Authors Ghislain A. Atemezing (EURECOM), Raphaël Troncy (EURECOM) Reviewer Fabien Gandon (INRIA)
François Scharffe (LIRMM) Franck Cotton (INSEE) Date June, 13th 2012
Reference
Version V1.2
Destination Public
F
ROM
R
AW
P
UBLISHED
D
ATA TO
I
NTERLINKED
S
EMANTIC
D
ATA
P
ROJET
D
ATA
L
IFT
De la donnée brute publiée vers la donnée sémantique interconnectée
Appel ANR CONTINT 2010 ANR-10-CORD-009
D6.2 :
TOOLS
FOR
VISUALIZING
DATA
ON
THE
SEMANTIC
WEB
Authors:
Ghislain Atemezing (EURECOM)
Raphaël Troncy (EURECOM)
Reviewer:
Fabien Gandon (INRIA)
François Scharffe (LIRMM)
Franck Cotton (INSEE)
Table of Contents
1. Introduction ... 4
2. Visual tools that operate over RDF data ... 6
2.1. Fresnel ... 6
2.2. Spark ... 7
2.3. Faceted spatial-semantic browsing widgets ... 9
2.4. Sgvizler ... 10
2.5. Map4rdf... 11
2.6. Exhibit (Simile widgets) ... 12
2.7. Linked Data API (LDA) ... 14
ELDA ... 15
PUELIA ... 16
2.8. SemanticWebImport plugin (SWImP) ... 18
3. Visual tools that operate over other structured format ... 19
3.1. Choosel ... 19
Architecture Overview ... 20
Visualization Component Architecture ... 20
3.2. Many Eyes ... 21
3.3. D3.js ... 22
3.4. Google Visualization API ... 24
3.5. Data Publica Visualization Tool ... 25
3.6. The Geoportal API ... 26
4. Criteria for choosing a visualization Tool ... 27
5. Conclusion ... 31
1.
Introduction
The goal of information visualization is to translate abstract information into a visual form that provides new insight about that information
.
One of the principles of designing information visualization is the need to present information clearly, precisely, and without extraneous or distracting clutter (Marti, 2009).For the purposes of visualization, it is useful to classify data as either quantitative or categorical. Quantitative data is defined as data upon which arithmetic operations can be made (integers, real numbers). Categorical data can be further subdivided into interval, ordinal, nominal, and hierarchical. Interval data is essentially quantitative data that has been discretized and made into ordered data (e.g., time is converted into months, quarters, and years). Ordinal data is data that can be placed in an order, but the differences among the values cannot be directly measured (e.g., hot, warm, cold, or first, second, third). Nominal data includes names of people and locations, and text. Finally, hierarchical data is nominal data arranged into subsuming groups (Marti, 2009).
Several kinds of visualization work well with at least limited amounts of nominal data. Nodes-and-link diagrams, also called network graphs, can convey relationships among nominal variables because there is no implied ordering among the children of a node. The biggest problem with network graphs is that they do not scale well to large sizes -- the nodes become unreadable and the links cross into a jumbled mess.
Category systems are the main tool for navigating information structures and organizing search results. A category system is a set of meaningful labels organized in such a way as to reflect the concepts relevant to a domain. A fixed category structure helps define the information space, organizing information into a familiar structure for those who know the field, and providing a novice with scaffolding to help begin to understand the domain. Category system structure in search interfaces is usually either flat, hierarchical, or faceted. Categories can be used for sorting search results, that is, for reordering results according to one or more attributes' values.
For nominal attributes which do not have a meaningful order, it can be more useful to provide users with a filtering function, to be used in conjunction with sorting. Filtering is the application of a category or attribute to select out from the search results only those items that meet the filtering criterion.
Activating a filter is functionally similar to navigating via a category, but differs conceptually in terms of interface design and expectations. While both perform narrowing functions, a filter is intended to be toggled on and off, to manipulate the subset of search results without disturbing the other constraints on the results, while selecting a topic category is meant to hide the other category choices and reduce the set in view.
The main idea of hierarchical faceted metadata is to build a set of category hierarchies each of which corresponds to a different facet (dimension or feature type) that is relevant to the collection to be navigated (Marti, 2009). Each facet has a hierarchy of terms associated with it. After the facet hierarchies are designed, each item in the
collection can be assigned any number of labels from the facet hierarchies. The resulting interface is known as faceted navigation, or sometimes as guided navigation. (Hearst & al, 2002.) describe faceted metadata as being composed of “orthogonal” sets of categories, meaning each category describes a different, usually independent aspect of the information items.
This document is divided in three sections: The first section describes tools that operate over RDF data. The second section revisits those tools that operate over other structured format, and the last section provides some criteria to take into account when selecting a given visualization tool, with some weight attached to each of the criterion. We end up with a summary and outlook some future work.
2.
Visual tools that operate over RDF data
2.1.
Fresnel
Fresnel (Fresnel, 2005) is a simple, browser-independent vocabulary for specifying how to display an RDF model and how to style it using existing style languages such as CSS. Fresnel is developed as an extensible ontology of core RDF display concepts.
Fresnel's design goals are to create an ontology that is:
• useful for rendering different output formats like HTML, SVG, PDF, plain text, and others,
• applicable across different RDF display paradigms, (nested box-based textual
representation à la XHTML+CSS, node-link diagram, etc.),
• built on existing Web technology, • extensible for more specialized needs, • easy to learn and use.
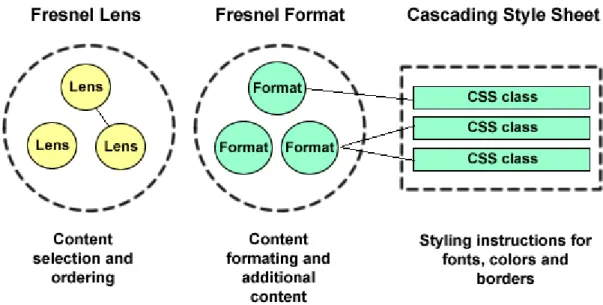
Fresnel's two foundational concepts are lenses and formats. Lenses define which properties of an RDF resource are displayed and how these properties are ordered. Fresnel formats determine how the selected properties are rendered by specifying RDF-specific formatting attributes and by providing hooks to CSS which is used to specify fonts, colors, margins, borders, and other decorative elements.
