the scripts on each nodes of Spark cluster, and uses local application BLAST + to start multiple computing processes of BLAST, and processes in parallel the accepted subtasks, finally, the calculation results was written to the HDFS.
(4)Merging result, the results of distributed parallel alignment were merged by the getmerge method of Hadoop, and the results of merging were stored in the local file system.
There are several advantages in this design. Firstly, the method provides a scalable data storage, efficient calculation and convenient operation tool without changing the BLAST+ software. Secondly, users only need to submit data query files and execute commands through the terminal, and the tasks will be automatically executed by Spark cluster. Finally, the method supports all BLAST algorithms in BLAST + software, such as blastn, blastp, blastx and so on.
Design Experiment
Experimental Environment
Table 1. The table of Spark cluster virtual machine configuration information.
Nodes OS RAM CPU BLAST Hadoop Spark JDK
namenode Centos6.5 8GB 4 BLAST 2.6.0+ hadoop-2.5.2 Spark-1.2.0 jdk-7u25
node01 Centos6.5 8GB 4 BLAST 2.6.0+ hadoop-2.5.2 Spark-1.2.0 jdk-7u25
node02 Centos6.5 8GB 4 BLAST 2.6.0+ hadoop-2.5.2 Spark-1.2.0 jdk-7u25
node03 Centos6.5 8GB 4 BLAST 2.6.0+ hadoop-2.5.2 Spark-1.2.0 jdk-7u25
node04 Centos6.5 8GB 4 BLAST 2.6.0+ hadoop-2.5.2 Spark-1.2.0 jdk-7u25
Selecting Experimental Data
In order to improve the reliability and feasibility of the experiment, the human gene sequencing
published by NCBI were selected. The reference gene is
[image:4.595.86.509.348.444.2]GCF_000001405.37_GRCh38.p11_genomic.fna, and the size is 3.2GB. Different size of sequence files were selected, including 6.1 MB, 68 MB, 158.7 MB, 503.5 MB and 1024 MB. The detail information of sequence files are shown in Table 2.
Table 2. The table of sequence file.
Name Reads number Length(bp) Size(MB)
SRR4253374 32635 300 9.4
SRR7351575 341512 200 68.6
SRR7359601 793898 200 158.7
SRR7369074 2560486 200 503.5
SRR7368879 5102574 200 1024
Experiment
Single Machine Experiment. Install BLAST+ 2.6.6 on the same configuration of the virtual machine. And the index database were constructed by the command: “#makeblastdb -in DB.fa -dbtype nucl -parse_seqids -out human”. The results of single-machine experiment are shown in Table 3. Here is the command for alignment:
#blastn -db DB -outfmt 7 -num_threads 8 -query query.fasta -out output;
Table 3. The information table of Single machine BLAST experimental results
File-Name SRR4253374 SRR7351575 SRR7359601 SRR7369074 SRR7368879
Size(MB) 9.4 68.6 158.7 503.5 1024
Stand-alone
time (s) 28 193 495 1726 3344
Cluster Experiment. First, start the Spark clusters, and submit tasks to the Spark cluster for BLAST parallel alignment. The results of the cluster mode are shown in Table 4. Here is the command for alignment on Spark:
[image:4.595.93.505.573.621.2]Table 4. The information table of distributed parallel computing on Spark cluster.
File-Name SRR4253374 SRR7351575 SRR7359601 SRR7369074 SRR7368879
Size(MB) 9.4 68.6 158.7 503.5 1024
Time(s) 55 108 190 471 846
Result Analysis
[image:5.595.87.511.226.333.2]Comparing the single-machine BLAST with the parallel BLAST experiment based on Spark cluster. The detailed results of the experiment are shown in Table 5.
Table 5. The information table of experimental results of single machine and Spark cluster.
File-Name SRR4253374 SRR7351575 SRR7359601 SRR7369074 SRR7368879
Size(MB) 9.4 68.6 158.7 503.5 1024
Stand-alone
time(s) 28 193 495 1726 3344
Cluster time(s) 55 108 190 471 846
Stand-alone
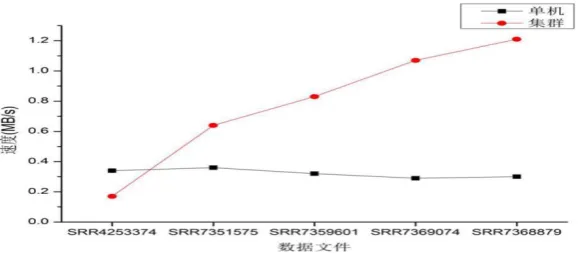
speed(MB/s) 0.34 0.36 0.32 0.29 0.30
Cluster
speed(MB/s) 0.17 0.64 0.83 1.07 1.21
Comparing the results between single-machine and cluster experiments, as it shown in Figure 2, they takes almost the same time in the beginning, But with the increase of the size of sequence files, the time-consuming of Spark cluster processing the same data set is significantly less than the single-machine experiment. The time spent on a single machine is almost 4 times than the cluster.
