Network Architecture Design Exploration and Simulation on High Speed
Camera System using SynDEx
Eri Prasetyo W.† Antonius Irianto. S‡ Nurul Huda∗ Djati K.∗∗ Michel P.⋆ †Doctoral Program of Information Technology
Gunadarma University, Indonesia
‡Faculty of Industrial Engineering Gunadarma University, Indonesia ∗KPK, Indonesia
∗∗Gunadarma University, Indonesia ⋆LEAD, Burgundy University, France
{eri, irianto}@staff.gunadarma.ac.id
Abstract
Nowadays, embedded multi-processor develop-ment that concentrated on vision machine, such a camera system, still has enthusiasm. This paper extracted specific multi-processor network inter-connection design features from an architectural point of view. Two types of network correlated to our design ring and coherent interconnection network had expressed. SynDEx is used to simu-late and find out the best fit architecture of multi-processor network. The extracted features will be used to modify our network design continuing our previous research result on 10.000 fps pixel 64x64 sensors.
Keywords:multi-processor, Heyrman, ring, tile, Syndex
1 Introduction
Recently improvements is continue to be made in the growing digital camera system with the CMOS technology. CMOS has the main advan-tage on ability to integrate processing element with the sensors pixel level instead of CCD. It means that the usage of CMOS has major oppor-tunity to be made easily on single chip, today we often find the words System on Chip (SoC).
As mentioned in [1], advanced in CMOS tech-nology has enable multi-processor system on chip (MPSoC) devices to be built. MPSoCs provide high computing power in an energy-efficient way, making them ideal for multimedia consumer applications. Camera system is part of its application. An MPSoC consists of Pro-cessing Elements (PE). For scalability reasons we envision that in the near future MPSoCs will include a Network-on-Chip (NoC) for communi-cation between PEs, as in example [2].
Many network PEs architecture design has been introduced by other researchers. Hakdu-ran Koc [3] proposed new method on data fetch-ing from memory in embedded multiprocessor and Daewook Kim [4] also concerned on shared memory multiprocessor. Klaus Hermann [5] proposed a new distributed embedded DRAM within multi-processor system. Amerijckx [6] introduced the architecture of a new embedded field programmable processor array (E-FPPA). The interconnection network that has been se-lected for the E-FPPA is hierarchical ring archi-tecture. Another design that show architecture in more general is proposed by Baghdadi [7]. Generic feature is depicted by its Modularity, Flexibility and Scalability.
An abstract representation of the multipro-cessor system considered in our research is ex-plained by [8]. The design has increased speed but still has a bottleneck possibility on its net-work design. This paper exhibits this problem and explores some other alternative network de-sign to overcome the bottleneck and to give other advantages.
SynDEx [9] is a free academic system level CAD tool, meaning Synchronized Distributed Execution. SynDEx is developed in INRIA Roc-quencourt, France. It supports the AAA method-ology (Adequation Algorithm Architecture) for distributed real-time processing. SynDEx pro-vides a timing graph which includes simulation results of the distributed application and thus en-ables SynDEx to be used as a virtual prototyping tool.
The extracted features of the solution will be used to modify our network design and to con-tinue our previous research result on 10.000 fps 64x64 pixel sensors.
2 Pre-considered Network Architecture Our consideration on network architecture is in-spired by Bart [8]. This multi-processor design model is shown on figure 1.
Figure 1. Modeled Architecture [8] The choice of his network of PEs is a par-tial crossbar shown on figure 2. Network that interconnects PEs is an important part of multi-processing system. Indeed, if we are not able to efficiently provide the data to processing ele-ments, or if the link between sensor and PE array is a bottleneck, the whole system will suffer from an important loss of performance.
Figure 2. Simple schema of PE [8] This is the main concern on our refinement to this modeled architecture. Some disadvantages also arise from this model. These disadvantages are :
◦ The estimation of size of silicon surface would be larger enough when using AMS 0.35 µm CMOS technology.
◦ See Figure 1, there is bottleneck possibility on the link between MUX and Network, and the link between MUX and Memory, because of the huge data transmission that fulfills the bus.
◦ Memories scheduling algorithm and PEs selec-tion algorithm would be difficult to implement because of pseudo-assembler code dependant.
◦ A way to overcome the latency problem in sin-gle bus would be the use of crossbar architec-ture. Unfortunately, crossbars are not scalable and the implementation cost is high.
3 Alternative Network Architecture To overcome disadvantages of Bart design [8], Figure 1 and figure 2, we explore some alter-native network architecture to meet the best-fit of our design. First, we explain network archi-tecture based on ring topology proposed by [6]. Second, we summarize the CAKE project fea-ture that adopting coherent interconnect network [10].
3.1 Ring
As mentioned before, Americjkx [6] has intro-duced new architecture of processors intercon-nection using ring topology. See figure 3.