Figure 1: Fresnel overview with LFC model: Lens-Format-CSS
The Fresnel rendering process is decomposed in the following three steps (Pietriga, Bizer, Karger, & Lee, 2006):
1. Selection: the parts of the RDF graph to be displayed are selected and ordered using Fresnel lenses. The result of the selection step is an ordered tree of RDF nodes, not containing any formatting information yet.
2. Formatting: Fresnel formats are then applied to the tree, adding formatting information and hooks to CSS classes to nodes of the tree.
3. Output Generation: the result of the second step is rendered into the appropriate output format.
Possible output formats are HTML, SVG documents, XML trees, PDF documents, plain text documents and interactive rich clients such as Haystack (Haystack) . One implementation of Fresnel concepts is the IsaViz tool available at
http://www.w3.org/2001/11/IsaViz/
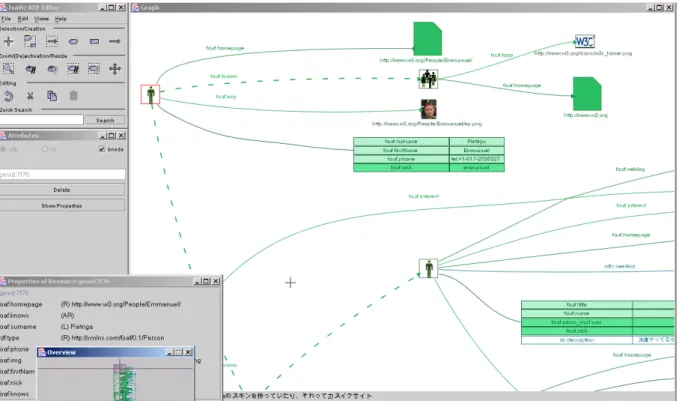
Fresnel expresses RDF presentation knowledge in a declarative way; Fresnel applications should take all formatting information into account, but are free to interpret and adapt them in a way that is appropriate with respect to their fundamental representation paradigm (e.g. nested box-based textual representation à la XHTML+CSS, node-link diagram, etc.). In other words, Fresnel does not dictate how to transform the tree resulting from the formatting step into an actual target document of the chosen output format.
Figure 2: Fresnel application to FOAF in the IsaViz implementation.
2.2.
Spark
Spark (Vrandecic & Harth, 2011)is a library that enables HTML authors to create mash-ups more easily than ever before. Using standard Web technologies like SPARQL, RDF, HTML5, and JavaScript, Spark1 can query external knowledge sources (so called triple
stores or SPARQL endpoints), and then visualize the results.
Spark requires at least JQuery version 1.1.4 to run. Once JQuery is included, there are two ways to include Spark into a website: 1) include it from AIFB Website, or 2)
1http://code.google.com/p/rdf-spark
download it and include it locally. Currently, Internet Explorer is not supported due to problems with cross-site data access.
Once included, HTML elements can be marked up for Spark to process them. The class
class="spark" should be added to the element, (e.g. like this <span class="spark">). After, some other parameters should be added to call Spark. Each parameter must only be used once. The following parameters are generally available:
• data-spark-endpoint: The URL of the SPARQL endpoint to be queried.
• data-spark-rdf: The URL of the RDF-file with the data to be queried. This can be
omitted if a SPARQL endpoint is given.
• data-spark-format: The format to use for rendering the result. Note that you can
simply use a proprietary format, by entering the URL of the JavaScript file containing the formatter. Otherwise, the simple formatter is assumed.
• data-spark-query: The SPARQL query to be executed. Note that the query does
not require to be complete, including all namespace declarations etc…
• data-spark-ns-*: Namespace declaration. Instead of * you write the namespace
prefix, the attribute value gives the actual namespace. Spark already comes with a small set of namespaces.
• data-spark-param-*: Further parameters as used by the given format.
2.3.
Faceted spatial-semantic browsing widgets
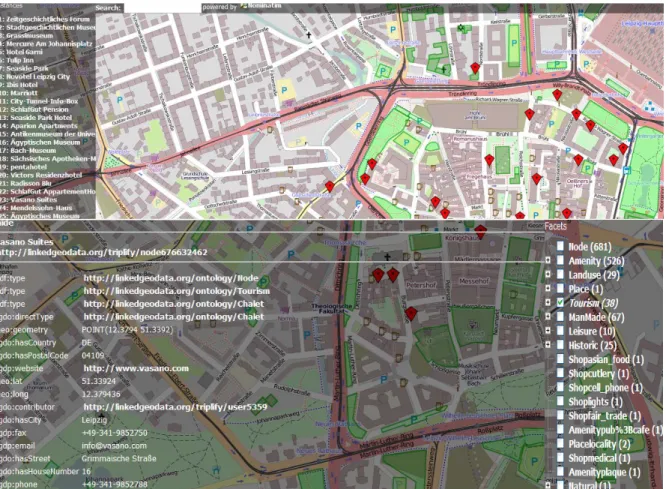
The Spatial Semantic Browsing Widgets (SSBW)2 used in the LinkedGeodata project are implemented as jQuery plugins3 and are the following three types widgets (LOD2), as depicted in Figure 4.
• Map Widget: This widget is used to display a geographical map with markers indicating the locations of points and polygons of interest. It is based on OpenLayers4 and uses the tiles rendered by OpenStreetMap5 as the default map
layer. Clicking on an object of interest will display detailed information about it.
• Facet Widget: This widget serves two purposes: The first one is to display the class and property hierarchy based on the instances in the currently visible area. The second one is to allow one to set filters on the classes and properties. Only resources that match the chosen filter criteria are displayed in the map view.
• Result Widget: The result view displays a list of the labels and most specific types of the resources visible in the map view.
Figure 4: Screenshot of the widgets in the LinkedGeoData browser.
2 https://github.com/AKSW/SpatialSemanticBrowsingWidgets 3http://docs.jquery.com/Main_Page
4http://openlayers.org 5http://openstreetmap.org
The widgets are written in JavaScript, and require a SPARQL Endpoint for data access. Ideally, such an endpoint has Cross-Origin Resource Sharing (CORS)6 enabled, which
means that a client browser may directly perform cross domain requests to it.
