International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)333
Extraction of Business Rules from Web logs to Improve
Web Usage Mining.
Sawan Bhawsar1, Kshitij Pathak2, Sourabh Mariya3, Sunil Parihar4
1,2,4
Mahakal Institute of Technology, Ujjain
3
Jawaharlal Institute of technology, Khargone
Abstract— The automatic extraction of information from
unstructured sources has opened up new avenues for querying, organizing, and analyzing data Information extraction (IE) is the task of automatically extracting structured information from unstructured and/or
semi-structured machine-readable documents. Information
Extraction systems attempt to pull out information from documents by filling out predefined templates. The information typically consists of entities and relations between entities like who did what to whom, where, when and how. In our case input is server web log files, and the extracted information is web sessions performed by users. This extracted information can be further used to improve web usage mining, like next page prediction i.e. prediction of next page accessed by the user, improve web personalization, fraud detection and future prediction accessed by user, user profiling, and also to know about user browsing behaviour. A broad goal of IE is to allow computation to be done on the previously unstructured data i.e. server web log. A more specific goal is to allow logical reasoning to draw inferences based on the logical content of the input data. Structured data is semantically well-defined data from a chosen target domain.
Keywords— Information extraction, business rules, web
usage mining, preprocessing of web log file.
I. INTRODUCTION
The explosive growth and popularity of the world-wide web has resulted in a huge amount of information sources on the Internet. However, due to the heterogeneity and the lack of structure of Web information sources, access to this huge collection of information has been limited to browsing and searching. Sophisticated Web mining applications, such as comparison shopping robots, require expensive maintenance to deal with different data formats.
To automate the translation of input pages into structured data, a lot of efforts have been devoted in the area of information extraction (IE). Unlike information retrieval (IR), which concerns how to identify relevant documents from a document collection, IE produces structured data ready for post-processing, which is crucial to many applications of Web mining and searching tools.
Formally, an IE task is defined by its input and its extraction target. The input can be unstructured documents like free text that are written in natural language or the semi-structured documents that are pervasive on the Web, such as tables or itemized and enumerated lists The extraction target of an IE task can be a relation of k-tuple (where k is the number of attributes in a record)or it can be a complex object with hierarchically organized data. For some IE tasks, an attribute may have zero (missing) or multiple instantiations in a record. The difficulty of an IE task can be further complicated when various permutations of attributes or typographical errors occur in the input documents. Programs that perform the task of IE are referred to as extractors or wrappers. A wrapper was originally defined as a component in an information integration system which aims at providing a single uniform query interface to access multiple information sources. In an information integration system, a wrapper is generally a program that “wraps” an information source (e.g. a database server, or a Web server) such that the information integration system can access that information source without changing its core query answering mechanism. In the case where the information source is a Web server, a wrapper must query the Web server to collect the resulting pages via HTTP protocols, perform information extraction to extract the contents in the HTML documents, and finally integrate with other data sources. Among the three procedures, information extraction has received most attentions and some use wrappers to denote extractor programs. Therefore, we use the terms extractors and wrappers interchangeably. Wrapper induction (WI) or information extraction (IE) systems are software tools that are designed to generate wrappers. A wrapper usually performs a pattern matching procedure (e.g., a form of finite-state machines) which relies on a set of extraction rules. Tailoring a WI system to a new requirement is a task that varies in scale depending on the text type, domain, and
scenario. To maximize reusability and minimize
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)334 The task of Web IE, that we are concerned in this paper, differs largely from traditional IE tasks in that traditional IE aims at extracting data from totally unstructured free texts that are written in natural language. Web IE, in contrast, processes online documents that are semi-structured and usually generated automatically by a server-side application program. As a result, traditional IE usually takes advantage
II.
RELATED WORK
In the past few years, many approaches to WI systems, including machine learning and pattern mining techniques, have been proposed, with various degrees of automation. In this section we survey the previously proposed taxonomies for IE tools developed by the main researchers. The Message Understanding Conferences (MUCs)[1] have inspired the early work in IE. There are five main tasks defined for text IE, including named entity recognition, coreference resolution, template element construction, template relation construction and scenario template production. The significance of the MUCs in the field of IE motivates some researchers to classify IE approaches into two different classes: MUC Approaches (e.g., AutoSolg [2], LIEP [3], PALKA [4], HASTEN [5], and CRYSTAL [6]) Hsu and Dung [7] classified wrappers into 4 distinct categories, including hand-crafted wrappers using general programming languages, specially designed programming languages or tools, heuristic-based wrappers, and WI approaches. Chang [8] followed this taxonomy and compared WI systems from the user point of view and discriminated IE tools based on the degree of automation. They classified IE tools into four distinct categories, including systems that need programmers, systems that need annotation examples, annotation-free systems and semi supervised systems.
