Programmable Order-Preserving Secure Index for Encrypted Database Query
Dongxi Liu
Shenlu Wang
∗CSIRO ICT Centre, Marsfield, NSW 2122, Australia
{
shenlu.wang,dongxi.liu
}
@csiro.au
Abstract
The database services on cloud are appearing as an at-tractive way of outsourcing databases. When a database is deployed on a cloud database service, the data security and privacy becomes a big concern for users. A straightfor-ward way to address this concern is to encrypt the database. However, an encrypted database cannot be easily queried. In this paper, we propose an order-preserving scheme for indexing encrypted data, which facilitates the range queries over encrypted databases. The scheme is secure since it randomizes each index with noises, such that the origi-nal data cannot be recovered from indexes. Moreover, our scheme allows the programmability of basic indexing ex-pressions and thus the distribution of the original data can be hidden from the indexes.
1. Introduction
Cloud database services, such as Amazon Relational Database Service (RDS) and Microsoft SQL Azure, are ap-pearing as an attractive way for enterprises to outsource their databases. In cloud database services, the hardware and software underlying databases are shared among users. The database services allow enterprises to deploy their databases quickly without making the large investment on their proprietary hardware and software, hence reducing the total cost of ownership. Moreover, the database services on cloud can be elastic, meaning that an enterprise can dynam-ically increase or decrease the compute resources allocated to its databases according to its business requirements.
Though attractive as a new paradigm of data manage-ment, database services cannot be fully exploited if the problem of data privacy and security cannot be addressed [1, 5]. When a database is deployed into a public database service, the service provider has the complete physical con-trol over the database. The data in the database might be improperly accessed by the service provider accidentally or
∗Shenlu Wang is a vacation student from RMIT University.
intentionally, or by attackers who compromise the database service platforms. Since the database services are a kind of cloud computing services, the techniques of trusted cloud computing have the potential to be used to build trusted database services. However, there is still a gap of applying the techniques of trusted cloud computing such as [7, 15] to address the security and privacy problem in database ser-vices.
For cloud database services, a straightforward approach to addressing the security and privacy problem is to encrypt the database. By this way, the service provider or an at-tacker only can see the meaningless encrypted data. How-ever, after encrypted, a database cannot be easily queried. It is not acceptable to decrypt the entire database before per-forming each query because the decryption might be very slow for a large database and the decrypted database is again at the risk of having its security and privacy breached. Ide-ally, a query should be executed directly over the encrypted database.
A database query can be an equality query, a range query, an aggregate query or their combinations. In this paper, we focus on the problem of performing range queries on en-crypted databases. For example, a range query can be “se-lect staffs who join the company between 2000 and 2012”. For other two types of queries over encrypted databases, the equality queries are not hard to handle when a deterministic encryption scheme (e.g., AES in ECB mode) is used, since in this scheme the same plaintexts are always encrypted into the same ciphertexts, and the aggregate queries need homo-morphic encryption algorithms [11] to process the SQL op-erations SUM and AVG over encrypted databases. We also describe how to apply our method together with secure hash algorithms and homomorphic encryption algorithms to deal with all types of queries over encrypted databases.
To deal with range queries on encrypted databases, an order-preserving encryption scheme has been proposed in [2]. In this scheme, theith value in the plaintext domain is mapped to theith value in the ciphertext domain, such that the order between plaintexts is preserved between cipher-texts. To use this scheme, users need to be able to model the distributions of values in the plaintext and ciphertext
2012 IEEE Fifth International Conference on Cloud Computing
domains. However, when using cloud database services, an enterprise may not have database professionals who know the techniques [9] for data distribution modeling. In addi-tion, the scheme [2] can only deal with plaintexts in a finite domain. The cryptographic study of the order-preserving encryption scheme is done in [3].
The work [1] shows a way of building order-preserving polynomials, which are based on the polynomials proposed by Shamir for secret sharing [16]. However, the proposed mechanism is only applicable to a finite plaintext domain, where the number of plaintexts are needed to determine the range of coefficients in a polynomial. On the other hand, the evaluation results of order-preserving polynomials may reveal the distribution of plaintexts, since similar plaintexts are transformed with similar polynomials. As discussed in [2], the coupling distribution of plaintext and ciphertext do-mains might be exploited by attackers to guess the scope of the corresponding plaintext for a ciphertext.