Furthermore, the widgets operate on local spatial regions, meaning that they do not depend on global meta-data about the data in the SPARQL endpoint. In order to synchronize the widgets, they depend on a set of model classes. The following model classes is proposed (LOD2):
• Visible Area: Objects of this class represent the state of the visible rectangular area in a map widget. As soon as the visible area changes, all three widgets will be notified. So for instance, the facet widget will send a SPARQL query in order to retrieve information about the classes and object properties in the area.
• Visible Instances: This class keeps track of the positions of resources within the visible area. The map widget will display markers for these resources.
• A Filter Configuration object represents the state of the chosen filter criteria. A change in the filter criteria causes the map view and result view to update their display.
• Class and Property Hierarchy Cache: These objects keep track of a client side snapshot of the class and property hierarchy in the SPARQL endpoint. The hierarchy in the facet view is computed from this snapshot.
• Resource-Icon and Resource-Label Map: These maps serve the purpose ofallowing lazy-loading of the icons and labels of resources.
Those widgets are deployed in the browser of the LGD project, available at the URL:
http://browser.linkedgeodata.org.
The authors report three limitations of the SSBW, in its current version:
1. On large geospatial knowledge bases, such as LinkedGeoData, the visible area must not become too large in order for the queries generated by the widgets to return quickly. For instance, if one wanted to query all airports in Germany, the SPARQL endpoint would have to scan through multiple million entities.
2. Only Virtuoso triple store is supported.
3. There is currently neither support for RDFa7 templates nor support for a personalization of the map view.
2.4.
Sgvizler
Sgvizler (Sgvizler) is a javascript which renders the result of SPARQL SELECT queries into charts or html elements. The name and tool relies on and/or is inspired by SPARQL ,
Google Visualization API (Google, Google Visualization API Reference), SPARQLer8 , Snorql (Snorql) and Spark (Vrandecic & Harth, 2011). All the major chart types offered by the Google Visualization API are supported by Sgvizler. The user inputs a SPARQL query which is sent to a designated SPARQL endpoint. The endpoint must return the results back in SPARQL Query Results XML Format or SPARQL Query Results in JSON
6http://www.w3.org/TR/cors
7http://www.w3.org/TR/xhtml-rdfa-primer/ 8 http://www.sparql.org/query.html
format. Sgvizler parses the results into the JSON format that Google prefers and displays the chart using the Google Visualization API or a custom-made visualization or formatting function.
Sgvizler needs, in addition to the Google Visualization API, the javascript framework jQuery9 to work.
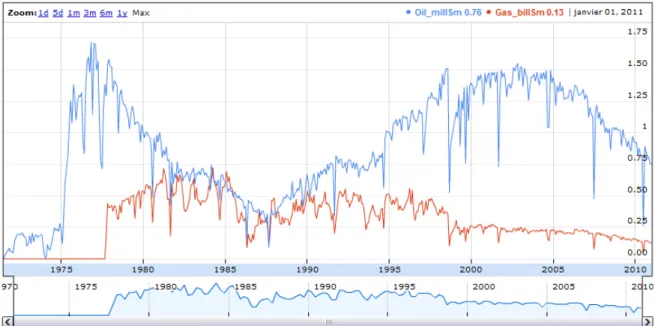
Figure 5: Timeline and line chart for a sample using Sgvizler (here oil and gas production)
2.5.
Map4rdf
Map4rdf (Map4rdf, 2011) is a mapping and faceted browsing tool for exploring and visualizing RDF datasets enhanced with geometrical Information. Map4rdf is an open source software and can be configured to be used from a SPARQL-endpoint. The geospatial aspects of the data can be modeled using either the data model from W3C Geo XG (Lieberman, 2010) or the geometrical data model proposed by GeoLinkedData (GeoLinkedData). Map4df features include Geospatial and geometrical visualization using both Google Maps and OpenStreetMap, filtering of resources and edition of a given resource.
9 htto://jquery.com
Figure 6: View of the airports in Spain, with pop-up for lat/long and more information to DBpedia.
2.6.
Exhibit (Simile widgets)
Exhibit is a lightweight framework for publishing structured data on standard web. Exhibit lets users publish richly interactive pages that exploit the structure of their data for better browsing and visualization. Such structured publishing in turn makes that data more useful to all of its consumers: individual readers get more powerful interfaces, mashup creators can more easily repurpose the data, and Semantic Web enthusiasts can feed the data to the nascent Semantic Web (Huynh, Karger, & Miller, 2007).
Exhibit’s user interface consists of two panels: the browse panel and the view panel, whose locations on the page are controlled by the author. The view panel displays a collection of items in one or more switchable views: map, timeline, table, thumbnail, and tile, etc.
Items can be presented differently in different views. Where there is little space to
render sufficient details in-place (e.g., on a map), markers or links provide affordance for
popping up bubbles containing each item’s details (e.g., map bubble). The browse panel
contains facets by which users can filter the items in the view panel. It is a conventional
dynamic query interface with preview counts.
Data creation:Exhibit can read data in its own JSON format. The items’ data is coded as an array of objects containing property/value pairs. Values can be strings, numbers, or booleans. If a value is an array, then the corresponding item is considered to have multiple values for that property. Data can be split into multiple files for convenience, and the exhibit10 just needs to load them.
The data model of each exhibit is a set of items in which each item has a type and several properties. The Exhibit abstract data model is essentially the RDF abstract data model except that property values cannot be assigned value types individually.
Lens and views: In Exhibit, lenses and views are used to display data. An Exhibit lens renders one single item while an Exhibit view renders a set of items, possibly by composing several lenses in some layout. Exhibit comes with several views: tile view, thumbnail view, tabular view, time line view, and map view. While views come pre-built
(but are configurable), lenses can be written by coding lens templates. A template is just
a fragment of HTML that can be specified in-line.
Application of Exhibit on data.eurecom.fr
Some efforts are going on the applied LD to universities in Europe. The so-called Linked Universities is an alliance of European universities engaged into exposing their public data as linked data 11. The motivation of Linked Universities is that there are only a few universities (Open, 2011), (Southampton, 2011), etc..., currently exposing their public data as linked data, using technologies such as RDF and SPARQL to give direct access to information such as their publications, courses, educational material, etc.