According to Murata and Saito (2006) [9] users interests can be revealed through graph on the basis of their web surfing. In this research, authors collected the users‟
accesses “web audience measurement data” from the
modified client web log and user search keyword and graph is generated from it. Thereafter, users‟ interests are also mined from graph by applying PageRank algorithm to assign importance to accessed pages. In next step, unimportant nodes and weak edges were removed from graph. In last phase, graph is decomposed into further subgraphs, which depict the behaviour of users surfing. The usage of client log file in WUM has become ineffective or obsolete. It is important to mention that some sort of cleaning was performed by removing unimportant nodes and noisy data from log data but no other significant technique was used for more precise preprocessing. Users‟
interests can be mined in better way by grouping the interests based on page visited in a particular time interval.
Pabarskaite (2002) [10] states that preprocessing of web log file plays an important role in WUM and takes 80% of total time of web mining. The cleaning technique was presented to remove the irrelevant links from log file. A filtered web log is obtained by comparing the both raw web log and link table. For pattern visualization, web pages in link table are assigned user-friendly labels for common user.
R.Cooley et al. 99 have clarified the preprocessing tasks necessary for Web usage mining. Their approach basically follows their steps to prepare Web log data for mining [11]. Mohammad Ala‟a Al- Hamami et al described an efficient web usage mining framework. The key ideas were to preprocess the web log files and then classify this log file into number of files each one represent a class, this classification done by a decision tree classifier. After the web mining processed on each of classified files and extracted the hidden pattern they didn‟t need to analyze these discovered patterns because it would be very clear and understood in the visualization level [12].
Navin Kumar Tyagi observed some data preprocessing activities like data cleaning and data reduction. They proposed the two algorithms for data cleaning and data reduction. It is important to note that before applying data mining techniques to discover user access patterns from web log, data must be processed because quality of results was based on data to be mined [13].
III.
A
NALYSIS OFIE
T
OOLSAlthough many researchers have developed various tools for data extraction from Web pages, there has been only a limited amount of effort to compare such tools. Unfortunately, in only a few cases can results generated by distinct tools be directly comparable. Therefore, in this paper , we use the criteria of information extraction from web logs to improve web usage mining. As well as we will provide an automated system for information extraction and will also predicts next page accessed by user.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)335
A. Page Type:
We first compare the input documents that each IE system targets. As discussed above, Web pages may be structured, semi-structured or free-text Web pages according to the level of structurization. For example, manual or supervised IE systems are designed to extract information from cross-website pages. (e.g. professor data from various universities), while semi-supervised and supervised IE systems are designed primarily for extracting data from the deep Web (template pages). Thus, the latter systems depend heavily on the common template that is used to generate Web pages, while the former have included more features of the tokens (e.g. the number of characters, the fraction of upper-case letters, etc.) for inducing extraction rules. By incorporating more characteristics of the template pages, unsupervised IE systems present high-degree automation for extraction rule generalization; in contrast, the extension to non-template pages is rather limited.
B. Non-HTML Support (NHS):
The support for non-HTML inputs depends on the features or background knowledge used by the IE systems. Thus, when an IE system fails to generalize extraction rules for an IE task, we (the programmers) know how to or what to adjust the system for such a task. Most supervised systems can support non-HTML documents by modifying the generalization hierarchy (e.g. Softmealy) or adding new token features (e.g. SRV). Manual systems such as Minerva and TSIMMIS, where extraction rules are written by hand, can be adapted by the wrapper developer to handle non-HTML documents. Some wrappers, e.g. WebOQL, W4F, XWrap, and DEPTA, rely heavily on the use of DOM trees information in their systems, so they cannot support non-HTML documents, while sequence based approaches, such as IEPAD, OLERA, Road- Runner, and DeLa can be adapted to handle non-HTML documents by adding proper encoding schemes. The equivalence class technology of EXALG also supports non- HTML documents, but the success depends on token role differentiation.
V. WEB USAGE MINING
Web mining [14] is one of the major and important fields of data mining. Data mining techniques are applied [15] on contents, structures and on log files of web sites to achieve performance, web personalization and schema modifications of web sites.