In [8], an indexing mechanism for range queries is pro-posed. This mechanism is not strictly order preserving since two different values may be mapped into the same bucket, which is used when checking query conditions. The mecha-nism can lead to inaccuracy of query results and hence some post-processing is needed to remove unexpected query re-sults.
In this paper, we propose an order-preserving indexing scheme, which is secure and easy to use. The scheme is built over the simple linear expressions of the forma∗x+b. The form of the expressions is public, however the coef-ficientsa andb are kept secret (not known by attackers). Based on the linear expressions, the indexing scheme maps an input valuevtoa∗v+b+noise, wherenoiseis a ran-dom value. Thenoise is carefully selected, such that the order of input values is preserved. For example, suppose the linear expression is defined over integers (i.e.,a,band xare all integers), then thenoise is selected from the set
{0,1, ..., a−1}. When more input values are indexed, more noises are introduced into the result, implying that attackers cannot recover the input values from the generated indexes. Hence, our indexing scheme is information-theoretically se-cure, since attackers cannot get enough information to solve the linear equations over the input values and the generated indexes.
Our indexing scheme allows the programmability of ba-sic indexing expressions (i.e., the linear expressions). Users can make an indexing program that deals with different in-put values with different indexing expressions. On the one hand, the programmability improves the robustness of our scheme against brute-force attacks since there are more in-dexing expressions to attack. On the other hand, the pro-grammability can help decouple the distributions of input values and indexes. When a single linear expression is used to index all input values, the distribution of indexes is
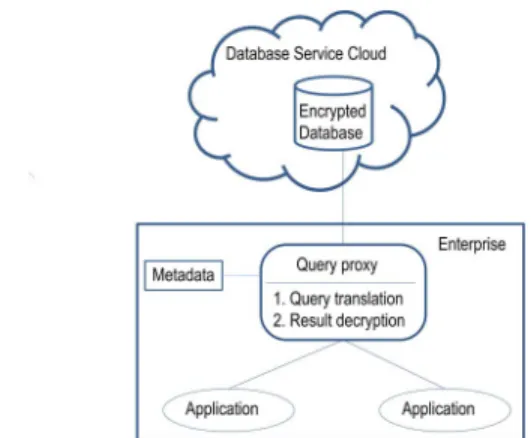
iden-Figure 1. Architecture of Querying Encrypted Databases
tical to the distribution of input values. This problem can be addressed by designing appropriate indexing programs. For example, suppose input values are uniformly distributed. Then, if the indexing program maps a bigger input value into an index that is distributed in a bigger range, then the indexes do not take the uniform distribution. Hence, the distribution of input values is not revealed by indexes.
Our indexing scheme is easier to use than that in [2], since our scheme does not need users to model data dis-tribution. Unlike the scheme in [2], our scheme does not generate the indexes with specified distribution. We only require the indexes do not reveal the distribution of input values. Our indexing scheme only depends on linear ex-pressions, which are easier for users to understand and use than polynomials used in in [1]. The usability of security mechanisms is important for them to be effectively taken in practice. In addition, unlike the schemes in [1, 2], our scheme is not an encryption scheme. It is used together with existing encryption algorithms (e.g., AES) to deal with range queries over encrypted databases. Thus, our scheme can benefit from the advances in the encryption algorithm research.
The rest of the paper is organized as follows. Section 2 describes the architecture of querying encrypted databases. Section 3 gives the details of our indexing scheme. Section 4 introduces query translation. In Section 5, we describe an prototype of the system. At last, related work and conclu-sion are given.
2. The Architecture of Querying Encrypted
Databases
In this section, we describe the architecture in which our indexing scheme is used in the queries to encrypted databases. The architecture is shown in Figure 1. In this
architecture, there is a database service provided in a pub-lic cloud, and an enterprise that deploys into the cloud a database, which is encrypted by the enterprise to protect its privacy.
To query or update the encrypted database, the enterprise has a query proxy managing the communication between the database applications and the encrypted database. When a query is received from an application, the proxy translates it into a query that can be executed directly over the en-crypted database. When a query result is returned from the database, the query proxy decrypts it before forwarding the result to the application. The query proxy depends on some metadata, such as keys and database schema, to translate queries and decrypt query results.
Briefly, when a value is put into the database, the proxy uses the indexing mechanism to generate its index and also encrypts the value with some encryption algorithm like AES. The index and the encrypted value are then stored into corresponding fields in the same record of the database. When a range query is made, the proxy calculates the index of the value in the query condition, which is then used by the database service to search indexes stored in the databases.