EURECOM12 is engaged in the process of using LD technologies to expose data in RDF and link them to other universities, in a project called data.eurecom.fr. The goal of this project is to take all this data generated by EURECOM, transform it in semantic formats (RDF), interlink it with other data (from other universities and datasets) and publish the whole as linked data in order to develop showcase applications that provide useful services to students and professors (GAZET, Atemezing, & Troncy, 2012).
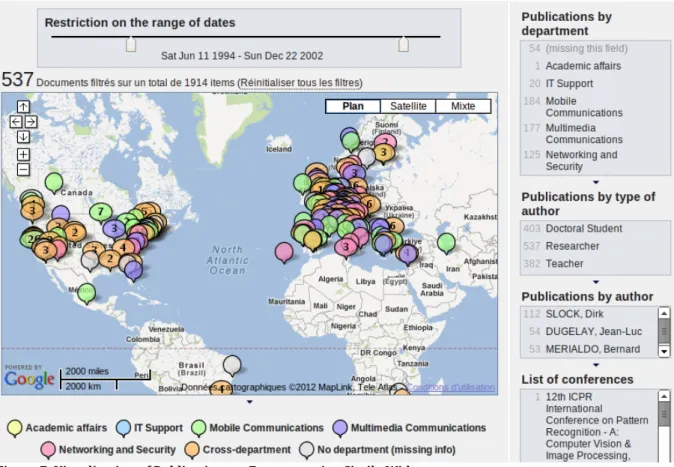
The first application built after the first generation of the triples is a map of the world with pins showing every conference where EURECOM researchers presented a paper, made easy thanks to the SIMILE Exhibit.
11http://linkeduniversities.org/lu/ 12http://www.eurecom.fr/en
Figure 7: Visualization of Publications at Eurecom using Simile Widgets
Exhibit 3.013 is the latest version of the framework, with two versions: Exhibit 3.0 Scripted Mode designed for smaller data sets, and Exhibit 3.0 Staged mode which extends the capacity of Exhibit by combining the in-browser software with greater capacity of a server-based component (with indexing capabilities from the server side).
2.7.
Linked Data API (LDA)
Linked data offers some great advantages for publishing government data. The approach makes it easy to publish information in a way that allows it to be combined with other sets of data. The benefits also arise from the semantics associated to things, common identifiers for things, from the inherent extensibility of the RDF data model, and from the publication of data in a standard format. Linked data is a great way of publishing information for diverse and distributed organizations, such as government (Tennison, 2010)
However, the RDF model, its various serializations and the SPARQL query language are foreign to the majority of developers. Those developers understandably want to be able to use the tool chains that they are familiar with to access government data. Publishing data purely as RDF, and providing access purely through SPARQL queries raises an unacceptable barrier onto the use of that data. That way there have been some works for the data.gov.uk on a way of retaining the advantages that the linked data approach gives us, while providing a much more familiar API to that data.
13https://github.com/zepheira/exhibit3/
The Linked Data API (Talis, Linked Data API, 2010), provides a configurable way to access RDF data using simple RESTful URIs that are translated into queries to a SPARQL endpoint. The API layer is intended to be deployed as a proxy in front of a SPARQL endpoint to support:(i) Generation of documents (information resources) for the publishing of Linked Data; (ii) Provision of sophisticated querying and data extraction features, without the need for end-users to write SPARQL queries and (iii) Delivery of multiple output formats from these APIs, including a simple serialization of RDF in JSON syntax.
ELDA
Elda (Epimorphics) is a java implementation of the LDA by Epimorphics. Elda comes with some pre-built samples and documentation, which allows us to build the specification to leverage the connection between the back-end (data in the triple store) and the front-end (visualizations for the user). The API layer helps to associate URIs with processing logic that extract data from the SPARQL endpoint using one or more SPARQL queries and then serialize the results using the format requested by the client. A URI is used to identify a single resource whose properties are to be retrieved or to identify a set of resources, either through the structure of the URI or through query parameters.
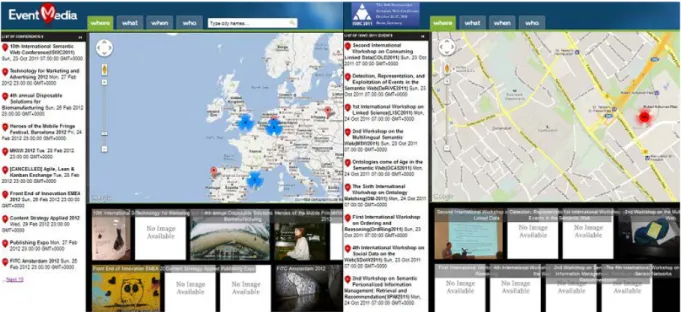
Application of Elda on EventMedia and Confomaton
In the EventMedia project14, we intend to develop an event-based approach for users to explore, annotate and share events through different media. The overall goal of EventMedia is to provide a web-based environment that allows users to discover meaningful, surprising or entertaining connections among events (Raphaël Troncy, 2010). The project uses a knowledge base of events from event directories linked to the LOD cloud, in conjunction with an event ontology.
Confomaton (Khrouf, Atemezing, Rizzo, Troncy, & Steiner, 2012) is a semantic web application that aggregates and reconciles information such as tweets, slides, photos and videos shared on social media that could potentially be attached to a scientific conference. The main demonstrator is available at
http://eventmedia.eurecom.fr/confomaton reflecting the up-to-date conferences
coming from Lanyrd feeds. A second demonstrator corresponding to the archived ISWC 2011 conference is available at http://eventmedia.eurecom.fr/iswc2011.
The user interface for the abovementioned demonstrators is built around four perspectives (tabs in the UI) characterizing an event: (i) Where does the event take place? , (ii) What is the event about?, (iii) When does the event take place?, and finally (iv) Who are the participants of the event?. Those four perspectives correspond to views in the Confomaton API configuration.