Web mining is divided into three categories [16] such as Web Content Mining, Web Structure Mining and Web Usage Mining. In web content mining, we discover useful
information from the contents of web site which may include text, hyperlinks, metadata, images, videos, and audios. Search engines and web spiders are used to gather data for content mining . In web structure mining, we mine the structure of website on the basis of hyperlinks and intra-links inside and out side the web pages. In web usage mining (WUM) or web log mining, users‟ behaviour or interests are revealed by applying data mining techniques on web log file.
In web mining, web log mining is high-flying due to effective use in numerous web related application. These applications may include modification of web site design, schema modifications, web site and web server performance; improve web personalization, fraud detection and future prediction.
World Wide Web is a global village and rich source of information. Day by day number of web sites and its users are increasing rapidly. While surfing the web sites, users‟ interactions with web sites are recorded in web log file. There are three main sources to get the raw web log file such as 1.) Client Log File, 2. ) Proxy Log File and 3.) Server Log File. Usage of these sources has its own pros and cons but their importance to collect the data for WUM
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)336 The common server log file types are Access Log; Agent Log; Error Log; and Referrer Log [19]. Referrer log file contains the information about the referrer. As someone jumps from any side to www.google.com by clicking the link, referrer log file of google server will record a referrer entry that a user came from that particular web site. In this regard google has implemented the PageRank algorithm for assigning the weights to referrer sites. Error log file records the errors of web site especially when user clicks on particular link and link does not locate the promised page or web site and user receives „„Error 404 File Not Found‟‟. Error Log file is more helpful for the web page designer to optimize the web site links. Agent log file records the information about the web site users‟ browser, browser‟s version and operating system[19]. This information is again utilized by the web site designer and administrator for the analysis that users are using which specific browser to access the web site. There are number of browser available to users and each browser has its own properties and advantages to their users. Different version of same browser can different added utilities and benefits to its users, so web site can be modified accordingly. Information about the users‟ operating system is also help for designer and web site changes are made accordingly.
Access Log File is major log of web server which records all the clicks, hits and accesses made by any web site user. There are number of attributes [19] in which information is captured about users. Information about the user is then processed for WUM and user behavior and interest can be mined. Table 1 elaborates the different attributes of access log file along with their description.
There are three main types of web server log file formats available to capture the activities of user on web site [20]. All the three log files are in ASCII text format. Log files act as health monitor for the web sites and are main source of user access data and user feedbacks. These are Common Log File Format (NCSA); Extended Log Format (W3C); and IIS Log Format (Microsoft). NCSA Common log file format is most widely used to capture user data. It is standardized format but not customizable. Only fixed numbers of attributes are available for raw data of users. Figure 1 elaborates the example of common log file with basic necessary information of log entries.
W3C extended log file format is more flexible and can be customized according to requirements. Different attributes can be added to collect the user access data. Figure 2 shows a segment of W3C extended log file.\
Microsoft IIS Log file format Figure 3 is non customizable but as compare to common log file format has more attributes and record more data of users‟ accesses.
VI. PREPROCESSING
Before data mining algorithms can be used, a target data set must be assembled. As data mining can only uncover patterns actually present in the data, the target dataset must be large enough to contain these patterns while remaining concise enough to be mined in an acceptable timeframe. The following are some preprocessing tasks[]
(a) Data Cleaning: The server log is examined to remove irrelevant items.
(b) User Identification: To identify different users by overcoming the difficulty produced by the presence of proxy servers and cache.
(c) Session Identification: The page accesses must be divided into individual sessions according to different Web users.
A common source for data is a data mart or data warehouse. Pre-processing is essential to analyze the multivariate datasets before data mining. The target set is then cleaned. Data cleaning removes the observations
containing noise and those with missing data.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)337 Consequently, web log file cannot be directly used in WUM process. .
Preprocessing of log fie is complex and laborious job and it takes 80% of the total time of web usage mining process as whole. Weighing the pros and cons, we come to the conclusion that, we can not negate importance of preprocessing step in web usage mining. Paying due attention to preprocessing step, improves the quality of data, furthermore, preprocessing improves the efficiency and effectiveness of other two steps of WUM such as pattern discovery and pattern analysis.
VII. MARKOV MODEL
As discussed in the introduction, techniques derived from Markov models have been extensively used for predicting the action a user will take next given the sequence of actions he or she has already performed.