Figure 3. Ring Network Architecture [6] Block (B) is composed of embedded proces-sor, its data memory, and its program memory and directly connected to the transfer controller (TC). In this architecture, each block (B) is nected to a ring of level-(i) by a transfer con-troller (TC) which handles all interface between the block and the ring network. Each level-(i) ring is connected to a level-(i-1) by an inter-ring transfer controller which manages the transfer between rings.
This kind of network design has many advan-tages. Some of its main advantages are:
◦ Ravindran et al. [11] have proven that small hierarchical rings are much more efficient than mesh of higher dimension.
◦ As mentioned in [12], one of the main advan-tages of this architecture is its high scalability.
◦ The small point-to-point connections allowing to work at a very high frequency. Moreover, these networks and their performances are well known [13]
Anyhow, the main disadvantage of this ring is that only one block can use the ring at a time. This mechanism leads to low network utilization. That is why americjkx extracted the performance comparison of token ring, slotted ring and regis-ter insertion ring.
3.2 Coherent Interconnect Network
Coherent interconnect network proposed by CAKE (Computer Architecture for a Killer Ex-perience) Project [10]. CAKE project suggests implanting a regular structure of communicat-ing tiles (the uniform clusters). Each tile can be configured to execute a set of tasks. The de-tails of a suitable inter-tile communication in-frastructure is a two-dimensional torus, see fig-ure 4. Figfig-ure 5 depicts a typical tile design. The blocks labeled SPF represent the special purpose hardware functions that are key to the compu-tational efficiency. There are multiple memory banks to increase the concurrency and improve throughput. All communication with other tiles on the chip is done by the router. The NIC is the network interface controller, responsible for the communication protocol.
Figure 4. Homogeneous Network of tiles [10] This network has some advantages such as the architecture has a high scalability of processors
Figure 5. Typical Architecture of a Tile [10]
and memories and also each tile contains a share of the CPU connected to a share of the ory that allow us to increase efficiency of mem-ory utilization. The tested process network algo-rithm had been proven using YAPI [14].
Our limited exploration has found that its dis-advantages are:
◦ The size of the tiles should be small enough so that they do not suffer too much from long wiring. But the tiles should be large enough to host a significant number of hardware func-tions to achieve high levels of computational efficiency on a wide range of applications.
◦ Need to have a good mechanism and a spe-cial treatment on spreading the traffic via NICs. This architecture has a possibility to flood the local NIC when the number of local CPU and local memory increased. Moreover, it would be a bottleneck on it.
4 Simulation Result
Each network processor elements architecture are modeled and simulated using SynDEx.
4.1 Heyrman Architecture
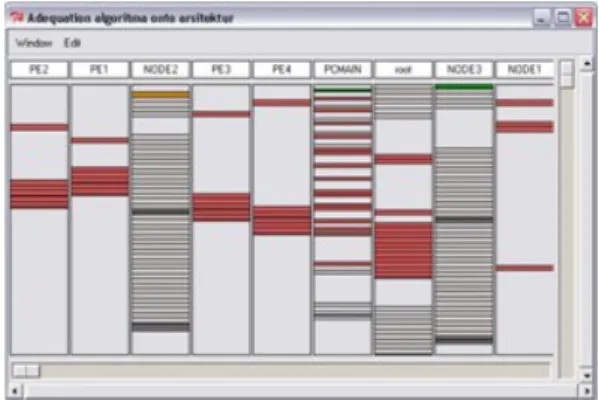
The Heyrman multi-processor network [8] as seen on figure 6 consists of input block (input memory and input from image), MUX, network, processor elements, RAM, and output memory.
After compose the Main Algorithm, the next step is make Main architecture block. It is a block where operators and communication me-dia exist, so they can communicate to each other. The algorithm and the architecture are connected by a software component.
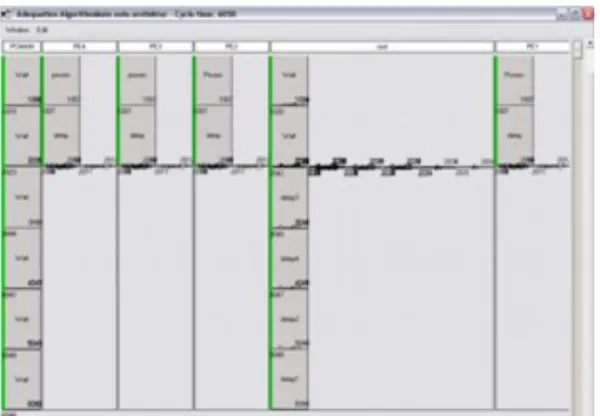
The simulation result can be seen on timing graph that shown on figure 7
Figure 6. Main Algorithm Window
Figure 7. Timing Graph of Heyrman Multipro-cessors Network Architecture
4.2 Ring Architecture
Ring multi processor network architecture is modeled as seen on figure 8. This Algorithm consists of a mux, IRTC(Inter-Ring Transfer Conrol), node that consists of processor elements and Transfer Control (TC) as seen on Figure11, and output memory. All node connected to its neighbor and IRTC in ring configuration. Opera-tors and communication media are communicat-ing in Main Architecture. Thus the timcommunicat-ing graph is shown on figure 9
Figure 8. Ring Multi Processor Network Main Algorithm
Figure 9. Ring Multi Processors Network Tim-ing Graph
4.3 Coherent Interconnection Network
This type of architecture is also known as Tile Architecture. Tile architecture is modeled us-ing 4 processor elements that will receive same amount of data sent by a router as seen on Figure 10. This router works as data transfer control for the processor elements. If the processor element is in idle condition, router will send data from memory to the processor element through a unit delay for synchronization need. The data that has been proceded is sent to register and mem-ory. The timing graph of this multi processor el-ements network simulation can be seen on figure 11.