The order-preserving indexing mechanism reveals the order information of encrypted values. Hence, the cryp-tographic system based on order-preserving encryption or order-preserving indexing is vulnerable to plaintext-chosen attacks [2, 3]. In this architecture, the proxy is put into the administrative boundary of the enterprise. The attackers from the cloud cannot control the proxy. Hence, the attack-ers cannot recover the encrypted values by using plaintext-chosen attacks.
3. Order-Preserving Secure Indexing and Its
Programmability
There are several data types (i.e., integer, double, string, etc.) used in a database. In our work, we design the index-ing scheme primitively for numerical values, and other data types are translated into integers before indexing.
3.1 Basic Order-Preserving Indexing
Our indexing scheme is based on the linear expression a∗x+b, wherexis the input value,aandbare secret coef-ficients (only known by the query proxy in the architecture of Figure 1). The input value and coefficients can be inte-gers or real numbers. To make sure the linear expression strictly increasing, we requirea > 0in the linear expres-sion. Hence, for allv1andv2, ifv1 > v2anda >0, then
a∗v1+b > a∗v2+b.
As shown above, the basic linear expression respects the order of input values. When the outputs of the linear ex-pressions, used as indexes of the input values, are put into
the encrypted databases, the attackers there cannot break the indexes if they do not knowa,band any input values. That is, the basic indexing scheme is secure against cipher-text only attacks. Though in our threat model we do not allow attackers to choose arbitrary input values, the attack-ers may happen to know the input values of some particular indexes. At this case, they may be able to recover aand bby solving two linear equations, since the equations have only two unknownsaandb. Suppose attackers know two different input valuesv1andv2corresponding respectively to indexesi1andi2, then the following two equations can be used to recoveraandb.
a∗v1+b=i1 a∗v2+b=i2
3.2 Order-Preserving Indexing with
Ran-domness
To solve the vulnerability described above, our idea is to add some random noise to each index. That is, given two input valuesv1andv2, their indexesi1andi2will bea∗v1+
b+noise1anda∗v2+b+noise2, respectively, wherenoise1 andnoise2 are randomly sampled from some range (to be defined later) by the query proxy. Consequently, even ifv1,
v2and their indexes are known accidentally by attackers on the cloud, they still cannot have enough information (i.e., due to the random noises) to solve the following equations.
a∗v1+b+noise1=i1 a∗v2+b+noise2=i2 In the following, we describe how to determine the range of noises, such that ifv1> v2anda >0, thena∗v1+b+
noise1> a∗v2+b+noise2.
3.2.1 Randomized Order-Preserving Indexing Over
Integers
We start the definition of the noise range from a special case, building up the intuitiveness of our method. In this special case, we assume the input values and coefficients in the lin-ear expression are all integers. Supposev1andv2are two integers andv1 > v2. Then, the gap between them is at least 1, that isv1−v2≥1. We will use sensitivity to mean the least gap, as in differential privacy research [10].
To determine how much noise can be added into indexes, such that the indexes keep the order betweenv1andv2, we need to know the least gap betweena∗v1+b(denotedi1) anda∗v2+b(denotedi2). Sincev1−v2 ≥1, we have
i1−i2 = a∗(v1−v2)and hencei1−i2 ≥ a∗1and
i1 ≥ i2+a∗1. Ifnoise1 andnoise2are both randomly sampled from the range[0, a∗1)(We keep writinga∗1to manifest the sensitivity of input values in the noise range), then we havei1+noise1> i2+noise2, which holds even whennoise1is 0 (the minimum ofnoise1) andnoise2is its maximum in[0, a∗1).
For example, suppose the linear expression over integers is5∗x+ 3, and then the noise can be randomly selected from the range[0,5). Hence, the index of input value1is distributed in the range[8,13), the index of2is in[13,18), and so on.
3.2.2 Randomized Order-Preserving Indexing
As shown above, the sensitivity of input values is needed to determine the amount of noise that can be added into indexes. The following is the formal definition of sensitivity of input values.
Definition LetV be the set of all input values. The sensi-tivityofV is the minimum element in the set{|v1−v2||v1∈
V, v2∈V, v1=v2}.