Figure 2. The trend diagram of Comparison between single and Spark cluster.
In the experiment, the amount of data processed per unit time is calculated and compared. Comparing the single computer with the cluster, as shown in Figure 3, the results clearly show that the speed of data processed by a single computer is in a stable state. However, with the increase of data volume, the processing speed of Spark cluster is obviously improved. It is clear that the processing speed of Spark cluster is faster than the single computer when processing large-scale data, but there is no obvious advantage for small-scale data.
[image:5.595.175.425.399.507.2] [image:5.595.153.447.617.744.2]Summary
Here are the conclusions obtained from experiments:
(1) The implementation of BLAST parallelization based on Spark greatly improves the efficiency of BLAST sequence alignment.
(2)Spark_BLAST Parallel computing has obvious advantages in dealing with large amount of data, which can greatly improve the efficiency of BLAST operation, but the advantage is not obvious when dealing with small data sets.
(3)HDFS can provide a highly reliable, expandable and highly available storage for gene data, which provides data source for data parallelization analysis.
The research combines Spark, Hadoop cluster and BLAST+ to realize the parallel computing of BLAST, and the efficiency of BLAST algorithm is greatly improved. For next step, it is necessary to consider the correlation between task allocation, parallel computing and resource scheduling. Try to improve the efficiency of the method by optimizing the performance of data distribution and resource allocation.
Acknowledgement
This research was financially supported by (1) the National Science Foundation named the research of cloud computing platform for alignment and analysis of the genome sequencing data of Mongolian plateau ruminant livestock and Construction of Variation Association Database (Project No: 61462070); (2) the doctoral research fund project of Inner Mongolia Agricultural University, (Project No: BJ09-44); (3) the Inner Mongolia Autonomous Region Key Laboratory of big data research and application of agriculture and animal husbandry.
References
[1] Pevsner J. Basic Local Alignment Search Tool (BLAST) [M]//Bioinformatics and Functional
Genomics. John Wiley & Sons, Inc. 2005:87-125.
[2] Altschul S, Gish W, Miller W, et al. Basic local alignment search tool[J]. Journal of Molecular
Biology, 1990, 215 (3): 403–410.
[3] Vouzis P D, Sahinidis N V. GPU-BLAST: using graphics processors to accelerate protein
sequence alignment[J]. Bioinformatics, 2011, 27(2):182-8.
[4] Zhao K, Chu X. G-BLASTN: accelerating nucleotide alignment by graphics processors[J].
Bioinformatics, 2014, 30(10):1384-91.
[5] Matsunaga A, Tsugawa M, Fortes J. CloudBLAST: Combining MapReduce and Virtualization
on Distributed Resources for Bioinformatics Applications[C]//IEEE Fourth International Conference on Escience, 2008. Escience. IEEE, 2009:222-229.
[6] Meng M, Gao J, Chen J J. Blast-Parallel: The parallelizing implementation of sequence
alignment algorithms based on Hadoop platform[C]//International Conference on Biomedical Engineering and Informatics. IEEE, 2014:465-470.
[7] Neumann R S, Kumar S, Shalchiantabrizi K. BLAST output visualization in the new
sequencing era.[J]. Briefings in Bioinformatics, 2014, 15(4):484-503.
[8] Castro M R D, Tostes C D S, Dávila A M R, et al. SparkBLAST: scalable BLAST processing
using in-memory operations[J]. Bmc Bioinformatics, 2017, 18(1):318.
[9] Grzegorz M Boratyn, Jean Thierry-Mieg, et al. Magic-BLAST, an accurate DNA and RNA-seq
[11] NCBI[EB/OL]. [2018-6-5]. https://www.ncbi.nlm.nih.gov/.
[12] Apache Hadoop[EB/OL]. [2018-4-20]. http://hadoop.apache.org/.
[13] Zaharia M, Xin R S, Wendell P, et al. Apache Spark: a unified engine for big data processing[J].
Communications of the Acm, 2016, 59(11):56-65.
[14] Apache Spark[EB/OL]. [2018-4-21]. http://Spark.apache.org/
[15] Yavuz B, Yavuz B, Yavuz B, et al. MLlib: machine learning in apache Spark[J]. Journal of
Machine Learning Research, 2016, 17(1):1235-1241.
[16] Vavilapalli V K, Murthy A C, et al. Apache Hadoop YARN:yet another resource
negotiator[C]//Symposium on Cloud Computing. ACM, 2013:1-16.
[17] Estrada R. The Manager: Apache Mesos[M]//Big Data SMACK. Apress, 2016.
[18] Pinheiro G, Vinagre E, Praça I, et al. Smart Grids Data Management: A Case for