14http://eventmedia.cwi.nl/
Figure 8: View of events rendered by the Elda API for EventMedia and Confomaton
PUELIA
Puelia (Talis, Puelia, 2011) is a PHP implemention of the Linked Data API specification. It is an application that handles incoming requests by reading rdf/turtle configuration files (in /api-config-files/) and converting those requests into SPARQL queries which are used to retrieve RDF data from SPARQL endpoints declared in the configuration files. The RDF data is then served up in a number of format options, including turtle, rdf/xml and "simple" json and xml formats.
The configuration defines a set of URI patterns (API endpoints) each of which maps on to the queries that are used to construct the list, which is then formatted as required. For each request, the middleware: selects some a page-worth of resources that should be viewed; views some set of properties of those resources to construct an RDF graph formats the RDF graph in the required serialization.
The API configuration itself is done using RDF and specifies both the API endpoints themselves and the way in which the RDF properties that it exposes are mapped onto JSON properties or XML elements. Most of the time, the configuration uses the same kind of dot-notation property path syntax as is used in the URI parameters. For example, the endpoint based on constituency name in education.data.gov.uk is specified using this sample below: spec:schoolsByConstituencyName a api:ListEndpoint ; api:uriTemplate "/education/api/school/constituency-name/{constituency}" ; api:selector [ api:parent spec:schoolsSelector ; api:filter "parliamentaryConstituency.label={constituency}" ] ; api:defaultViewer spec:viewerLocation
spec:schoolsSelector a api:Selector ; api:filter "type=School&establishmentStatus.label=Open" spec:viewerLocation a api:Viewer ; api:name "location" ; api:properties "label,uniqueReferenceNumber,establishmentNumber,typeOf" Application of Puelia in Library Linked Data
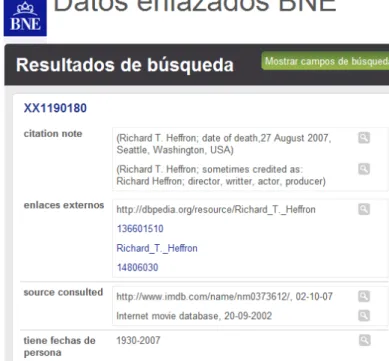
The project in Spain datos.bne.es aims at publishing works in Libraries as Linked Data. The source data is MARC21 and highly specialized library models (FRBR, ISBD) and multilingualism with IFLA. As from today, they have exposed 3,9 million bibliographical records using authorities; 4,2 million authority records: persons, entities, congresses, etc. The authors reuse the IFLA vocabulary-based ontology15. The results 60 million triples are linked with other sources (VIAF, SUDOC, GND, LIBRIS Sweden, DBPedia). The implementation of the frontend is based on the Puelia implementation of the LDA. The figure below shows the view of the authors (view: "persons" ) of the frontend at
http://datos.bne.es/frontend/persons.
Figure 9: A Puelia application in the data.bne.es for list of authors
15 http://iflastandards.info/ns/fr/
2.8.
SemanticWebImport plugin (SWImP)
The SemanticWebImport plugin (SWImP)16 is intended to allow the import of semantic data into Gephi17. The imported data are obtained by processing a SPARQL request on the semantic data (Wimmics & Dream, 2011). The data can be accessed locally (using the Corese engine) or remotely through REST and SOAP SPARQL. As for the REST endpoint, the resulting graph is built from the result returned by the endpoint.
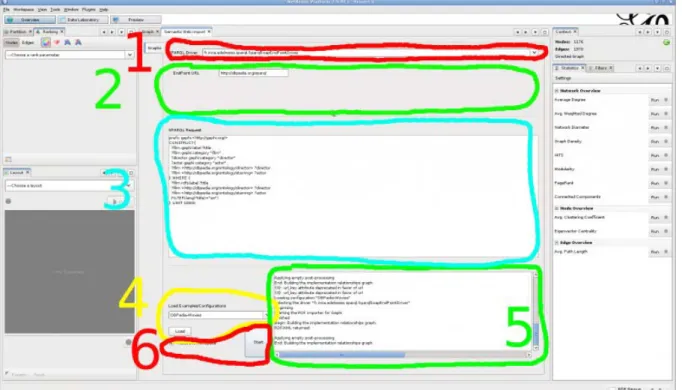
The User interface of the SemanticWebImport plugin is made of the following parts (see Figure 10):
• The selector for the SPARQL driver to be used with three types of access (i)
access to local data through the Corese engine; (ii) access to a remote REST SPARQL endpoint; (iii) access to a remote SOAP SPARQL endpoint.
• The parameters associated which each driver
• The SPARQL editor to enter a SPARQL CONSTRUCT that extract the data used to
build the graph.
• The selector for preset examples and the load button to activate them; • A log window for tracking events and errors;
• The start button and a checkbox to select whether the current workspace must
be cleaned before starting to build the graph from the result of the SPARQL request.
Figure 10: The description of the SemanticWebImport plugin:
http://wiki.gephi.org/index.php/SemanticWebImport
16https://gephi.org/plugins/semanticwebimport/ 17https://gephi.org/
3.
Visual tools that operate over other structured format
In this section, we describe also visualization tools that natively does not take as input RDF for two reasons:• those tools are relatively “popular” for analyzing data exposed by the
government and agencies (most of them in xls, csv) as they quickly make it easy to the users to build chart maps and compare with other datasets. One widely application is in the data journalism18 where facts are analyzed by those tools without waiting for the semantic publication of the data
• Also these tools have many options for visualizing data and are not totally
adapted in the Semantic community.
3.1.
Choosel
Choosel (Grammel & Storey, 2010) is built on top of GWT19 and the Google App Engine20 (the backend can be modified to run on any servlet container). It is a research
prototype21. The current limitations are:
• Small number of data items (up to several thousand rows with ~1000 visible
items / visualization). If larger data sets should be analyzed, the server part of Choosel can be extended to perform an initial automatic analysis or to sample the data.
• Exploration of static, read-only data. Choosel assumes that the data does not
change, and that it cannot be modified.
• Firefox 3.5+, Chrome 4+, and Safari 5+ are supported. There are problems
with the CSS rendering in Internet Explorer and older browser. Choosel also depends on fast JavaScript engines.