By its definition, the sensitivity is always greater than 0. The sensitivity of input values is usually specific to appli-cations. For example, if the salary in a company takes the format ofd1d2d3.d4d5, wherediis a digit, then the
sensi-tivity of salary is 0.01. That is, the least salary difference of between two staffs is 0.01 in the company. For another example, if the input values in an application can only be even numbers, then the sensitivity of input values in this application is 2.
Definition Given the sensitivitysensof input valuesV, the randomized index of valuev ∈ V isa∗v+b+noise, wherea >0andnoiseis randomly sampled from the range [0, a∗sens).
For example, suppose the linear expression is7.2∗x+ 3.75, and the sensitivity of input values is 0.01. Then, the range for generating noises is[0,0.072). For two example input values2.04 and2.05, their randomized indexes are calculated by7.2∗2.04+3.75+noise1and7.2∗2.05+3.75+
noise2, and hence distributed in the ranges[18.438,18.51) and[18.51,18.582), respectively. Note that due to random noises two same values can have different indexes.
We use the notationrindexsens
[a,b](v)to represent the ran-domized index of input valuev, calculated by using the above definition. The following theorem shows that ran-domized index defined above is order-preserving, reflecting the correctness of the randomized indexing scheme.
Theorem Given the sensitivitysensof input valuesV, for allv1∈V andv2∈V, ifv1> v2, thenrindexsens[a,b](v1)>
rindexsens
[a,b](v2).
To prove this theorem, we need to show that rindexsens[a,b](v1)−rindex[sensa,b](v2) > 0. Let noise1 and
noise2 denote the noises added to the indexes of v1 and
v2, respectively. Then, our proof goal becomesa∗(v1−
v2) + noise1 − noise2 > 0. According to the defini-tion of randomized indexes, both noise1 and noise2 lie in the range [0, a∗sens). Hence, the proof goal holds if a∗(v1 −v2)−noise2 > 0. Since sens is the sen-sitivity of the input values, we have v1 −v2 ≥ sens and hence a∗(v1 −v2) ≥ a∗sens > noise2, that is,
a∗(v1−v2)−noise2>0.
In the following, we introduce a special type of random-ized indexes. In this type of indexes, the sensitivity of in-dexes is the same as that of input values. Such sensitivity-keeping indexes will make the indexing programs easier to write, as to be discussed in the next subsection.
Definition Given the sensitivitysensof input valuesV, if a >1, then the sensitivity-keeping index of valuev∈V is a∗v+b+noise, wherenoiseis randomly sampled from the range[0, a∗sens−sens].
Note that the sensitivity-keeping index of valuevis de-fined only whena >1, which ensuresa∗sens−sens>0. Consider the previous example where the linear expres-sion is 7.2∗x+ 3.75 and the sensitivity of input values is 0.01. Then, the range of noises is[0,0.072−0.01](i.e., [0,0.062]). The sensitivity-keeping index ofv is indicated by the notation skindexsens
[a,b](v). The following theorem states that the sensitivity of input values is kept by indexes.
Theorem Given the sensitivitysensof input valuesV,v1∈
V andv2∈V, ifv1−v2=sens, thenskindexsens[a,b](v1)−
skindexsens
[a,b](v2)≥sens.
For the proof of this theorem, we have skindexsens
[a,b](v1) − skindexsens[a,b](v2) = a ∗ (v1 −
v2) + noise1 −noise2 = a ∗sens +noise1 −noise2. According to the definition of skindx, we have 0≤noise1≤(a−1)∗sensand0≤noise2≤(a−1)∗sens, and hencea∗sens+noise1−noise2 ≥ sens. Since the sensitivitysens is greater than 0, the theorem also shows the order betweenv1andv2is preserved.
To keep sensitivity,skindexwithholds some noise (i.e., the amount ofsens). In the next section, we will show that skindexis always followed byrindexin an indexing pro-gram, such that there is no noise withheld from final in-dexes.
3.3 Programmability of Indexes
In this section, we describe how to compose basic index-ing expressions (skindex orrindex) into indexing pro-grams. Briefly, an indexing program allows different in-put values to be indexed by different linear indexing ex-pressions and allows indexes to be indexed again (like the 3DES algorithm, in which a ciphertext is encrypted again by DES).