For this type of problems, Markov models are
represented by three parameters < A; S; T >, where A is the set of all possible actions that can be performed by the user; S is the set of all possible states for which the Markov model is built; and T is a |S|*|A| Transition Probability Matrix (TPM), Markov model depends on the number of previous actions used in predicting the next action. The simplest Markov model predicts the next action by only looking at the last action performed by the user.
A
First Order Markov ModelThe simplest Markov model predicts the next action by only looking at the last action performed by the user. This model is known as the first-order Markov model, each action that can be performed by a user corresponds to a state in the model.
VIII. PROPOSED METHODOLOGY.
It is proposed methodology for information extraction of our research work, in this approach we are taking server web log as input it has record about usage of particular web site like user id of user, ip address, time stamp, user agent used first task of our automated program is extract web page request by all users. Following algorithm is used to extract web sessions.
Algorithm Extracting Web pages from Web log files Input: Web Server Log File
Output: File_ of _URLs
Step1: Read LogRecord from Web Server Log File Step2: If ((LogRecord.url (http://))
then
Insert LogRecord into a File_ of _URLs // ("URL") and ("URLFrequency").
Step3: Repeat the above two steps until end of file (EOF) (Web Server Log File)
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)338 Step 4: Stop the process
Second task of our automated program is extracting user wise web session following algorithm is used to extract user wise web sessions.
Algorithm for User identification.
Identify user sessions in the log file. The pseudo code for the method is as follows.
IX. AN IMPLEMENTATION FOR ALGORITHMS: An application program is developed by us in Java using file handling feature, it takes web log text file (in common log format) and process it, performs data cleaning , user identification & session identification. Processed results are shown in fig 8.1 after user & session identification. Output of our program shows web session performed by specific user in a given time like. After user identification web request are arranged with different users.
This program has 7 tabs.
1) Home – It is starting page
2) Web site topology- This page shows topology of web site (shows no. of web pages)
3) Select web log- By using this tab user can upload web log file to be processed.
4) Processed web log- It provides web sessions as shown in fig 8.2.
5) PageRank- It shows PageRank of each web page. 6) First order Markov Model- By using this function one can automatically prepare first order Markov Model for giver web log. This tab also provides facility of prediction of next page, next page can be evaluated for each web page.
7) Transition probabilities- Transition probability matrix can be made for any web log.
Example 1. Here it is synthetic web log (in common web log file format) of web site having 7 web pages.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)339
Fig 9.1 Processed file
Fig shows web sequences of various users after user & session identification.
Program also provides web sequences regardless of the user of it. It is used to predict next page accessed by any user on particular website. This web sequences can be utilized in markov model [] to predict next page access[].
Fig 9.2 web sessions
It show web pages visited by first user are page1,
page2,page3,page4-page-1,page-5, page-6, page-7.for
[image:7.612.324.563.177.268.2]sequence {1 2 3 4 1 5 6 7 }.
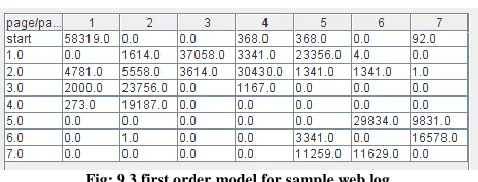
Fig: 9.3 first order model for sample web log.
Fig it is the output of automated system it shows that web log contains 58319 web page requests by all users in a given time frame. There are 7 pages and their transactions are shown in processed output snapshot, program automatically prepares first order markov model for given web log. As well as predicts next page access after each page. It can be easily understand by using snapshot of sample web log.
It shows page 1 to page 2 visits are 1614, page 1 to page 3 visits are 37058, page 1 to page 4 visits are 3341 and so on.
Prediction results snapshots are as follows:
Selected page is home.jsp and predicted page is duration.jsp (for web page 1 predicted page is web page 3)
Selected page is home.jsp and predicted page is duration.jsp (for web page 2 predicted page is web page 4)
Selected page is home.jsp and predicted page is duration.jsp (for web page 7 predicted page is web page 6)
X. CONCLUSION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 8, August 2012)340 In other words proposed system can be used with any web site with limited web pages and it will predict what would be the most clicked web page after any specific web page on particular web site.
REFERENCES
[1] Chia-Hui Chang, Mohammed Kayed, Moheb Ramzy Girgis, Khaled Shaalan. A Survey of Web Information Extraction Systems. IEEE transactions on knowledge and data engineering, pp. 01-18, TKDE-0475-1104.R3,
[2] Riloff, E., Automatically constructing a dictionary for infor-mation extraction tasks. Proceedings of the Eleventh National Conference on Artificial Intelligence (AAAI-93), pp. 811-816, AAAI Press/The MIT Press, 1993.