• Designed for mouse interaction and full screen windows on larger monitors (1280x1024). Touch interaction (e.g. iPad) is different in that hovering (and thus highlighting and tooltips) is difficult, and occlusion is problematic. Also, multitouch interaction is not supported. Similarly, small screen devices (e.g. smartphones) are unsuitable for Choosel.
18http://datajournalismhandbook.org/
19https://developers.google.com/web-toolkit/ 20https://developers.google.com/appengine/ 21http://code.google.com/p/choosel/
Architecture Overview
Figure 11: Architecture Overview of Choosel.
The client-side framework facilitates the interaction with visualization components, which can be wrappers around third party components and toolkits such as the Simile Timeline , Protovis and FlexViz. Choosel can integrate components developed using different technologies such as Flash and JavaScript.
Choosel provides several services such as view coordination and configuration, a desktop, undo/redo management, data management, etc. to make development of multi-view visualization environments easy.
Visualization Component Architecture22
The Choosel visualization component architecture separates the core functionality (which is required to use Choosel visualizations in GWT) from the workbench functionality. The visualizations are extracted into separate visualization modules. The architecture consists of three main components:
• Core module: The choosel.core module contains the core functionality that is
required by Choosel visualizations. This includes the resource (i.e. data) framework, the management of visualization states (e.g. data, highlighting, selection), the visualization component API, and also more general services such as logging (which wraps gwt-log). The choosel.core module needs to be inherited by any GWT module that uses Choosel, whether it is a visualization component, a GWT application or a Choosel workbench.
• Visualization modules: Visualization modules provide one or more
visualization components that implement the Choosel visualization component API. They can wrap around other libraries, e.g. GWT modules, JavaScript
22Note: Please note that while the modularization itself is complete, the visualization component API is
visualization toolkits, or Flash widgets. Choosel provides several visualization modules (map, timeline, text, chart, and graph) that can be used right away.
• Workbench module: The choosel.workbench module provides the persistence
and sharing facilities as well as the visualization workspace.
This separation of concerns makes reusing and extending Choosel easier. It enables three ways to leverage Choosel in your own projects:
• Developing your own visualization components: It is possible to implement
visualization components that adher to the Choosel visualization component API. These visualization components can then be used by yourself and others to take advantage of Choosel features such as management of view synchronization, management of selections, and support for hovering and details on demand.
• Using Choosel visualization components in a GWT application: You can use
one or several Choosel visualization components as widgets in an GWT application to visualize data.
• Creating a Choosel-based workbench: You can extend the whole Choosel
framework to develop your own visualization workbench, for example for a specific application domain.
Figure 12:A screenshot of a mash-up of the earthquakes with more than 1,000 casualties since 190023
3.2.
Many Eyes
Many Eyes (IBM, 2010) is a website that provides means to visualize data such as numbers, text and geographic information. It provides a range of visualizations including unusual ones such as “treemaps” and “phrase trees”. All the charts made in Many Eyes are interactive, so it is possible to change what data is shown and how it is
displayed. Many Eyes is also an online community where users can create groups (such as “Iraq War” or “OECD Factbook 2007”) to organize, share and discuss data visualizations. Users can also comment on visualizations made by others, which is a good way to improve their work. The authors claim that it is useful because it users can build quick and easily visualizations from their own data, with the possibility to share them. is quick and easy to make and share great looking and fun to use visualizations from your own data. Data input formats are XLS, Plain text and HTML. The output formats are PNG or embeddable.
However, using Many Eyes make public your data and the visualizations created with it. The license is proprietary of IBM.
Figure 13: View of the repartition of the financial resources in India
3.3.
D3.js
D3.js (Bostock, 2012) is a JavaScript library for manipulating documents based on data. D3 uses HTML, SVG and CSS. D3 combines powerful visualization components24 ,
plugins25 and a data-driven approach to Document Object Model (DOM) manipulation.
D3 solves problems of efficient manipulation of documents based on data. Thus, avoids proprietary representation and affords flexibility, exposing the full capabilities of web standards such as CSS3, HTML5 and SVG. D3 supports large datasets and dynamic behaviors for interaction and animation.
24https://github.com/mbostock/d3/wiki/API-Reference 25https://github.com/d3/d3-plugins
D3 intention is to replace gradually Protovis26, which is another tool to build customs
visualizations in the browser, created by the same authors and which is no longer under active development. Although D3 is built on many of the concepts in Protovis, it improves support for animation and interaction.
Where D3 and Protovis differ is the type of visualizations they enable and the method of implementation. While Protovis excels at concise, declarative representations of static scenes, D3 focuses on efficient transformations: scene changes. This makes animation, interaction, complex and dynamic visualizations much easier to implement in D3. Also, by adopting the browser’s native representation (HTML & SVG), D3 better integrates with other web technologies, such as CSS3and other developer tools27.
Usage of a d3.js library: the case of LOV datasets.
LOV objective is to provide easy access methods to this ecosystem of vocabularies, and in particular by making explicit the ways they link to each other and providing metrics on how they are used in the linked data cloud, help to improve their understanding, visibility and usability, and overall quality. LOV is the output of the DataLift project attached to the Work package 2: "Building a catalogue of ontologies".
The LOV dataset (Pierre-Yves Vandenbussche, 2011) contains the description of RDFS vocabularies or OWL ontologies used or usable by datasets in the Linked Data Cloud. Those descriptions contain metadata either formally declared by the vocabulary publishers or added by the LOV curators. Beyond usual metadata using Dublin Core, voiD, or BIBO, new and original description elements are added, using the VOAF vocabulary to state how vocabularies rely on, extend, specify, annotate or otherwise link to each other. Those relationships make the LOV dataset a growing ecosystem of interlinked vocabularies supported by an equally growing social network of creators, publishers and curators.
26http://mbostock.github.com/protovis/
Figure 14: LOV datasets visualization uses circle packing of d3.js, specifically the protovis-v03.2.js library; now integrated in d3.js.
3.4.
Google Visualization API
The Google Visualization API establishes two conventions to expose data and visualize it on the web (Tetherless, 2010)
1. a common interface to expose data on the web. 2. a common interface to provide data to visualizations.