I ::= rindexsens
[a,b]|S;rindexsens[a,b]
S ::= skindexsens[a,b]|ifCthenS1elseS2|S1;S2 C ::= gt(c)|ge(c)
Figure 2. Abstract Syntax of Indexing Pro-grams
The syntax of indexing programs is shown in Figure 2. An index program I is eitherrindexsens[a,b] or has the form S;rindexsens[a,b], where S is the composition of sensitivity-keeping indexing expressions. Scan be a basic sensitivity-keeping indexing expressionskindexsens
[a,b], a conditional in-dexing expression, or a sequential composition of expres-sions. In the conditional indexing expression,C means a condition, which can begt(c)orge(c), wherecis a con-stant.
The semantics of indexing programs is defined as fol-lows. Supposevis an input value. Then,I(v)means the ap-plication ofItov, generatingv’s index. IfIisrindexsens
[a,b], then I(v) = rindexsens
[a,b](v). If I isS;rindexsens[a,b], then
I(v) =rindexsens
[a,b](i), wherei =S(v). The semantics of indexing stepsSis defined inductively. IfSisskindexsens
[a,b], thenS(v) =skindexsens
[a,b](v). IfSis the conditional index-ing step, thenS(v) = S1(v) ifv makes the conditionC true; otherwise,S(v) = S2(v). The conditionC isgt(c) orge(c). The conditiongt(c)is true ifv > c, andge(c)is true ifv≥c. IfSis a sequential composition of steps, then S(v) =S2(i), wherei=S1(v).
An indexing program is said well-formed if it is order-preserving. Since in an indexing program the basic index-ing expressions skindex and rindex are already order-preserving, it is order-preserving if all conditional indexing expressions are also order-preserving. For any conditional indexing expression if C then S1 else S2, where C isgt(c)orge(c), it is order-preserving if S1(c) ≥ S2(c). This condition also makes sure there is no overlap among indexes generated byS1 andS2. Note that this order pre-serving condition can be checked by using only the program code (i.e., without using any input values).
When writing an indexing program, the argumentsens on all skindexandskindex represents the sensitivity of input values. In an indexing program that consists of a se-quence of expressions, all intermediate indexes are calcu-lated byskindex, which does not change the sensitivity of input values. Hence, programmers can use the sensitivity of input values in the whole program, easing the burden of programming.
An indexing program example is given in Figure 3. In this example, we assume the sensitivity of input values is 1. Suppose input values are from the range[0,500]and evenly
I =skindex1[3.1,14.7];S;rindex1[0.3,73]
S =if gt(1200)then skindex1[12,121.5]elseS1 S1=if gt(900)then skindex[91.2,81.7]elseS2 S2=if gt(650)then skindex[61.3,78.3]elseS3 S3=if gt(400)then skindex[41.1,65.2]elseS4 S4=if gt(280)then skindex[31.3,43.6]elseS5 S5=if gt(150)then skindex[21.5,30.1]elseS6
S6=if gt(100)then skindex1[1.8,19.7]else skindex1[1.2,3.7] Figure 3. An Indexing Program Example distributed. This indexing program first transforms the in-put values withskindex1[3.1,150], leading to intermediate in-dexes in range [14.7,1566.8] (i.e., the upper bound 1566.8 is calculated by3.1∗500+14.7+3.1∗1−1). Then, the gram divides the intermediate indexes into eight parts, pro-cessed by indexing expressions with different coefficients. At last, an randomized indexing expression is applied to generate the final indexes. In this example the indexes are not evenly distributed, since a bigger index is distributed in a bigger range.
The programmability of indexes increases the robustness of our index scheme in two aspects. First, input values can be indexed by multiple linear expressions, making brute-force attacks harder. Second, the distribution of indexes can be decoupled from the distribution of input values, making it harder to estimate the range of input values according to the positions of indexes.
The following notations will be used later. LetIndexbe an indexing program, which is used secretly by the proxy when translating queries. Then, Index(v, s) generates the index ofv by using the programIndex, with all indexing expressions in the program takingsas their sensitivity. Spe-cially,Index(v,0)means the index ofvwithout adding any noise, which the minimum index ofv.
3.4 Indexing String Input Values
In this section, we introduce how to convert a string into an integer, such that our indexing scheme can be applied. Our basic idea is to convert a string into an integer, where a character in the string has its ASCII encoding as the value of the corresponding byte in the integer. For example, “BC” is converted to 0x4243.