Figure 10. Tile Multi Processor Network Main Algorithm
5 Conclusion
In this article, some multi-processor networks are described modeled and simulated using Syn-DEx software. By using this simulation method, the most important and complicated parts of multi-processor network development, such as
Figure 11. Multi Processors Network Timing Graph
the distribution of code for different proces-sors, or synchronization between computation and communication are all implemented by the SynDEx tool, and the automatic code could be generated automatically with the help of the nec-essary kernels. The Code can be used as a pro-gram to run FPGA.
References
[1] Gerard J. M. Smit Pierre G. Jansen Maarten H. Wiggers, Nikolay Kavaldjiev. Architec-ture design space exploration for streaming applications through timing analysis. Pro-ceedings of Communicating Process Ar-chitectures (WoTUG-28), pages 219–233, 2005.
[2] Pierre G. Jansen Nikolay Kavaldjiev, Ger-ard J. M. Smit. A virtual channel router for onchip networks. Proceedings of IEEE International SOC Conference, pages 289– 293, September 2004.
[3] Ehat Ercanli Ozcan Ozturk Hakduran Koc, Mahmut Kandemir. Reducing offchip memory access costs using data recompu-tation in embedded chip multiprocessors. ACM,DAC, 48, june 2007.
[4] Manho Kim Daewook Kim and Gerald E. Sobelman. Dcos: Cache embedded switch architecture for distributed shared memory multiprocessor socs. 2006.
[5] Jrg Hilgenstock Peter Pirsch Klaus Her-rmann, Sren Moch. Implementation of a multiprocessor system with distributed em-bedded dram on a large area integrated cir-cuit. Proceedings IEEE International
Sym-posium on Defect and Fault Tolerance in VLSI Systems (DFT), October 2000. [6] J.-D. Legat C. Amerijckx. A low-power
multiprocessor architecture for embedded reconfigurable systems. 2000.
[7] D. Lyonnard A.A. Jerraya A. Baghdadi, N-E. Zergainoh. Generic architeture platform for multiprocessor system-on-chip design. 2000.
[8] Renaud Schmit Laurent Letellier Thierry Colletteb Barthelemy Heyr-man, Michel Paindavoine. Smart camera design for intensive embedded computing. Real-Time Imaging, 11:282289, 2005. [9] C. Lavarenne T. Grandpierre and Y. Sorel.
Optimized rapid prototyping for real-time embedded heterogeneous multiprocessors. CODES’99, pages 74–78, 1999.
[10] Paul Stravers and Jan Hoogerbugge. Single- Chip Multiprocessing for Con-sumer Electronics, Domain-Specific Pro-cessors Systems, Architectures, Modeling, and Simulation. 2004.
[11] M. Stumm G. Ravindran. A performance comparison of hierarchical ring- and mesh-connected multiprocessor network. In Pro-ceedings of HPCA97,, pages 58–69, 1997. [12] P. K. McKinley L. M. Ni. A survey
of-wormhole routing techniques in direct net-works. IEEE Computer, pages 62–76, February 1993.
[13] W. J. Dally. Performance analysis of k-ary ncube interconnection networks. IEEE Transactions on Computers, 39(6):775– 785, June 1990.
[14] Essink G. Smits W. J. M. van der Wolf P. Brunel J.-Y. Kruijtzer W. M. Lieverse P. Vissers K. A. De Kock, E. A. Yapi: Appli-cation modeling for signal processing sys-tems. Proceedings of the 37th Design Au-tomation Conference, 2000.
![Figure 1. Modeled Architecture [8]](https://thumb-us.123doks.com/thumbv2/123dok_us/439138.2550787/2.892.114.418.236.460/figure-modeled-architecture.webp)
![Figure 4. Homogeneous Network of tiles [10]](https://thumb-us.123doks.com/thumbv2/123dok_us/439138.2550787/3.892.477.771.130.295/figure-homogeneous-network-of-tiles.webp)