Because the Google Visualization API provides a platform that can be used to create, share and reuse visualizations written by the developer community at large, it provides means to create reports and dashboards as well as possibility to analyze and display data through the wealth of available visualization applications. Many kinds of visualizations are available28.
Google Visualization accepts data in two different ways: a direct construction as well as a JSON literal object, instantiated via the object google.visualization.DataTable.29 . In the latter, the structure of this JSON format is the convention that Google API data sources are expected to return. So, a google.visualization.DataTable can be created using the results of an AJAX response.
It is possible to retrieve and visualize RDF data. As long as the URL retrieved returns Google Visualization JSON, you can create a DataTable and give it to the visual construct
28http://code.google.com/apis/ajax/playground/?type=visualization#data_source_request.
to draw(). The results of a SPARQL query can be converted to the Google Visualization JSON using an XSL like the one used at RPI for data.gov]. A sample performing these steps is presented in the Tetherless World Constellation, named SparqlProxy30. It performs these steps for a client with a single HTTP request. By providing the URL of a sparql endpoint to be queried (using service_uri), a query (using query or query-uri), and a specification for return format as Google Visualization JSON (using output=gvds).
Figure 15: Line chart of unemployment rate for 3 different countries in EU using Google Public Data visualization
3.5.
Data Publica Visualization Tool
Data Publica has developed a tool for visualizing open data (DataPublica) in France. The tool is based on the Dataset Publishing Language (Google, Dataset Publishing Language), an implementation of Google public data explorer and Google visualization API. It uses highcharts31. The only constraint is that data should be formatted in DSPL, an open
XML-based meta data format. Google Data explorer is part of the Google Public Data tool.
Google Public Data32 is a data visualization tool that allows users to compare data in charts, graphs, and maps, as well as videos that show data change over time. Users can use the tools with their own datasets and share results via hyperlink. Its data are drawn from a large directory of public sources, including the US Bureau of Labor Statistics, the US Census Bureau, the World Bank IMF, and Eurostat.
Users can upload via the Google Public Data their own datasets for visualization and exploration. And for official data providers, there is a special form to add data to the directory.
30http://data-gov.tw.rpi.edu/ws/sparqlproxy.php 31http://www.highcharts.com/
3.6.
The Geoportal API
The Geoportal API (GeoAPI) for the web is a library code aims at enriching your web page with a dynamic cartography (IGN, 2012). The API is based on the data produced at IGN. Also the library includes services to search by location based on the exhaustive BD ADRESSE and BD BYME databases at IGN.
GeoAPI proposed the set of libraries code in Javascript and Flash. The use of the API is free without limit of request for a non-commercial purpose. The input data formats are GML, KML, GPX. The scope of the data is the French territory (Metropolitan, Corsica, DOM and overseas communities.
4.
Criteria for choosing a visualization Tool
“An information visualization tool is a computer-based (usually) system designed to
display visually encoded data in order to support the process of information visualization”33. We agree with (Pollack & Ben-Ari) when they state that "If there were only one set of criteria for choosing a visualization tool, there would be only one visualization system". Thus, it not normal that the multiplicity of tools and systems means that different researchers have different sets of criteria when implementing the tools for visualization open data. So the Web of Data is one of the application domains of Information visualization.
There are often three principal components of Information Visualization:
• Representation: how the data is encoded usually in visual form
• Presentation: how suitably encoded data is laid out in; available display area and time
• Interaction: the actions performed by user to move from one view of the data to another
We consider some criteria that could be taken into account to assess different visualization tools, adapting from the analysis provided in the field of education (Pollack & Ben-Ari), in Table 1. We group those criteria in five groups, each of them with a different weight. Those criteria are the following:
• Usability (20%) • Visualization (35%) • Data accessibility (25%) • Deployment (15%) • Extensibility (5%)
Here is a list of aspects of the tools that could be assessed under some sub criteria and weights:
Criterion Sub criterion Weight
Usability 20%
Installation Existing Libraries
Creating different type of views
Visualization 35%
Control of facets/customization Ease of aggregation of views Number of charts
Time of response to user Browser capability
Data Accessibility 25%
Data format
Data pre-processing Data scalability (big data?) Data access
Deployment 15%
Client library
Mode server deployment License
Extensibility 5%
Implementation Language Interoperability with other tools
Tableau 1: Criteria for selecting visualization tools with some weights.
Tools Data
formats Data Access Language code Type of views Imported Libraries Deployment License SemWeb Complia nt
Creator
Choosel
xls, csv API GWT Text, Map, Bar chart Time (simile), Protovis charts, Flexvis
Client Open No Lars
Grammel Fresnel
RDF -- RDF Properties, Labels, Welkin, IsaViz, Haystack, CSS
Client Open Yes Emmanuel
Pietriga et al. Spark
RDF/JSON SPARQL PHP Date chart, Pie chart, simple
table -- Client Open Yes AIFB/KIT
LDA RDF SPARQL Java, Php -- -- Client Open Yes Talis,
Epimorphis
SWImP RDF SPARQL
CONSTRUCT Netbeans Graph node views -- Client CECILL-B
34 Yes Wimmics
(INRIA) Many Eyes XLS, Plain
text and H TML
API Java
Flash Charts, trees, graphs, maps -- Web embedded Proprietary No IBM Research
D3.js CSV,
SVG,GeoJso
n API JavaScript
Charts, trees, graphs, maps Jquery, sizzle,
colorbrewer Client
Open
Possible Mike Bostock
FSSBW RDF/JSON SPARQL JavaScript Map, Facet Jquery,
dynatree Client Open Yes AKSW
Sgvizler RDF/JSON SPARQL SELECT JavaScript Map, line chart, timeline,
sparkline Google API Client Open Yes Martin G.
Skjæveland
Map4rdf RDF/JSON SPARQL Java, GWT Facet, map OSM Layers, Google Maps
Client Open Yes UPM
Exhibit
JSON-Exhibit Data Dump JavaScript
Tile, thumbnail, tabular
timeline and
map ---- Client Open Yes MIT
Google Visualization API
JSON
Data Inline API JavaScript Many charts, controls and
dashboard AJAX API
Client Web
embedded Open Yes, but.. Google Data Publica DSPL API (beta) JavaScript Map, graph, histogram,
table highchart.js Web embedded Proprietary No
Data Publica
GeoAPI GML, KML,
GPX API Javascript Map views OpenLayers Prototype.js Client
Free for
non-commercial use
5.