Strings are usually compared in the lexical order. For ex-ample, the string “BC” is greater than “ABC”. When strings are converted into integers, their order must be preserved. Hence, it is not acceptable that “BC” is converted to 0x4243 and “ABC” is converted to 0x414243, since 0x4243 is less than 0x414243. To solve this problem, our indexing scheme needs to know the maximum length of strings that will be compared. If the maximum length of input strings isl and a string has the lengthn, then(l−n)bytes of zeros will be
Figure 4. Change of Table Structures padded to the end of the converted integer.
For example, suppose l = 4. Then, “BC” is con-verted to 0x42430000 (two bytes of zeros are padded) and “ABC” is converted to 0x41424300 (one byte of zero is padded). Apparently, we have “BC” >“ABC”, and also 0x42430000>0x41424300.
4. Query of Encrypted Databases
We introduce how to perform range queries on encrypted databases, under the architecture in Figure 1. The equality and aggregate queries are also discussed.
4.1 The Basic Idea
The basic idea of performing range queries is illustrated with the following example. Suppose the database appli-cation developers have designed a database that has aStaff table, which includes only one columnSalary. When cre-ating such a table in a cloud database service, the proxy hashes the table name, such that the table name is meaning-less to attackers on cloud. For the columnSalary, the proxy actually creates two corresponding columns in the created table; their names are obtained by hashingSalaryEncand SalaryRngIdx, respectively, whereEncandRngIdxare post-fixes also applied to other columns.
When an input value from the database application is be-ing put into the encrypted table, the proxy encrypts the value with some encryption algorithms such as AES, generating the ciphertext for the SalaryEnccolumn, and also indexes the value for the SalaryRngIdxcolumn (Note that the col-umn names are hashed in the cloud database service). When the database application issues a range query on the column Salary, the proxy translates the query into a new one that se-lects the encrypted values from the columnSalaryEncwith the range condition compared on the columnSalaryRngIdx. The new query is then executed by the database service.
The basic idea also applies to equality and aggregate queries. To support equality queries, the proxy adds an-other extra column, which contains the secure hash of in-put values. Thus, the same value appears the same in this column. For example, for theSalarycolumn, another ex-tra column SalaryEqIdxis added. When inserting a value into the encrypted table, the proxy hashes the value for the column SalaryEqIdx with the secure hash algorithms like
HMACSHA1. Thus, for an equality query or a query that depends on equality comparison (e.g., a query using Group By), it will be translated to make equality comparisons on the columnSalaryEqIdx.
To support the queries involving the operations SUM and AVG, the proxy must use homomorphic encryption al-gorithms, such as [4, 13], to generate ciphertext for the SalaryEnccolumn. Thus, the aggregate operations can be performed directly on the encrypted data in theSalaryEnc column. Figure 4 summarizes the table structure seen by the database application and the table structure managed by the cloud database service, where the notationStaff repre-sents the hash of nameStaff, and similar notations are also for other names.
4.2 The Translation of SQL Statements
The queries from database applications are translated by the proxy before being executed by the cloud database ser-vice. The translation of some representative queries is in-troduced below. Assume the proxy has the keyk. We write Enc(k, v)for the encryption ofvwithk, andHash(k, v)for the secure hash ofv withk. The numeric and string data type is represented byNumandString.
4.2.1 Creation of Encrypted Databases and Tables
To create a database and a table, the database application can issue the following two statements.
create database dbname
create table tblname (colnm Type,... )
In the statement above,Typeis the data type for the col-umncolnm. The statements are translated into the following statements by the proxy. In addition, the proxy records the schema of the created table in its metadata.
create database Hash(k,dbname)
create table Hash(k,tblname)
(Hash(k,colnm+"EqIdx") String,
Hash(k,colnm+"RngIdx") Num,
Hash(k,colnm+"Enc") String,... )
That is, three columns are created for the columncolnm. The columncolnm+“EqIdx”have the type String, since its values are always hexadecimal strings generated by secure hash functions. The values of columncolnm+“RngIdx”are generated by our indexing mechanism and have the numer-ical type. The columncolnm+“Enc”for ciphertext also has the type String.
4.2.2 Insertion of Values into Tables
After a table is created, the database application can put a new record into the table by using the following statement.
insert into tblname (colnm,... ) values (v,...)
Assume the sensitivity of values in columncolnmissens, which is configured in the proxy. The proxy translates the above statement into the following one for execution. In the new statement, the valuevis hashed, indexed and encrypted for storing into different columns.
insert into Hash(k,tblname)
(Hash(k,colnm+"EqIdx"),
Hash(k,colnm+"RngIdx"),
Hash(k,colnm+"Enc"),... ) values (Hash(k,v),Index(v,sens),Enc(k,v),...)