[3] Huffman, S., Learning information extraction patterns from examples. Connectionist, statistical, and symbolic Approaches to Learning for Natural Language Processing, Springer-Verlag, 1996.
[4] Kim, J. and Moldovan, D., Acquisition of linguistic patterns for knowledge-based information extraction. IEEE Transactions on Knowledge and Data Engineering 7(5): 713-724, 1995.
[5] Krupka, G., Description of the SRA system as used for MUC-6. Proceedings of the sixth Message Understanding Conference (MUC-6), pp. 221-235, 1995.
[6] Soderland, S., Fisher, D., Aseltine, J., and Lehnert, W., CRYSTAL:Inducing a conceptual dictionary. Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence (IJCAI), 1995.
[7] Hsu, C.-N. and Dung, M., Generating finite-state transducers for semi-structured data extraction from the web. Journal of Information Systems 23(8): 521-538, 1998.
[8] Chang, C.-H., Hsu, C.-N., and Lui, S.-C. Automatic information extraction from semi-Structured Web Pages by pattern discovery. Decision Support Systems Journal, 35(1): 129-147, 2003.
[9] Murata, T. and K. Saito (2006). Extracting Users' Interests from Web Log Data. Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence (WI 2006 Main Conference Proceedings)(WI'06) 0-7695-2747-7/06.
[10] Pabarskaite, Z. (2002). Implementing Advanced Cleaning and End-User Interpretability Technologies in Web Log Mining. 24th Int. Conf. information Technology Interfaces /TI 2002, June 24-27, 2002, Cavtat, Croatia.
[11] R. Cooley, B. Mobasher, and J. Srivastava, “Data preparation for mining World Wide Web browsing patterns,” Knowledge and Information Systems, Vol. 1, No. 1, 1999, pp. 5-32.
[12] Mohammad Ala‟a Al- Hamami et al: "Adding New Level in KDD to Make the Web Usage Mining More Efficient".
[13] Navin Kumar Tyagi, A.K. Solanki and Sanjay Tyagi: “An Algorithmic Approach to Data Preprocessing in Web Usage Mining”.International Journal of Information Technology and KnowledgeManagement, Volume 2, No. 2, July-December 2010, pp. 279-283.
[14] Tasawar Hussain, Dr. Sohail Asghar, Dr. Nayyer Masood, Web Usage Mining: A Survey on Preprocessing of web log file, Information and Emerging Technologies (ICIET), 2010
[15] Suneetha, K. R. and D. R. Krishnamoorthi (2009). "Identifying User Behavior by Analyzing Web Server Access Log File." IJCSNS International Journal of Computer Science and Network Security, VOL.9 No.4, April 2009.
[16] Alam, S., G. Dobbie, et al. (2008). Particle Swarm Optimization Based Clustering Of Web Usage Data. 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology 978-0-7695- 3496-1/08 DOI 10.1109/WIIAT.2008.292 IEEE/WIC/ACM International Confer-ence on Web.
[17] Stermsek, G., M. Strembeck, et al. (2007). A User Profile Derivation Approach based on Log-File Analysis. IKE 2007: 258-264.
[18] Muraa, T. and K. Saito (2006). Extracting Users' Interests from Web Log Data. Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence (WI 2006 Main Conference Proceedings)(WI'06) 0-7695-2747-7/06.
[19] Wahab, M. H. A., M. N. H. Mohd, et al. (2008). Data Preprocessing on Web Server Logs for Generalized Association Rules Mining Algorithm. World Academy of Science, Engineering and Technology 48 2008.
[20] Yun, L., W. Xun, et al. (2008). A Hybrid Information Filtering Algorithm Based on Distributed Web log Mining. Third 2008 International Conference on Convergence and Hybrid Information Technology 978-0-7695-3407-7/08 2008 IEEE DOI 10.1109/ICCIT.2008.39.
[21] Theint Theint Aye, Computer Research and Development (ICCRD), 2011 3rd International Conference on 11 March 2011, Volume:2 Page(s):490 – 494
[22]. M. Deshpande and G. Karypis. Selective markov models for predicting web page accesses. ACM Transactions on Internet Technology, , 2004. Page(s): - 163-184