Conclusion
In this document, we have presented some tools and APIs to visualize structured data. We have also provided some criteria that could help for decision making.
We are aware that more research at user level is necessary to validate our proposal. We recognize that the visualization tools presented in this document varied from their scope, the libraries used, the type of views or deployments required both at the server and the client side. Some of them are publicly available and thus extensible for a specific use or application. Some further studies should be made for mobile applications, as they are not considered in this current study.
At the current stage of the Datalift Project (mid-term), it is worth highlighting we have put in practice some of the tools described in this document. More precisely, we have experiment three of them: Exhibit for building a map of publications and conferences at EURECOM; LDA with the Elda implementation for events and media reconciliation in the cloud; and finally protovis (now D3) applied to represent the LOV datasets. Those demonstrators are available at:
• http://perso.telecom-paristech.fr/~gazet/map.html
• http://eventmedia.eurecom.fr/ and http://eventmedia.eurecom.fr/confomaton/
• http://labs.mondeca.com/dataset/lov/
We plan to select some of these tools to implement the use cases for the DataLift platform.
References
Bostock, M. (2012). Data-Driven Documents. Retrieved May 26, 2012, from http://d3js.org/
DataPublica. (n.d.). Data Publica Visualization API. Retrieved from http://www.data-publica.com/content/api/
Epimorphics. (n.d.). Elda. Retrieved June 09, 2012, from http://code.google.com/p/elda Fresnel. (2005). W3C. Retrieved June 09, 2012, from Manual de Fresnel:
http://www.w3.org/2005/04/fresnel-info/manual
GAZET, A.-E., Atemezing, G., & Troncy, R. (2012). Building data.eurecom.fr. Sophia-Antipolis: EURECOM, Semester Report.
GeoLinkedData. (n.d.). GeoLinkedData.es. Retrieved from 2011: http://geo.linkeddata.es Google. (n.d.). Dataset Publishing Language. Retrieved from
https://developers.google.com/public-data/
Google. (n.d.). Google Visualization API Reference. Retrieved May 26, 2012, from https://developers.google.com/chart/interactive/docs/reference Grammel, L., & Storey, M.-A. (2010). Poster: Choosel – Web-based Visualization
Construction and Coordination for Information Visualization Novices. IEEE Information Visualization Conference (InfoVis).
Haystack. (n.d.). Haystack. Retrieved June 09, 2012, from Haystack: http://haystack.csail.mit.edu
Hearst, M., & al. (2002.). Finding the flow in web site search. Communications of the ACM, 45(9).
Huynh, D., Karger, D. R., & Miller, R. C. (2007). Exhibit: lightweight structured data publishing . Proceedings of the 16th international conference on World Wide Web, WWW'07 (pp. 737-746). New York: ACM.
IBM, R. (2010). Many Eyes. Retrieved May 26, 2012, from www-958.ibm.com/ IGN. (2012, May 24). API Géoportail pour le web. Retrieved June 13, 2012, from
https://api.ign.fr/geoportail/api/doc/fr/index.html
Khrouf, H., Atemezing, G., Rizzo, G., Troncy, R., & Steiner, T. (2012). Aggregating Social Media for Enhancing Conference Experience. (ICWSM'12) 1st International
Workshop on Real-Time Analysis and Mining of Social Streams (RAMSS'12). Dublin, Ireland, June 4, 2012.
Lieberman, J. (2010, July 21). W3C Geospatial Incubator Group. Retrieved from http://www.w3.org/2005/Incubator/geo/
LOD2, p. (n.d.). Deliverable D5.1.1 LOD2. Retrieved May 26, 2012, from
http://static.lod2.eu/Deliverables/LOD2_D5.11_Spatial-faceted_browsing_widget.pdf
Map4rdf. (2011). Map4rdf. Retrieved from http://oegdev.dia.fi.upm.es/map4rdf/
Marti, H. (2009). Search User Interfaces. In H. Marti, Search User Interfaces. University of California, Berkeley: Hardback, ISBN: 978052113793.
Open, U. (2011). data.open.ac.uk. Retrieved June 09, 2012, from http://data.open.ac.uk/ Pierre-Yves Vandenbussche, B. V. (2011). LOV dataset . Retrieved from
http://labs.mondeca.com/dataset/lov/
Pietriga, E., Bizer, C., Karger, D., & Lee, R. (2006). Browser-Independent Presentation Vocabulary for RDF. ISWC.
Pollack, S., & Ben-Ari, M. (n.d.). Selecting a Visualization System. Third Program Visualization Workshop, (pp. 134-140).
Raphaël Troncy, B. M. (2010). Linked Data Triplification Challenge. 6th International Conference on Semantic Systems (I-SEMANTICS'10). Graz, Austria.
Sgvizler. (n.d.). Sgvizler. Retrieved May 09, 2012, from Sgvizler: http://code.google.com/p/sgvizler
Snorql. (n.d.). Snorql. Retrieved from http://dbpedia.org/snorql/ Southampton, U. (2011). data.southampton.ac.uk. Retrieved from
http://data.southampton.ac.uk
Talis. (2010). Linked Data API. Retrieved June 09, 2012, from
http://code.google.com/p/linked-data-api/wiki/Specification
Talis. (2011). Puelia. Retrieved June 09, 2012, from http://code.google.com/p/puelia-php/
Tennison, J. (2010, July 02). Guest Post: A Developers' Guide to the Linked Data APIs . Retrieved June 09, 2012, from http://data.gov.uk/blog/guest-post-developers-guide-linked-data-apis-jeni-tennison
Tetherless, C. (2010). How to Use Google Visualization API. Retrieved May 20, 2012, from http://data-gov.tw.rpi.edu/wiki/How_to_use_Google_Visualization_API
Vrandecic, D., & Harth, A. (2011). Visualising SPARQL result sets with Spark. Karlsruhe, Institute AIFB, KIT: Tech Report.
Wimmics, & Dream. (2011). SemanticWebImport. Retrieved June 13, 2012, from http://wiki.gephi.org/index.php/SemanticWebImport