4.2.3 Queries
A query from the database application can take the follow-ing basic form.
select colnm,... from tblname where cond If∗is used in the query (i.e., select * from ...), the proxy can replace∗with all column names according to the table schema in its metadata. For the basic query statement, the proxy translates it into the following form, where the trans-lation ofcondintocondis discussed below.
select Hash(k,colnm+"Enc"),... from Hash(k,tblname) where cond’
For the conditioncond, it is defined over the primitive logical forms colnm < c,colnm = c,colnm > c, where cis a constant from the domain of thecolnmcolumn, by using the logical connectives (i.e, and, or). When translating the conditioncond, we just need to replace each primitive logical expression with the translated one.
The condition colnm< c is translated into
Hash(k,colnm+“RngIdx”)<Index(c,0). Recall thatIndex(c,0) is the minimum index ofc. The conditioncolnm=cis sim-ply translated into Hash(k,colnm+“EqIdx”) = Hash(k,c). Assume the sensitivity of values in the colnm column is sens. Then,c+sensis the next value ofc, andcolnm> cis equivalent to the new conditioncolnm≥c+sens, which is translated into Hash(k,colnm+“RngIdx”)≥Index(c+sens,0). Note thatIndex(c+sens,0)is the minimum index ofc+sens. The keywords order by colnm and group by colnm are frequently used in queries. They are trans-lated into order byHash(k,colnm+“RngIdx”) and group byHash(k,colnm+“EqIdx”), respectively.
5. Implementation and Experiment
We implemented a prototype of our indexing scheme for querying encrypted database. In the implementation, we simulate a database service by wrapping up the Apache Derby database management system with a SOAP-based web service interface, which is accessed by the proxy to query over the encrypted database. The query proxy is also implemented as a web service, accepting SQL queries from
Figure 5. A Fragment of Encrypted Database the webs server and returning back the decrypted query re-sults. The database application is a web application, which includes the web server and browser. The web services and web server are deployed over the GlassFish 3.1 platform.
The web application is designed to manage the staffs in a company and the projects they are involved in. The database in the application includes the following two tables.
staff(id INTEGER, name VARCHAR(32), email VARCHAR(255), level INTEGER) project(id INTEGER, project VARCHAR(32),
deadline TIMESTAMP)
In the database service, the schema is expanded, with the table name and column names hashed with the HMACSHA1 algorithm. For example, in the encrypted database, the staff table has the name “9EE14475FCE3725D60410AE3A9DDA94A1CBA766E” and the id column has led to three columns
and the idEnc column has the name
“D97B7C1AB660AF36862144A51C384964873C4EF5”. To test the application, we put 200 staff records and 300 project records into the encrypted database. A fragment of the database is shown in Figure 5, where the first row is the HMACSHA1 hashes of four column names (idEnc, nameEnc,emailEncandlevelEnc) and other rows are en-crypted records. In the application, the AES algorithm is used for encryption, and the indexing programs used are different for different columns. As an example, for theid column, the following is the used indexing program, repre-sented in XML.
<indexing table="STAFF" col="ID" sens="1"> <skstep><a>2</a><b>11</b></skstep> <ifstep><gt>50</gt> <skstep><a>5</a><b>17</b></skstep> <skstep><a>3</a><b>13</b></skstep> </ifstep> <rstep><a>7</a><b>19</b></rstep> </indexing>
The query over the encrypted database is illustrated by the following example. Given a range query below, Figure 6 shows the query result returned by the database service and the decryption result generated by the proxy.
select * from staff natural join project where "deadline">’2012/6/9’ and
Figure 6. A Query Result and its Decryption
6. Related Works
The most related works include the order-preserving en-cryption scheme [2], the order-preserving polynomials [1] and the order-preserving indexing scheme [8]. In addition to the differences discussed before, the programmability of indexing expressions is a unique feature of our scheme and can improve the robustness of our scheme by indexing dif-ferent input values with difdif-ferent indexing expressions.
The work [12] uses strictly increasing functions to imple-ment order-preserving encryption. Their functions can be higher order and can be sequentially composed. However, all input values are encrypted by the same functions. These functions do not add noises into the encryption result, and hence the secret coefficients can be recovered when some pairs of plaintexts and ciphertexts are known by attackers.
The order-preserving hash functions discussed in [6] map a set of input values into a set of hash values for fast in-formation retrieval, with the hash values preserving the or-der of input values. These hash functions are not designed for protecting security. For example, there is no secret val-ues (like encryption keys) that prevent the recovery of input values from hash values.
The CryptDB [14] is a system supporting SQL queries over encrypted databases, where range queries rely on order-preserving encryption [3]. Our method can be incor-porated into such systems to process range queries.
7. Conclusion
In this paper, we proposed a method of generating order-preserving indexes for facilitating range queries over en-crypted databases. Our indexing is simple to use since it is based on linear expressions. The basic linear indexing ex-pression is information-theoretically secure since each in-dex is added with some random noise. We gave the way of controlling the amount of noises such that the random-ized indexes are still order-preserving. Our scheme is pro-grammable, meaning that the basic indexing expressions can be composed together to improve the robustness of the indexing programs and hide the distribution of input val-ues from indexes. We introduced how to apply the indexing
scheme to query encrypted databases by query translation. A prototype is implemented to demonstrate our system.
References
[1] D. Agrawal, A. E. Abbadi, F. Emekc¸i, and A. Metwally. Database management as a service: Challenges and opportu-nities. InProceedings of the 25th International Conference on Data Engineering, pages 1709–1716, 2009.
[2] R. Agrawal, J. Kiernan, R. Srikant, and Y. Xu. Order pre-serving encryption for numeric data. InProceedings of the 2004 ACM SIGMOD international conference on Manage-ment of data, SIGMOD ’04, pages 563–574, 2004. [3] A. Boldyreva, N. Chenette, Y. Lee, and A. O’Neill.
Order-preserving symmetric encryption. InProceedings of the 28th Annual International Conference on Advances in Cryptol-ogy, EUROCRYPT ’09, pages 224–241, 2009.
[4] Z. Brakerski and V. Vaikuntanathan. Fully homomorphic en-cryption from ring-lwe and security for key dependent mes-sages. InProceedings of the 31st annual conference on Ad-vances in cryptology, CRYPTO’11, pages 505–524, 2011. [5] CircleID Reporter. Survey: Cloud computing ‘no
hype’, but fear of security and control slowing adoption.
http://www.circleid.com/posts/20090226_ cloud_computing_hype_security, Feb. 2009. [6] E. A. Fox, Q. F. Chen, A. M. Daoud, and L. S. Heath.
Order-preserving minimal perfect hash functions and information retrieval.ACM Trans. Inf. Syst., 9:281–308, July 1991. [7] A. Haeberlen. A case for the accountable cloud. SIGOPS
Oper. Syst. Rev., 44:52–57, April 2010.
[8] B. Hore, S. Mehrotra, and G. Tsudik. A privacy-preserving index for range queries. InProceedings of the 30th interna-tional conference on Very large data bases, 2004.
[9] A. C. K¨onig and G. Weikum. Combining histograms and parametric curve fitting for feedback-driven query result-size estimation. InProceedings of the 25th International Conference on Very Large Data Bases, 1999.
[10] F. D. McSherry. Privacy integrated queries: an extensible platform for privacy-preserving data analysis. In Proceed-ings of the 35th SIGMOD international conference on Man-agement of data, SIGMOD ’09, pages 19–30, 2009. [11] D. Micciancio. A first glimpse of cryptography’s holy grail.
Commun. ACM, 53(3):96, 2010.
[12] G. Ozsoyoglu, D. A. Singer, and S. S. Chung. Anti-tamper databases: Querying encrypted databases. InIn Proc. of the 17th Annual IFIP WG 11.3 Working Conference on Database and Applications Security, pages 4–6, 2003. [13] P. Paillier. Public-key cryptosystems based on composite
degree residuosity classes. InProceedings of the 17th in-ternational conference on Theory and application of crypto-graphic techniques, pages 223–238, 1999.
[14] R. A. Popa, C. M. S. Redfield, N. Zeldovich, and H. Balakr-ishnan. CryptDB: protecting confidentiality with encrypted query processing. InProceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, 2011. [15] N. Santos, K. P. Gummadi, and R. Rodrigues. Towards
trusted cloud computing. InProceedings of the 2009 con-ference on Hot topics in cloud computing, 2009.
[16] A. Shamir. How to share a secret. Commun. ACM, 22:612– 613, November 1979.